Prometheusの監視をElastic Stackでスケールさせる
ツールについて考えてみましょう。エンジニアなら誰でもチーム作業の生産性を支援するツールが大好きだし、問題をより早く解決するツールはなおさら歓迎です。しかしツールというものは、数が増えやすく、追加のメンテナンスを必要とします。また何より致命的なことに、サイロ化を招く可能性を有します。組織では、あらゆるチームがツールに関する一定の責任を負っており、固有の要件を可能な限り最適な方法で解決するツールを常時探しています。結果的に、各チームは1つのユニットとしては効率的になる一方で、このようなパフォーマンス型自治の副作用として、組織の他部署へのインサイトの欠落が生じます。チームの数が増えるほどこの現象は増幅し、ビジネスがどう動いているかについての全体的な視点を欠いた、孤立したクラスターがすぐに出現してしまいます。
このようなツールの最たる例が、Prometheusです。Prometheusは急速に、コンテナーシステムを監視/アラートする人気ツールになりました。主な強みは、サーバーサイドメトリックを効率的に監視し、格納できることです。Prometheusは完全なオープンソースです。活発なコミュニティの活動により、Exporterという形式で多数のサードパーティシステムに対応しています。他の多くの専門ツールと同様に、Prometheusはシンプルかつ簡単に運用できるよう設計されています。このシンプルさには代償もあり、大規模なデプロイやチームを横断する共同作業を伴うケースで特に表面化します。本ブログ記事では、その代償について具体的にいくつか検証し、その問題解決にどのようにElastic Stackが役立つかをご説明します。
長期のデータ保持
Prometheusはデータをローカルで、インスタンス内に格納します。1つのノードで演算とデータ格納を行うことにより、運用が簡単になるメリットがある一方で、スケールと高可用性の確保は困難になります。この結果、Prometheusはメトリックの長期格納に最適になってはいません。環境のサイズにもよりますが、Prometheusにおける時系列の最適な保持レートは、数日から数時間と、非常に短くなっています。
Prometheusデータを拡張分析(例:時系列の季節間格差など)向けに、スケーラブルかつ堅牢な方法で保持するには、長期ストレージのソリューションでPrometheusを補完する必要が生じます。この選択肢としては、他の特化型TSDBや、時系列に最適化した列指向データベースなど多数のソリューションが存在します。これらのソリューションはメトリックを格納する上で非常に効率的ですが、共通する欠点も1つあります。それは、メトリックという1つのデータタイプに特化していることです。メトリックは、各種システムの挙動を理解する上では非常に重要です。同時に、メトリックはシステムで観測できるデータのたった1つの側面でしかありません。
オブザーバビリティの観点から、ユーザーはログやトレースといった他のタイプの運用データとメトリックを組み合わせたいと考えます。Elastic Stackにおけるオブザーバビリティを説明した以前のブログ記事でも、ログをきっかけにElastic Stackを導入したユーザーが、その後メトリックやトレース、アップタイムデータもElasticsearchに投入するケースが増えていることをご紹介しました。この事象は不思議ではありません。Elasticsearchではすべてのデータタイプを新たなインデックスとして扱うため、あらゆる運用データのアグリゲーションや相関付け、分析、可視化などを、思いのままに実施できます。Elastic Stackが搭載するデータのロールアップ機能などを使えば、履歴の時系列データを、生データの格納コストの数分の一で格納することができます。
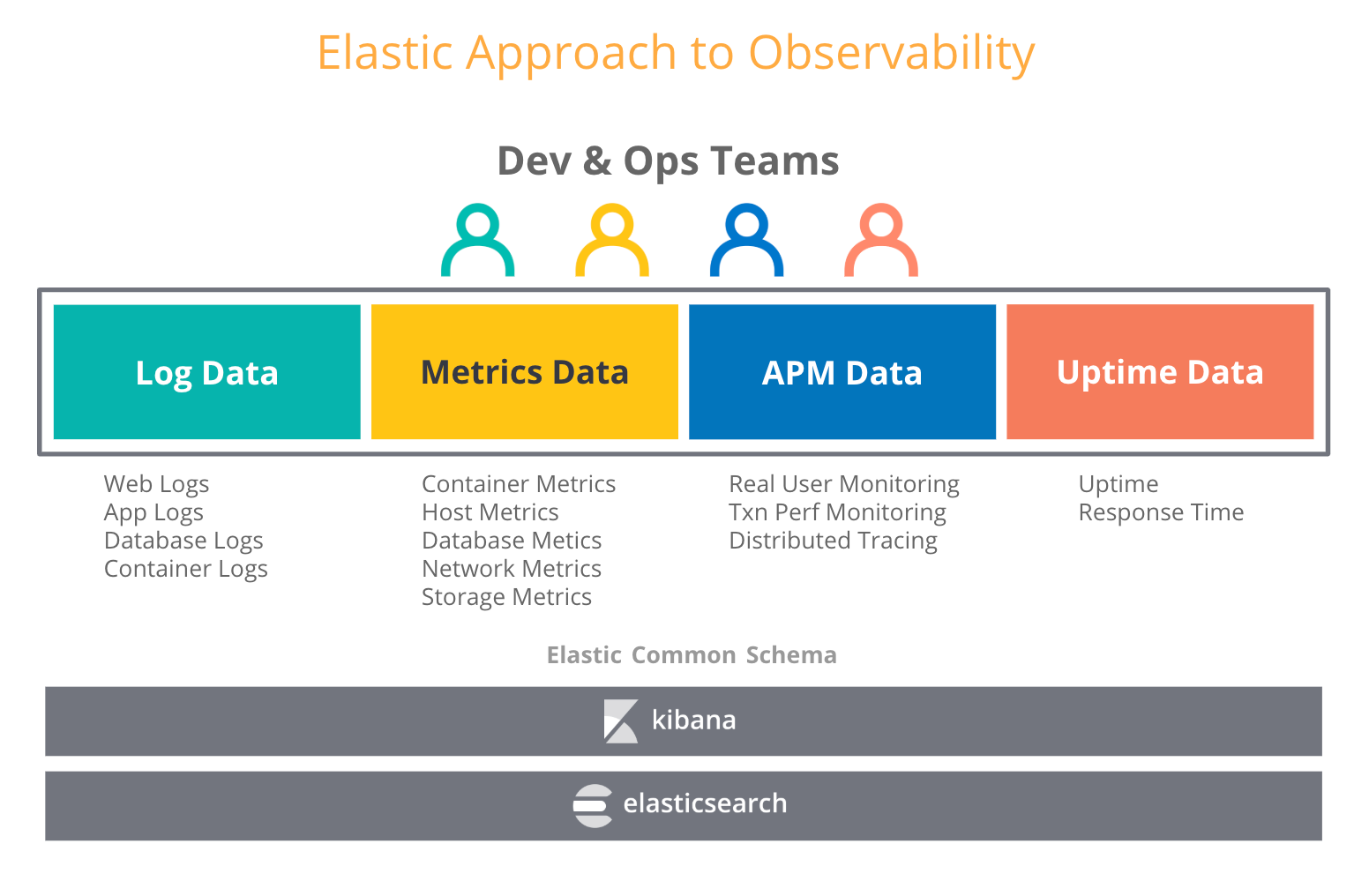
さて“Prometheus用に長期ストレージを選ぶ”ことは、どういうことでしょうか?Prometheusメトリックをより長期のレートで保持するからといって専用のメトリックストアを選択すれば、新たなサイロとなる可能性があります。ではElastic Stackを使うとどうでしょう?Elastic Stackを活用すれば、2つの世界の最良の部分を組み合わせることができます。つまり、エッジではPrometheusを実行し、そのメトリックをどれほど長い間でも、Elasticsearchのデプロイに保持できます。しかも他の運用データと共に、スケーラブルに、一元的に格納できます。長期のストレージとなり、オブザーバビリティも向上するわけです。
Prometheusデータを一元的なグローバルビューで表示する
運用を立ち上げる段階で、複数のKubernetesクラスターを管理するケースは少なくありません。おそらく各クラスターで1つ、またはそれ以上のPrometheusインスタンスを実行して、ノードやpod、サービス、エンドポイントのヘルスを確認できるように設定するでしょう。ここまでで何か、忘れていることはありませんか?
1つのPrometheusインスタンスがカバーできるのは、環境中のリソースのサブセットです。複数のクラスターから来るメトリックをクエリする必要が生じる質問をする場合、Prometheusで簡単に実行する方法は存在しません。

Elastic Stackを一元的なストアとして使えば、数百ものPrometheusインスタンスから来るデータを統合し、すべてのリソースから来るデータのグローバルなビューを作成する上で役立ちます。Metricbeat向けのPrometheusモジュールは、Prometheusインスタンスやpush gateway、exporter、その他の、Prometheusエクスポジションフォーマットをサポートする多数のサービスから来るメトリックを自動でスクレイピングします。特に嬉しいのが、運用環境に一切の変更が必要ない点です。このモジュールは純粋な“プラグアンドプレイ”です。
高カーディナリティ次元
なぜ“高カーディナリティ”は重要なのでしょうか?高カーディナリティであれば、メトリックにタグやラベルなど、任意のコンテクストを追加することができます。こうしたメタデータを保持したいというニーズは多くのケースに存在します。メタデータは、サービスのデバッグに非常に役立つ可能性があるためです。トレースID、リクエストID、コンテナーID、バージョン番号などのあらゆるメタデータを活用すれば、システムの現状をさらに詳細に把握できます。

純粋なTSDB(時系列データベース)は、低カーディナリティ次元を扱うことが得意です。特化型のTSDBがElasticsearchに対して謳うストレージ効率の優位性は、低カーディナリティ次元に大きく依拠しています。一方、Prometheusのドキュメントは高カーディナリティデータを強く推進しています。
注意:key-valueラベルのペアによる一意の組み合わせはすべて、新規の時系列を表現します。これによって格納するデータ量が劇的に増える、ということを思い出しましょう。高カーディナリティで次元を格納するために、ユーザーIDやメールアドレス、際限のない他の値などのラベル(多数の異なるラベル値)を使用しないでください。
これは本当に有益なアドバイスでしょうか?分散環境において、デバッグは非常に複雑なタスクです。以前、モノリスだった頃のデバッグは、アプリケーションコードを通じて実施する単純なプロセスでした。いくつかのダッシュボードを確認すれば、モノリスのモジュールのうち、問題を起こしている犯人がどれか簡単に特定することができました。現在は、そうはいきません。インフラのソフトウェアは今、パラダイムシフトの過渡期にあります。コンテナー、オーケストレーター、マイクロサービス、サービスメッシュ、サーバーレス、ラムダ…このような非常に有望なテクノロジーが、ソフトウェアを開発/運用する手法自体を変化させています。結果的にソフトウェアはより分散化し、デバッグは“システムのどこに問題のあるコードが存在するかを探し出す”という業務になりつつあります。
Elastic Stackにおいては、高カーディナリティは問題とはなりません。データに関連するコンテクストを追加するにあたって、一切の制約がないためです。インデックス機能のおかげで、Elasticsearchのユーザーはあらゆるメタデータを活用し、メトリックに自在に注釈を追加できます。この仕様は、可能な限り早期に、根本原因の特定に役立つ寄与因子を発見する手助けとなります。
あらゆるところに、セキュリティ
すぐれたツールに期待することの1つに、“環境へ持ち込まれるセキュリティリスクの低さ”があります。セキュリティの2大原則は、分散されたあらゆるデプロイで通信を暗号化すること、そしてアクセスを制御すること、です。
本記事の執筆時点では、Prometheusサーバー、Alertmanager、オフィシャルのexporterのいずれも、HTTPエンドポイントでのTLS暗号化をサポートしていません。これらのコンポーネントを安全にデプロイするためには、nginxなどのリバースプロキシを使い、プロキシレイヤーにTLS暗号化を適用する必要があります。メトリックに対するロールベースのアクセス制御(RBAC)もすべて、Prometheusサーバー自体ではなく、外部で対応する必要があります。ただし、Kubernetesクラスター内でPrometheusを実行している場合は、TLSとRBACが共に提供されるため、問題となることはありません。それ以外のすべてのケース(例:地理的に分散させた、またはハイブリッドデプロイで実行している数百のPrometheusサーバーなど)では、サードパーティツールを使ってこのようなセキュリティ上の懸念を解決することは、容易なタスクではありません。
Elasticはこのようなリスクに真摯に向き合い、スタックに統合されるすべての部分にセキュリティ策を講じています。無料のデフォルト配布パッケージに基本的なセキュリティオプションが含まれているほか、Elasticsearchにはクラスターのデータに安全にアクセスする複数の方法があり、またクラスターとデータシッパー間のトラフィックも暗号化されます。RBACに加え、Elasticsearchは高粒度の属性ベースアクセス制御(ABAC)メカニズムもサポートしています。これは、検索クエリとアグリゲーションに際し、ドキュメントへのアクセス制御を実施する機能です。またMetricbeatのSSL構成設定を使えば、環境規模や分散の状況を問わず、運用データの通信を確実に安全に保つことができます。
PrometheusメトリックをElasticsearchにストリーミングする
Metricbeatを使って、今すぐメトリックをPrometheusからElasticsearchにストリーミングしはじめることができます。Prometheusモジュールを使うと、Prometheusサーバーやexporter、push gatewaysから来るメトリックをスクレイピングできます。
- 現在Prometheusサーバーを実行中で、そのメトリックを直接クエリしたいという場合は、Prometheusサーバーに接続し、
/metricsエンドポイント、あるいはPrometheus Federation APIのいずれかを使用して収集済みのメトリックをプルする、というやり方ではじめることもできます。
- Prometheusサーバーを設置していない場合や、exporterやpush gatewaysを複数のツールと並行してスクレイピングすることに抵抗がない場合は、直接接続することもできます。

Metricbeatは、可能な限りPrometheusサーバーに近い場所で実行します。ニーズに最適な設定を選択するには、Prometheusとオープンスタンダードに関するこちらのブログ記事をご参照ください。
Prometheusサーバーのヘルスを監視する
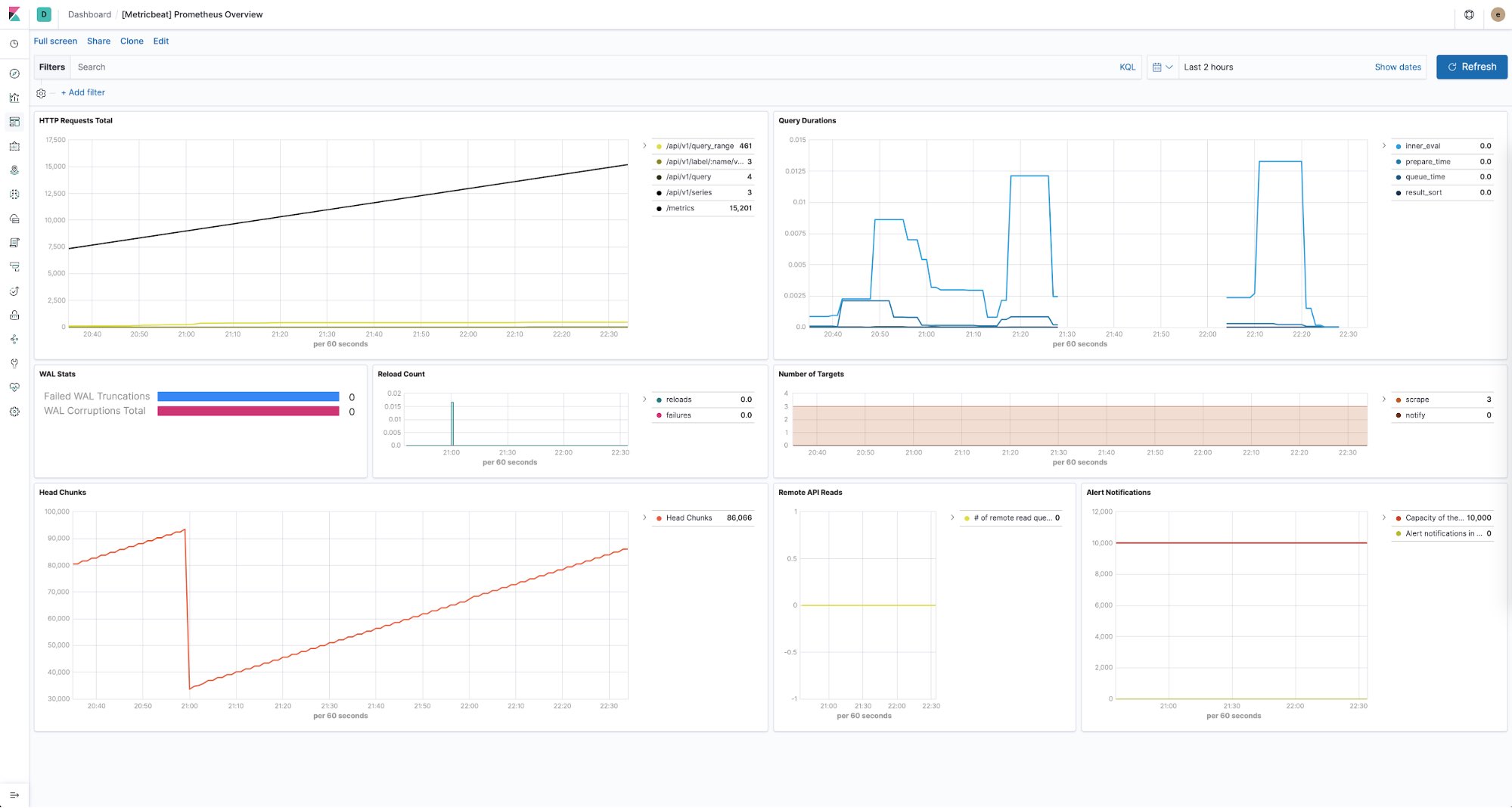
Elastic Stackは、Prometheusインスタンスのあらゆるヘルスを監視する方法も提供しています。Metricbeatを使用して、環境の各Prometheusサーバーから来るパフォーマンスメトリックを収集、および格納することができます。すぐに使える事前定義済みのダッシュボードを使って、エンドポイントごとのHTTPリクエスト数や、クエリ時間、見つかったターゲットの数など、さまざまなデータを簡単に表示できます。
まとめ
目的は、一日の終わりに、あなたとあなたのチームや、組織全体が順風満帆であることです。あらゆるツールは、目的に向かうための手段として見なされるべきです。そして各チームは、潜在能力を遺憾なく発揮するために、役立つものは何でも自由に選べるべきです。もし運用のサイロを破壊する必要が生じたら、そのときはElastic Stackを頼ってください。究極のオブザーバビリティプラットフォームを構築し、そこで組織が運用データに安全にアクセスしたり、操作したりすることで、再び“ワンチーム”となる手助けをします。
時系列データについて詳しくは、Elastic Metrics Webページをご覧ください。まずメトリックをElasticsearch Serviceにストリーミングしてみましょう。一番簡単な方法で、すぐにはじめることができます。ご質問等は、ディスカッションフォーラムにお気軽にお寄せください。