Qu’est-ce que la recherche hybride ?
Deux méthodes de récupération ou plus. Une liste classée.
La recherche hybride est une technique de récupération d'informations qui combine deux méthodes de recherche ou plus (par exemple, la recherche lexicale et la recherche sémantique) en une seule liste classée pour améliorer la pertinence et le rappel. L'association la plus courante combine la recherche lexicale en texte intégral, qui est excellente pour faire correspondre des mots et des phrases exacts, avec la recherche vectorielle sémantique, qui interprète la signification derrière une requête. Le côté lexical ajoute de la précision, et le côté sémantique fournit une compréhension approfondie de l'intention sous-jacente de l'utilisateur.
Ces méthodes sont exécutées ensemble dans une seule requête, puis leurs résultats sont fusionnés en un classement cohérent à l'aide de stratégies de fusion spécialisées. Bien que la combinaison lexicale + sémantique soit la plus populaire, la recherche hybride peut unir d'autres approches — comme la recherche géospatiale + sémantique ou même la recherche texte + image — pour répondre à différents besoins.
Pourquoi la recherche hybride est importante.
La recherche hybride atténue les faiblesses des méthodes de recherche individuelles tout en tirant parti de leurs points forts dans un seul pipeline. L'IA moderne doit traiter diverses modalités : texte, images, audio, logs et autres, et faire le lien entre l'intention et les données. La pertinence devient plus cruciale que jamais. Dans le commerce électronique, par exemple, une expérience de recherche peut réussir si elle aide les utilisateurs à filtrer et affiner rapidement les résultats, mais un agent d'IA a souvent besoin d'une seule réponse très pertinente pour répondre à une question ou effectuer une action. C'est pourquoi la capacité de combiner et d'optimiser les techniques de recherche est essentielle aujourd'hui, car elle alimente non seulement les résultats de recherche traditionnels, mais aussi les agents conversationnels qui fournissent des réponses précises et basées sur des données.
Avant d’approfondir la recherche hybride, examinons rapidement comment la recherche lexicale et la recherche sémantique diffèrent et pourquoi elles se complètent.
Recherche lexicale expliquée
La recherche lexicale est idéale lorsque vous avez des données bien structurées et que les utilisateurs savent ce qu'ils recherchent. Il correspond à des termes exacts, ce qui le rend très précis et explicable, s’appuyant sur un algorithme de score de pertinence (comme BM25F) pour classer les documents selon la fréquence et la rareté des termes de requête. Cette approche offre une notation transparente et permet d'affiner la pertinence grâce à des améliorations de champ, des synonymes et des analyseurs. Parce qu'elle n'a pas de surcharge de modèle, la recherche lexicale est rapide et efficace, avec des filtres et des facettes qui fonctionnent de manière fiable, même à grande échelle, sans ralentissement ni balayage complet de l'index. Il est particulièrement efficace pour les requêtes structurées, les termes rares et le langage spécifique à un domaine.
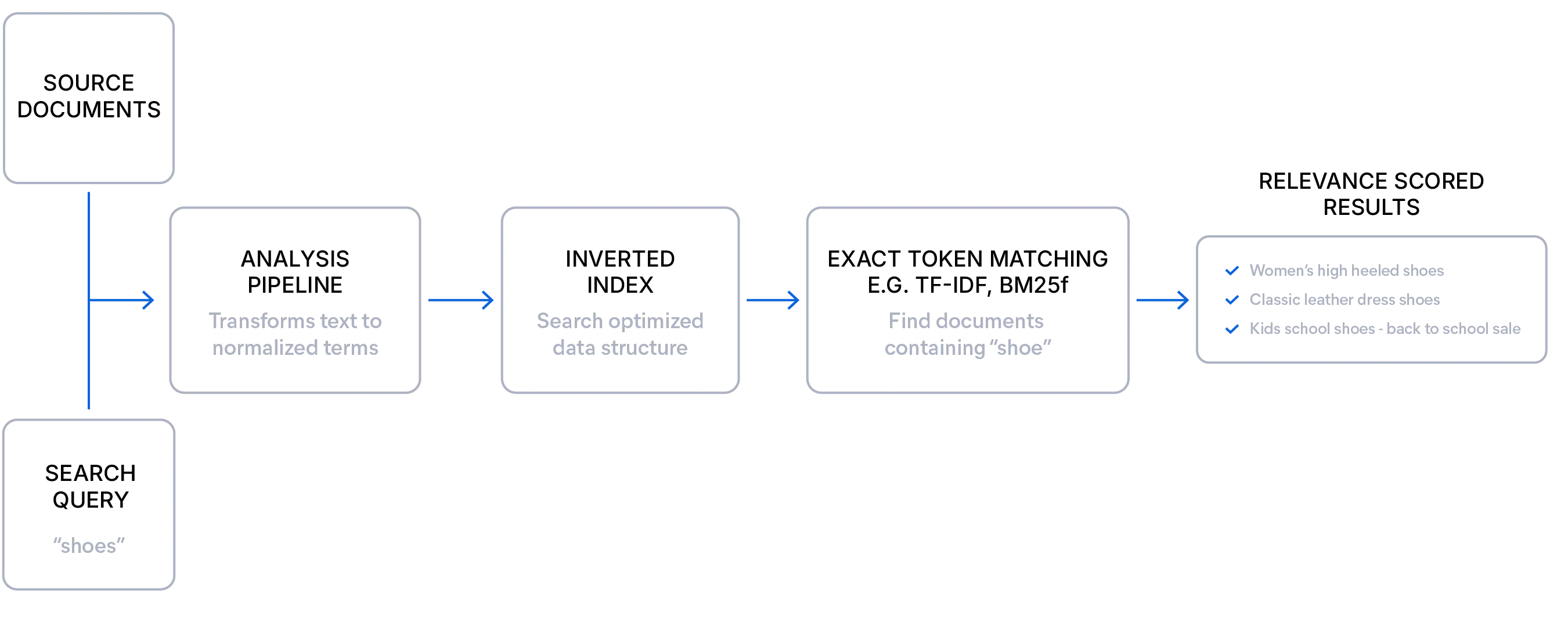
Voici un exemple simple de requête de recherche lexicale :
GET example-index/_search
{
"query": {
"semantic": {
"text": "blue shoes"
}
}
}
Examinons également un exemple similaire de recherche lexicale avec le langage de requête Elasticsearch (ES|QL) pour un blog de cuisine. Le blog contient des recettes avec divers attributs, notamment du contenu textuel, des données catégorielles et des évaluations numériques.
FROM cooking_blog métadonnées _score | WHERE description: « fluffy pancakes » | KEEP title, description, _score | SORT _score DESC | LIMIT 1000
Cette requête recherche dans le champ description des documents contenant soit « fluffy » ou « pancakes » (ou les deux). Par défaut, ES|QL utilise la logique OU entre les termes de recherche, afin de correspondre aux documents contenant l’un des mots spécifiés. Vous pouvez spécifier exactement quels champs inclure dans vos résultats en utilisant la commande KEEP et demander les métadonnées _score pour classer les résultats de recherche en fonction de leur correspondance avec votre requête.
Apprenez-en plus sur la recherche lexicale avec ce tutoriel pratique.
Recherche sémantique expliquée
La recherche sémantique récupère les résultats en fonction de la similarité de sens entre une requête et des documents, plutôt que de simplement correspondre des termes exacts comme dans la recherche lexicale.
Un modèle d'intégration transforme la signification de votre texte ou d'autres médias en une représentation numérique appelée vecteur. Ces vecteurs — une liste de nombres — capturent le contexte et le sujet sous-jacents du texte et sont stockés dans une base vectorielle comme Elasticsearch.
Cela permet au moteur de recherche de trouver des résultats conceptuellement similaires, même lorsqu'ils ne partagent aucun mot exact avec la requête.
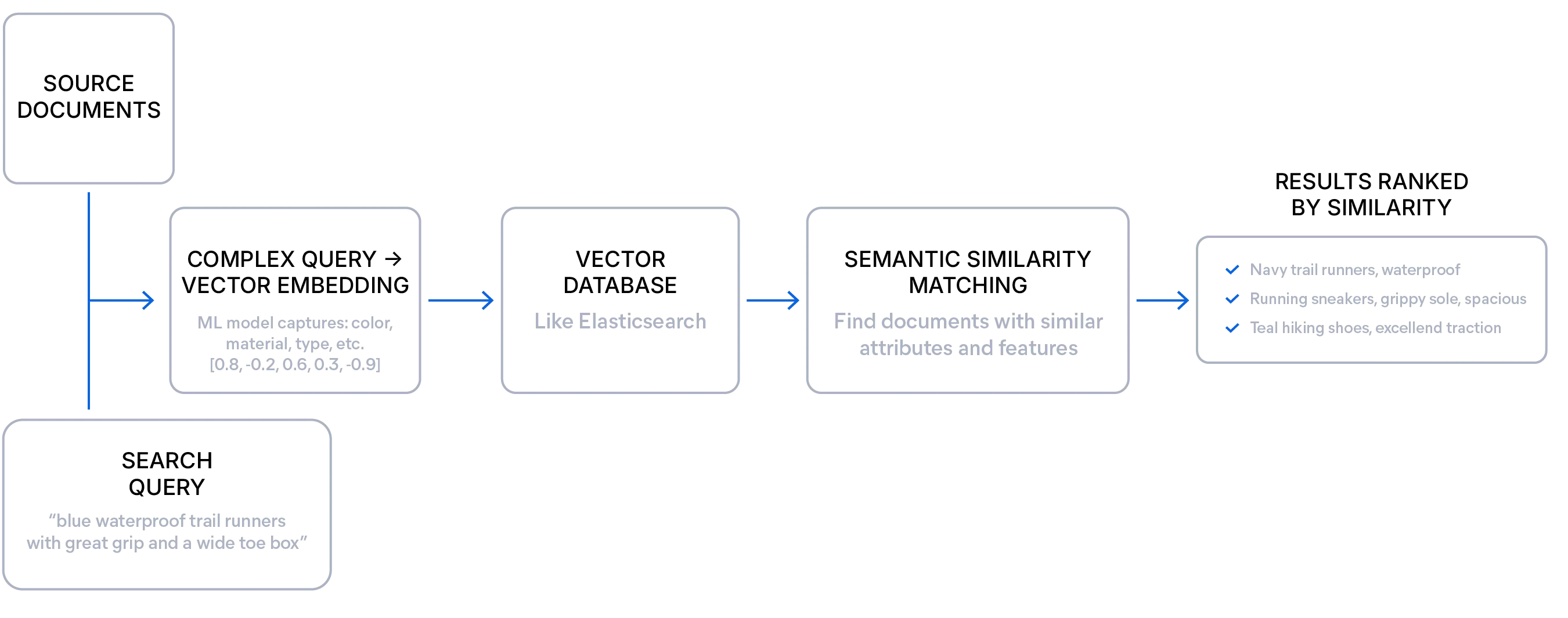
Cette approche est particulièrement utile pour les données non structurées, les requêtes exploratoires et les cas où les utilisateurs ne connaissent pas les termes exacts à utiliser. Les développeurs peuvent tirer parti de la recherche sémantique pour fournir des résultats plus pertinents et gérer des formulations vagues, verbeuses ou ambiguës tout en obtenant les bonnes réponses.
Vous trouverez ci-dessous un exemple de requête de recherche sémantique :
GET example-index/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "blue waterproof trail runners with great grip and a wide toe box"
}
}
}
ES|QL prend en charge la rechercher sémantique lorsque vos mappings incluent des champs du type semantic_text . Une fois que le document a été traité par le modèle sous-jacent exécuté sur le point de terminaison d'inférence, vous pouvez effectuer une recherche sémantique. Voici un exemple de requête en langage naturel sur le champ semantic_description :
FROM cooking_blog métadonnées _score | WHERE semantic_description:"Quels sont quelques repas à base de plantes faciles à préparer mais nutritifs ?" | SORT _score DESC | LIMIT 5
Apprenez-en plus sur la recherche sémantique ou essayez ce tutoriel pratique pour approfondir vos connaissances.
Les algorithmes lexicaux comme BM25F excellent en précision lorsque les termes de la requête correspondent à ceux du document, mais échouent lorsque le contenu pertinent est exprimé différemment. (Par exemple, une requête pour « chaussures de sport » pourrait ne pas trouver de documents contenant uniquement le mot « chaussures » ou « chaussures de trail ».) La recherche vectorielle sémantique, utilisant des embeddings de haute dimension et des algorithmes de voisins approximatifs (ANN) (par exemple, HNSW), récupère des documents conceptuellement similaires indépendamment du chevauchement exact des termes — mais elle peut introduire du bruit si le contexte est ambigu.
Comment fonctionne la recherche hybride ?
Et si vous pouviez tirer le meilleur parti des deux mondes ? Saisissez rechercher hybride. Lorsqu'elle est bien réalisée, la recherche hybride est plus que la somme de ses parties ; elle peut produire des résultats bien meilleurs que la recherche lexicale ou sémantique seule. L'option hybride vous offre les deux, avec une pertinence équilibrée, un meilleur gain cumulatif actualisé normalisé (NDCG) et un rappel plus élevé sans avoir à ajouter un deuxième système de recherche.
Voici un exemple de requête de recherche hybride :
GET example-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"requête": {
"terme": {
"description": "shoes"
}
}
}
},
{
"knn": {
"field": "vector",
"query_vector": [1.25, 2, 3.5],
"k": 50,
"num_candidates": 100
}
}
],
"rank_constant": 20,
"rank_window_size": 50
}
}
}
Vous pouvez également combiner des requêtes full-text et sémantiques dans ES|QL. Dans cet exemple, nous combinons la recherche en texte intégral et sémantique avec des poids personnalisés :
FROM my-index métadonnées _score
| FORK ( WHERE match(text_field:"chaussures") | SORT _score DESC | LIMIT 50)
( WHERE knn(vector, [1,25, 2, 3,5], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 50 ) // k pour knn est dérivé de LIMIT
| FUSE RRF AVEC { "rank_constant": 20 }
| SORT _score DESC
| LIMIT 50
L'exécution d'une requête de recherche hybride implique généralement d'exécuter au moins une recherche lexicale et une recherche sémantique, puis la combinaison de leurs résultats. Le principal défi réside dans la fusion de plusieurs listes classées en un classement unique et cohérent.
Les scores de recherche lexicaux, générés par des algorithmes comme BM25F ou TF-IDF, peuvent être illimités, les valeurs maximales étant influencées par la fréquence des termes et la distribution des documents. En revanche, les scores de recherche sémantique se situent généralement dans une plage fixe, déterminée par la fonction de similarité (par exemple, [0, 2] pour la similarité cosinus).
Pour les fusionner, il faut une méthode de fusion qui maintient la pertinence relative des documents récupérés.
Recherche hybride avec Elasticsearch
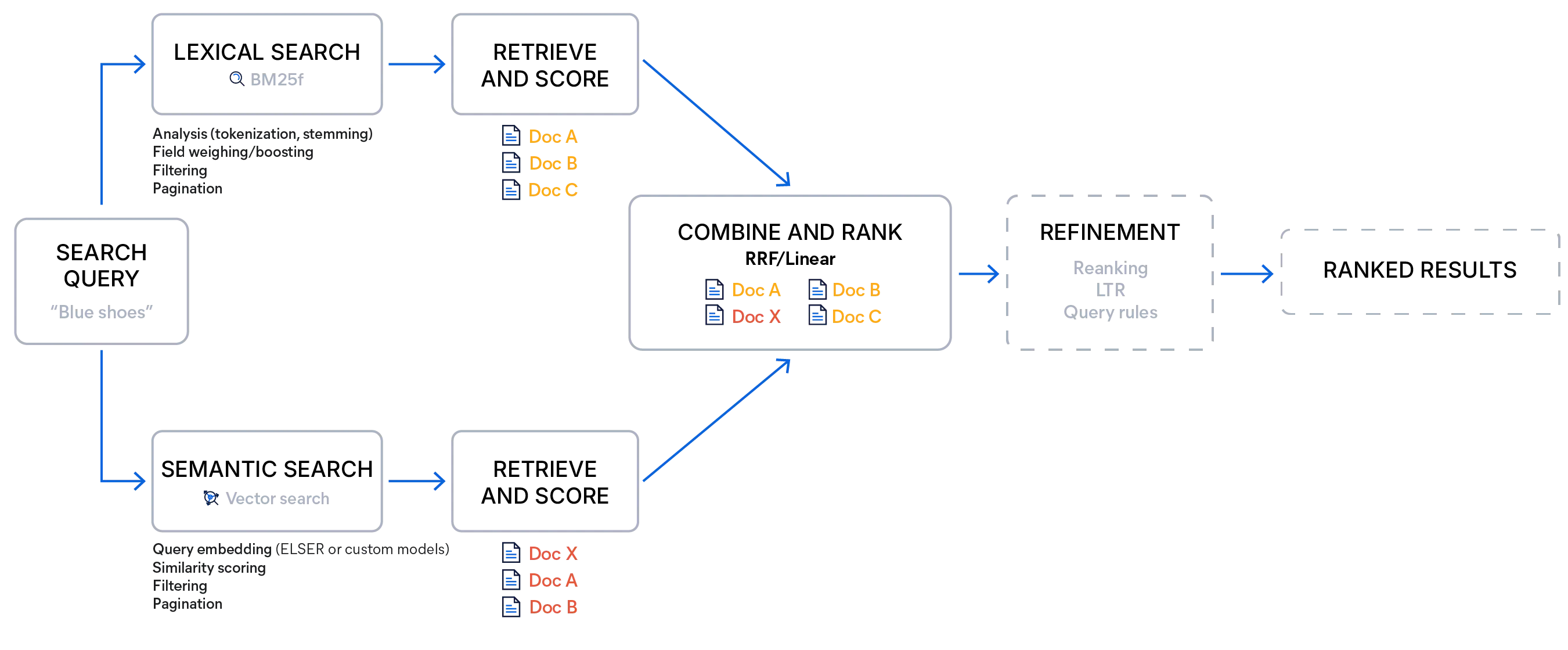
La recherche hybride avec Elasticsearch peut être mise en œuvre en associant une requête par mot-clé standard à une requête vectorielle ou en utilisant un récupérateur — une option de recherche qui exécute plusieurs requêtes de différents types et fusionne leurs résultats en une seule liste classée à l'aide d'une méthode de notation choisie. Cela permet d'activer des pipelines de récupération en plusieurs étapes dans un seul appel de recherche, supprimant ainsi le besoin de multiples requêtes ou d'une logique supplémentaire côté client pour combiner les résultats.
Elasticsearch propose deux méthodes de fusion intégrées : la fusion de rangs réciproques (RRF) et la combinaison linéaire (souvent appelée retriever linéaire dans les API). Les deux visent à établir un classement unifié qui préserve les points forts de chaque retriever, mais ils diffèrent quant à la manière dont ils traitent les scores et au moment où ils sont les plus efficaces.
La fusion de rang réciproque ignore complètement les scores bruts et se concentre sur la hauteur d’apparition d’un document dans chaque liste. Les documents classés en haut de n'importe quelle liste sont fortement récompensés, et les documents apparaissant dans plusieurs listes reçoivent des boosts additifs. La méthode est robuste, car elle contourne les problèmes liés à l'incompatibilité des plages de scores, ne nécessite pratiquement aucun réglage au-delà de la constante de classement et favorise naturellement la diversité des premiers résultats.
Le RRF évalue les documents selon leur rang dans l’ensemble des résultats en utilisant la formule suivante, où k est une constante arbitraire destinée à ajuster l’importance des documents de faible rang :
![]()
RRF est particulièrement utile lorsque les récupérateurs partagent un certain chevauchement dans leurs meilleurs résultats et lorsque les développeurs ont besoin d'une solution prête à l'emploi sans données d'entraînement étiquetées ni d'étalonnage complexe.
La combinaison linéaire, en revanche, fusionne directement les scores réels de chaque retriever. Étant donné que les scores lexicaux et sémantiques fonctionnent sur des échelles très différentes, la normalisation linéaire nécessite un scaling, tel que le scaling min-max, pour amener les scores dans une plage comparable.
Une fois normalisés, les scores sont combinés en utilisant des poids qui représentent l'importance relative de chaque récupérateur. Un poids supérieur à 1 augmente l'influence d'un récupérateur, tandis qu'un poids inférieur à 1 la réduit.
Cette approche permet un contrôle précis : les développeurs peuvent mettre l'accent sur BM25F lorsque la précision des mots-clés est importante, privilégier la similarité sémantique lorsque l'intention et le contexte sont essentiels, ou intégrer des signaux commerciaux ou de personnalisation supplémentaires aux côtés des scores de récupération. Lorsque les poids sont soigneusement calibrés, la combinaison linéaire peut surpasser la RRF en produisant des classements plus précis et prévisibles, mais cela nécessite de l'expérimentation et est sensible au réglage spécifique à l'ensemble de données.
La combinaison linéaire combine les résultats de recherche lexicale et les résultats de recherche sémantique avec des poids respectifs et β (où 0 ≤ α, β), de sorte que :
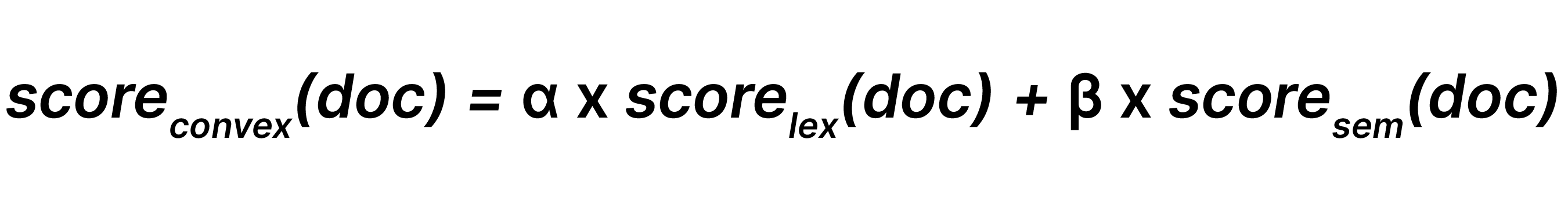
En pratique, le RRF est le meilleur point de départ pour la recherche hybride en raison de sa simplicité et de sa résilience face à des échelles de score incompatibles. Il produit de bons résultats sans réglages approfondis, ce qui le rend idéal pour le prototypage ou lorsque les retrievers se chevauchent. La combinaison linéaire est mieux adaptée lorsque différentes méthodes de récupération renvoient des résultats disjoints ou lorsqu'il est nécessaire d'équilibrer soigneusement les signaux lexicaux, sémantiques et externes. En résumé, la méthode RRF permet une hybridation rapide et fiable dès le départ, tandis que la méthode linéaire offre une plus grande précision potentielle une fois que les poids et les normalisateurs sont adaptés à l'application et aux données.
Récapitulons :
| reciprocal rank fusion | Combinaison linéaire |
|---|---|
Commencez par le RRF pour obtenir rapidement de bons résultats hybrides. |
Passez au mode linéaire lorsque vous êtes prêt(e) à affiner la pertinence. |
En résumé, la combinaison linéaire offre une plus grande précision potentielle lorsqu'elle est réglée, tandis que la méthode RRF est plus facile à mettre en œuvre et fonctionne bien sans données de formation étiquetées.
Essayez ce tutoriel pour en savoir plus sur la recherche hybride.
Comment fonctionne la récupération de la recherche hybride
- Récupération lexicale : BM25F associe les termes de requête aux jetons indexés — idéal pour la précision, les filtres structurés et une notation explicable.
- Recherche sémantique : les vecteurs (denses ou épars) représentent le sens du texte ; la recherche de similitudes permet de trouver des contenus apparentés même en l'absence de mots communs.
- Fusion : Combinez les scores avec le RRF, le blending pondéré ou un retriever linéaire. Les filtres et les boosts s'appliquent de manière cohérente sur les deux récupérations.
| Type de recherche | Fonctionnement | Ce qui se passe | Idéal lorsque |
|---|---|---|---|
| Recherche lexicale Requête : « chaussures de course rouges taille 10 » | Correspond aux mots exacts de la requête avec les mots dans les documents (BM25F, TF-IDF, analyseurs, synonymes). | Permet de trouver des produits dont le titre ou la description contient exactement ces mots-clés (par exemple, « Chaussures de course Nike rouges pour hommes, taille 10 »). | Le client sait exactement ce qu'il veut. Précise, explicable et efficace. |
| Recherche sémantique Requête : « chaussures légères pour le jogging» | Utilise les plongements pour capturer le sens et le contexte, pas seulement les mots-clés. Trouve des résultats conceptuellement liés même si les termes ne correspondent pas. | Retourne les « Baskets de course Adidas Cloudfoam, taille 10 », même si les termes « légères » et « jogging » n'apparaissent pas textuellement. | Les clients décrivent leurs intentions ou utilisent un langage naturel. Traite les requêtes vagues ou descriptives. |
| Recherche hybride Requête : « chaussures habillées confortables pour le bureau » | Combine les résultats lexicaux et sémantiques, puis fusionne les classements (par exemple, via la RRF). | Récupère des correspondances exactes comme « Chaussures habillées en cuir noir, confort optimal » et des articles sémantiquement liés comme « Mocassins avec semelles intérieures rembourrées ». Les deux apparaissent ensemble, classés par ordre de pertinence. | Les requêtes mélangent des termes précis et des intentions. Concilie précision et découverte. |
Recherche hybride : explication des vecteurs denses et épars
La recherche sémantique avec Elasticsearch fonctionne en transformant les requêtes et les documents en représentations vectorielles qui capturent le sens. La recherche hybride combine la récupération lexicale et sémantique, que ce soit en utilisant des modèles denses ou épars.
Vecteurs denses
Les vecteurs denses sont des tableaux de nombres de longueur fixe produits par des modèles comme BERT, où des entrées similaires (telles que chat et chaton) apparaissent proches dans l'espace vectoriel, ce qui les rend puissants pour la correspondance sémantique, les recommandations et la recherche de similarités.
Lorsque le texte est intégré sous forme de vecteur dense, il ressemble à ceci :
[ 0.13586345314979553, -0.6291824579238892, 0.32779985666275024, 0.36690405011177063, ... ]
Chaque dimension contient des informations significatives, rendant les vecteurs denses en données. Un contenu similaire produit des intégrations proches les unes des autres dans l'espace vectoriel.
Dans Elasticsearch, les vecteurs denses sont stockés dans un champ dense_vector et interrogés avec des algorithmes approximatifs de voisins (ANN) comme HNSW. C'est la solution idéale pour saisir le sens sémantique global d'un texte, d'une image ou d'un autre contenu.
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"requête": {
"correspondance" : {
"text_field": "fox"
}
}
}
},
{
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 5,
"num_candidates": 100
}
}
]
}
}
}
Voici un exemple ES|QL :
DE MÉTADONNÉES MY-INDEX _score
| FORK ( OÙ correspond (text_field : « renard ») | TRIER _score DESC | LIMITE 5)
( OÙ knn(image_vector, [0.1, 3.2, 2.1], { "min_candidates" : 100 }) | TRIER _score DESC | LIMITE 5 )
| FUSIBLE
| TRIER _score DESCComme nous pouvons le voir ci-dessus, une requête de recherche hybride utilise simplement le retriever RRF qui combine une requête lexicale (par exemple, une requête de correspondance) effectuée avec un récupérateur standard et une requête de recherche vectorielle spécifiée dans le retriever kNN. Ce que fait cette requête, c'est d'abord récupérer les cinq meilleures correspondances vectorielles au niveau global, puis les combiner avec les correspondances lexicales, et enfin renvoyer les 10 meilleures correspondances. Le récupérateur rrf utilise le classement RRF afin de combiner les correspondances vectorielles et lexicales.
Comprendre les vecteurs épars et ELSER
Les intégrations denses ne sont pas le seul moyen d'effectuer une recherche sémantique.
Les vecteurs épars contiennent principalement des zéros avec quelques valeurs pondérées liées à des termes interprétables, ce qui les rend peu gourmands en ressources, explicables et efficaces dans les scénarios sans données préalables.
Une représentation vectorielle éparse se présente comme suit :
{"f1":1.2,"f2":0.3,… }
Dans Elasticsearch, Elastic Learned Sparse EncodeR (ELSER) est un modèle de traitement du langage naturel (NLP) parcimonieux hors domaine qui développe le texte en termes sémantiquement liés et attribue des poids, permettant des correspondances au-delà des mots-clés exacts tout en préservant l’interprétabilité.
En outre, le champ semantic_text rend la recherche sémantique aussi facile que la recherche textuelle traditionnelle en gérant automatiquement la génération et l'inférence lors de l'ingestion. Vous pouvez indexer les documents comme un champ texte et exécuter une simple requête de correspondance — même entre des index où le type de champ diffère — pour obtenir des correspondances lexicales et sémantiques sans logique de requête supplémentaire. Pour un contrôle avancé, utilisez des requêtes knn ou sparse_vector sur le même champ.
Exemple avec ELSER :
- Préentraînée avec un vocabulaire d'environ 30 000 termes
- Stocké sous la forme de sparse_vector (paires terme/poids)
- Généré automatiquement à l’ingestion avec semantic_text ou à l’index avec le processeur d’ingestion d’inférence
- Interrogés via un index inversé (comme la recherche lexicale), les rendant efficaces, compatibles avec les filtres et explicables
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"requête": {
"correspondance" : {
"text_field": "fox"
}
}
}
},
{
"standard": {
"requête": {
"vecteur creux" : {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
Ensemble, les vecteurs denses et épars offrent de la flexibilité : les vecteurs denses excellent à capturer des significations nuancées, tandis que les vecteurs clairsemés offrent transparence et scalabilité pour la recherche réelle.
Découvrez comment l'extension de texte avec ELSER vous permet d'obtenir de meilleurs résultats :
Vecteurs clairsemés vs. vecteurs denses en pratique
| Vecteurs clairsemés (ELSER) | Vecteurs denses | |
|---|---|---|
| Fonctionnement | Étend le texte en termes sémantiquement liés et pondérés. Chaque dimension correspond à un jeton avec un poids associé. | Encode le contenu (texte, images, etc.) en vecteurs à virgule flottante de longueur fixe. Sens similaire = positions proches dans l'espace vectoriel. |
| Points forts |
|
|
| Exemples de cas d'utilisation |
|
|
| Idéal pour | Lorsque vous avez besoin d'une amélioration sémantique et de transparence, ou lorsque les termes spécifiques à un domaine sont essentiels. | Lorsque vous souhaitez une découverte et une similarité basées sur la signification, et non sur des mots exacts, à travers différents types de données |
Recherche hybride avec des modèles denses et épars
Jusqu'à présent, nous avons vu deux façons différentes d'effectuer une recherche hybride, selon que l'on recherchait dans un espace vectoriel dense ou épars. Nous pouvons mélanger des données denses et des données éparses dans le même index.
POST my-index/_search
{
"_source": faux,
"champs" : [ "champ_texte" ],
"retriever": {
"rrf": {
"retrievers": [
{
"knn": {
"field": "image_vector",
"query_vector": [0.1, 3.2, ..., 2.1],
"k": 5,
"num_candidates": 100
}
},
{
"standard": {
"requête": {
"vecteur creux" : {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
Aller plus loin : Recherche hybride avec des données denses, éparses et BM25F
Cet exemple combine trois récupérateurs et fusionne leurs listes classées avec la RRF :
- BM25F(correspondance sur le texte) : correspondance mots-clés/phrases précises (« snowy mountain »)
- kNN(vecteur_image) : similitude visuelle à l'aide de l'image intégrée fournie(k résultats à partir de num_candidats)
- Sémantique (semantic_text) : correspondances de concepts via l’expansion sémantique de la requête
rank_window_size contrôle le nombre de résultats fusionnés ; rank_constant équilibre les contributions de chaque liste.
OBTENIR my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"requête": {
"correspondre": {
"texte": {
"query": "snowy mountain"
}
}
}
}
},
{
"knn": {
"field": "image_vector",
"query_vector": [
0.01,
0.3,
-0.4
],
"k": 10,
"num_candidates": 100
}
},
{
"standard": {
"requête": {
"sémantique": {
"field": "semantic_text",
"query": "snowy mountain"
}
}
}
}
],
"rank_window_size": 50,
"rank_constant": 60
}
}
}
Examinons également un exemple similaire avec ES|QL :
FROM my-index métadonnées _score
| FORK (WHERE match(text, "montagne enneigée") | SORT _score DESC | LIMIT 50)
(WHERE knn(image_vector, [0.01, 0.3, -0.4], {"min_candidates": 100 }) | SORT _score DESC | LIMIT 50)
(WHERE match(semantic_text, "montagne enneigée") | SORT _score DESC | LIMIT 50)
| FUSE RRF AVEC {"rank_constant": 60 } // 60 est la valeur par défaut de toute façon ?
| SORT _score DESC
| LIMIT 50Conclusion
La recherche hybride réunit la précision de la recherche full-text et la portée contextuelle de la recherche sémantique, offrant des résultats plus précis et pertinents sur une grande variété de contenus. En prenant en charge des modèles denses et clairsemés et en proposant des méthodes de fusion flexibles telles que la combinaison linéaire et la fusion de rangs réciproques, vous pouvez adapter la récupération à votre cas d'utilisation, qu'il s'agisse d'associer directement des requêtes et des vecteurs ou de rationaliser la récupération en plusieurs étapes avec un retriever. Cette flexibilité fait de la recherche hybride une approche puissante pour les requêtes complexes, les données variées et les exigences de pertinence exigeantes.
Pour en savoir plus sur la recherche hybride :
- Consultez cet article de blog sur la recherche hybride : les types de requêtes pris en charge par Elasticsearch et comment les créer.
- Au sujet du contexte : évolution de la recherche hybride et ingénierie du contexte
- Recherche hybride et récupération en plusieurs étapes dans ES|QL
- Les retrievers : la recherche hybride sans prise de tête
Voulez-vous aller au-delà des vecteurs ? Découvrez la recherche hybride intelligente avec des agents LLM dans Elasticsearch.
Prêt à mettre la main à la pâte ? Suivez notre tutoriel sur la recherche hybride pour combiner les résultats en texte intégral et les résultats kNN, ou essayez le tutoriel ES|QL pour rechercher et filtrer à l'aide d'ES|QL.