Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
Building AI search applications often involves coordinating multiple tasks, data retrieval, and data extraction into a seamless workflow. LangGraph simplifies this process by letting developers orchestrate AI agents using a node-based structure. In this article, we are going to build a financial solution using LangGraph.js
What is LangGraph
LangGraph is a framework for building AI agents and orchestrating them in a workflow to create AI-assisted applications. LangGraph has a node architecture where we can declare functions that represent tasks and assign them as nodes of the workflow. The result of multiple nodes interacting together will be a graph. LangGraph is part of the broader LangChain ecosystem, which provides tools for building modular and composable AI systems.
For a better understanding of why LangGraph is useful, let's solve a problematic situation using it.
Overview of the solution
In a venture capital firm, investors have access to a large database with many filtering options, but when one wants to combine criteria, it becomes hard and slow. This may cause some relevant startups not to be found for investment. It results in spending a lot of hours trying to identify the best candidates, or even losing opportunities.
With LangGraph and Elasticsearch, we can perform filtered searches using natural language, eliminating the need for users to manually build complex requests with dozens of filters. To make it more flexible, the workflow automatically decides based on the user's input between two query types:
- Investment-focused queries: These target financial and funding aspects of startups, such as funding rounds, valuation, or revenue. Example: “Find startups with Series A or Series B funding between $8M–$25M and monthly revenue above $500K.”
- Market-focused queries: These concentrate on industry verticals, geographic markets, or business models, helping identify opportunities in specific sectors or regions. Example: “Find fintech and healthcare startups in San Francisco, New York, or Boston.”
To keep the queries robust, we will make the LLM build search templates instead of full DSL queries. This way, you always get the query you want, and the LLM just has to fill in the blanks and not carry the responsibility of building the query you need every time.
What you need to get started
- Elasticsearch APIKey
- OpenAPI APIKey
- Node 18 or newer
Step-by-step instructions
In this section, let’s see how the app will look. For that, we will use TypeScript, a superset of JavaScript that adds static types to make the code more reliable, easier to maintain, and safer by catching errors early while remaining fully compatible with existing JavaScript.
The nodes' flow will look as follows:
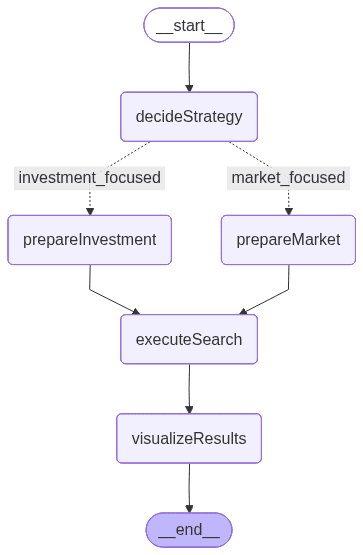
The image above is generated by LangGraph and represents the workflow that defines the execution order and conditional logic between nodes:
- decideStrategy: Uses an LLM to analyze the user’s query and decide between two specialized search strategies, investment-focused or market-focused.
- prepareInvestmentSearch: Extracts filter values from the query and builds a predefined template emphasizing financial and funding-related parameters.
- prepareMarketSearch: Extracts filter values as well, but dynamically builds parameters emphasizing market, industry, and geographic context.
- executeSearch: Sends the constructed query to Elasticsearch using a search template and retrieves the matching startup documents.
- visualizeResults: Formats the final results into a clear, readable summary showing key startup attributes such as funding, industry, and revenue.
This flow includes a conditional branching, working as an “if” statement, that determines whether to use the investment or market search path based on the user’s input. This decision logic, driven by the LLM, makes the workflow adaptive and context-aware, a mechanism we’ll explore in more detail in the next sections.
LangGraph State
Before seeing each node individually, we need to understand how the nodes communicate and share data. For that, LangGraph enables us to define the workflow state. This defines the shared state that will be passed between nodes.
The state acts as a shared container that stores intermediate data throughout the workflow: it begins with the user’s natural language query, then keeps the selected search strategy, the prepared parameters for Elasticsearch, the retrieved search results, and finally the formatted output.
This structure allows every node to read and update the state, ensuring a consistent flow of information from the user input to the final visualization.
Set up the application
All the code on this section can be found in the elasticsearch-labs repository.
Open a terminal in the folder where the app will be located and Initialize a Node.js application with the command:
Now we can install the necessary dependencies for this project:
@elastic/elasticsearch: Helps us handle Elasticsearch requests such as data ingestion and retrieval.@langchain/langgraph: JS dependency to provide all LangGraph tools.@langchain/openai: OpenAI LLM client for LangChain.- @langchain/core: Provides the fundamental building blocks for LangChain apps, including prompt templates.
dotenv: Necessary dependency to use environment variables in JavaScript.zod: Dependency to type data.
@types/node tsx typescript allows us to write and run TypeScript code.
Now create the following files:
elasticsearchSetup.ts: Will create the index mappings, load the data set from a JSON file, and ingest the data to Elasticsearch.main.ts: will include the LangGraph application..env: file to store the environment variables
In the .env file, let’s add the following environment variables:
The OpenAPI APIKey will not be used directly on the code; instead, it will be used internally by the library @langchain/openai.
All the logic regarding mappings creation, search templates creation, and dataset ingestion can be found in the elasticsearchSetup.ts file. In the next steps, we will be focusing on the main.ts file. Also, you can check the dataset to better understand how the data looks in the dataset.json.
LangGraph app
In the main.ts file, let’s import some necessary dependencies to consolidate the LangGraph application. In this file, you must also include the node functions and the state declaration. The graph declaration will be done in a main method in the next steps. The elasticsearchSetup.ts file will contain Elasticsearch helpers we are going to use within the nodes in further steps.
As mentioned before, the LLM client will be used to generate the Elasticsearch search template parameters based on the user's question.
The method above generates the graph image in png format and uses the Mermaid.INK API behind the scenes. This is useful if you want to see how the app nodes interact together with a styled visualization.
LangGraph nodes
Now lets see each node detailed:
decideSearchStrategy node
The decideSearchStrategy node analyzes the user input and determines whether to perform an investment focused or market focused search. It uses an LLM with a structured output schema (defined with Zod) to classify the query type. Before making the decision, it retrieves the available filters from the index using an aggregation, ensuring the model has up to date context about industries, locations, and funding data.
To extract the filters possible values and send them to the LLM, let’s use an aggregation query to retrieve them directly from the Elasticsearch index. This logic is allocated in a method called getAvailableFilters:
With the aggregation query above, we have the following results:
See all the results here.
For both strategies, we are going to use hybrid search to detect both the structured part of the question (filters) and the more subjective parts (semantics). Here is an example of both queries using search templates:
Look at queries detailed in the elasticsearchSetup.ts file. In the following node, it will be decided which of the two queries will be used:
prepareInvestmentSearch and prepareMarketSearch nodes
Both nodes use a shared helper function, extractFilterValues, which leverages the LLM to identify relevant filters mentioned in the user’s input, such as industry, location, funding stage, business model, etc. We are using this schema to build our search template.
Depending on the detected intent, the workflow selects one of two paths:
prepareInvestmentSearch: builds financially oriented search parameters, including funding stage, funding amount, investor, and renew information. You can find the entire query template in the elasticsearchSetup.ts file:
prepareMarketSearch: creates market-driven parameters focused on industries, geographies, and business models. See the entire query in the elasticsearchSetup.ts file:
executeSearch node
This node takes the generated search parameters from the state and sends them to Elasticsearch first, using the _render API to visualize the query for debugging purposes, and then sends a request to retrieve the results.
visualizeResults node
Finally, this node displays the Elasticsearch results.
Programmatically, the entire graph looks like this:
As you can see, we have a conditional edge where the app decides which “path” or node will run next. This feature is useful when workflows need branching logic, such as choosing between multiple tools or including a human-in-the-loop step.
With the core LangGraph features understood, we can set up the application where the code will be running:
Put everything together in a main method, here we declare the graph with all the elements under the variable workflow:
The query variable simulates the user input entered in a hypothetical search bar:

From the natural language phrase “Find startups with Series A or Series B funding between $8M-$25M and monthly revenue above $500K”, all the filters will be extracted.
Finally, invoke the main method:
Results
For the input sent, the application chooses the investment-focused path, and as a result, we can see the Elasticsearch query generated by the LangGraph workflow, which extracts the values and ranges from the user input. We can also see the query sent to Elasticsearch with the extracted values applied, and finally, the results formatted by the visualizeResults node with the results.
Now let's test the market-focused node using the query “Find fintech and healthcare startups in San Francisco, New York, or Boston”:
Learnings
During the writing process I learned:
- We must show the LLM the exact values of filters, otherwise we rely on the user typing the exact values of things. For low cardinality this approach is fine, but when the cardinality is high we need some mechanism to filter results out
- Using search templates makes the results much more consistent than letting the LLMwrite the Elasticsearch query, and it's also faster
- Conditional edges are a powerful mechanism to build applications with multiple variants and branching paths.
- Structured output is extremely useful when generating information with LLMs because it enforces predictable, type-safe responses. This improves reliability and reduces prompt misinterpretations.
Combining semantic and structured search through hybrid retrieval produces better and more relevant results, balancing precision and context understanding.
Conclusion
In this example, we combine LangGraph.js with Elasticsearch to create a dynamic workflow capable of interpreting natural language queries and deciding between financial or market-focused search strategies. This approach reduces the complexity of crafting manual queries while improving flexibility and accuracy for venture capital analysts.
Related Content

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

June 30, 2026
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.
June 26, 2026
Talk to your Elasticsearch data: building a real-time voice agent with Google ADK and MCP in 3 components
Wire Google ADK's real-time voice streaming to your Elasticsearch data via Agent Builder's built-in MCP server; no custom integration code required.

June 22, 2026
Your data analyst doesn't need SQL: wiring Elastic Agent Builder to AWS AgentCore for natural-language Elasticsearch queries
Wire plain-English questions to your Elasticsearch data using Elastic Agent Builder MCP, AWS Bedrock AgentCore and the Strands SDK. Python code included.