Prometheus監視
運用上の負債を抱えずにPrometheusを拡張する — 処理速度は30倍高速化、ストレージ容量は2.5分の1に削減
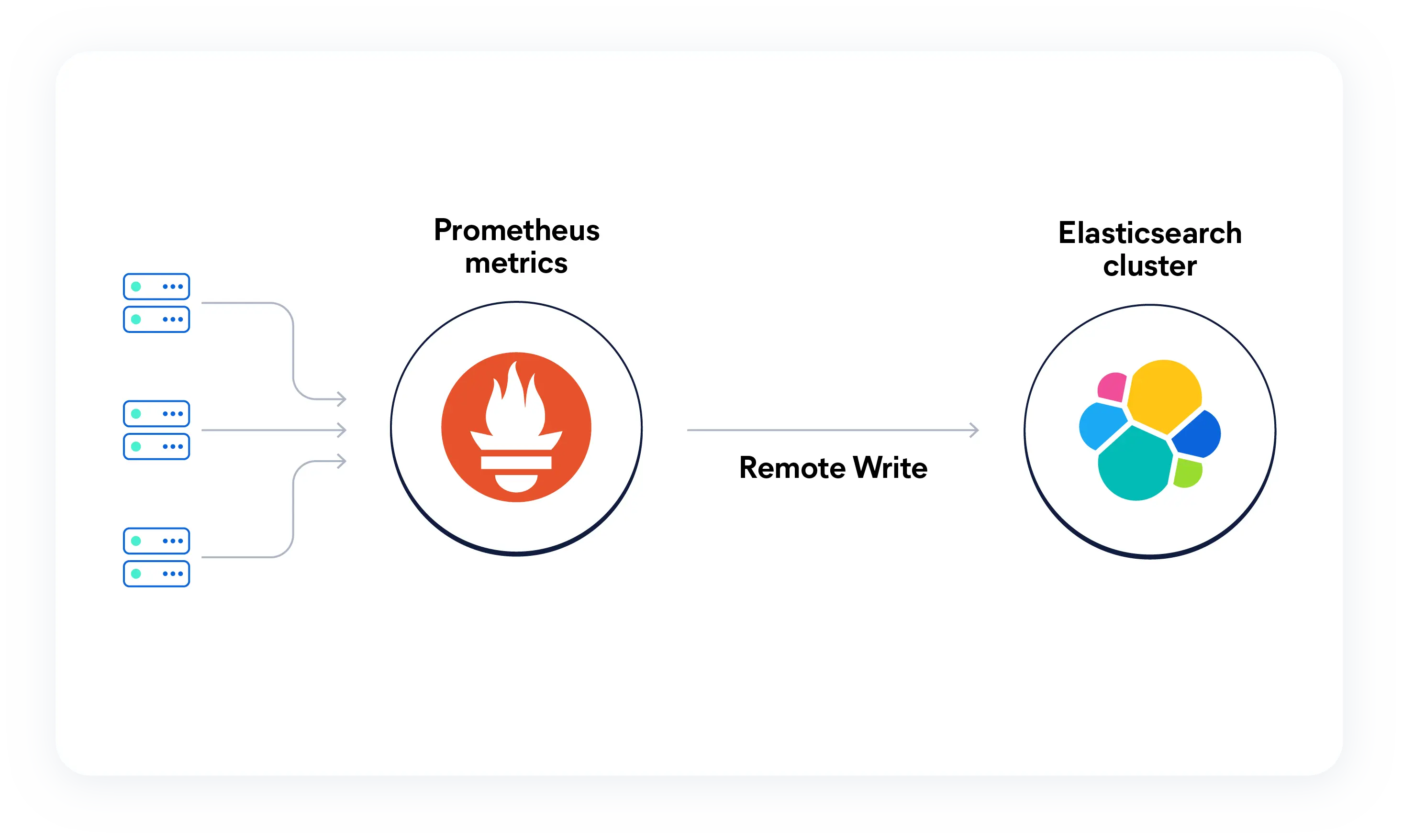
PrometheusのメトリクスをElasticsearchにネイティブに取り込み、PromQLクエリをKibanaで直接実行します。カーディナリティの高い時系列データをログやトレースと統合して、AI主導でスケーラブルでオープンな設計によるフルスタックのオブザーバビリティを実現します。
Elasticsearch:メトリクスにおける最高クラスの効率性
当社のTSDBは、あらゆる規模において、データ取り込み速度とクエリ速度でPrometheusを凌駕します。
Prometheus + Elasticsearch
Elasticは、Prometheusのメトリクスと業界最高レベルのログ分析ソリューションを連携させます。使い慣れたPromQLワークフローはそのままに、ログ相関とエージェント型AIでさらに強化できます。ダッシュボードを手動で操作する代わりに、AIがメトリクスとログを分析し、数秒で必要な情報を見つけ出します。
オブザーバビリティスタックへの応急処置での対応を停止
SREは、Prometheusのスケーリングに伴う運用上のオーバーヘッドや、サイロ化されたシグナルを使用してインシデントを解決するために必要なコンテキスト切り替えにうんざりしています。Elasticは、これらすべてを単一の高性能プラットフォームに統合します。



Prometheusに伴う追加作業が不要に
Prometheusの管理やスケーリングが負担に感じられることがなくなります。Elasticの統合データストアにより、パフォーマンスとコストを犠牲にすることなく、長期的なデータ保持が可能になります。
Elasticsearch
Prometheus / Mimir / ClickHouse
ネイティブのPrometheusとPromQLを使用することで、ロックインや書き換え、数ヶ月にわたる移行プロジェクトが不要になります。
Prometheusの長期ストレージとスケーリングには、多くの場合、MimirやClickhouseなどの追加バックエンドが必要です。
MimirはPromQLをサポートしていますが、ClickHouseは翻訳レイヤーを必要とします。
PrometheusとOTelを1つの高性能時系列データストアにネイティブに保存します。セマンティックな変更も、独自のレイヤーもありません。
Prometheusは明示的な変換を行うOTel Collectorを必要とします。
ClickHouseはOTelをサポートしていますが、カスタムスキーマ作業とパイプライン設定が必要です。
共通プラットフォームで、1つのクエリ言語(ES|QL)で、タブやコンテキストを切り替えることなく、メトリクス、ログ、トレースを関連付けます。PromQLステートメントはES|QLクエリの一部として含めることができます。
メトリックとログは別々のバックエンドに存在し、インシデント発生時にツールやクエリ言語間でコンテクストスイッチングが必要になります。
ClickHouseは3種類の信号をすべて保存できますが、そのためにはカスタムスキーマとパイプラインの大幅な作業が必要となります。
ディスク上の列型ストレージにより、メモリ内のカーディナリティ上限がなくなります。OOMの壁なしに、高カーディナリティのKubernetesやクラウド環境にスケールできます。
PrometheusとMimirはメモリ内倒置インデックスを使用しており、カーディナリティの急上昇は最悪のタイミングでメモリ不足によるクラッシュを引き起こします。
ほとんどのクエリタイプにおいて、低カーディナリティと高カーディナリティの両方で、PrometheusおよびMimirを10倍~25倍以上上回るパフォーマンスを発揮します。
ClickHouseはカーディナリティの処理に優れているが、大規模化すると大幅な調整が必要になります。
自動ダウンサンプリング機能を内蔵。フル解像度のデータを引き続き検索可能です。優れた圧縮により、手動作業やデータ損失なしにストレージフットプリントを削減します。
Mimirにはダウンサンプリングが組み込まれていません。長期保存を管理するには、手動で記録ルールを作成する必要があり、データの粒度が永久に失われてしまいます。
ClickHouseではカスタムTTLと集計パイプラインが必要です。
長期保持と高解像度を実現した予測可能な価格設定。カーディナリティペナルティはなく、強制的なロールアップもありません。
PrometheusとMimirのスケーリングは、コストとパフォーマンスのトレードオフを意味します。つまり、より多くの費用を支払ってデータをより長く保持するか、ダウンサンプリングして粒度を落とすかのどちらかを選択することになります。
ClickHouseは、クエリ速度とストレージコストのバランスを取るために、継続的なチューニングが必要です。
Elastic Cloud、セルフマネージド、ハイブリッド導入で完全な機能を提供します。
PrometheusとMimirは自己管理のみで、スケール時には大きな運用オーバーヘッドが発生します。
ClickHouseは運用に相当なインフラの専門知識を必要とします。
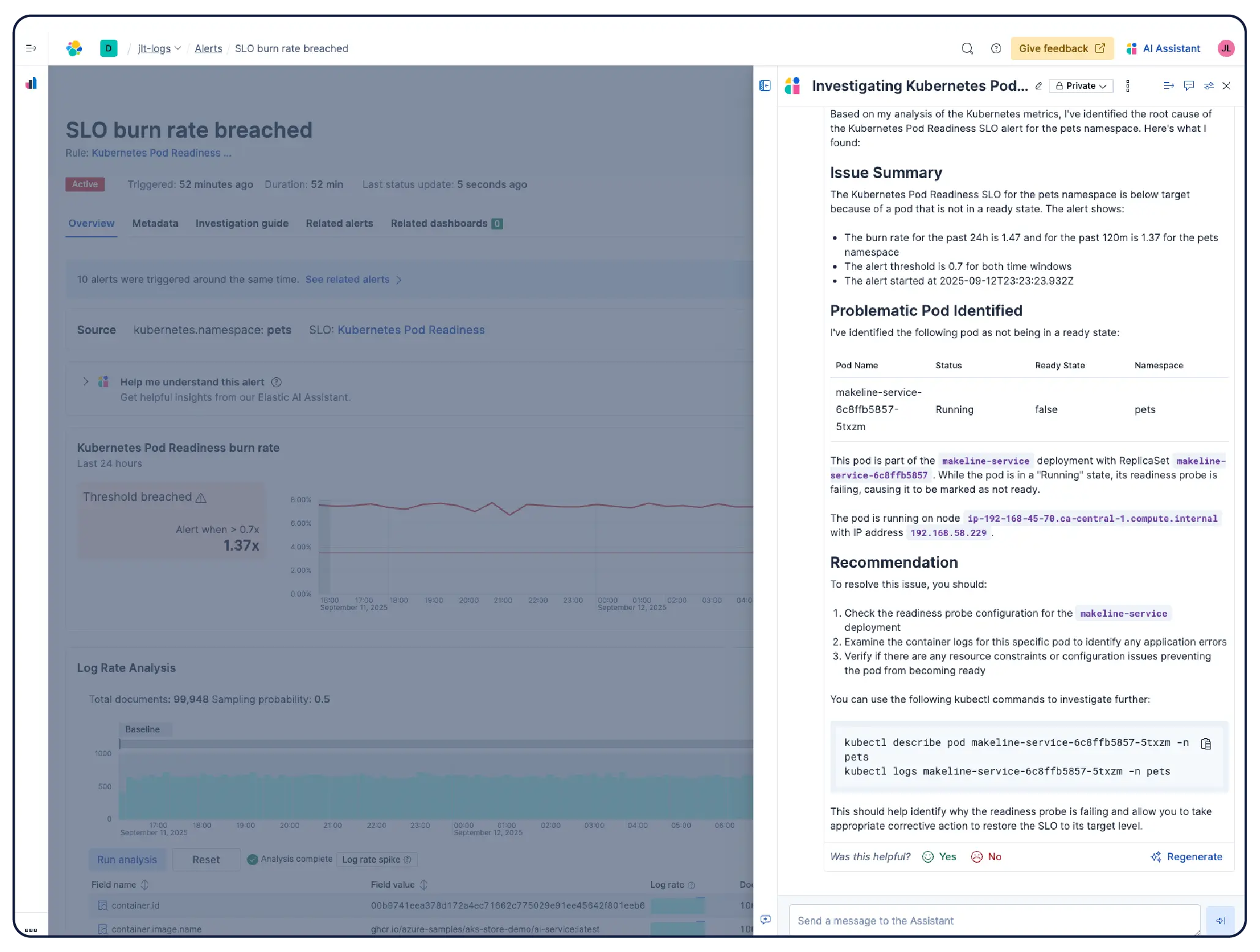
AIはメトリクス、ログ、トレースを分析して根本原因を迅速に特定し、改善をガイドします。手動でのダッシュボード探索は不要です。
GrafanaのAIアシスタントは、単一の統合されたデータストアではなく、断片化されたバックエンド間で動作します。
ClickHouseにはネイティブのエージェントAIが存在しません。調査は、切り離されたツールやデータサイロ間の相関に依存しています。
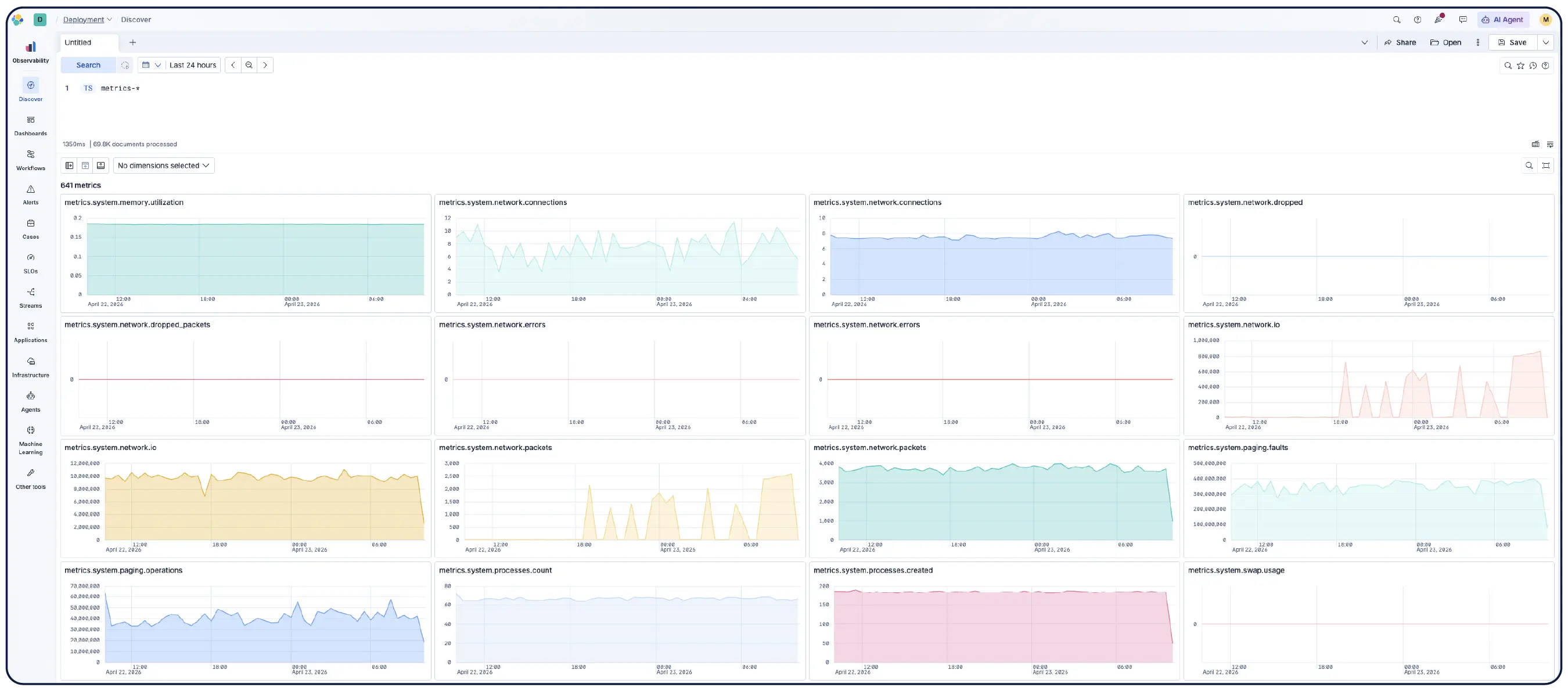
インフラデータをアクションに変換
インフラストラクチャを大規模に監視します。AI主導の調査により異常が強調表示され、傾向が明らかになり、修復が自動化されます。これにより、キャパシティプランニングや問題解決を迅速に行うことができます。
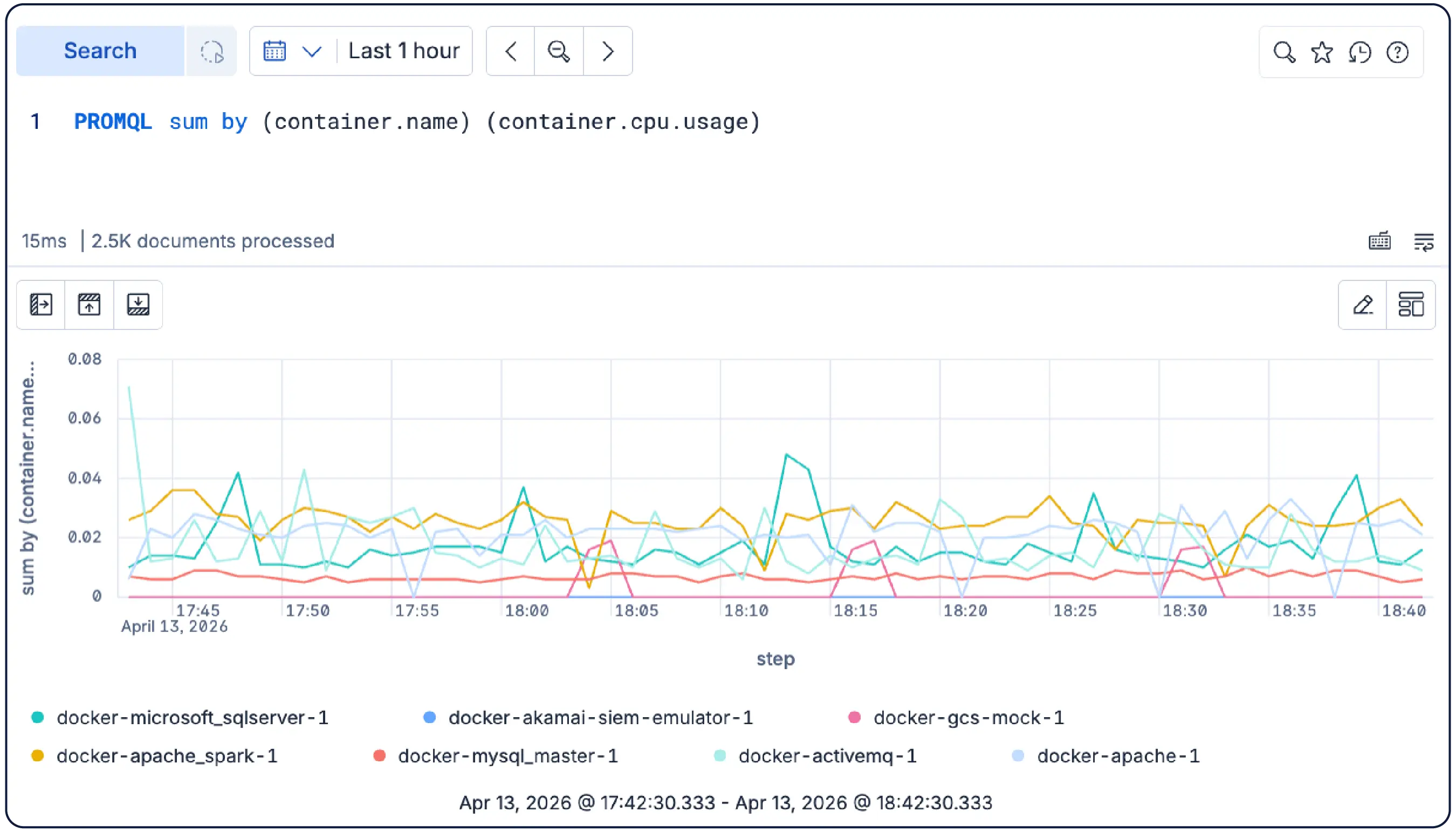
PromQLクエリをKibanaで直接実行できます。変換レイヤーや書き換えは不要です。レート、合計、最大オーバータイム、その他の一般的な関数はES|QLと並行してそのまま機能します。
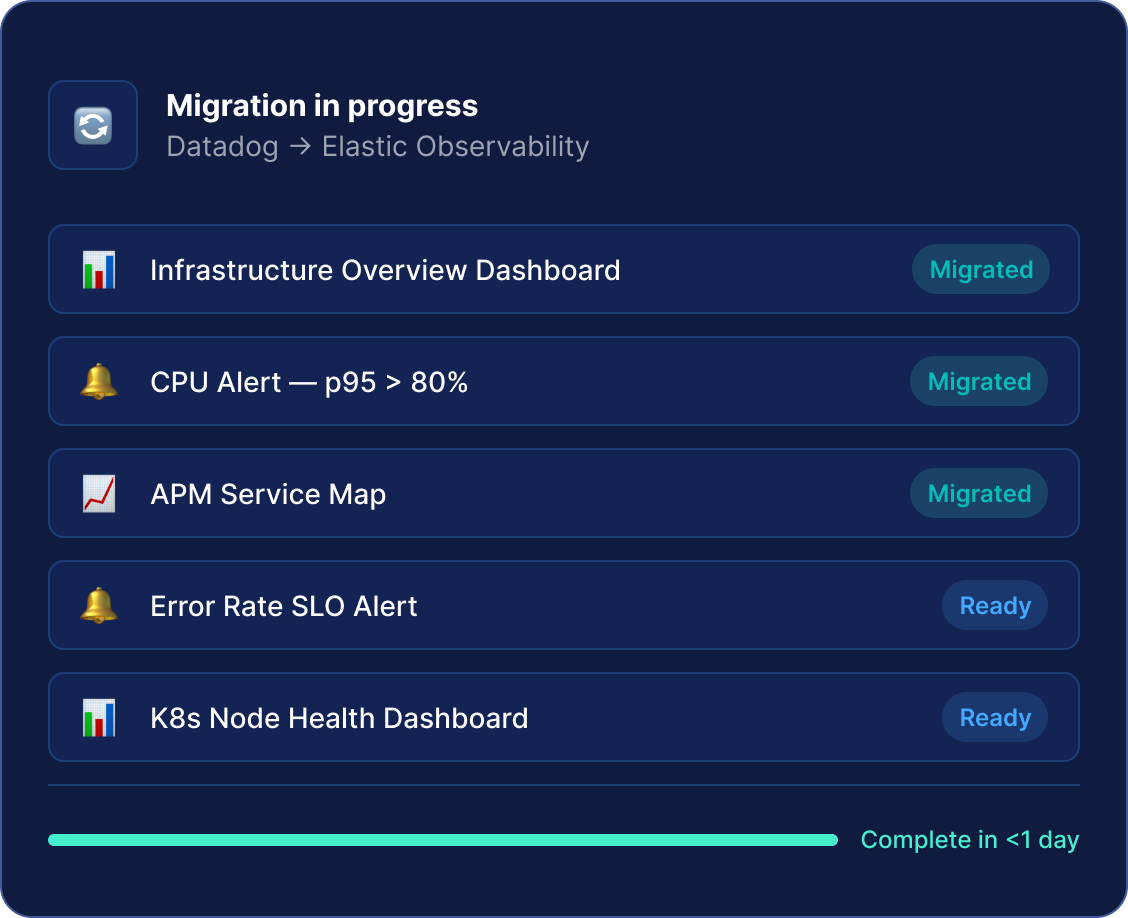
移行ツール — テクニカルプレビュー
Grafanaから一夜にして移行
GrafanaのダッシュボードとアラートルールをElasticに自動的に変換することで、プラットフォーム切り替えのコストと複雑さを大幅に削減します。
よくあるご質問
Prometheusとは?そしてPrometheusの監視とは?
Prometheusとは?そしてPrometheusの監視とは?
Prometheusはオープンソースのモニタリングツールキットです。クラウドネイティブやコンテナ環境で広く採用されているPrometheusは、オープンかつベンダーニュートラルなテキストベースの表示形式を使用してインストルメントされたジョブから時系列データを収集する、人気のツールです。
自己管理型のPrometheusから移行すべき理由とは?
自己管理型のPrometheusから移行すべき理由とは?
Prometheusのスケーリングには、時間とともに増大する運用上のオーバーヘッドが必要です。Mimirのようなバックエンドの管理は、根本的な問題を解決することなく複雑さを増すだけです。Elasticなら、スケーリングを自動で処理するため、そうした作業が一切不要になります。さらに、当社のカラム型ストレージとベクトル化処理により、ほとんどのクエリタイプにおいてPrometheusやMimirを10倍~25倍以上上回るクエリ速度を実現します。
PrometheusのメトリクスをElasticsearchに格納する理由は?
PrometheusのメトリクスをElasticsearchに格納する理由は?
Prometheusのローカルストレージは短期間の保持用に設計されており、通常15日~30日です。Elasticsearch TSDBは、データの経過に応じて自動ロールオーバー、圧縮、ダウンサンプリングを行う効率的な長期ストレージ(Prometheusの2.5倍効率的)を提供します。既存のスクレイピング設定はそのまま使用できます。
既存のPrometheusネイティブのダッシュボードやアラート、クエリはまだ動作しますか?
既存のPrometheusネイティブのダッシュボードやアラート、クエリはまだ動作しますか?
はい。PromQLのネイティブサポートにより、既存のPrometheusワークフローを簡単に引き継ぐことができます。クエリの書き換えや長い移行プロジェクトは必要ありません。
Elasticはどのようにストレージコストを削減しているのでしょうか?
Elasticはどのようにストレージコストを削減しているのでしょうか?
優れたダウンサンプリングと圧縮により、ストレージ容量が大幅に削減されます。予測可能でリソースベースの価格設定により、カーディナリティが増えたり新しいラベルを追加しても請求額が急騰しません。必要なすべての指標をフル解像度で、必要なだけ長く保存できます。
ログの相関はどのようにメトリクスと連携しますか?
ログの相関はどのようにメトリクスと連携しますか?
Elasticはメトリクスとログを同じプラットフォームに格納するため、異なるツールやタブ間でコンテキストを切り替えることなく、ES|QLで両方を同時にクエリできます。
Agentic AIはインシデント解決にどのように役立ちますか?
Agentic AIはインシデント解決にどのように役立ちますか?
ElasticのエージェントAIは、ダッシュボードを手動で調べる代わりに、オブザーバビリティデータを分析して調査を導き、根本原因を明らかにし、修復ワークフローを実行します。
実際の移行はどのように行われますか?
実際の移行はどのように行われますか?
数か月にも及ぶ移行プロジェクトは不要です。ネイティブのPromQLとOTelのサポートにより、既存のデータ取り込みアーキテクチャ、ダッシュボード、クエリを一夜にして移行できます。移行ツール(現在テクニカルプレビュー版)についてはお問い合わせください。
チャットに参加
Elasticのグローバルコミュニティとつながり、オープンな会話やコラボレーションに参加しましょう。


.jpg)
