Elastic Observability en SRE y respuesta ante incidentes
Motivos de la importancia de la confiabilidad de servicios
Los servicios de software son una parte esencial del negocio moderno en la era digital. Solo ve las apps en tu teléfono inteligente. Compras, banca, transmisión, juegos, lectura, mensajes, viajes compartidos, calendarios, búsqueda; por mencionar algunos. La sociedad funciona con servicios de software. La industria ha crecido rápidamente para cumplir con las demandas, y las personas tienen muchas opciones en las que gastar su dinero y centrar su atención. Las empresas deben competir para atraer y retener clientes que pueden cambiar servicios con solo deslizar el pulgar.
La confiabilidad de servicios es una expectativa universal. Uno esperaría que cualquier servicio fuera rápido y funcional, de lo contrario “deslizas a la izquierda” y eliges un servicio que respete tu tiempo. Amazon perdió, como todo el mundo sabe, aproximadamente USD 1.2 millones por minuto durante el tiempo de inactividad el Amazon Prime Day en 2018. Pero no hace falta ser un gigante de la tecnología para entender los motivos de la importancia de la confiabilidad de servicios. El tiempo de inactividad y la degradación pueden dañar la reputación de cualquier empresa mucho después de la pérdida inmediata de ingresos. Es por eso que las empresas hacen grandes inversiones en las operaciones y gastaron aproximadamente USD 5200 millones en software de DevOps en 2018.
En este blog se explora la práctica de la ingeniería de confiabilidad de sitios, el ciclo de vida de respuesta ante incidentes y el rol de Elastic Observability para maximizar la confiabilidad. El contenido es relevante para los ingenieros y líderes técnicos que tengan la responsabilidad de garantizar que un servicio de software cumpla las expectativas de los usuarios. Para el final, deberías comprender con claridad los conceptos básicos de cómo los equipos de operaciones realizan la ingeniería de confiabilidad de sitios y la respuesta ante incidentes, y cómo logran sus objetivos usando una solución tecnológica como Elastic Observability.
¿Qué es la SRE?
La ingeniería de confiabilidad de sitios (SRE) es la práctica de asegurarse que un servicio de software cumpla con las expectativas de rendimiento de los usuarios. En pocas palabras, la SRE mantiene la confiabilidad de los servicios. La responsabilidad se remonta al “software como servicio” en sí. Recientemente, los ingenieros de Google acuñaron el término “ingeniería de confiabilidad de sitios” y codificaron su marco de trabajo en el que se ha vuelto un libro muy influyente: Site Reliability Engineering (Ingeniería de confiabilidad de sitios). Este blog se basa en los conceptos de ese libro.
Los ingenieros de confiabilidad de sitios (SRE) son responsables de lograr los objetivos de nivel de servicio usando indicadores como la disponibilidad, latencia, calidad y saturación. Estos tipos de variables influyen directamente en la experiencia del usuario de un servicio. De ahí los motivos de la importancia comercial de los SRE: un servicio satisfactorio genera ingresos, y las operaciones eficientes controlan los costos. Para ello, los SRE generalmente tienen dos tareas: gestionar la respuesta ante incidentes para proteger la confiabilidad de servicios e instituir soluciones y mejores prácticas según las cuales los equipos de operaciones y desarrollo puedan optimizar la confiabilidad de servicios y reducir el costo del esfuerzo.
Los SRE suelen expresar el estado deseado de los servicios en términos de SLA, SLO y SLI:
- Acuerdo de nivel de servicio (SLA): “¿qué espera el usuario?”. Un SLA es una promesa que un proveedor de servicios hace a sus usuarios sobre el comportamiento de sus servicios. Algunos SLA son contractuales y obligan al proveedor de servicios a compensar a los clientes afectados por un incumplimiento del SLA. Otros son implícitos y se basan en el comportamiento del usuario observado.
- Objetivo de nivel de servicio (SLO): “¿cuándo tomamos medidas?”. Un SLO es un umbral interno sobre el cual el proveedor de servicios toma medidas para evitar el incumplimiento de un SLA. Por ejemplo, si el proveedor de servicios promete un SLA del 99 % de disponibilidad, entonces un SLO más estricto del 99.9 % de disponibilidad podría darle tiempo suficiente para evitar el incumplimiento del SLA.
- Indicador de nivel de servicio (SLI): “¿qué medimos?”. Un SLI es una métrica observable que describe el estado de un SLA o SLO. Por ejemplo, si el proveedor de servicios promete un SLA del 99 % de disponibilidad, entonces una métrica como el porcentaje de pings exitosos al servicio podría servir como su SLI.
Estos son algunos de los SLI más comunes que monitorean los SRE:
- Disponibilidad mide el tiempo de actividad de un servicio. Los usuarios esperan que un servicio responda a las solicitudes. Es una de las métricas más básicas e importantes que se deben monitorear.
- Latencia mide el rendimiento de un servicio. Los usuarios esperan que un servicio responda a las solicitudes de manera oportuna. Lo que los usuarios perciben como “oportuno” varía según el tipo de solicitud que realizan.
- Errores mide la calidad y la exactitud de un servicio. Los usuarios esperan que un servicio responda a las solicitudes con éxito. Lo que los usuarios perciben como “con éxito” varía según el tipo de solicitud que realizan.
- Saturación mide el uso de recursos que hacen los servicios. Esta puede indicar la necesidad de escalar recursos para cumplir con las demandas del servicio.
Todos los que desarrollan y operan un servicio son responsables por su confiabilidad, incluso si su puesto no es el de ingeniero de confiabilidad de sitios. Tradicionalmente, se incluye a los siguientes:
- El equipo de producto que lidera el servicio.
- El equipo de desarrollo que crea el servicio.
- El equipo de operaciones que ejecuta la infraestructura.
- El equipo de soporte que escala los incidentes de los usuarios.
- El equipo de guardia que resuelve incidentes.
Las organizaciones con servicios complejos pueden tener un equipo dedicado de SRE que se encarguen de la práctica y medien con los otros equipos. En ellas, los SRE son un puente entre “Dev” y “Ops”. Por último, independientemente de la implementación, la confiabilidad de sitios es una responsabilidad colectiva en el ciclo de DevOps.
¿Qué es la respuesta ante incidentes?
Respuesta ante incidentes, en el contexto de SRE, es un esfuerzo por revertir el estado no deseado de un despliegue al estado deseado. Los SRE comprenden los estados deseados y suelen gestionar el ciclo de vida de respuesta ante incidentes para mantener esos estados deseados. En general, el ciclo de vida involucra la prevención, el descubrimiento y la resolución, con el objetivo final del mayor grado de automatización posible. Analicemos esos conceptos.
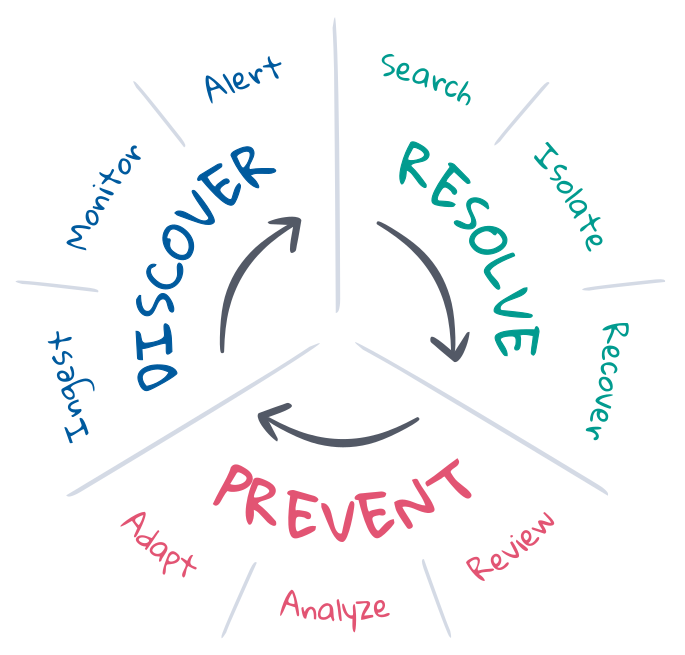
Prevención es el primer y último paso de la respuesta ante incidentes. Idealmente, los incidentes se previenen con el desarrollo controlado por pruebas en el pipeline de CI/CD. Pero las cosas no siempre resultan como lo planeado en producción. Los SRE optimizan la prevención a través de la planificación, la automatización y los comentarios. Antes del incidente, definen los criterios del estado deseado e implementan las herramientas necesarias para descubrir y resolver el estado no deseado. Después del incidente, hacen una revisión posterior para ver qué sucedió y debatir la adaptación. A largo plazo, pueden analizar los KPI y usar esa información para enviar solicitudes de mejora a los equipos de producto, desarrollo y operaciones.
Detección es saber cuándo puede haber ocurrido un incidente y alertar a los canales correctos para que respondan. El descubrimiento debe automatizarse para maximizar la cobertura de respuesta ante incidentes, minimizar el tiempo promedio hasta la detección (MTTD) y proteger los SLO. La automatización requiere la observabilidad continua del estado de todo el despliegue, el monitoreo continuo del estado deseado y la alerta inmediata en caso de un estado no deseado. La cobertura y relevancia de la detección de incidentes depende en gran medida de las definiciones de estado deseado, aunque el Machine Learning puede ayudar a detectar cambios de estado inesperados que podrían indicar o explicar incidentes.
Resolución significa devolver un despliegue a su estado deseado. Algunos incidentes tienen soluciones automatizadas, como servicios de escalado automático cuando la capacidad está casi saturada. Pero muchos incidentes requieren atención humana, en especial cuando los síntomas no se reconocen o la causa es desconocida. La resolución requiere que los expertos adecuados investiguen la causa raíz, aíslen y reproduzcan el problema para indicar una solución, y recuperen el estado deseado del despliegue. Este es un proceso iterativo que puede rotar por muchos expertos, investigaciones e intentos fallidos. La búsqueda y la comunicación son clave para el éxito. La información acorta los ciclos, minimiza el tiempo promedio de resolución (MTTR) y protege los SLO.
Elastic en SRE y respuesta ante incidentes
Elastic Observability impulsa el ciclo de vida de respuesta ante incidentes con observabilidad, monitoreo, alertas y búsqueda. En este blog se incluye una introducción a su capacidad de entregar observabilidad continua del estado de despliegue de la pila completa, monitoreo continuo de los SLI en busca de incumplimientos de los SLO, alertas automatizadas de incumplimientos para el equipo de respuesta ante incidentes y experiencias de búsqueda intuitivas que llevan a los responsables de responder a una solución rápida. De manera colectiva, la solución minimiza el tiempo promedio de resolución (MTTR) para proteger la lealtad de los clientes y la confiabilidad de servicios.
Observabilidad y datos
No puedes resolver un problema si no puedes observarlo. La respuesta ante incidentes requiere visibilidad de la pila completa del despliegue afectado en el tiempo. Pero los servicios distribuidos están repletos de complejidad incluso para un solo evento lógico, como se muestra a continuación. Cada componente de la pila es una fuente potencial de degradación o fallas en todo lo posterior. Los responsables de responder ante incidentes deben considerar, si no controlar y reproducir, el estado de cada componente durante la resolución. La complejidad es el flagelo de la productividad. Es imposible resolver un incidente dentro de los límites de un SLA estricto a menos que haya un único lugar para observar el estado de todo en el tiempo.

Elastic Common Schema (ECS) es nuestra respuesta al problema de la complejidad. ECS es una especificación de modelo de datos open source para observabilidad. Estandariza las convenciones de nomenclatura, los tipos de datos y las relaciones de servicios distribuidos modernos e infraestructura. El esquema presenta una vista unificada de la pila de despliegue completa en el tiempo usando datos que una vez existieron tradicionalmente en silos. Los rastreos, las métricas y los logs en cada capa de la pila coexisten en este esquema para permitir una experiencia de búsqueda sin problemas durante la respuesta ante incidentes.
La estandarización de ECS permite mantener la observabilidad con poco esfuerzo. Los agentes APM y Beats de Elastic capturan automáticamente rastreos, métricas y logs de tus despliegues, ajustan los datos al esquema común y los envían a una plataforma de búsqueda central para investigación futura. Las integraciones con fuentes de datos populares como plataformas cloud, contenedores, sistemas y marcos de trabajo de aplicaciones facilitan la incorporación y gestión de datos a medida que tus despliegues se vuelven más complejos.
Cada pila de despliegue es única de su empresa. Es por eso que puedes extender ECS para optimizar tu flujo de trabajo de respuesta ante incidentes. Los nombres de proyecto de servicios y la infraestructura ayudan a los responsables de responder a encontrar lo que buscan, o a saber qué están viendo. Las ID de confirmación de aplicaciones ayudan a los desarrolladores a encontrar el origen de los errores como existían en el sistema de control de versión al momento de la creación. Los indicadores de características ofrecen información sobre el estado de los despliegues canary o los resultados de las pruebas A/B. Todo aquello que ayude a describir tus despliegues, ejecutar tus flujos de trabajo o cumplir con tus requisitos comerciales puede incrustarse en el esquema.
Monitoreo, alertas y acciones
Elastic Observability automatiza el ciclo de vida de respuesta ante incidentes monitoreando, detectando y alertando sobre los SLI y SLO esenciales. En cuanto al monitoreo, la solución incluye lo siguiente: Uptime, APM, Metrics y Logs. Uptime monitorea la disponibilidad enviando latidos externos a los endpoints de servicio. APM monitorea la latencia y calidad midiendo y capturando eventos directamente desde adentro de las aplicaciones. Metrics monitorea la saturación midiendo el uso de recursos de infraestructura. Logs monitorea la exactitud capturando mensajes de sistemas y servicios.
Una vez que conoces tus SLI y SLO, puedes definirlos como alertas y acciones para compartir los datos adecuados con la gente correcta cada vez que se incumpla un SLO. Las alertas de Elastic son búsquedas programadas que activan acciones cuando los resultados cumplen ciertas condiciones. Esas condiciones son expresiones de métricas (SLI) y umbrales (SLO). Las acciones son mensajes entregados a uno o más canales, como un sistema de notificación o sistema de rastreo de problemas, para indicar el inicio de un proceso de respuesta ante incidentes.
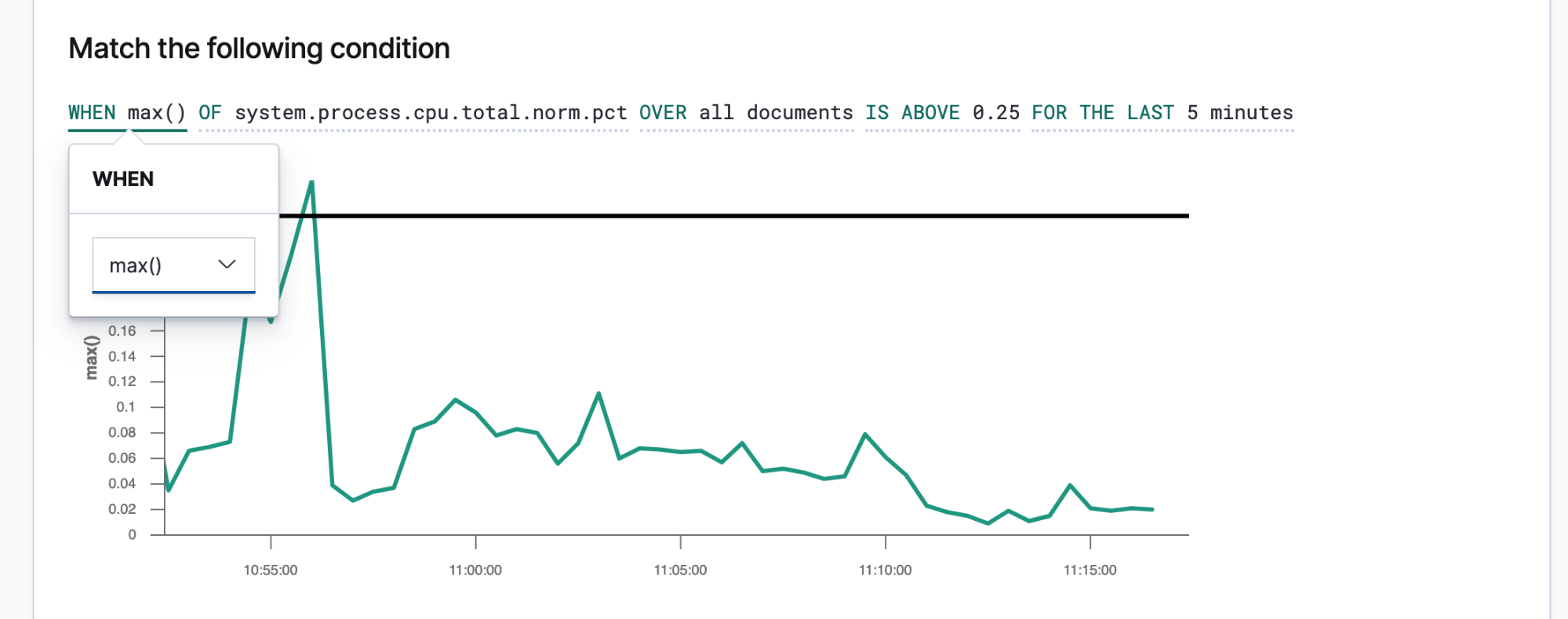
Las alertas breves y procesables guiarán a los responsables de responder hacia una resolución rápida. Los responsables de responder deben tener información suficiente para reproducir el estado del entorno y el problema observado. Debes crear una plantilla de mensaje que proporcione esos detalles a los responsables de responder. Estos son algunos detalles que debes considerar incluir:
- Título: “¿cuál es el incidente?”
- Gravedad: “¿cuál es la prioridad del incidente?”
- Lógica: “¿cuál es el impacto comercial de este incidente?”
- Estado observado: “¿qué sucedió?”
- Estado deseado: “¿qué se suponía que debía suceder?”
- Contexto: “¿cuál era el estado del entorno?”. Usa datos de la alerta para describir la hora, el cloud, la red, el sistema operativo, el contenedor, el proceso y demás contexto del incidente.
- Enlaces: “¿a dónde voy a continuación?”. Usa datos de la alerta para crear enlaces que lleven a los responsables de responder a dashboards, reportes de error u otros destinos útiles.
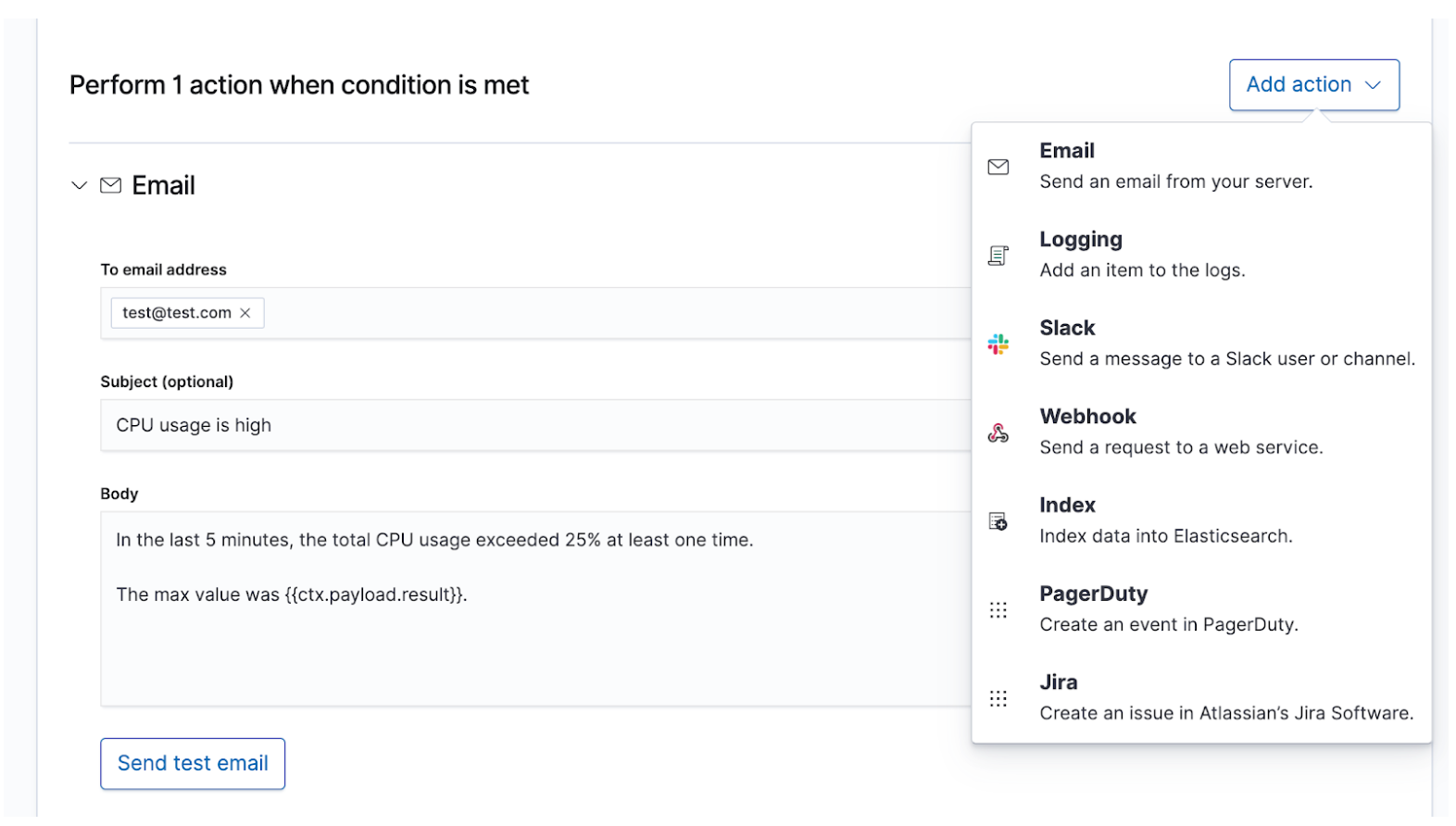
Los incidentes de mayor gravedad que requieren atención humana inmediata deben alertar al equipo de respuesta ante incidentes de guardia a través de canales en tiempo real como PagerDuty o Slack. Un ejemplo sería el tiempo de inactividad de un servicio que requiere al menos el 99 % de disponibilidad. Este SLA permite menos de 15 min de tiempo de inactividad por día, lo que ya es menos tiempo del que podría necesitar el equipo de respuesta ante incidentes para resolver el problema. Los incidentes de menor gravedad que requieren atención humana eventual podrían crear un ticket en un sistema de rastreo de problemas como JIRA. Un ejemplo sería un aumento en las tasas de error o latencia de los servicios que no afectan directamente los ingresos. Puedes optar por alertar a varios destinos al mismo tiempo, cada uno con su propio contenido de mensaje, a los fines de mantener un registro o la sobrecomunicación.
Investigación y búsqueda
¿Qué sucede luego de notificar al equipo de guardia una alerta? El recorrido hasta la resolución variará según el incidente, pero algunas cosas son seguras. Habrá personas con diferentes habilidades y experiencias trabajando bajo presión para resolver un problema poco claro de forma rápida y correcta, mientras lidian con un enorme caudal de datos. Necesitarán encontrar los síntomas reportados, reproducir el problema, investigar la causa raíz, aplicar una solución y ver si resuelve el problema. Es posible que necesiten hacer algunos intentos. Quizá se encuentren con que cayeron a un abismo. Todo este esfuerzo requiere cafeína respuestas. La información es lo que impulsa la respuesta ante incidentes de lo incierto a la resolución.
La respuesta ante incidentes es un problema de búsqueda. La búsqueda entrega respuestas oportunas y relevantes a las preguntas. Una buena experiencia de búsqueda es más que solo “la barra de búsqueda”; toda la interfaz del usuario anticipa tus preguntas y te guía hacia las respuestas correctas. Piensa en tu última experiencia de compra en línea. A medida que navegas por el catálogo, la aplicación anticipa la intención de tus clics y búsquedas para brindarte las mejores recomendaciones y filtros, lo que te lleva a gastar más dinero y más pronto. Nunca escribes una búsqueda estructurada. Quizá ni siquiera sepas lo que estás buscando y aun así lo encuentras rápidamente. Los mismos principios aplican a la respuesta ante incidentes. El diseño de esta experiencia de búsqueda tiene una gran influencia en el tiempo para resolver un incidente.
La búsqueda es clave para una respuesta ante incidentes veloz, no solo porque la tecnología es rápida, sino porque la experiencia es intuitiva. Nadie debe aprender la sintaxis de un lenguaje de búsqueda. Nadie debe hacer referencia a un esquema. Nadie debe ser perfecto como una máquina. Solo busca y encontrarás lo que necesitas en segundos. ¿Buscabas otra cosa? La búsqueda puede guiarte. ¿Deseas buscar por un campo específico? Comienza a escribir y la barra de búsqueda te sugerirá campos. ¿Sientes curiosidad por un pico en un gráfico? Haz clic en el pico y el resto del dashboard mostrará lo que sucedió durante este. La búsqueda es rápida y tiene alta tolerancia, y cuando se realiza correctamente brinda a los responsables de responder el poder de actuar de forma rápida y correcta a pesar de sus imperfecciones humanas.
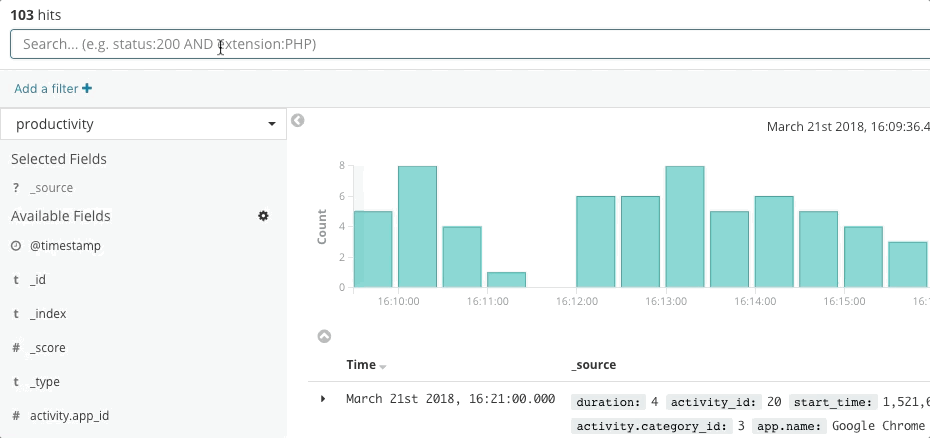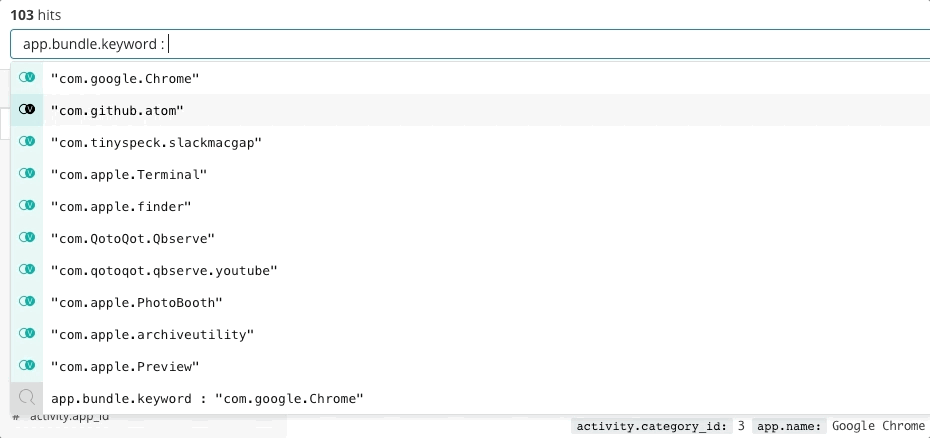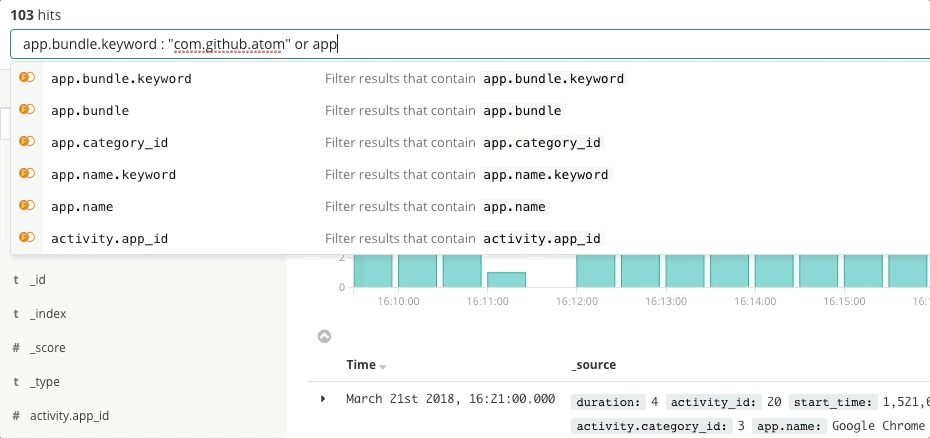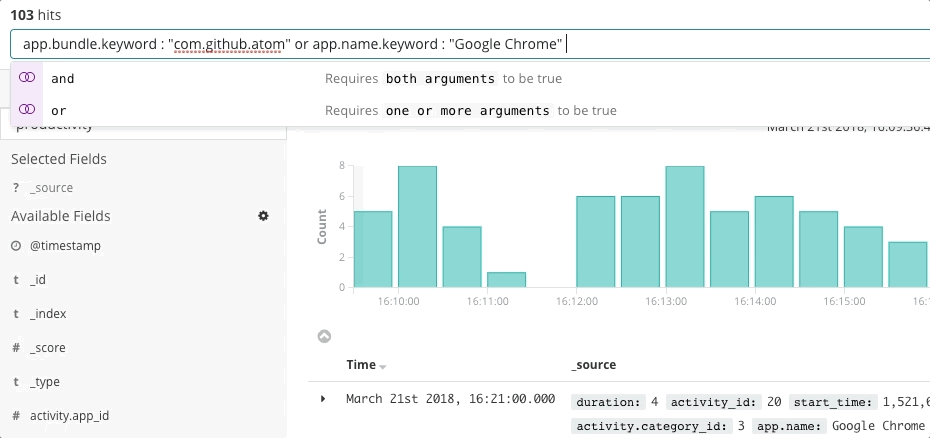
Elastic Observability presenta una experiencia de búsqueda para la respuesta ante incidentes que anticipa las preguntas, expectativas y objetivos de los responsables de responder ante incidentes. El diseño ofrece una experiencia conocida para cada uno de los silos de datos tradicionales (Uptime, APM, Metrics, Logs) y después guía a los responsables de responder a través de esas experiencias para ver la pila completa del despliegue. Esto es posible gracias a que los datos en sí existen en un esquema común, no en silos. Efectivamente, el diseño responde las preguntas iniciales de disponibilidad, latencia, errores y saturación, y después navega a la causa raíz a través de la experiencia que sea adecuada para ti.
Revisemos algunos ejemplos de esta experiencia.
Elastic Uptime responde las preguntas básicas sobre disponibilidad de servicios como: “¿cuáles servicios están inactivos? ¿Cuándo estuvo inactivo un servicio? ¿Estuvo inactivo el agente de monitoreo de tiempo de actividad?”. Las alertas de SLO de disponibilidad pueden llevar al responsable de responder ante incidentes a esta página. Tras encontrar los síntomas de un servicio no disponible, el responsable de responder puede seguir los enlaces para explorar los rastreos, las métricas o los logs del servicio afectado y su infraestructura de despliegue al momento de la falla. A medida que el responsable de responder navega, el contexto de la investigación permanece filtrado con el servicio afectado. Esto ayuda al responsable de responder a explorar hasta la causa raíz del tiempo de inactividad de dicho servicio.
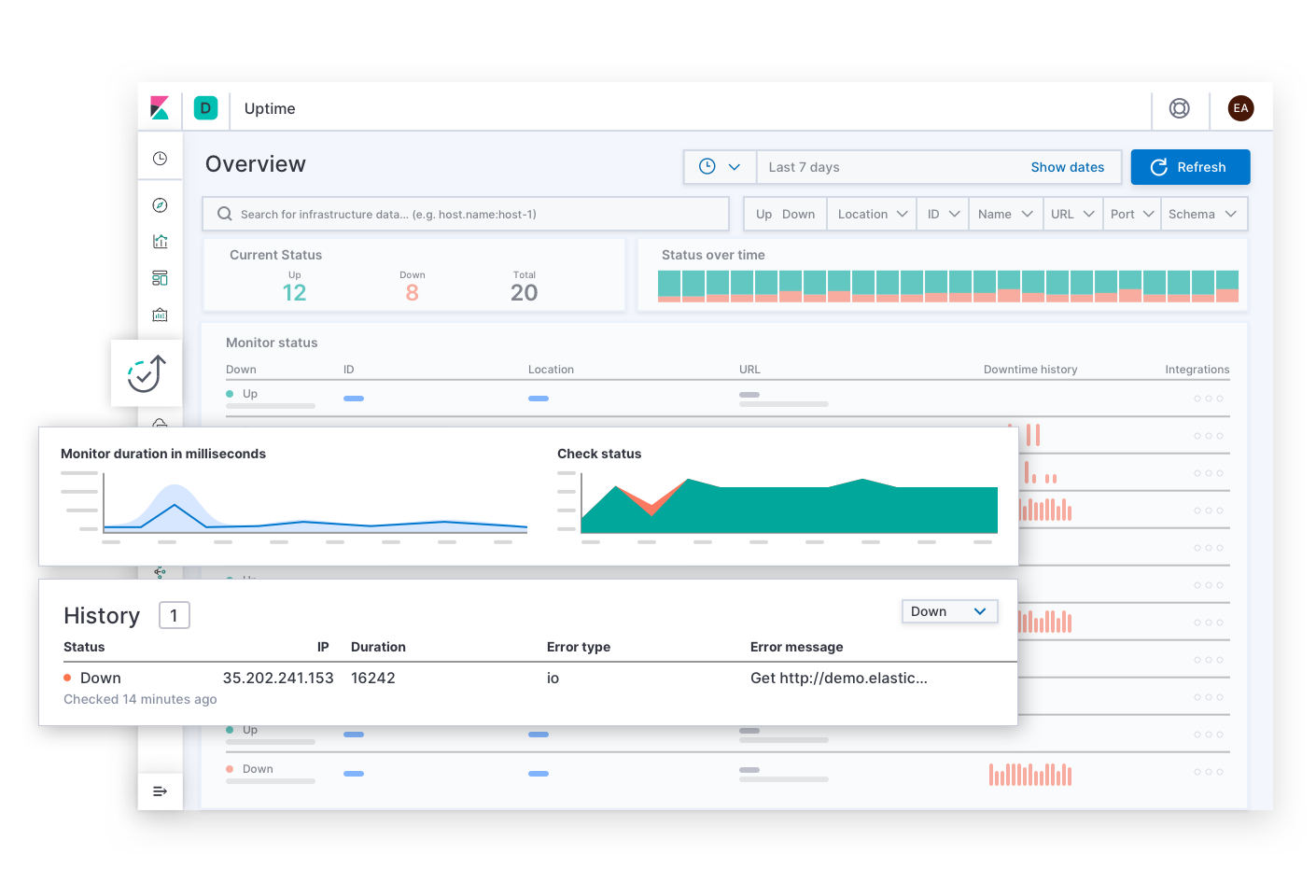
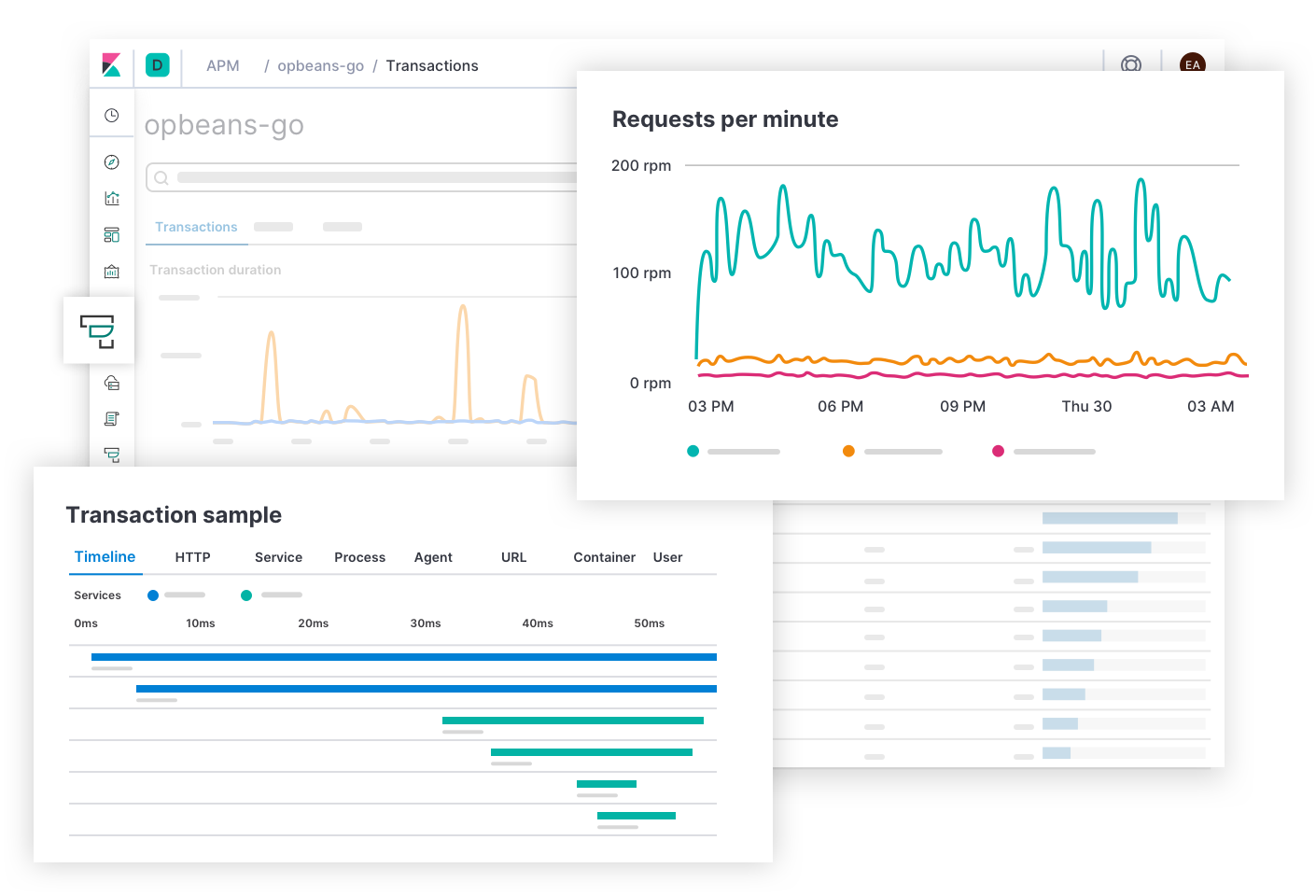
Elastic APM responde las preguntas sobre errores y latencia de servicios como: “¿cuáles endpoints tienen el impacto más negativo sobre la experiencia del usuario? ¿Cuáles intervalos disminuyen la velocidad de las transacciones? ¿Cómo rastreo las transacciones de los servicios distribuidos? ¿En qué parte del código fuente hay errores? ¿Cómo puedo reproducir un error en un entorno de desarrollo equivalente al entorno de producción?”. Las alertas de SLO de latencia y errores pueden llevar al responsable de responder ante incidentes a esta página. La experiencia de APM brinda a los desarrolladores de la aplicación la información que necesitan para encontrar, reproducir y solucionar errores. Los responsables de responder pueden explorar la causa de cualquier latencia navegando más profundo en la pila para ver las métricas de la infraestructura de despliegue de un servicio afectado.
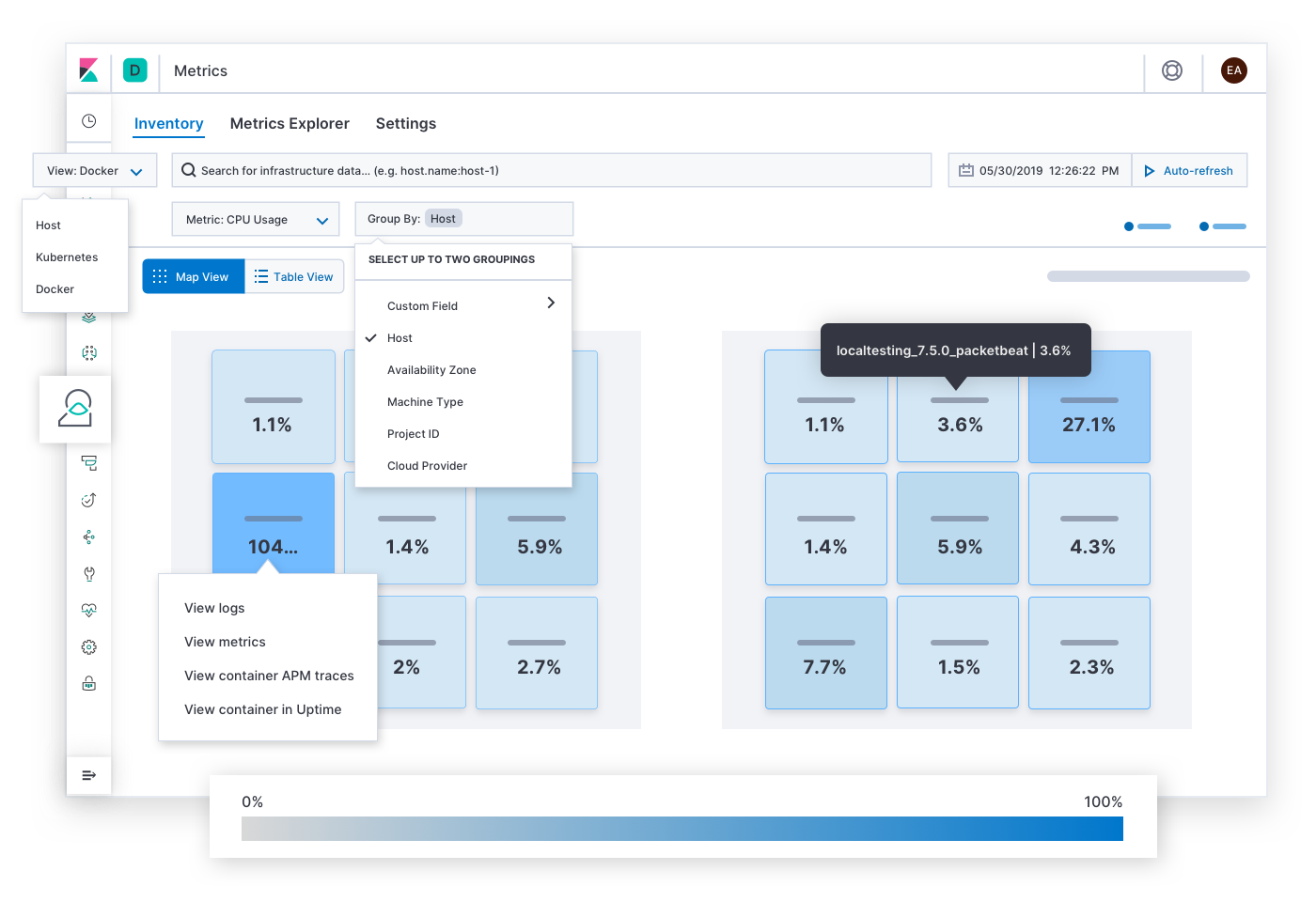
Elastic Metrics responde preguntas sobre la saturación de recursos como: “¿cuáles hosts, pods o contenedores tienen un consumo alto o bajo de memoria? ¿Almacenamiento? ¿Procesamiento? ¿Tráfico de red? ¿Y si los agrupo por Proveedor Cloud, región geográfica, zona de disponibilidad u otro valor?”. Las alertas de SLO de saturación pueden llevar al responsable de responder ante incidentes a esta página. Tras encontrar síntomas de congestión, puntos calientes o caídas de tensión, el responsable de responder puede expandir los logs y las métricas históricas de la infraestructura afectada o explorar el comportamiento de los servicios que se ejecutan en ella.
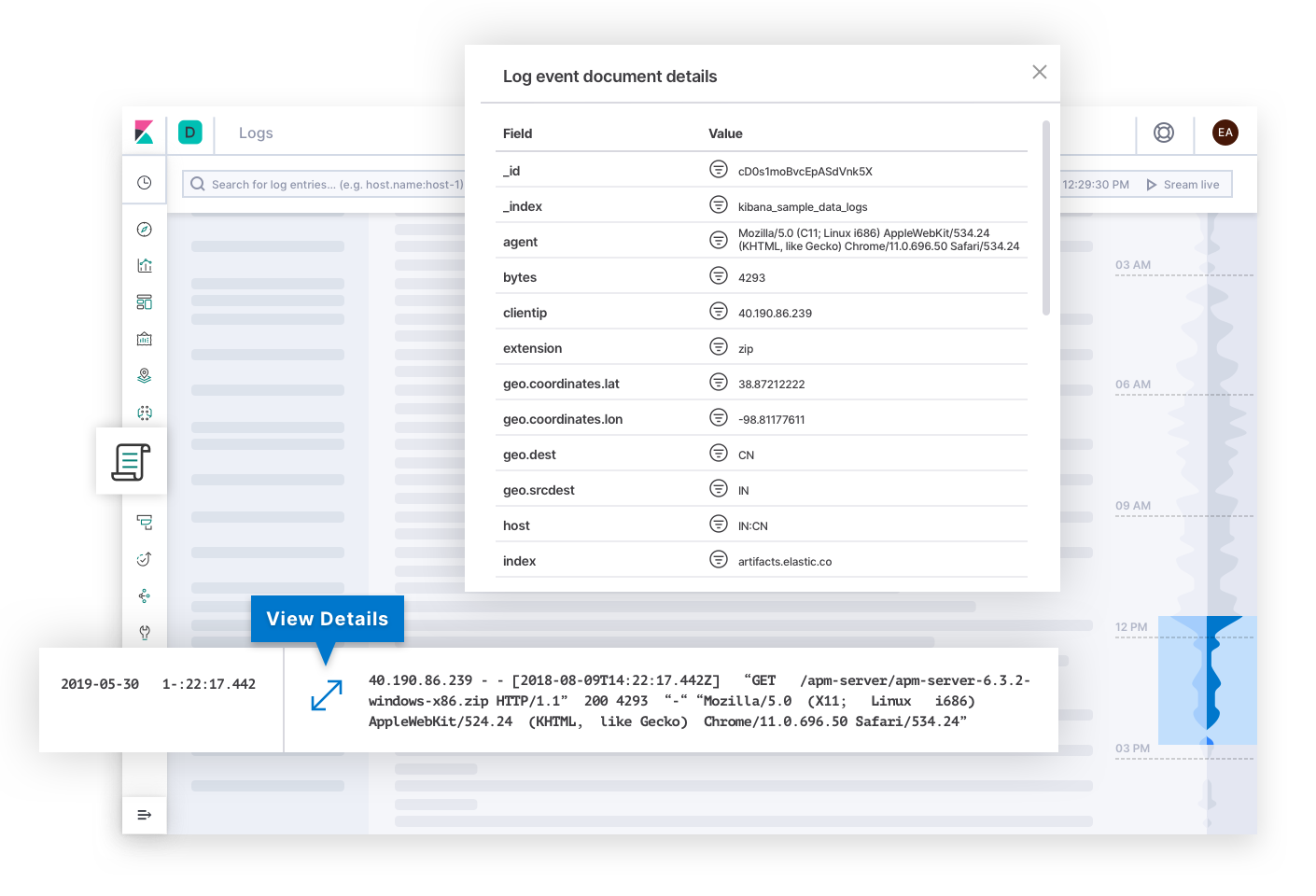
Elastic Logs responde preguntas sobre la fuente de la verdad de los eventos emitidos por sistemas y aplicaciones. Las alertas de SLO de calidad o exactitud pueden llevar al responsable de responder ante incidentes a esta página. Los logs pueden explicar la causa raíz de la falla y convertirse en el destino final de la investigación. O pueden explicar la causa de otros síntomas que eventualmente lleven al responsable de responder hacia la causa raíz. Detrás de escena, la tecnología puede categorizar logs y detectar tendencias en el texto para brindar a los responsables de responder ante incidentes señales que puedan explicar los cambios en el estado de un despliegue.
Los ingenieros de Elastic diseñaron una experiencia de búsqueda ampliamente aplicable para la observabilidad gracias a la entrada de miles de clientes y miembros de la comunidad. Por último, los SRE son los expertos de sus propios despliegues, y tú puedes imaginar una experiencia diferente óptima para las necesidades únicas de tu operación. Es por eso que puedes crear tus propios dashboards customizados y visualizaciones usando cualquier dato en Elastic y compartirlos con cualquiera que debería usarlos. Es tan simple como arrastrar y soltar.
Más allá del esfuerzo diario, Canvas es un medio creativo para expresar KPI de todos los equipos o de la cadena de liderazgo. Piensa en ellos como infografías de historias comerciales, en lugar de como dashboards que resuelven problemas técnicos. ¿Qué mejor forma de mostrar la experiencia del usuario actual que una cuadrícula de SLO disfrazada con caras felices o tristes? ¿Qué mejor forma de explicar que aún no se encontró la cantidad habitual de errores del día que un banner que diga: “Tienes 12 minutos para probar el código en producción”? (No lo hagas). Cuando conoces a tu audiencia, Canvas te permite enmarcar una situación compleja en una historia significativa que puedan seguir.

Ejemplos
Veamos algunos ejemplos prácticos de Elastic Observability. Cada escenario comienza con una alerta de un SLI diferente, y cada uno tiene un recorrido único hasta la resolución que puede involucrar a personas de distintos equipos. Elastic ayuda a los equipos de respuesta ante incidentes a progresar hacia una resolución rápida en diversas circunstancias.
Disponibilidad: ¿Por qué el servicio está inactivo?
Elastic notifica al equipo de guardia tras detectar un servicio que no responde y requiere el 99 % de disponibilidad. Ramesh del equipo de operaciones toma el mando. Hace clic en un enlace para ver el historial de tiempo de actividad. Verifica que el agente de monitoreo esté en buen estado para asegurarse de que sea poco probable que la alerta sea un falso positivo. Navega desde el servicio afectado para ver las métricas del host y después agrupa las métricas por hosts y contenedores. Ningún contenedor en el host reporta métricas. “El problema debe estar más arriba en la pila”. Vuelve a agrupar los datos por zonas de disponibilidad y hosts. Otros hosts están en buen estado en la zona afectada. Pero cuando filtra por hosts que ejecutan una réplica del servicio afectado, los hosts no reportan nada. “¿Por qué los hosts fallan solo con este servicio?”. Comparte un enlace al dashboard en el canal #ops en Slack. Una ingeniera dice que recientemente actualizó el cuaderno de estrategias que configura los hosts que ejecutan ese servicio. Revierte los cambios y las métricas comienzan a transmitirse a la vista. El problema desaparece. Resolvieron el problema en 12 minutos; mantuvieron el SLA del 99 %. Después, la ingeniera revisará los logs del host para saber por qué los cambios hicieron que el host quedara inactivo y así realizar un cambio adecuado.
Latencia: ¿Por qué el servicio está lento?
Elastic crea un ticket en el sistema de rastreo de problemas después de detectar una latencia anómala en varios servicios. Los desarrolladores de la aplicación se reúnen para revisar los rastreos de muestra y encontrar los intervalos que contribuyen la mayor parte de la latencia. Observan un patrón de latencia en los servicios que interactúan con un servicio de validación de datos. Sandeep, el desarrollador que lidera el servicio, analiza los intervalos. Los intervalos reportan búsquedas prolongadas en la base de datos, que se corroboran con una tasa de logs anómala del log de demora. Inspecciona las búsquedas y las reproduce en un entorno local. Las expresiones combinaban columnas no indexadas, lo cual había pasado desapercibido hasta que una inserción de datos masiva reciente causó una demora. Su optimización de la tabla mejora la latencia del servicio, pero no al SLO requerido. Cambia su investigación y compara el rastreo de muestra con una versión anterior del servicio usando filtros contextuales. Intervalos nuevos procesan los resultados de búsqueda. Sigue el rastreo de la pila en su entorno local hasta un método que evalúa un conjunto de expresiones regulares para cada resultado de búsqueda. Ajusta el código para compilar previamente los patrones antes del bucle. Después de confirmar los cambios, las latencias de los servicios vuelven a los SLO. Sandeep marca el problema como resuelto.
Errores: ¿Por qué el servicio genera errores?
Esther es una desarrolladora de software que lidera el servicio de registro de cuentas de una tienda en línea. Recibe una notificación del sistema de rastreo de problemas de su equipo. El problema indica que Elastic detectó una tasa de errores excesiva del servicio de registro de producción en la región de Singapur, lo cual podría poner en peligro negocios nuevos. Hace clic en un enlace en la descripción del problema que la lleva a un grupo de errores por un “Unicode Decode Error” (Error de decodificación de Unicode) no controlado en el endpoint de envío del formulario. Abre una muestra y encuentra detalles sobre la causa, incluidos el nombre del archivo, la línea de código en la que se generó el error, el rastreo de la pila, el contexto sobre el entorno e incluso el hash de confirmación del código fuente cuando se creó la aplicación. Ve las entradas del formulario de registro con algunos datos ocultos para cumplir con las regulaciones de privacidad. Observa que las entradas contienen caracteres Unicode vietnamitas. Reproduce el problema en su máquina local usando toda esta información. Después de corregir el controlador Unicode, confirma los cambios. El pipeline de CI/CD ejecuta las pruebas, las cuales se aprueban, y después despliega la aplicación actualizada en producción. Esther marca el problema como resuelto y continúa con su trabajo normal.
Saturación: ¿Dónde está por agotarse la capacidad?
Elastic crea un ticket en el sistema de rastreo de problemas después de detectar una anomalía en el uso de la memoria, y considera la región una influencia. Una operadora hace clic en un enlace para ver el uso de memoria regional en el tiempo. La región de Berlín muestra un pico repentino indicado con un punto rojo, tras el cual el uso aumenta lentamente en el tiempo. Pronostica que la memoria se agotará pronto si esto continúa. Observa las métricas de memoria recientes de todos los pods en todo el mundo. Aquellos en Berlín claramente se destacan como más saturados que los de otras regiones. Afina la búsqueda agrupando pods por nombre de servicio y filtrando por Berlín. Un servicio se destaca: el servicio de recomendación de productos. Expande la búsqueda para ver réplicas de este servicio en todo el mundo. En Berlín se observa el uso de memoria más alto y la mayor cantidad de pods de réplica. Explora hasta las transacciones de este servicio en Berlín. Comparte un enlace a este dashboard con el desarrollador de la aplicación encargado del servicio. El desarrollador lee el contexto de las transacciones. Observa una etiqueta personalizada para un indicador de característica que se lanzó solo en Berlín para una prueba A/B. Optimiza el servicio para realizar cargas diferidas en lugar de cargas diligentes de un set de datos que crece con el tiempo. El pipeline de CI/CD despliega el servicio actualizado, el uso de memoria vuelve a la normalidad y la operadora marca el problema como resuelto. No hay indicios de que este problema haya afectado los negocios, pero el pronóstico sugería que hubiese sido así de no haber detectado el pico.
Casos de estudio
Sobran las historias de éxito que demuestran el valor de Elastic Observability. Un ejemplo excelente es Verizon Communications, un conglomerado de telecomunicaciones americano y componente del Promedio Industrial Dow Jones (DJIA). En su Reporte anual de 2019 a la SEC, Verizon incluyó “la calidad, capacidad y cobertura de red” y “la calidad del servicio al cliente” entre los principales riesgos competitivos para sus negocios. Durante ese año, el 69.3 % de su total de USD 1 309 000 millones de ingresos provinieron del segmento inalámbrico que realizaba negocios como Verizon Wireless. Un equipo de operaciones de infraestructura en Verizon Wireless declaró que reemplazando su solución de monitoreo heredada con Elastic “redujeron el MTTR de 20–30 minutos a 2–3 minutos”, lo que se “traduce directamente en un servicio sobresaliente a los clientes”. La confiabilidad de servicios, la respuesta ante incidentes y el Elastic Stack son fundamentales para el posicionamiento competitivo de esta empresa y otras que deben entregar un servicio confiable.
¿Qué sigue?
Estos son los pasos que puedes seguir para maximizar la confiabilidad e inspirar confianza en tus servicios de software: