Elastic Stackによる可観測性
Elasticで可観測性担当製品リードを務めている私は、「可観測性」という言葉に対するいくつかの異なる反応を見てきました。未だに圧倒的に多い反応は、「可観測性って何ですか?」というものです。 また、最近よく聞くようになったのは、「「可観測性イニシアティブ」を始めたところなのですが、どう具体的に取り組めばいいのか未だに考えています」といった言葉です。 そしてようやく、協業させていただいたいくつかの組織が、「可観測性」は製品やサービスの設計および構築に欠かせないものであると捉えるようになっています。
この言葉はまだまだ理解が必要なため、Elasticでどのように「可観測性」を捉えているか、ソートリーダーであるお客様から学んだこと、Elastic Stackをオペレーションのユースケース向けに進化させるために製品の観点から考えていることについて、この記事で分かりやすく説明することが役立つのではないかと考えました。
「可観測性」とは
私たちが「可観測性」という言葉を発明したわけではありません。この言葉はユーザーの皆様から聞くようになりました。主にSite Reliability Engineering(SRE)コミュニティ内からです。この言葉の起源に関しては、Twitterのようなシリコンバレーの巨大企業からSREの企業へと広まったとする説がいくつかあります。影響力のあるGoogle SRE Bookでは、この言葉に触れてはいないものの、「可観測性」に関連する原理の多くを提示しています。
「可観測性」は、ベンダーがボックスに入れて提供するものです。つまり、構築するシステムの属性であり、使いやすさや高い可用性、安定性などに似ています。「観測可能な」システムの設計および構築の目標は、本番環境で実行したときに担当のオペレーターが、好ましくない振る舞い(サービスのダウンタイム、エラー、反応の遅延など)を検知し、根本原因を特定するための効果的な方法(詳細なイベントログ、リソース使用に関する細かい情報、アプリケーションのトレースなど)で実用的な情報を得られるようにすることです。 このような明確に思える目標の達成を阻む一般的な課題には、十分な情報を収集していないこと、あまりにも多くの情報を収集しているのにそれらを実用化していないこと、その情報へのアクセスが分断されていることなどが挙げられます。
最初のポイント、つまり好ましくない振る舞いの検知は通常、サービスレベル指標(SLI)およびサービスレベル目標(SLO)を設定することから始まります。 これらは観測性を認識している組織が本番環境のシステムを判断するための、社内における成功の尺度です。契約上の義務としてこれらの目標を満たす場合、SLI/SLOはサービスレベル契約(SLA)とも呼ばれることがあります。SLIの最も一般的な例は、システムのアップダイムです。99.9999%のSLOとして設定することがあります。システムのアップタイムは外部の顧客に提供する最も一般的なSLAでもあります。ただし、社内のSLI/SLOはよりきめ細かい場合があり、本番環境システムの振る舞いの最も重要な要因を監視およびそれらに関するアラートを通知することは、可観測性イニシアティブの基盤となります。可観測性のこの側面は、「監視」という言葉としても知られています。
2つめのポイント、つまり本番環境の問題を迅速かつ効率的にデバッグするためのきめ細かい情報をオペレーターに提供することについては、多くの動きや変革が見られます。よく話題に上っているのは、「可観測性の3つの柱」であるメトリック、ログ、アプリケーションのトレースですが、それと同時に認識されているのは、ツールの寄せ集めを使用してそのような細かいデータを単純に収集することは必ずしも実用的ではなく、多くの場合、費用対効果が低いということです。
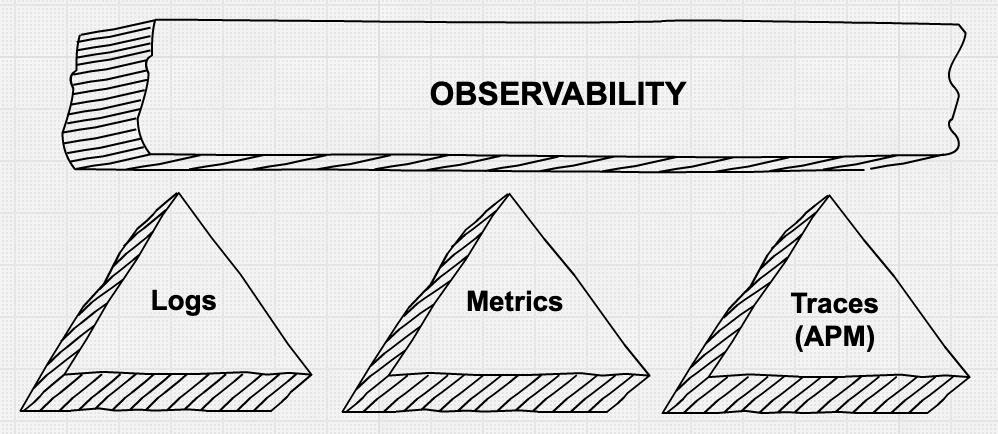
可観測性の「柱」
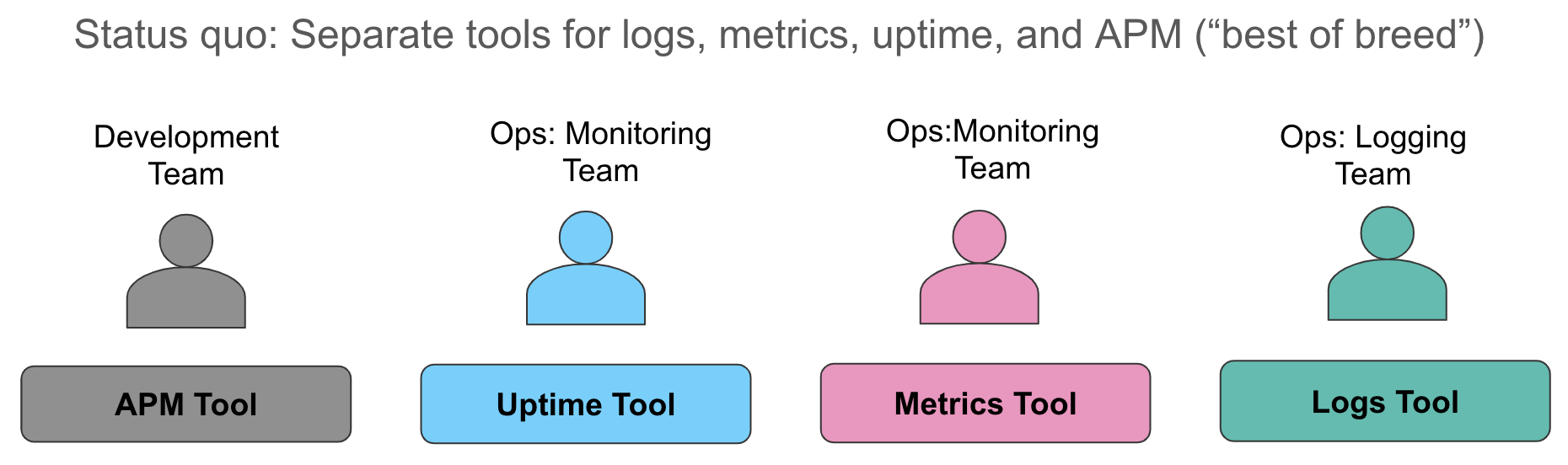
このデータ収集の側面について詳細に見ていきましょう。現在、私たちがよく見るのは、メトリックを1つめのシステム(通常は時系列データベース、またはリソース監視用のSaaSサービス)に収集し、ログを2つめのシステム(想像どおり、多くの場合はELKスタック)に収集し、リクエストレベルのトレースはアプリケーションを調整する3つめのツールを使用して提供するという方法です。サービスレベルの違反を示すアラートが発行されると、オペレーターはシステムに駆け寄り、できる限り最高の「回転椅子の範囲での統合」を実行します。つまり、1つめのブラウザーウィンドウでメトリックを確認し、それを別のウィンドウでログに手動で関連付け、必要な場合は3つめのウィンドウでトレースを引き出します。
このアプローチにはいくつかの欠点があります。まず、同じストーリーを伝えているさまざまなデータソースを手動で関連付ける作業は、サービスの低下時または停止時の貴重な時間を浪費します。2つめは、3つの異なるオペレーション用データソースの維持にかかる運用コストが負担となります。ライセンスコスト、異種の運用ツールに関する個別の管理者の必要性、各データソースの一貫性のない機械学習機能、アラート用のさまざまなセマンティックを考える労力が必要になり、私が話したことのある組織はすべて、これらの課題に悩まされています。
そこで認識が高まってきているのが、これらの情報のすべてを、直感的なユーザーインターフェースで自動的に関連付ける機能を持った単一の運用ストアに格納することの重要性です。私たちのお客様にとっての理想は、アプリケーションからの長文のデータ、計装から生じるトレースデータ、時系列のメトリックで示されるリソース使用状況データなど、サポートしているサービスに関連するすべてのデータを、統一された方法でオペレーターに提供することです。要件としてお客様が強調しているのは、ソースに関係なくこれらのデータに均一かつその場ですぐにアクセスし、検索からフィルタリング、集計、ビジュアライゼーションまでできることです。メトリックから開始して、ログの詳細確認からトレースまで、コンテキストを切り替えることなく数回のクリックでできれば迅速に調査できます。同様に、構造化されたログから数値を抽出することはメトリックに驚くほど似ており、横に並べて視覚化することは運用の観点から見て大きな価値があります。
前述したように、単純にデータを収集するだけではあまりにも多くの情報をディスクに格納することになり、インシデントが発生したときに十分な実用的情報を持っていないことになる場合があります。ますます期待されるようになっているのは、運用データを収集しているシステムが自動的に、時系列のパターンと比較して「興味深い」イベント、トレース、異常を提供してくれることです。これによってオペレーターは、根本原因に焦点を当てながらより迅速に問題を調査できるようになります。これらの異常検知機能は、「可観測性の4つめの柱」と呼ばれることもあります。アップタイムデータ、リソースの使用状況、ログパターンにおける例外、最も関連性の高いトレースなどにわたる異常を検知することは、可観測性チームが出している新しい要件です。
可観測性... そしてELKスタック
では、可観測性とElastic Stack(運用サークル内ではELK Stackと呼ばれています)はどう関係しているのでしょうか?
ELK Stackは、運用システムからのログを一元管理する事実上の方法として広く知られています。その前提は、Elasticsearch(「検索エンジン」)はフリーテキスト検索のためにテキストベースのログを格納する最適な場所である、というものです。実際に、「error」(エラー)という語句を検索、または良く知られているタグを基にしてログをフィルタリングするために、テキストベースのログを検索することは非常に強力な方法であり、しばしばほとんどのユーザーがこれを開始点とします。
しかし、ほとんどのELK Stackユーザーは知っていますが、 データストアとしてのElasticsearchは、転置インデックス以外にも、効率的な全文検索およびシンプルなフィルタリング機能のための多くの方法を提供します。また、ELK Stackには高密度の時系列数値データの格納と運用に最適化された列ストアもあります。列ストアは、文字列と数値の両方について、解析ログから抽出された構造データを格納するのに使用されます。実際、効率的な数値の格納と取得を実現するために、最初にElasticsearchの最適化を推し進めたのは、ログをメトリックに変換するユースケースに対応するためでした。
そのうち、ユーザーは時系列数値データを直接Elasticsearchに投入し始めたため、Elasticsearchはレガシーの時系列データベースに取って代わりました。このニーズに後押しされ、Elasticは最近、メトリックの自動収集のためのMetricbeatを導入しました。これは自動ロールアップのコンセプトを備えており、データストアおよびUIの両方に関するメトリック固有の機能もあります。結果として、さらに多くのユーザーがログのためにELK Stackを採用するようになっており、これらのユーザーはリソース使用状況などのメトリックデータをElastic Stackに投入し始めています。Elasticsearchが魅力的である理由は、前述した運用コストの削減に加えて、数値の集計の対象となるフィールドのカーディナリティに制約がないことです(これは既存の多くの時系列データベースに関してよく聞かれる不満です)。
メトリックと同様、アップタイムデータはログとともに重要度の高いデータタイプとなっており、監視機能によるSLO/SLIアラートの重要なソースとなっています。アップタイムデータにより、通常はユーザーが影響を感じる前に、サービス、API、Webサイトのパフォーマンスの低下に関する情報を提供できます。さらなるメリットとして、アップタイムデータは格納要件の観点からは非常に小さいため、少しの追加コストで大きな価値をもたらします。
昨年、Elasticはスタックにアプリケーショントレーシングおよび分散トレーシングを追加するElastic APMも導入しました。すでにいくつかのオープンソースプロジェクトや有名なAPMベンダーがElasticsearchを使用してデータを格納、検索していたため、これは私たちにとって自然な進化でした。従来のAPMツールの現状は、APMトレースデータをログおよびメトリックとは別に維持し、運用データのサイロを永続させるものです。Elastic APMは、サポートされた言語およびフレームワークからトレースデータを収集する一連のエージェントを提供し、OpenTracingをサポートします。このトレースデータは自動的に、メトリックおよびログと関連付けられます。
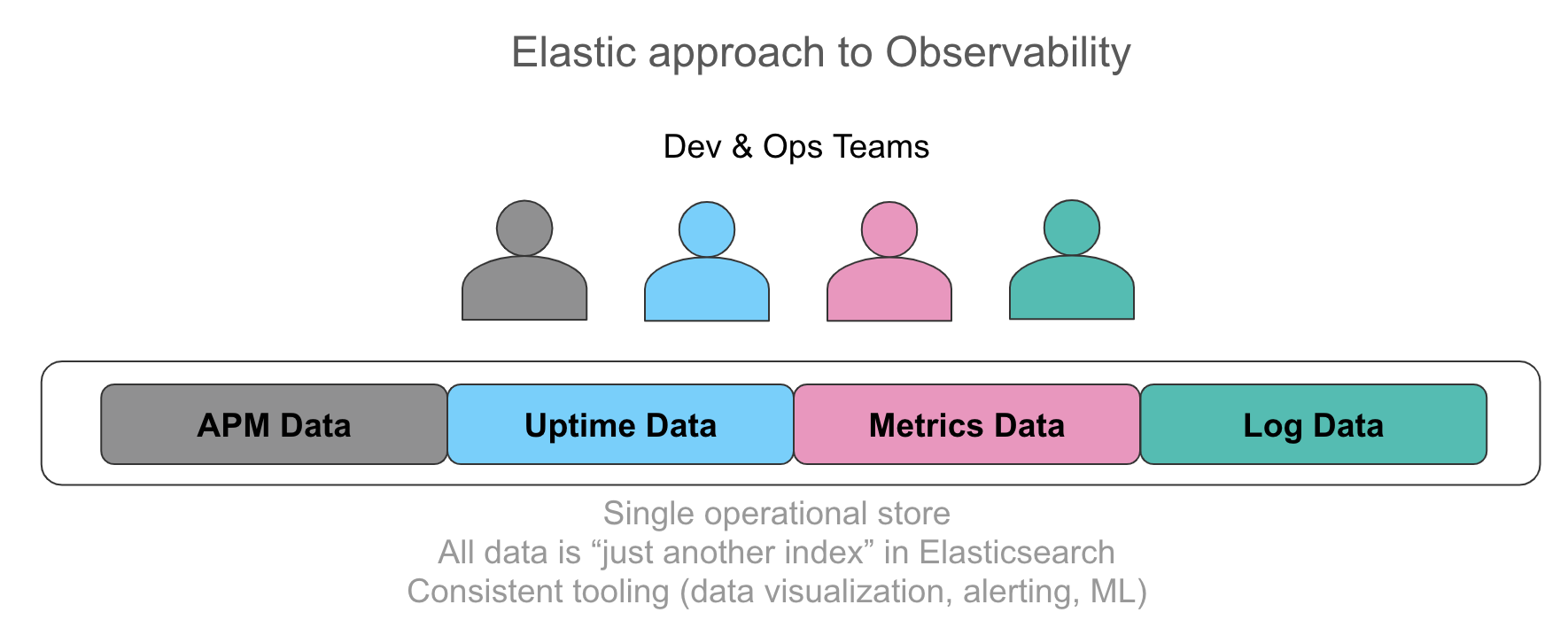
これらすべてのデータ入力の共通のスレッドは、それぞれがElasticsearchの別のインデックスです。これらすべてのデータに実行する集計、Kibanaでの可視化方法、各データソースへのアラートおよび機械学習の適用方法について、制約はありません。その実際の操作については こちらのビデオをご覧ください。
観測可能なKubernetesとElastic Stack
コンテナーのオーケストレーションにKubernetesを採用しているユーザーグループのコミュニティでは、可観測性の概念が会話のトピックとして注目されています。これらの「クラウドネイティブ」(Cloud Native Computing Foundation(CNCF)から有名になった用語)のユーザーたちは、独自の課題に直面しています。Kubernetesによるコンテナーオーケストレーションプラットフォーム上に構築(またはそのプラットフォームへと移行)されたアプリケーションとサービスを大規模に一元化するということと、モノリシックなアプリケーションを「マイクロサービス」に分割するというトレンドに直面しているのです。これまで、インフラストラクチャー上で実行されているアプリケーションへの必要な可視性を提供するのに使用していたツールや方法は、今や役に立たなくなりました。
Kubernetesの可観測性に関してはそれだけで別の記事が必要ですが、その詳細については観測可能なKubernetesに関するウェビナーおよびElastic APMでの分散トレーシングに関するブログ記事をご覧ください。
次のステップ
このような記事の場合は、参照できるいくつかのリソースをご紹介しておくのが適切でしょう。
可観測性のベストプラクティスの詳細を学ぶには、先に触れたGoogle SRE Bookから開始されることをお勧めします。本番環境の重要なアプリケーションを完璧に運用することに、事業の存続がかかっている企業もあります。それらの企業によるブログ記事は非常に示唆に富んでいます。たとえば、Salesforceのエンジニアよって最近投稿されたブログは、可観測性の状態を繰り返し改善するための実用的で役立つガイドとなっています。
観測に関する取り組みにElastic Stackの機能を試す場合は、Elastic Cloud上で最新バージョンのElasticsearch Serviceを実行するか(最終的にセルフマネージドとしてデプロイした場合でも優れたサンドボックスとなります)、またはElastic Stackのコンポーネントをローカルにダウンロードしてインストールしてください。一般的な可観測性ワークフロー専用に構築されたKibanaの新しいログ、インフラストラクチャー監視、APM、およびアップタイム(6.7で搭載)UIをご確認ください。また、ご質問に関しては遠慮なくディスカッションフォーラムにお知らせください。私たちがお手伝いいたします。