Get hands-on with Elasticsearch: Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
In Elasticsearch 9.2, we’ve introduced the ability to do dense vector search and hybrid search in Elasticsearch Query Language (ES|QL). This continues our investment in making ES|QL the best search language to solve modern search use cases.
Multistage retrieval: The challenge of modern search
Modern search has evolved beyond simple keyword matching. Today's search applications need to understand intent, handle natural language, and combine multiple ranking signals to deliver the best results.
Retrieval of the most relevant results happens in multiple stages, with each stage gradually refining the result set. This wasn’t the case in the past, where most use cases would require one or two stages of retrieval: an initial query to get results and a potential rescoring phase.
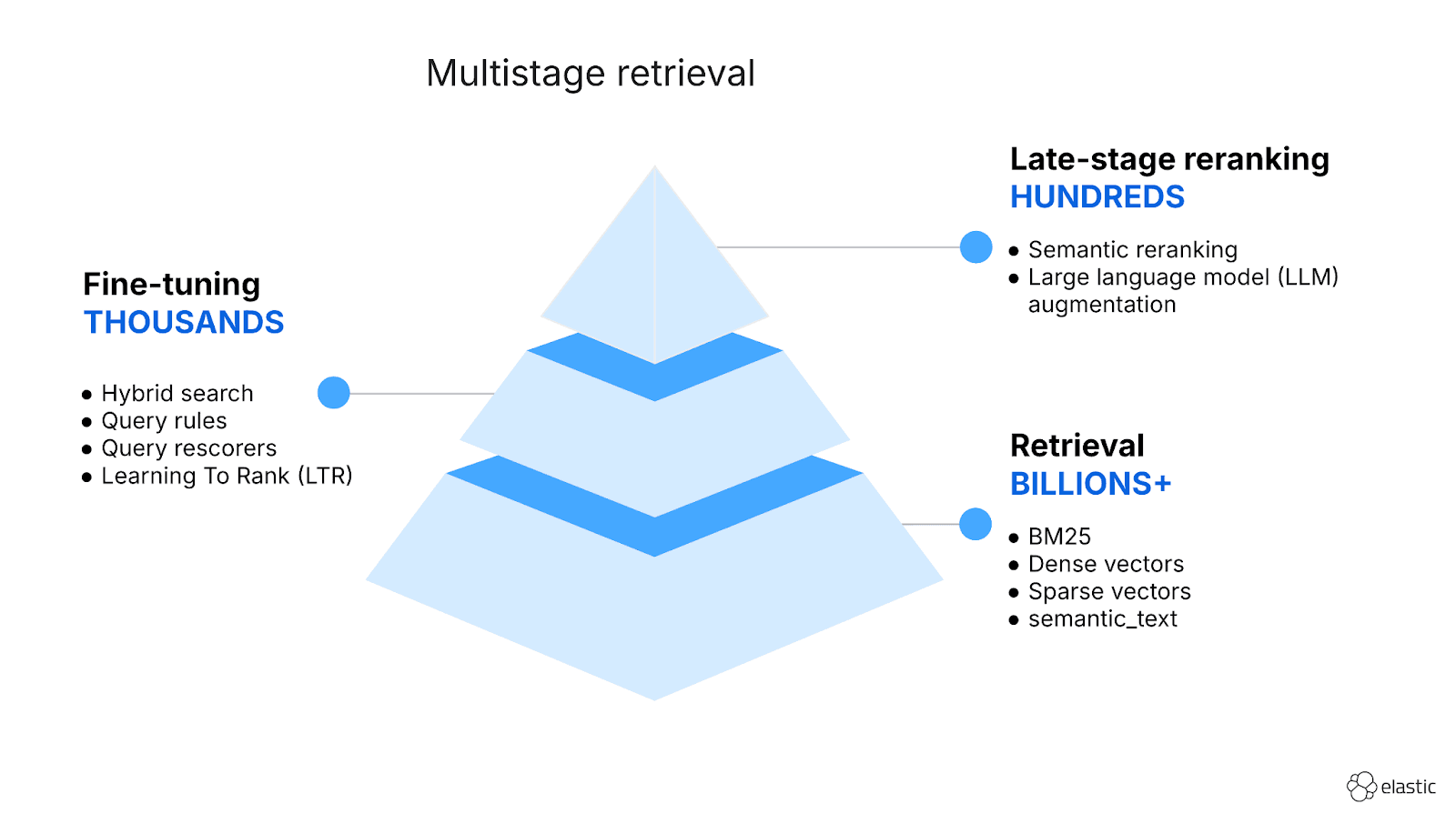
We start with an initial retrieval, where we cast a wide net to gather results that are relevant to our query. Since we need to sieve through all the data, we should use techniques that return results fast, even when we index billions of documents.
We therefore employ trusted techniques, such as lexical search that Elasticsearch has supported and optimized since the beginning, or vector search, where Elasticsearch excels in speed and accuracy.
Lexical search using BM25 is quite fast and best at exact term matching or phrase matching, and vector or semantic search is better suited for handling natural language queries. Hybrid search combines lexical and vector search results to bring the best from both. The challenge that hybrid search solves is that vector and lexical search have completely different and incompatible scoring functions which produce values in different intervals, following different distributions. A vector search score close to 1 can mean a very close match, but it doesn’t mean the same for lexical search. Hybrid search methods, such as reciprocal rank fusion (RRF) and linear combination of scores, assign new scores that blend the original scores from lexical and vector search.
After hybrid search, we can employ techniques such as semantic reranking and Learning To Rank (LTR), which use specialized machine learning models to rerank the result.
With our most relevant results, we can use large language models (LLMs) to further enrich our response or pass the most relevant results as context to LLMs in agentic workflows in tools such as Elastic Agent Builder.
ES|QL is able to handle all these stages of retrieval. By design, ES|QL is a piped language, where each command transforms the input and sends the output to the next command. Each stage of retrieval is represented by one or more consecutive ES|QL commands. In this article, we show how each stage is supported in ES|QL.
Vector search
In Elasticsearch 9.2, we introduced tech preview support for dense vector search in ES|QL. This is as simple as calling the knn function, which only requires a dense_vector field and a query vector:
This query executes an approximate nearest neighbor search, retrieving 100 documents that are the most similar to the query_vector.
Hybrid search: Reciprocal rank fusion
In Elasticsearch 9.2, we introduced support for hybrid search using RRF and linear combination of results in ES|QL.
This allows combining vector search and lexical search results into a single result set.
To achieve this in ES|QL, we need to use the FORK and FUSE commands. FORK runs multiple branches of execution, and FUSE merges the results and assigns new relevance scores using RRF or linear combination.
In the following example, we use FORK to run two separate branches, where one is doing a lexical search using the match function, while the other is doing a vector search using the knn function. We then merge the results together using FUSE:
Let's decompose the query to better understand the execution model and first look at the output of the FORK command:
The FORK commands outputs the results from both branches and adds a _fork discriminator column:
| _id | title | _score | _fork |
|---|---|---|---|
| 4001 | The Hobbit | 0.88 | fork1 |
| 3999 | The Fellowship of the Ring | 0.88 | fork1 |
| 4005 | The Two Towers | 0.86 | fork1 |
| 4006 | The Return of the King | 0.84 | fork1 |
| 4123 | The Silmarillion | 0.78 | fork1 |
| 4144 | The Children of Húrin | 0.79 | fork1 |
| 4001 | The Hobbit | 4.55 | fork2 |
| 3999 | The Fellowship of the Ring | 4.25 | fork2 |
| 4123 | The Silmarillion | 4.11 | fork2 |
| 4005 | The Two Towers | 3.8 | fork2 |
| 4006 | The Return of the King | 4.1 | fork2 |
As you’ll notice, certain documents appear twice, which is why we then use FUSE to merge rows that represent the same documents and assign new relevance scores. FUSE is executed in two stages:
- For each row,
FUSEassigns a new relevance score, depending on the hybrid search algorithm that is being used. - Rows that represent the same document are merged together, and a new score is computed.
In our example, we’re using RRF. As a first step, FUSE assigns a new score to each row using the RRF formula:
Where the rank_constant takes a default value of 60 and rank(doc) represents the position of the document in the result set.
In the first phase, our results become:
| _id | title | _score | _fork |
|---|---|---|---|
| 4001 | The Hobbit | 1 / (60 + 1) = 0.01639 | fork1 |
| 3999 | The Fellowship of the Ring | 1 / (60 + 2) = 0.01613 | fork1 |
| 4005 | The Two Towers | 1 / (60 + 3) = 0.01587 | fork1 |
| 4006 | The Return of the King | 1 / (60 + 4) = 0.01563 | fork1 |
| 4123 | The Silmarillion | 1 / (60 + 5) = 0.01538 | fork1 |
| 4144 | The Children of Húrin | 1 / (60 + 6) = 0.01515 | fork1 |
| 4001 | The Hobbit | 1 / (60 + 1) = 0.01639 | fork2 |
| 3999 | The Fellowship of the Ring | 1 / (60 + 2) = 0.01613 | fork2 |
| 4123 | The Silmarillion | 1 / (60 + 3) = 0.01587 | fork2 |
| 4005 | The Two Towers | 1 / (60 + 4) = 0.01563 | fork2 |
| 4006 | The Return of the King | 1 / (60 + 5) = 0.01538 | fork2 |
Then the rows are merged together and a new score is assigned. Since a SORT _score DESC follows the FUSE command, the final results are:
| _id | title | _score |
|---|---|---|
| 4001 | The Hobbit | 0.01639 + 0.01639 = 0.03279 |
| 3999 | The Fellowship of the Ring | 0.01613 + 0.01613 = 0.03226 |
| 4005 | The Two Towers | 0.01587 + 0.01563 = 0.0315 |
| 4123 | The Silmarillion | 0.01538 + 0.01587 = 0.03125 |
| 4006 | The Return of the King | 0.01563 + 0.01538 = 0.03101 |
| 4144 | The Children of Húrin | 0.01515 |
Hybrid search: Linear combination of scores
Reciprocal rank fusion is the simplest way to do hybrid search, but it isn’t the only hybrid search method that we support in ES|QL.
In the following example, we use FUSE to combine lexical and semantic search results using linear combination of scores:
Let's first decompose the query and take a look at the input of the FUSE command when we only run the FORK command.
Notice that we use the match function, which is able to not only query lexical fields, such as text or keyword, but also semantic_text fields.
The first FORK branch executes a semantic query by querying a semantic_text field, while the second one executes a lexical query:
The output of the FORK command can contain rows with the same _id and _index values representing the same Elasticsearch document:
| _id | title | _score | _fork |
|---|---|---|---|
| 4001 | The Hobbit | 0.88 | fork1 |
| 3999 | The Fellowship of the Ring | 0.88 | fork1 |
| 4005 | The Two Towers | 0.86 | fork1 |
| 4006 | The Return of the King | 0.84 | fork1 |
| 4123 | The Silmarillion | 0.78 | fork1 |
| 4144 | The Children of Húrin | 0.79 | fork1 |
| 4001 | The Hobbit | 4.55 | fork2 |
| 3999 | The Fellowship of the Ring | 4.25 | fork2 |
| 4123 | The Silmarillion | 4.11 | fork2 |
| 4005 | The Two Towers | 3.8 | fork2 |
| 4006 | The Return of the King | 4.1 | fork2 |
In the next step, we use FUSE to merge rows that have the same _id and _index values, and assign new relevance scores.
The new score is a linear combination of the scores the row had in each FORK branch:
Here, _score1 and _score2 represent the score a document has in the first FORK branch and the second FORK branch, respectively.
Notice that we also apply custom weights, giving more weight to the semantic score over the lexical one, resulting in this set of documents:
| _id | title | _score |
|---|---|---|
| 4001 | The Hobbit | 0.7 * 0.88 + 0.3 * 4.55 = 1.981 |
| 3999 | The Fellowship of the Ring | 0.7 * 0.88 + 0.3 * 4.25 = 1.891 |
| 4006 | The Return of the King | 0.7 * 0.84 + 0.3 * 4.1 = 1.818 |
| 4123 | The Silmarillion | 0.7 * 0.78 + 0.3 * 4.11 = 1.779 |
| 4005 | The Two Towers | 0.7 * 0.86 + 0.3 * 3.8 = 1.742 |
| 4144 | The Children of Húrin | 0.7 * 0.79 + 0.3 * 0 = 0.553 |
One challenge is that the semantic and lexical scores can be incompatible to apply the linear combination, since they can follow completely different distributions. To mitigate this, we first need to normalize the scores, employing score normalization methods, such as minmax. This ensures that the scores from each FORK branch are first normalized to take values between 0 and 1, before applying the linear combination formula.
To achieve this with FUSE, we need to specify the normalizer option:
Semantic reranking
At this stage, after hybrid search, we should be left with the most relevant documents. We can now use semantic reranking to reorder the results using the RERANK command. By default, RERANK uses the latest Elastic semantic reranking machine learning model, so no additional configuration is needed:
We now have our best results, sorted by relevance.
One key feature that sets the RERANK command apart from other products that offer semantic reranking integrations is that it doesn’t require the input to represent a mapped field from an index. RERANK only expects an expression that evaluates to a string value, making it possible to do semantic reranking using multiple fields:
LLM completions
Now we have a set of highly relevant, reranked results.
At this stage, you might simply decide to return the results back to your application or you might want to further enhance your results using LLM completions.
If you’re using ES|QL as part of a retrieval-augmented generation (RAG) workflow, you can choose to call your favorite LLM directly from ES|QL.
To achieve this, we’ve added a new COMPLETION command that takes in a prompt, a completion inference ID which designates which LLM to call, and a column identifier to specify where to output the LLM response.
In the following example, we’re using COMPLETION to add a new _completion column that contains the summary of the content column:
Each row now contains a summary:
| _id | title | _score | summary |
|---|---|---|---|
| 4001 | The Hobbit | 0.03279 | Bilbo helps dwarves reclaim Erebor from the dragon Smaug. |
| 3999 | The Fellowship of the Ring | 0.03226 | Frodo begins the quest to destroy the One Ring. |
| 4005 | The Two Towers | 0.0315 | The Fellowship splits; war comes to Rohan; Frodo nears Mordor. |
| 4123 | The Silmarillion | 0.03125 | Ancient myths and history of Middle-earth's First Age. |
| 4006 | The Return of the King | 0.3101 | Sauron is defeated and Aragorn is crowned King. |
| 4144 | The Children of Húrin | 0.01515 | The tragic tale of Túrin Turambar's cursed life. |
In another use case, you may simply want to answer a question using the proprietary data that you have indexed in Elasticsearch. In this case, the best search results that we’ve computed in the previous stage can be used as context for the prompt:
Since the COMPLETION command unlocks the ability to send any prompt to an LLM, the possibilities are endless. Although we’re only showing a few examples, the COMPLETION command can be used in a wide range of scenarios, from security analysts using it to assign scores depending on whether a log event can represent a malicious action or data scientists using it to analyze data, to cases where you just need to generate Chuck Norris facts based on your data.
This is only the beginning
In the future, we’ll be expanding ES|QL to improve semantic reranking for long documents, better conditional execution of the ES|QL queries using multiple FORK commands, support sparse vector queries, removing close duplicate results to enhance result diversity, allowing full text search on runtime generated columns, and many other scenarios.
Additional tutorials and guides:
- ES|QL for search
- ES|QL for search tutorial
- Semantic_text field type
FORKandFUSEdocumentation- ES|QL search functions
Related Content

July 16, 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

How to build search analytics on Elastic using OpenTelemetry, no extra pipeline required
How to instrument your search application to use modern Open Telemetry standard to drive insights in to your search and users.
Follow the money: tracing laundering networks with ES|QL and cross-cluster search
The data model, cross-cluster architecture and five ES|QL queries that power mule detection and laundering network tracing, built from infrastructure most financial institutions already run.

July 1, 2026
One command. Natural language. Your Elasticsearch data, straight to the terminal.
Query your Elasticsearch data from the terminal in plain English. The official Elastic GitHub Copilot CLI plugin generates and runs ES|QL queries against your cluster. No Kibana, no manual syntax.

June 30, 2026
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.