Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
In our last blog post, we introduced Elastic Learned Sparse Encoder, a model trained for effective zero-shot text retrieval. Elasticsearch
® also has great lexical retrieval capabilities and rich tools for combining the results of different queries. In this blog, we introduce the concept of hybrid retrieval and explore two concrete implementations available in Elasticsearch. In particular, we explore how to improve the performance of Elastic Learned Sparse Encoder by combining it with BM25 using Reciprocal Rank Fusion and Weighted Sum of Scores.
We also discuss experiments we undertook to explore some general research questions. These include how best to parameterize Reciprocal Rank Fusion and how to calibrate Weighted Sum of Scores.
Hybrid retrieval
Despite modern training pipelines producing retriever models with good performance in zero-shot scenarios, it is known that lexical retrievers (such as BM25) and semantic retrievers (like Elastic Learned Sparse Encoder) are somewhat complementary. Specifically, it will improve relevance to combine the results of retrieval methods, if one assumes that the more matches occur between the relevant documents they retrieve than between the irrelevant documents they retrieve.
This hypothesis is plausible for methods using very different mechanisms for retrieval because there are many more irrelevant than relevant documents for most queries and corpuses. If methods retrieve relevant and irrelevant documents independently and uniformly at random, this imbalance means it is much more probable for relevant documents to match than irrelevant ones. We performed some overlap measurements to check this hypothesis between Elastic Learned Sparse Encoder, BM25, and various dense retrievers as shown in Table 1. This provides some rationale for using so-called hybrid search. In the following, we investigate two explicit implementations of hybrid search.

Reciprocal Rank Fusion
Reciprocal Rank Fusion was proposed in this paper. It is easy to use, being fully unsupervised and not even requiring score calibration. It works by ranking a document d with both BM25 and a model, and calculating its score based on the ranking positions for both methods. Documents are sorted by descending score. The score is defined as follows:
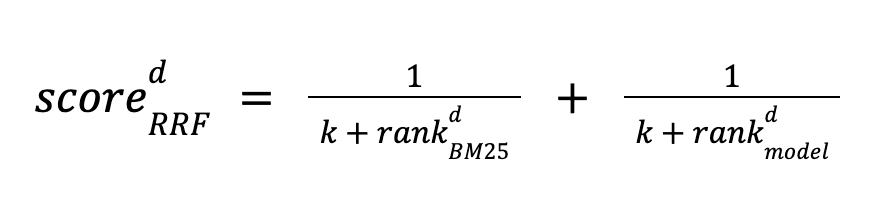
The method uses a constant k to adjust the importance of lowly ranked documents. It is applied to the top N document set retrieved by each method. If a document is missing from this set for either method, that term is set to zero.
The paper that introduces Reciprocal Rank Fusion suggests a value of 60 for k and doesn’t discuss how many documents N to retrieve. Clearly, ranking quality can be affected by increasing N while recall@N is increasing for either method. Qualitatively, the larger k the more important lowly ranked documents are to the final order. However, it is not a priori clear what would be optimal values of k and N for modern lexical semantic hybrid retrieval. Furthermore, we wanted to understand how sensitive the results are to the choice of these parameters and if the optimum generalizes between data sets and models. This is important to have confidence in the method in a zero-shot setting.
To explore these questions, we performed a grid search to maximize the weighted average NDCG@10 for a subset of the BEIR benchmark for a variety of models. We used Elasticsearch for retrieval in this experiment representing each document by a single text field and vector. The BM25 search was performed using a match query and dense retrieval using exact vector search with a script_score query.

Referring to Table 2, we see that for roberta-base-ance-firstp optimal values for k and N are 20 and 1000, respectively. We emphasize that for the majority of individual data sets, the same combination of parameters was optimal. We did the same grid search for distilbert-base-v3 and minilm-l12-v3 with the same conclusion for each model. It is also worth noting that the difference between the best and worst parameter combinations is only about 5%; so the penalty for mis-setting these parameters is relatively small.
We also wanted to see if we could improve the performance of Elastic Learned Sparse Encoder in a zero-shot setting using Reciprocal Rank Fusion. The results on the BEIR benchmark are given in Table 3.

Reciprocal Rank Fusion increases average NDCG@10 by 1.4% over Elastic Learned Sparse Encoder alone and 18% over BM25 alone. Also, importantly the result is either better or similar to BM25 alone for all test data sets. The improved ranking is achieved without the need for model tuning, training data sets, or specific calibration. The only drawback is that currently the query latency is increased as the two queries are performed sequentially in Elasticsearch. This is mitigated by the fact that BM25 retrieval is typically faster than semantic retrieval.
Our findings suggest that Reciprocal Rank Fusion can be safely used as an effective “plug and play” strategy. Furthermore, it is worth reviewing the quality of results one obtains with BM25, Elastic Learned Sparse Encoder and their rank fusion on your own data. If one were to select the best performing approach on each individual data set in the BEIR suite, the increase in average NDCG@10 is, respectively, 3% and 20% over Elastic Learned Sparse Encoder and BM25 alone.
As part of this work, we also performed some simple query classification to distinguish keyword and natural question searches. This was to try to understand the mechanisms that lead to a given method performing best. So far, we don’t have a clear explanation for this and plan to explore this further. However, we did find that hybrid search performs strongly when both methods have similar overall accuracy.
Finally, Reciprocal Rank Fusion can be used with more than two methods or could be used to combine rankings from different fields. So far, we haven’t explored this direction.
Weighted Sum of Scores
Another way to do hybrid retrieval supported by Elasticsearch is to combine BM25 scores and model scores using a linear function. This approach was studied in this paper, which showed it to be more effective than Reciprocal Rank Fusion when well calibrated. We explored hybrid search via a convex linear combination of scores defined as follows:
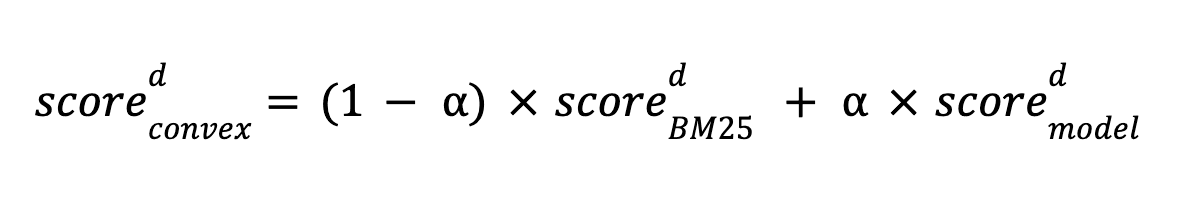
where α is the model score weight and is between 0 and 1.
Ideal calibration of linear combination is not straightforward, as it requires annotations similar to those used for fine-tuning a model. Given a set of queries and associated relevant documents, we can use any optimization method to find the optimal combination for retrieving those documents. In our experiments, we used BEIR data sets and Bayesian optimization to find the optimal combination, optimizing for NDCG@10. In theory, the ratio of score scales can be incorporated into the value learned for α. However, in the following experiments, we normalized BM25 scores and Elastic Learned Sparse Encoder scores per data set using min-max normalization, calculating the minimum and maximum from the top 1,000 scores for some representative queries on each data set. The hope was that with normalized scores the optimal value of transfers. We didn’t find evidence for this, but it is much more consistent and so normalization does likely improve the robustness of the calibration.
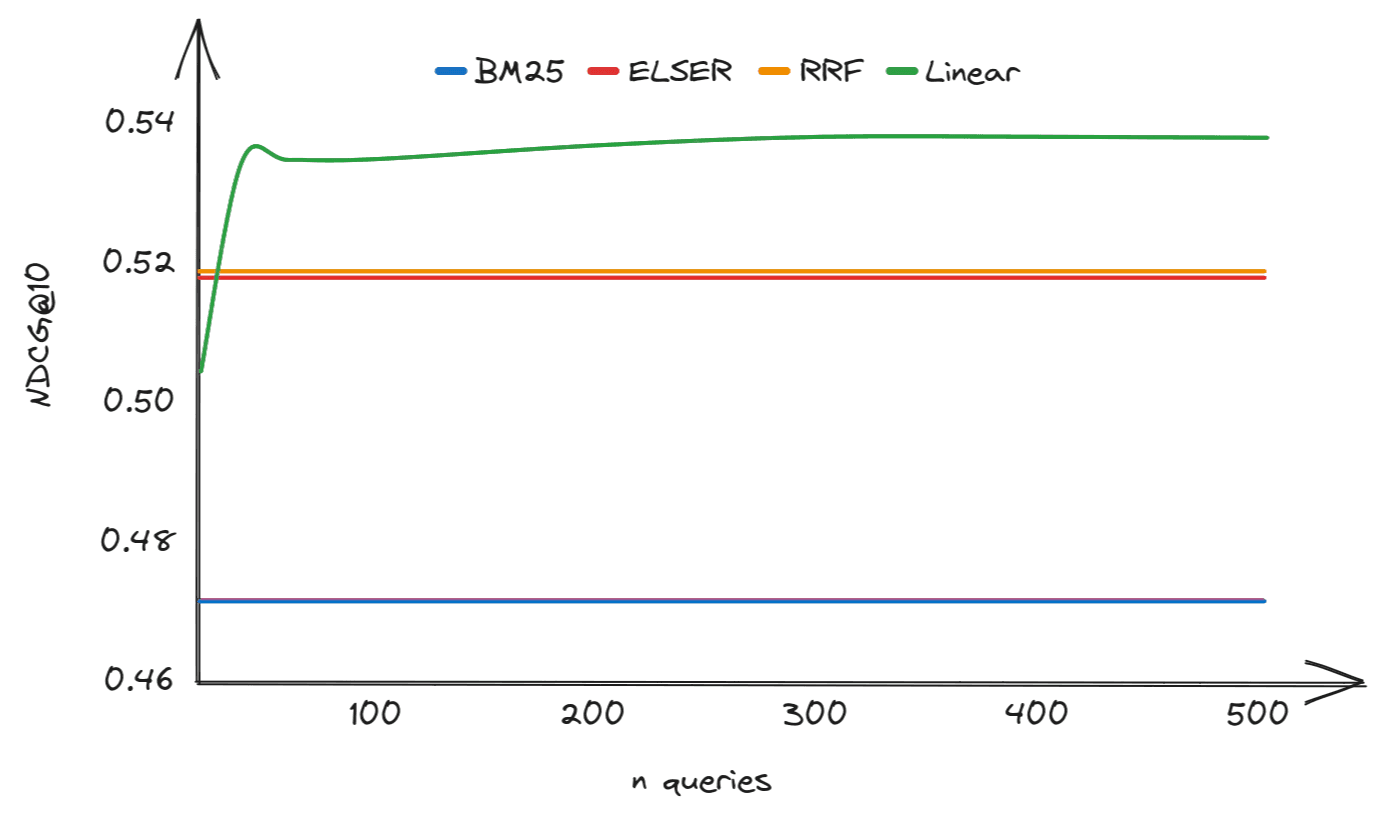
Obtaining annotations is expensive, so it is useful to know how much data to gather to be confident of beating Reciprocal Rank Fusion (RRF). Figure 1 shows the NDCG@10 for a linear combination of BM25 and Elastic Learned Sparse Encoder scores as a function of the number of annotated queries for the ArguAna data set. For reference, the BM25, Elastic Learned Sparse Encoder and RRF NDCG@10 are also shown. This sort of curve is typical across data sets. In our experiments, we found that it was possible to outperform RRF with approximately 40 annotated queries, although the exact threshold varied slightly from one data set to another.
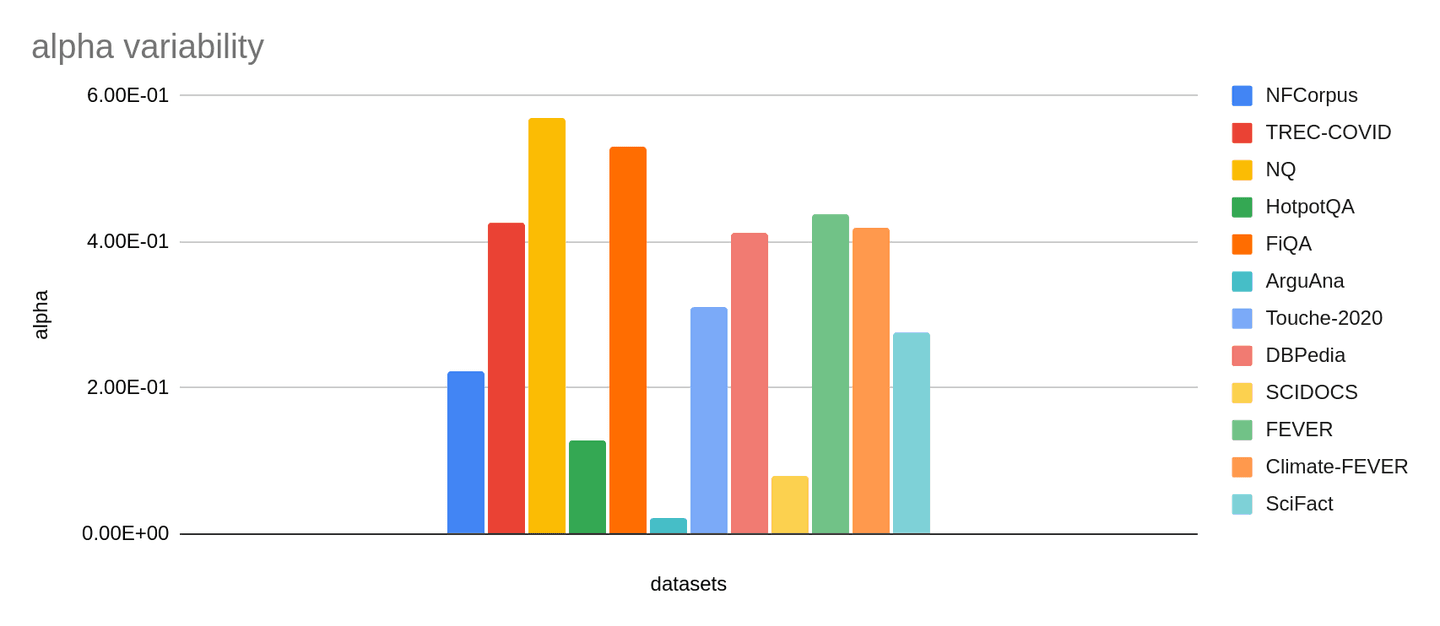
We also observed that the optimal weight varies significantly both across different data sets (see Figure 2) and also for different retrieval models. This is the case even after normalizing scores. One might expect this because the optimal combination will depend on how well the individual methods perform on a given data set.
To explore the possibility of a zero-shot parameterisation, we experimented with choosing a single weight α for all data sets in our benchmark set. Although we used the same supervised approach to do this, this time choosing the weight to optimize average NDCG@10 for the full suite of data sets, we feel that there is enough variation between data sets that our findings may be representative of zero-shot performance.
In summary, this approach yields better average NDCG@10 than RRF. However, we also found the results were less consistent than RRF and we stress that the optimal weight is model specific. For this reason, we feel less confident the approach transfers to new settings even when calibrated for a specific model. In our view, linear combination is not a “plug and play” approach. Instead, we believe it is important to carefully evaluate the performance of the combination on your own data set to determine the optimal settings. However, as we will see below, if it is well calibrated it yields very good results.
Normalization is essential for comparing scores between different data sets and models, as scores can vary a lot without it. It is not always easy to do, especially for Okapi BM25, where the range of scores is unknown until queries are made. Dense model scores are easier to normalize, as their vectors can be normalized. However, it is worth noting that some dense models are trained without normalization and may perform better with dot products.
Elastic Learned Sparse Encoder is trained to replicate cross-encoder score margins. We typically see it produce scores in the range 0 to 20, although this is not guaranteed. In general, a query history and their top N document scores can be used to approximate the distribution and normalize any scoring function with minimum and maximum estimates. We note that the non-linear normalization could lead to improved linear combination, for example if there are score outliers, although we didn’t test this.
As for Reciprocal Rank Fusion, we wanted to understand the accuracy of a linear combination of BM25 and Elastic Learned Sparse Encoder — this time, though, in the best possible scenario. In this scenario, we optimize one weight α per data set to obtain the ideal NDCG@10 using linear combination. We used 300 queries to calibrate — we found this was sufficient to estimate the optimal weight for all data sets. In production, this scenario is realistically difficult to achieve because it needs both accurate min-max normalization and a representative annotated data set to adjust the weight. This would also need to be refreshed if the documents and queries drift significantly. Nonetheless, bounding the best case performance is still useful to have a sense of whether the effort might be worthwhile. The results are displayed in Table 4. This approach gives a 6% improvement in average NDCG@10 over Elastic Learned Sparse Encoder alone and 24% improvement over BM25 alone.

Conclusion
We showed it is possible to combine different retrieval approaches to improve their performance and in particular lexical and semantic retrieval complement one another. One approach we explored was Reciprocal Rank Fusion. This is a simple method that often yields good results without requiring any annotations nor prior knowledge of the score distribution. Furthermore, we found its performance characteristics were remarkably stable across models and data sets, so we feel confident that the results we observed will generalize to other data sets.
Another approach is Weighted Sum of Scores, which is more difficult to set up, but in our experiments yielded very good ranking with the right setup. To use this approach, scores should be normalized, which for BM25 requires score distributions for typical queries, furthermore some annotated data should be used for training the method weights.
In our final planned blog in this series, we will introduce the work we have been doing around inference and index performance as we move toward GA for the text_expansion feature.
- Part 1: Steps to improve search relevance
- Part 2: Benchmarking passage retrieval
- Part 3 : Introducing Elastic Learned Sparse Encoder, our new retrieval model
- Part 4: Hybrid retrieval
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Related Content

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

July 6, 2026
Who grades the grader? LLM-as-a-Judge inside Elasticsearch Workflows
Find out if your RAG agent is ready to ship. Score it on correctness, faithfulness and retrieval quality using only Elasticsearch Workflows and two Claude models.

June 15, 2026
Your search index is already an agent memory system: Persistent agent memory for Claude Code with Elasticsearch
Give your AI agent persistent cross-session memory using Elasticsearch: Hybrid recall, a knowledge graph, and cross-device handoffs. Three commands to install.

June 15, 2026
Your FAQ bot doesn't need a PhD: LLM query routing with Elastic Workflows
Route LLM queries by complexity using Elasticsearch search metadata: Mistral Small for FAQ questions, Claude Sonnet for multi-source synthesis.