De la idea a realidad: Anuncio del lenguaje de búsqueda con barras verticales de Elastic, ES|QL


 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
Hoy, nos complace anunciar la vista previa técnica del nuevo lenguaje de búsqueda con barras verticales de Elastic®, ES|QL (Elasticsearch Query Language), que transforma, enriquece y simplifica las investigaciones de datos. Impulsado por un nuevo motor de búsqueda, ES|QL brinda capacidades de búsqueda avanzadas con procesamiento concurrente y mejora así la velocidad y la eficiencia independientemente de la estructura y la fuente de datos. Resuelve problemas con rapidez creando agregaciones y visualizaciones, todo desde una única pantalla para un flujo de trabajo iterativo y sin inconvenientes.

Evolución en Elasticsearch
En los últimos 13 años, Elasticsearch® ha evolucionado significativamente, se ha adaptado a las necesidades de los usuarios y al cambiante panorama digital. Originalmente para búsqueda de texto completo, Elasticsearch se expandió para brindar soporte a un conjunto más amplio de casos de uso basados en los comentarios de los usuarios. En este recorrido, Elasticsearch Query DSL, nuestro primer lenguaje de búsqueda adoptado, brindó un completo conjunto de búsquedas para filtros, agregaciones y otras operaciones. Este DSL basado en JSON se convirtió en última instancia en la base de nuestro endpoint de la API _search.
Con los años y la diversificación de las necesidades, se hizo evidente que los usuarios querían más que lo que Query DSL brindaba. Comenzamos a adoptar e incorporar DSL adicionales en nuestro Query DSL para scripting o para eventos en investigaciones de seguridad y mucho más. Sin embargo, si bien estas adiciones fueron versátiles, no cubrieron por completo algunos de los requisitos de los usuarios.
Los usuarios querían un lenguaje de búsqueda que pudiera hacer lo siguiente:
- Simplificar las investigaciones de amenazas y seguridad, además de observar y resolver problemas de producción a través de una sola búsqueda que brinde un enfoque completo e iterativo
- Optimizar las investigaciones de los datos buscando, enriqueciendo, agregando, visualizando y más, todo desde una única interfaz
- Usar capacidades de búsqueda avanzadas, como procesamiento concurrente que mejore la velocidad y la eficiencia de búsqueda en grandes cantidades de datos independientemente de la estructura y la fuente
De la idea a realidad: Presentación de ES|QL
Los escuchamos y nos enorgullece presentar Elasticsearch Query Language (ES|QL), nuestro nuevo e innovador lenguaje de búsqueda con barras verticales; un lenguaje y método único y unificado para interactuar con datos en Elasticsearch y al mismo tiempo eliminar la costosa necesidad de transferirlos a sistemas externos para un procesamiento especializado. A diferencia de otros lenguajes que Elastic adoptó a lo largo de los años, como Query DSL, ES|QL está diseñado y pensado desde cero para simplificar en gran medida las investigaciones de los datos y ser accesible para los principiantes, sin dejar de ser poderoso para los expertos.
Comando de ejemplo de ES|QL:
from logstash-*
| stats avg_bytes = avg(bytes) by geo.src
| eval avg_bytes_kb = round(avg_bytes/1024, 2)
| enrich geo-data on geo.src with country, continent
| keep avg_bytes_kb, geo.src, country, continent
| limit 4Salida de ejemplo de ES|QL:
| avg_bytes_kb | geo.src | country | continent |
| 8.84 | BD | Bangladesh | Asia |
| 6.92 | BR | Brazil | Americas |
| 2.75 | CI | Côte d'Ivoire | Africa |
| 4.55 | CL | Chile | Americas |
Simpleza optimizada: Una UI personalizada para flujos de trabajo mejorados e iterativos
Conectar los puntos de un ataque en desarrollo o navegar por los datos de observabilidad requiere que filtres, busques, transformes y agregues una enorme cantidad de datos. ES|QL brinda esta funcionalidad a partir de una única búsqueda.
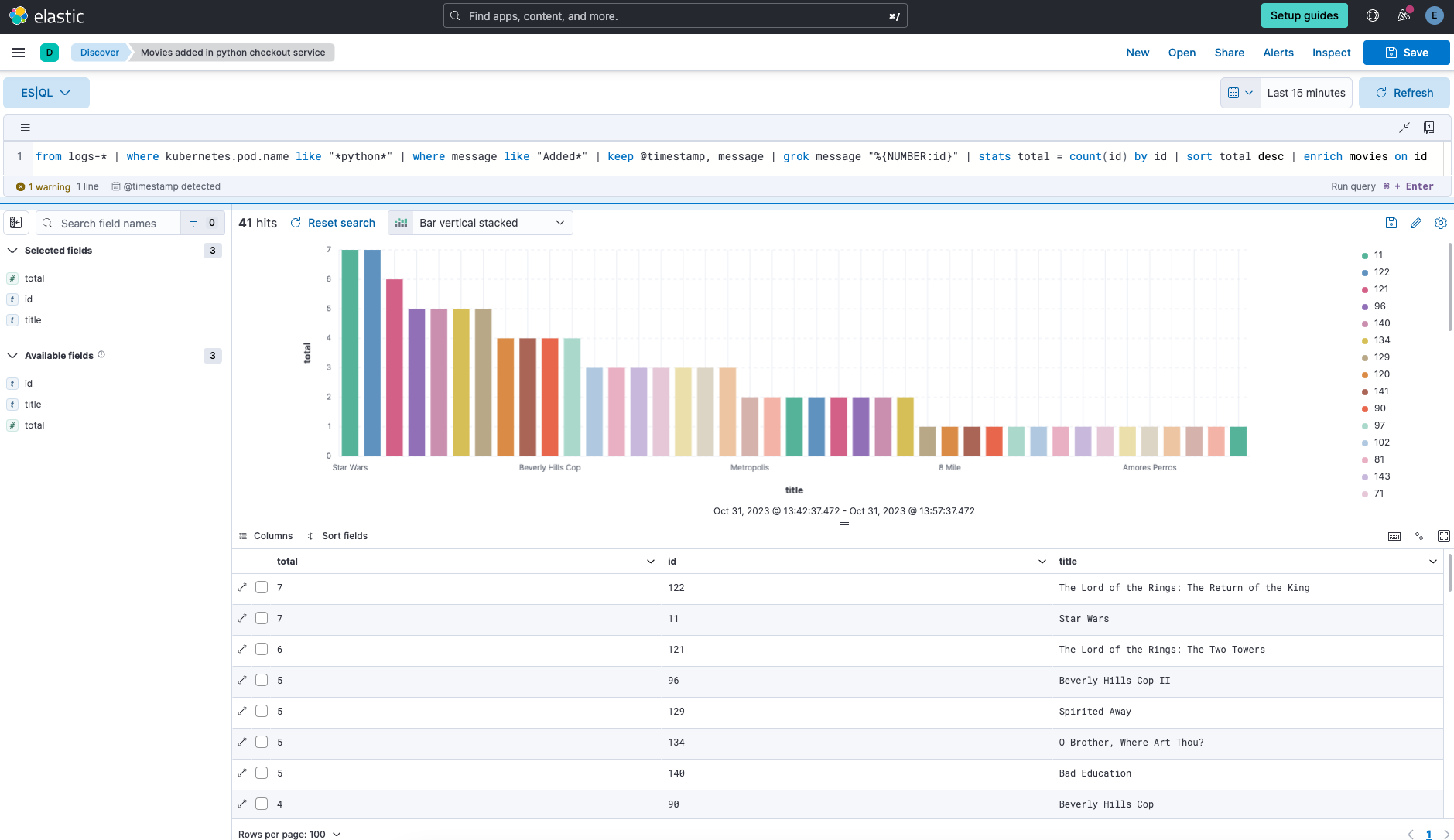
El cambio de contexto o intentar encontrar lo que buscas en varias pantallas te puede enlentecer y ser frustrante. Desde una pantalla unificada, ES|QL proporciona una sintaxis de autocompletar, integra la documentación del producto y visualiza los resultados de búsqueda, lo que garantiza un flujo de trabajo ininterrumpido y eficiente para las consultas de datos. Ya sea por seguridad, observabilidad o búsqueda, ES|QL mejora la eficiencia, la velocidad y la profundidad de la exploración de datos.
Concurrencia de ES|QL: Dos subprocesos son mejores que uno
Impulsado por un motor de búsqueda robusto, ES|QL ofrece capacidades de búsqueda avanzadas con procesamiento concurrente, lo que permite a los usuarios buscar sin inconvenientes en varias fuentes de datos y estructuras.
No hay traducción ni transpilación a Query DSL; en cambio, cada búsqueda en ES|QL se desglosa inicialmente, se interpreta según su significado, se valida su precisión y luego se mejora para el mejor rendimiento. Luego se plantea un proceso para ejecutar la búsqueda en varios nodos dentro del cluster. Los nodos objetivo se ocupan de la búsqueda y realizan ajustes sobre la marcha en el plan de ejecución mediante el marco de trabajo que brinda ES|QL. El resultado son búsquedas a la velocidad de la luz que obtienes de fábrica. A modo de ejemplo, consulta las evaluaciones comparativas cada noche.
La innovación de la plataforma impulsa beneficios en las soluciones de Elastic
Las soluciones de Elastic (Search, Observability y Security) se benefician de las características e innovaciones que se proporcionan en Elasticsearch y Kibana®. ES|QL cambia fundamentalmente la experiencia de usar estas soluciones y proporciona un flujo de trabajo de investigación de datos simple pero poderoso.
ES|QL mejora Elastic Security
ES|QL cambia fundamentalmente cómo los analistas persiguen las amenazas y fortalece la detección. Integrado en la respuesta a la entrada enriquecida de la comunidad, desata el poder las búsquedas con barras verticales a la velocidad de Elasticsearch, lo que mejora las capacidades de SIEM, seguridad de endpoint y seguridad en el cloud de Elastic Security.
- Buscar rápido y de forma iterativa: seguir la ruta de una amenaza emergente requiere de acción rápida y un lenguaje que brinda un flujo de trabajo iterativo.
- Enriquecer los resultados con contexto: ES|QL permite a los analistas correlacionar direcciones IP sospechosas con bases de datos de inteligencia de amenazas, brindando claridad inmediata sobre amenazas potenciales.
- Transformar datos: ES|QL empodera a los usuarios para manipular sus datos definiendo nuevos campos o analizando datos no normalizados, lo que asegura la claridad y relevancia de los datos.
- Agregar datos: los resultados pueden consolidarse y agregarse, lo que abre el camino para un análisis más profundo y la extracción de información.
Elastic es la única plataforma de búsqueda que empareja la eficiencia de una arquitectura de esquema durante la escritura con la experiencia de búsqueda iterativa de un lenguaje de búsqueda con barras verticales de esquema durante la lectura. Con una búsqueda increíblemente rápida (y salida de búsqueda a plena vista), los analistas pueden acercarse a su objetivo con cada barra vertical sucesiva.
ES|QL también mejora el motor de detección poderoso de Elastic Security. A fin de reducir la fatiga por alarmas, mejorar la relevancia de alertas y brindar otro camino para la detección por comportamiento, las organizaciones pueden incorporar valores agregados en las reglas de detección. Con la evaluación en línea, los especialistas pueden desarrollar de forma iterativa y centrarse en reglas basadas en ES|QL. Las búsquedas se hacen en texto sin formato, lo que simplifica la colaboración y brinda soporte a la detección como código.
ES|QL impacta en Elastic Observability
Los SRE que usen Elastic Observability pueden aprovechar ES|QL para analizar logs, métricas, rastreos y datos de perfilado, lo cual les permite identificar cuellos de botella de rendimiento y problemas en el sistema con una sola búsqueda. Los SRE obtienen las ventajas siguientes al gestionar datos de alta dimensionalidad y alta cardinalidad con ES|QL en Elastic Observability:
- Eliminar el ruido de la señal: con las alertas de ES|QL, mejora la precisión de detección enfocándote en las tendencias significativas en lugar de en incidentes individuales, así podrás minimizar falsas alarmas y entregar notificaciones procesables. Los SRE pueden gestionar estas alertas a través de la API de Elastic e integrarlas en los procesos de DevOps.
- Análisis mejorado con información: ES|QL puede procesar diversos datos de observabilidad, que incluyen datos de aplicaciones, infraestructura y empresas, y más, independientemente de la fuente y la estructura. ES|QL puede enriquecer los datos con facilidad mediante campos y contexto adicionales, lo cual permite la creación de visualizaciones para dashboards o análisis de problemas con una sola búsqueda.
- Tiempo promedio de resolución reducido: ES|QL, en combinación con AI Assistant y AIOps de Elastic Observability, mejora la precisión de detección identificando tendencias, aislando incidentes y reduciendo falsos positivos. Esta mejora en contexto facilita la resolución de problemas y la identificación y resolución rápidas de inconvenientes.
ES|QL en Elastic Observability no solo mejora la capacidad de un SRE para gestionar la experiencia del cliente, los ingresos de una organización y los SLO de forma más efectiva, sino que también facilita la colaboración con desarrolladores y DevOps proporcionando datos agregados contextualizados.
ES|QL potencia Elastic Search
Con ES|QL, puedes recuperar, agregar, calcular y transformar datos en una sola búsqueda. Cuenta con características clave, como la capacidad de definir campos al momento de la búsqueda, realizar búsquedas de enriquecimiento de datos y procesar búsquedas de manera concurrente. Comprende y explora tus datos con ES|QL de varias formas. Desde utilizar clientes para la integración directa de API/código hasta visualizar los resultados directamente en una pantalla, ES|QL optimiza tus investigaciones de datos y se asegura de que obtengas el máximo valor de los sets de datos de manera fácil y simple.
El foco del diseño de ES|QL es evidente en su capacidad para reducir la complejidad del código, que en última instancia lleva al ahorro de costos y tiempo. Al facilitar la reutilización de los resultados de búsqueda en búsquedas posteriores, ES|QL minimiza la sobrecarga informática y elimina así la necesidad de scripts intrincados y búsquedas redundantes. ES|QL no es solo una API, sino una forma simple y poderosa de transformar tu enfoque respecto a la búsqueda.
Comienza tu recorrido con ES|QL
El futuro de la manipulación y exploración de los datos está aquí. Elastic invita a los analistas de seguridad, SRE y desarrolladores a experimentar este lenguaje transformador de primera mano y liberar nuevos horizontes en sus tareas de datos. Obtén más información sobre las posibilidades con ES|QL o comienza tu prueba gratuita ahora en vista previa técnica.
El lanzamiento y el plazo de cualquier característica o funcionalidad descrita en este blog quedan a la entera discreción de Elastic. Cualquier característica o funcionalidad que no esté disponible actualmente puede no entregarse a tiempo o no entregarse en absoluto.
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime