How to get the best of lexical and AI-powered search with Elastic’s vector database



Partager sur Twitter


Partager sur LinkedIn


Partager sur Facebook


Partage par e-mail


Imprimer
Maybe you came across the term “vector database” and are wondering whether it’s the new kid on the block of data retrieval systems. Maybe you are confused by conflicting claims about vector databases. The truth is, the approach used by vector databases has been around for a few years. If you’re looking for the best retrieval performance, hybrid approaches that combine keyword-based search (sometimes referred to as lexical search) with vector-based approaches represent the state of the art.
In Elasticsearch®, you can get the best of both worlds: lexical and vector search. Elastic® made lexical columnar retrieval popular, implemented in Lucene, and has been perfecting that approach for more than 10 years. In addition, for several years, Elastic has been investing in vector database capabilities, such as a native implementation of approximate nearest neighbor search using hierarchical navigable small world (HNSW) (available in 8.0 and later releases).
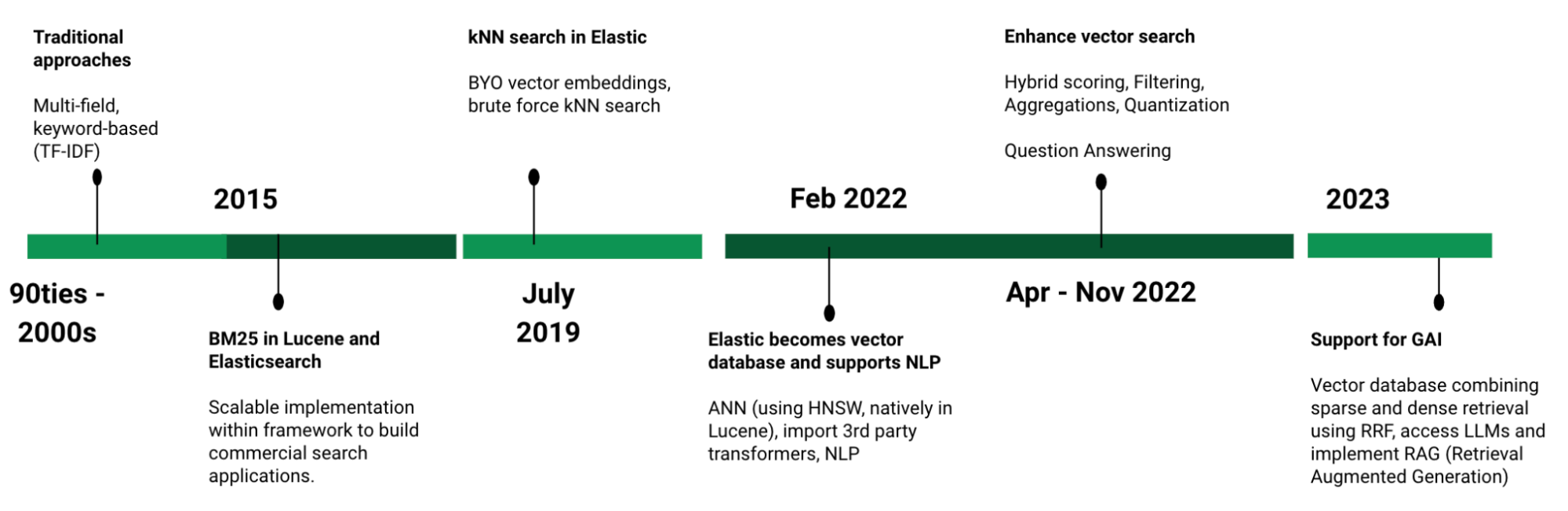
Elastic is positioned to be a leader in the rapidly evolving vector database market:
- Fully performant and scalable vector database functionality, including storing embeddings and efficiently searching for nearest neighbor
- A proprietary sparse retrieval model that implements semantic search out of the box
- Industry-leading relevance of all types — keyword, semantic, and vector
- The ability to apply generative AI and enrich large language models (LLMs) with proprietary, business-specific data as context
- All capabilities in a single platform: execute vector search, embed unstructured data into vector representations applying off-the-shelf and custom models, and implement search applications in production, complete with solutions for observability and security
In this blog, learn more about the concepts relating to vector databases, how they work, which use cases they apply to, and how you can achieve superior search relevance with vector search.
The basics of vector databases
Why is there so much attention on vector databases?
A vector database is a term for a system capable of executing vector search. So to understand vector databases, let’s start with vector search and why it has garnered so much attention lately.
Vector search plays an important role in recent discussions about how AI is transforming literally everything, from business workflows to education. Why does vector search play such an important role on this topic? First, vector search enables fast and accurate semantic search of unstructured data — without extensive curation of metadata, keywords, and synonyms. Second, vector search contributes a piece to the recent excitement around generative AI because it can provide accurate context from proprietary sources outside what LLMs “know” (i.e., have seen during their training).
What are vector databases used for?
Most standard databases let you retrieve related information by matching on structured fields, including matching keywords in descriptions, and values in numeric fields. By contrast, a vector database captures the meaning of unstructured text and finds you “what you mean” instead of matching text — also known as semantic search.

Additionally, vector databases allow you to:
- Search unstructured data other than text, including images or audio. Searches that involve more than one type of data have been referred to as “multimodal search” — like searching for images using a textual description.
- Personalize user experiences by modeling user characteristics or behaviors in a statistical (vector) model and matching others against that.
- Create “generative” experiences, where the system doesn’t just return a list of documents related to a query the user issued, but engages the user in conversations, explains multi-step processes, and generates an interaction that goes well beyond perusing related information.
What is a vector database, and how does it work?
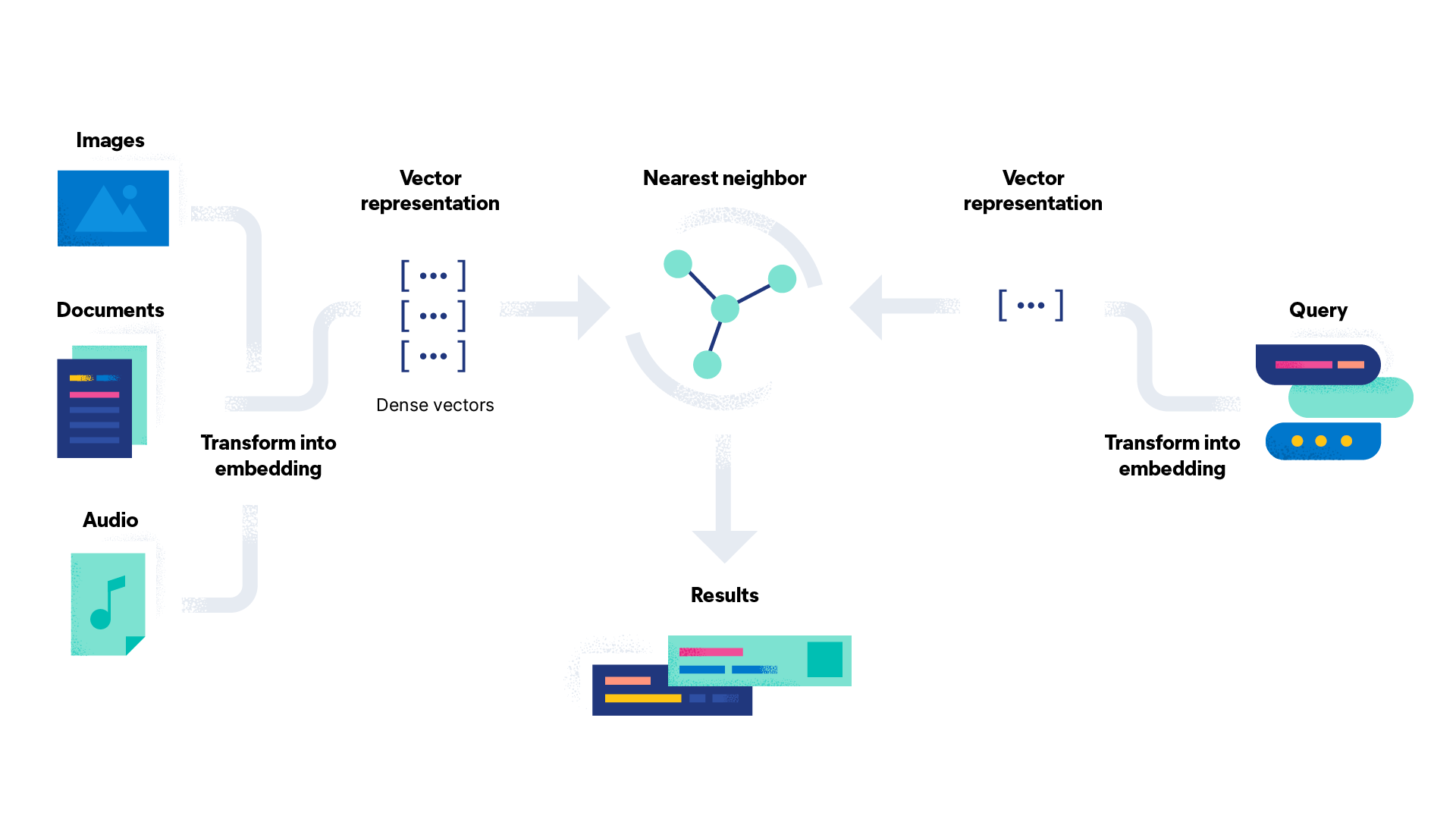
A vector database consists of two primary components:
Indexing and storing embeddings, which is what the multi-dimensional numeric representation of unstructured data is generally called. Embeddings are generated by deep neural networks that were trained to classify that type of unstructured data and capture the meaning, context, and associations of unstructured data in a “dense” vector, usually hundreds to thousands dimensions deep — the secret sauce of vector search.
A search algorithm that efficiently finds nearest neighbors in the high dimensional “embedding space,” where vector proximity means similarity in meaning. Different ways to search indices exist, also known as approximate nearest neighbor (ANN) search, with HNSW being one of the most commonly utilized algorithms by vector database providers.
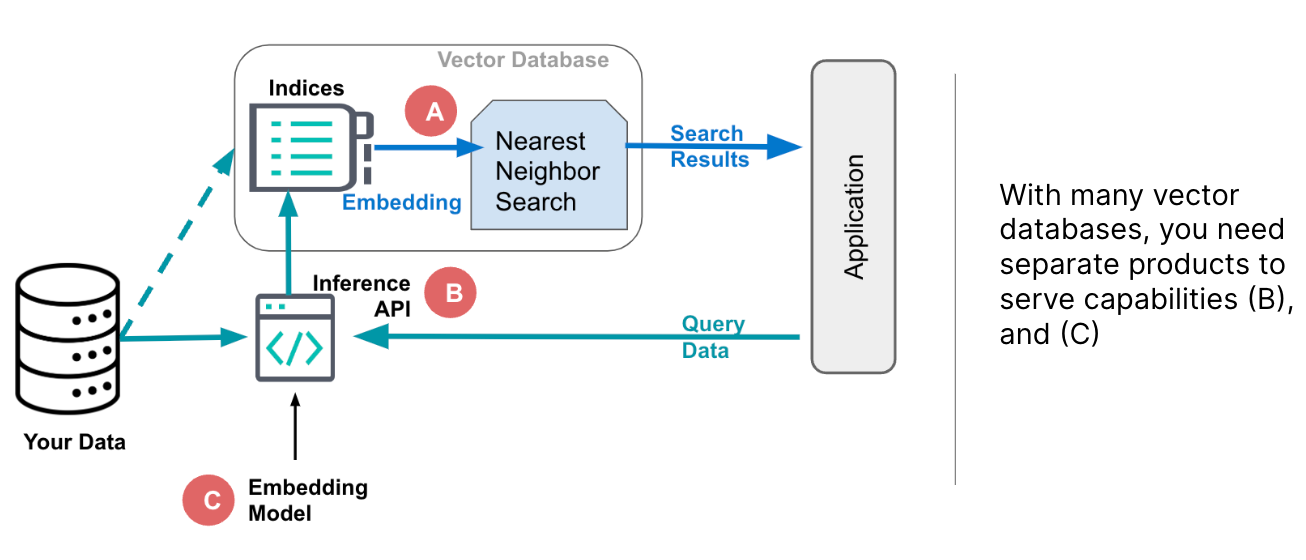
Some vector databases only provide the capability to store and search embeddings, depicted as A in Figure 2 above. However, this approach leaves developers with the challenge of how to generate those embeddings. Typically, that requires access to an embedding model (shown as C) and an API to apply it to your data and queries (B). And you may be able to store only very limited meta data along with the embeddings, making it more complex to provide comprehensive information in your user application.
Further, dedicated vector databases leave you to figure out how to integrate the search capability into your application, as alluded to on the right side in Figure 2. Managing the components of your software architecture to solve those challenges involves evaluating many solutions offered from different vendors with varying quality levels and support.
Elastic as a vector database
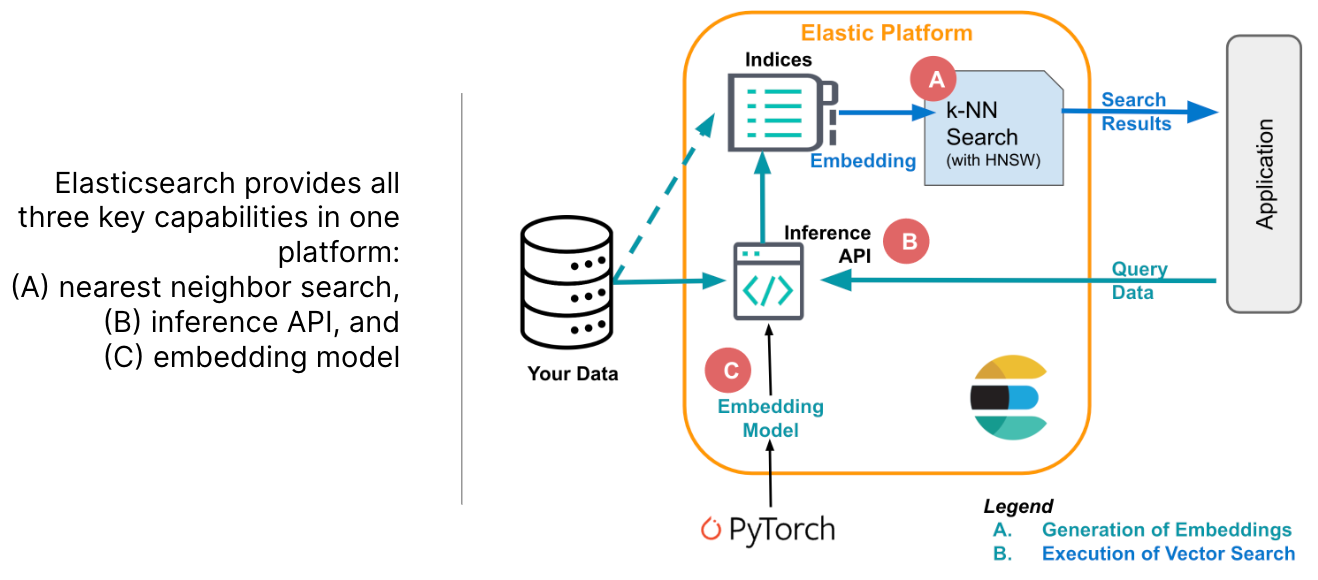
Elastic provides all capabilities you should expect from a vector database and more!
In contrast to dedicated vector databases, Elastic supports three capabilities in a single platform that are critical to implement applications powered by vector search: storing embeddings (A), efficiently searching for nearest neighbor (B), and embedding text into vector representations (C).
This approach eliminates inefficiencies and complexities compared to accessing them through APIs, as necessary with other vector databases. Elastic implements approximate nearest neighbor search using HNSW natively in Lucene and lets you apply filtering (as pre-filtering, for accurate results) using an algorithm that switches between brute force and approximate nearest neighbors as appropriate (i.e., falls back to brute force when the pre-filter removes a large portion of the candidate list).
Use our market-leading Learned Sparse Encoder model or bring your own embedding model. Learn more about loading transformers created in PyTorch into Elastic in this blog.
How to get optimal retrieval performance with vector search
Challenges with implementing vector search
To the heart of how to implement superior semantic search, let’s understand the challenges with (dense) vector search:
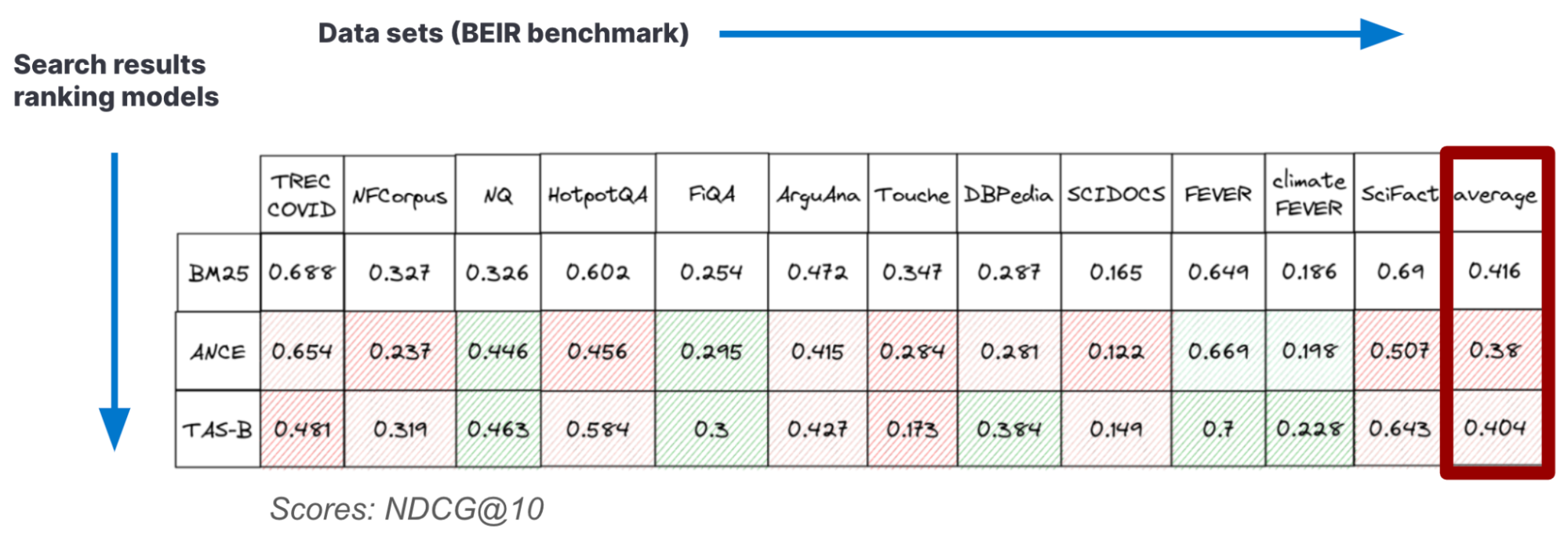
- Picking the right embedding model: Standard embedding models deteriorate out of domain, like the ones available off the shelf on public repositories — as shown, for example, in Table 2 of our earlier blog on benchmarking vector search. If you’re lucky, a pre-trained model works well enough for your use case, but generally you have to adapt them with domain data, which requires annotated data and expertise in training deep neural networks. You can find a blueprint for the model adaptation process in this blog.
- Implementing efficient filtering: In search and recommender systems, you are typically not done returning a list of relevant documents; users want to apply filters. Filtering for metadata with vector search is challenging: if you filter after running the vector search, you risk being left with too few (or no) results matching the filter conditions (known as “post filtering”). Otherwise, if you filter first, the nearest neighbor search isn’t as efficient because it’s performed on a small subset of the data, whereas the data structure used during vector search (like the HNSW graph) was created for the whole data set. Restricting the search scope to relevant vectors is — for many use-cases — an absolute necessity for providing a better customer experience.
- Performing hybrid search: For best performance, you typically have to combine vector search with traditional lexical approaches
Dense versus sparse vector retrieval
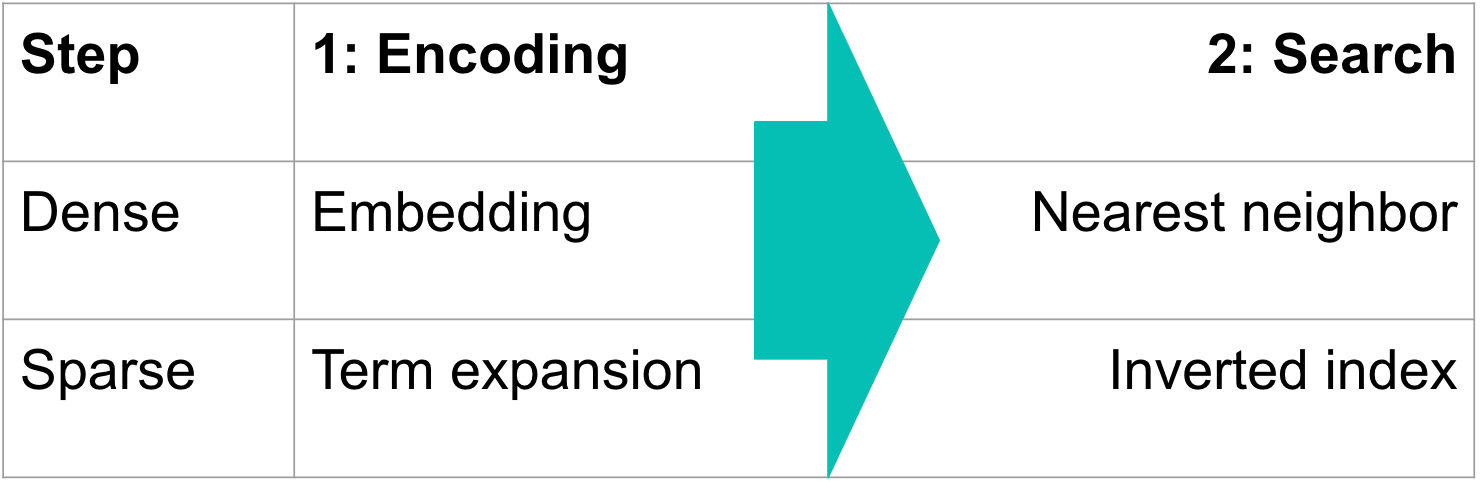
There are two big families of retrieval approaches, often referred to as “dense” and “sparse.” Both use a vector representation of text, which encodes meaning and associations, and both perform a search for close matches as a second step, as indicated in Figure 5 below. All vector-based retrieval approaches have that in common.
Above we described what more specifically is known as “dense” vector search, where unstructured data is transformed into a numeric representation using an embedding model, and you find matches as a nearest neighbor to a query in embedding space. To deliver high relevance results, dense vector search generally requires in-domain retraining. Without in-domain retraining, they may underperform even traditional lexical scoring, such as Elastic’s BM25. The upside and reason why vector search has garnered so much attention is that it can outperform all other approaches when fine-tuned, and it allows you to search unstructured data other than text, like images or audio, which has become known as “multimodal search.” The vector is considered “dense” because most of its values are non-zero.
By contrast to “dense” vectors described above, “sparse” representations contain very few non-zero values. For example, lexical search that made Elasticsearch popular (BM25) is an example of a sparse retrieval method. It uses a bag-of-words representation for text and achieves high relevance by modifying the basic relevance scoring method known as TF-IDF (term frequency, inverse document frequency) for factors like length of the document.
Learned sparse retrievers: Highly performant semantic search out of the box
The latest sparse retrieval approaches use learned sparse representations that offer multiple advantages over other approaches:
- High relevance without any in-domain retraining: They can be used out of the box without adapting the model on the specific domain of the documents.
- Interpretability: You can follow along which terms are matched, and the score attached by sparse encoders indicates how relevant a term is to a query — very interpretable — whereas dense vector search relies on the numeric representations of meaning that were derived by applying an embedding model, which is “black box” like many machine learning approaches.
- Fast: Sparse vectors fit right into inverted indices that have made established sparse retrievers like Lucene and Elasticsearch so fast. But sparse retrievers only apply to text data — not to images or other types of unstructured data.
Key tradeoffs between sparse and dense vector-based retrieval
Sparse retrieval | Dense vector-based retrieval |
Good relevance without tuning (learned sparse) | Adapted to domain; can beat other approaches |
Interpretable | Not interpretable |
Fast | Multimodal |
Elastic 8.8 introduced our own learned sparse retriever, included with the Elasticsearch Relevance EngineTM (ESRETM), which expands any text with related relevant words. Here’s how it works: a structure is created to represent terms found in the document, as well as their synonyms. In a process called term expansion, the model adds terms based on their relevance to the document, from a static vocabulary of 30K fixed tokens, words, and sub-word units.
This is similar to vector embedding in that an auxiliary data structure is created and stored in each document, which then can be used for just-in-time semantic matching within a query. Each term also has an associated score, which captures its contextual importance within the document and therefore is interpretable — unlike embeddings.
Our pre-trained sparse encoder lets you implement semantic search out of the box and also addresses the other challenges with vector-based retrieval described above:
- You don’t need to worry about picking an embedding model — Elastic’s Learned Sparse Encoder model comes pre-loaded into Elastic, and you can activate it with a single click.
- There are multiple ways to implement hybrid search, including reciprocal rank fusion (RRF) and linear combination.
- Keep memory and storage in check by using quantized (byte-size) vectors and leveraging all the recent innovations in Elasticsearch that reduce data storage requirements.
- Get all that in a hardened platform that can handle petabyte scale.
You can learn about the model’s architecture, how we trained it, and how it outperforms alternative approaches in this blog describing the Elastic Learned Sparse Encoder.
Why choose Elastic as your vector database?
Elastic’s vector database is a strong offering in the fast developing vector search market. It provides:
- Semantic search out of the box
- Best-in-class retrieval performance: Hybrid search with Elastic’s Learned Sparse Encoder combined with BM25 outperforms SPLADE, ColBERT, and high-end embedding models offered by OpenAI.

- The flexibility of using our market leading learned sparse encoder model, picking any off-the-shelf model, or bringing your own optimized model — so you can keep up with innovations in this rapidly evolving space
- Efficient pre-filtering on HNSW using a practical algorithm that appropriately trades off speed against loss in relevancy
- Capabilities needed in most search applications that dedicated vector databases do not provide, like aggregation, filtering, faceted search, and auto-complete
In addition, unlike most others, Elastic is agnostic to your data store (on-prem or any cloud provider) and lets you combine both (cross-cluster search).
With Elastic, you can join the generative AI revolution and augment public LLMs with your proprietary, domain-specific data. Bring this to market quickly, since no tuning, configuration, model selection, or domain training are required. To further optimize performance, Elastic gives you the flexibility to leverage advanced approaches — like using a fine-tuned embedding model or running your own LLMs — on a mature and feature rich platform.
Don’t take our word for it — we’re recognized as a leader by industry analysts and at-scale adoption by the search market, along with a vibrant user community.
Ready to dive in?
- Learn about the Elastic Relevance Engine, which includes the Elastic Learned Sparse Encoder that delivers semantic search out-of-box.
- Watch a demo of combining semantic search with generative AI from our presentation at Microsoft Build.
- Sign up for a free Elastic trial, and don’t forget to enable auto-scaling.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Partager
Partager sur Twitter
Partager sur LinkedIn
Partager sur Facebook
Partage par e-mail
Imprimer

