Was versteht man unter RAG (Retrieval Augmented Generation)?
Definition: Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) ist eine Technik zur Anreicherung der Textgenerierung mit Informationen aus privaten oder proprietären Datenquellen. Dabei wird ein Abrufmodell, das zum Durchsuchen großer Datensätze oder Wissensdatenbanken entwickelt wurde, mit einem Generationsmodell, wie etwa einem großen Sprachmodell (Large Language Model, LLM) kombiniert, das die Informationen entgegennimmt und sinnvolle Texte generiert.
Retrieval Augmented Generation kann die Relevanz von Sucherlebnissen verbessern, indem Kontext aus zusätzlichen Datenquellen bereitgestellt und die ursprüngliche Wissensbasis des LLM mit Training angereichert wird. Auf diese Weise lässt sich die Ausgabe des Sprachmodells verbessern, ohne das Modell neu zu trainieren. Als zusätzliche Informationsquellen können neue Informationen aus dem Internet, mit denen das LLM nicht trainiert wurde, proprietäre Geschäftsdaten oder sogar vertrauliche interne Dokumente von Unternehmen verwendet werden.
RAG ist hilfreich für Aufgaben wie das Beantworten von Fragen und die Inhaltsgenerierung, da generative KI mit dieser Methode externe Informationsquellen verwenden kann, um genauere und kontextbezogene Antworten zu liefern. Dabei werden Such- und Abrufmethoden – üblicherweise semantische Suche oder Hybridsuche – implementiert, um auf die Nutzerabsichten zu antworten und möglichst relevante Ergebnisse zu liefern.
Entdecken Sie Retrieval Augmented Generation (RAG) und finden Sie heraus, wie dieser Ansatz Ihre proprietären Echtzeitdaten mit generativen KI-Modellen verknüpfen kann, um bessere Endnutzererlebnisse und mehr Genauigkeit zu erreichen.
Was bedeutet Informationsabruf?
Informationsabruf (Information Retrieval, IR) ist ein Prozess, bei dem relevante Informationen aus einer Wissensquelle oder einem Datensatz gesucht und extrahiert werden. Dieser Vorgang ähnelt der Verwendung einer Suchmaschine, um Informationen im Internet nachzuschlagen. Sie geben eine Abfrage ein, und das System sucht Dokumente oder Webseiten, die vermutlich die von Ihnen gesuchten Informationen enthalten, und zeigt sie an.
Informationsabruf umfasst Techniken zum effizienten Indizieren und Durchsuchen großer Datensätze; dies erleichtert es Nutzern, die benötigten Informationen aus einem riesigen Pool verfügbarer Daten zu finden. Neben Web-Suchmaschinen werden IR-Systeme oft in digitalen Bibliotheken, in Dokumentverwaltungssystemen und in verschiedenen Anwendungen für den Zugang auf Informationen eingesetzt.
Die Entwicklung von KI-Sprachmodellen
KI-Sprachmodelle haben sich im Lauf der Jahre dramatisch weiterentwickelt:
- In den 1950er- und 1960er-Jahren steckte dieser Bereich noch in den Kinderschuhen und verwendete einfache, regelbasierte Systeme mit begrenztem Sprachverständnis.
- In den 1970er und 1980er Jahren wurden Expertensysteme eingeführt: Diese Systeme kodierten menschliches Wissen zur Problemlösung, hatten jedoch sehr begrenzte sprachliche Fähigkeiten.
- In den 90er-Jahren wurden vermehrt statistische Methoden mit datengestützten Herangehensweisen für Sprachaufgaben eingesetzt.
- In den 2000er-Jahren kamen Machine-Learning-Techniken wie Support Vector Machines auf, die verschiedene Arten von Textdaten in einem hochdimensionalen Raum kategorisierten, obwohl Deep Learning noch in den Anfängen steckte.
- Die 2010er-Jahre markierten einen Wendepunkt, was Deep Learning betrifft. Die Transformationsarchitektur veränderte die natürliche Sprachverarbeitung durch den Einsatz von Aufmerksamkeitsmechanismen, mit denen sich das Modell auf unterschiedliche Teile der Eingabesequenz konzentrieren konnte.
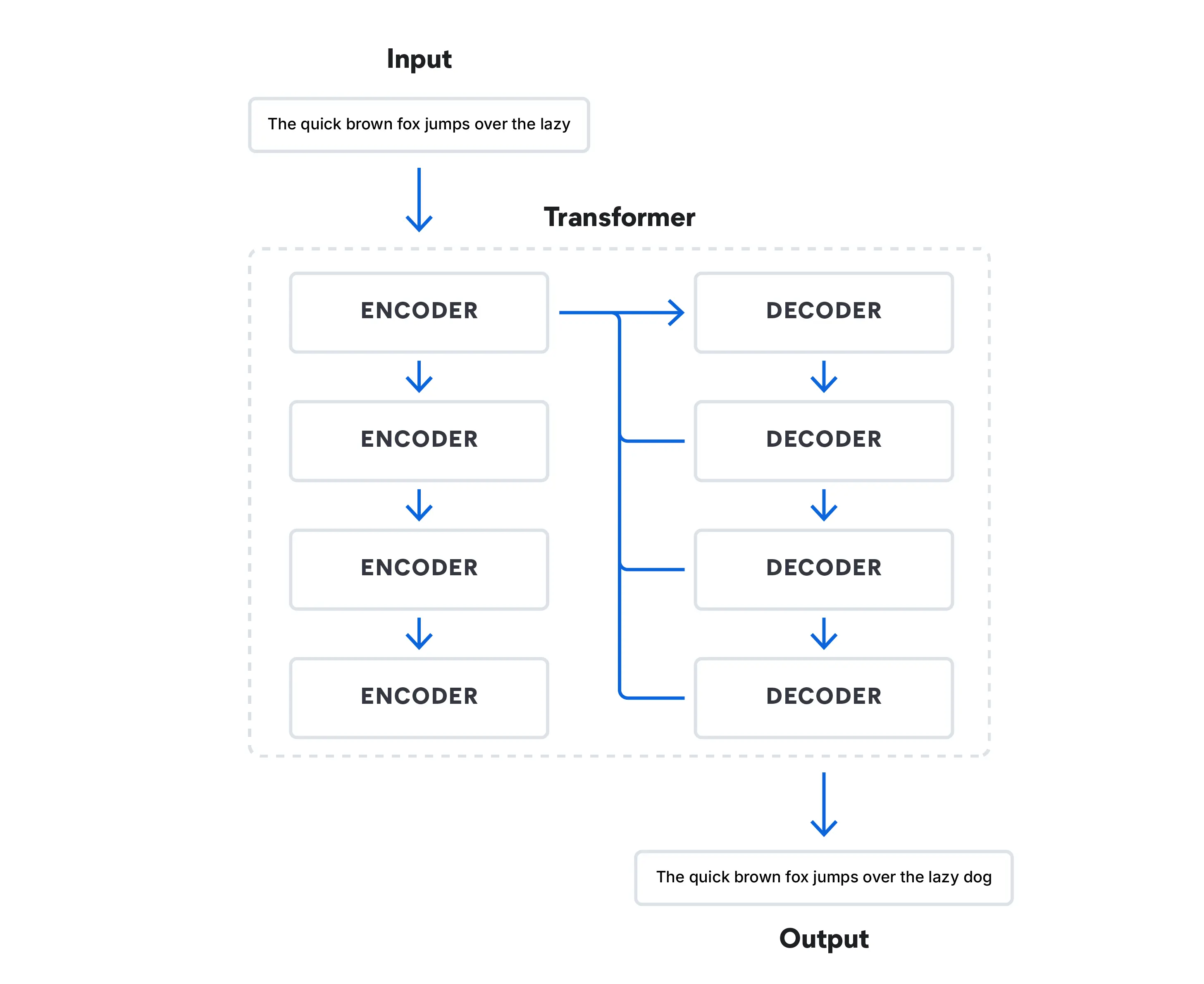
Heutzutage sind Transformationsmodelle in der Lage, menschliche Sprache zu simulieren, indem sie die Wahrscheinlichkeit des nächsten Worts in einer Abfolge von Wörtern vorhersagen. Diese Modelle haben den Bereich revolutioniert und LLMs wie Google BERT (Bidirectional Encoder Representations from Transformers) ermöglicht.
Aktuell wird eine Kombination aus umfangreich vortrainierten Modellen mit spezialisierten Modellen für bestimmte Aufgaben eingesetzt. Modelle wie RAG gewinnen an Beliebtheit und erweitern den Umfang von generativer KI -Sprachmodellen weit über die Einschränkungen gewöhnlicher trainierter Modelle hinaus. 2022 hat OpenAI ChatGPT vorgestellt, das wohl bekannteste LLM, das auf einer Transformationsarchitektur basiert. Die Konkurrenz setzt sich zusammen aus chatbasierten Foundation-Modellen wie Google Bard und Microsoft Bing Chat. Das von Meta veröffentlichte LLaMa 2 ist kein Chatbot für Verbraucher, sondern ein für LLM-Forscher frei verfügbares Open-Source-LLM.
Verwandt: Die Wahl eines LLM: Der Einsteiger-Leitfaden für Open-Source-LLMs für das Jahr 2024
Wie funktioniert RAG?
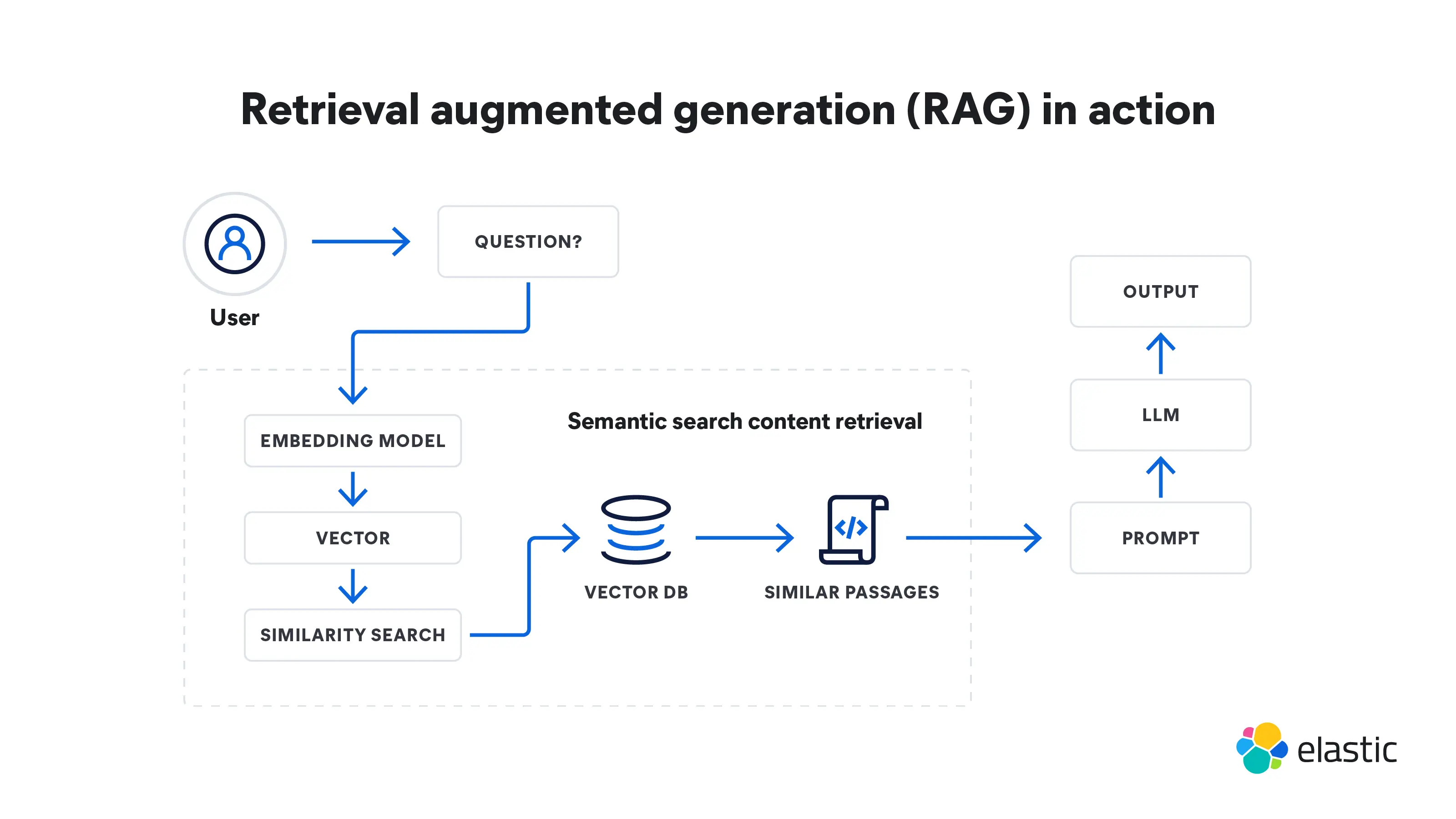
Retrieval Augmented Generation ist ein mehrstufiger Prozess, der vom Datenabruf zur Generierung von Daten führt. So funktioniert dieser Prozess:
Abruf
- RAG beginnt mit der Eingabe einer Abfrage. Dabei kann es sich um die Frage eines Nutzers oder eine beliebige Texteingabe handeln, die eine ausführliche Antwort erfordert.
- Ein Abrufmodell sammelt relevante Informationen aus Wissensdatenbanken, Datenbanken oder externen Quellen, oder auch aus mehreren Quellen gleichzeitig. Die Orte, an denen das Modell sucht, hängen von der gestellten Frage ab. Diese abgerufenen Informationen dienen jetzt als Referenzquelle für alle Fakten und Kontextdaten, die das Modell benötigt.
- Die abgerufenen Informationen werden in Vektoren in einem hochdimensionalen Raum umgewandelt. Diese Wissensvektoren werden in einer Vektordatenbank gespeichert.
- Das Abrufmodell ordnet die abgerufenen Informationen gemäß ihrer Relevanz für die ursprüngliche Abfrage. Dokumente oder Textpassagen mit der höchsten Bewertung werden zur weiteren Verarbeitung ausgewählt.
Generierung
- Anschließend verwendet ein Generationsmodell, etwa ein LLM, die abgerufenen Informationen, um Antworten in Textform zu generieren.
- Der generierte Text kann anschließend weitere Nachbereitungsschritte durchlaufen, um sicherzustellen, dass er grammatikalisch korrekt und zusammenhängend ist.
- Diese Antworten sind insgesamt exakter und im Kontext sinnvoller, weil sie mit den zusätzlichen Informationen angereichert wurden, die das Abrufmodell bereitgestellt hat. Diese Fähigkeit ist besonders wichtig in Spezialbereichen, in denen öffentlich zugängliche Daten aus dem Internet nicht ausreichen.
RAG-Vorteile
Retrieval Augmented Generation bietet zahlreiche Vorteile gegenüber isoliert arbeitenden Sprachmodellen. Die generierten Antworten werden unter anderem auf die folgenden Arten verbessert:
- RAG sorgt dafür, dass Ihr Modell die neuesten und aktuellsten Fakten und relevanten Informationen kennt, weil externe Referenzen regelmäßig aktualisiert werden können. Auf diese Weise wird sichergestellt, dass die generierten Antworten auch aktuellste Informationen berücksichtigen, die für die anfragenden Nutzer möglicherweise relevant sind. Sie können auch Sicherheit auf Dokumentebene implementieren, um den Zugriff auf Daten in einem Datenstrom zu steuern und Zugriffsberechtigungen auf bestimmte Dokumente einzuschränken.
- RAG ist eine kostengünstige Option, die weniger Computing und Speicher erfordert. Sie brauchen also kein eigenes LLM und müssen kein eigenes Modell mit hohem Zeit- und Geldaufwand trainieren.
- Genauigkeit zu versprechen ist eine Sache, aber sie nachweisen zu können, ist eine ganz andere. RAG kann externe Quellen zitieren und den Nutzern vorlegen, um die Antworten zu untermauern. Bei Bedarf können die Nutzer diese Quellen anschließend auswerten, um die Genauigkeit der erhaltenen Antworten zu überprüfen.
- LLM-basierte Chatbots können zwar relevantere Antworten liefern als ältere, skriptbasierte Versionen, aber RAG kann diese Antworten noch weiter anpassen. Dies liegt daran, dass dieses Modell Abrufmethoden (üblicherweise semantische Suche) verwendet, um verschiedene kontextbasierte Punkte zu referenzieren und Antworten unter Berücksichtigung der ermittelten Absicht zu generieren.
- Bei komplexen Anfragen, für die ein LLM nicht trainiert wurde, entstehen manchmal ungenaue oder sogar falsche Antworten, sogenannte Halluzinationen. RAG kann genauere Antworten auf mehrdeutige Anfragen liefern, da die Antworten mit zusätzlichen Referenzen aus relevanten Datenquellen gestützt werden.
- RAG-Modelle sind vielseitig und können für zahlreiche verschiedene Aufgaben im Bereich der natürlichen Sprachverarbeitung eingesetzt werden, wie etwa Dialogsysteme, Inhaltsgenerierung und Informationsabruf.
- Von Menschen erstellte KI-Systeme haben oft mit Verzerrungen zu kämpfen. Durch die Nutzung externer Quellen kann RAG die Verzerrungen in den gelieferten Antworten minimieren.
Gegenüberstellung: Retrieval Augmented Generation und Feinjustierung
Retrieval Augmented Generation und Feinjustierung sind zwei verschiedene Herangehensweisen beim trainieren von KI-Sprachmodellen. RAG kombiniert das Abrufen verschiedenster externer Wissensquellen mit der Textgenerierung, während bei der Feinjustierung ein eng gesteckter Datenbereich für einen sehr spezifischen Zweck verwendet wird.
Bei der Feinjustierung wird ein vorab trainiertes Modell mit spezialisierten Daten für einen bestimmten Aufgabenbereich zusätzlich trainiert. Dabei werden die Gewichtungen und Parameter des Modells an den neuen Datensatz angepasst, damit das Modell aufgabenspezifische Muster lernen kann, ohne das Wissen aus dem ursprünglichen Training zu verlieren.
Die Feinjustierung eignet sich für alle Arten von KI. Ein einfaches Beispiel ist das Erkennen von Kätzchen beim Identifizieren von Katzenfotos im Internet. In sprachbasierten Modellen ist die Feinjustierung neben der Textgenerierung auch hilfreich in Aufgabenbereichen wie Textklassifizierung, Standpunktanalyse und Erkennung benannter Entitäten. Dieser Prozess ist jedoch oft extrem zeitraubend und kostenintensiv. RAG beschleunigt den Prozess und konsolidiert diese Kosten mit niedrigeren Computing- und Speicheranforderungen.
Durch den Zugang zu externen Ressourcen ist RAG besonders hilfreich für Aufgaben, die nur mit Echtzeit- oder dynamischen Informationen aus dem Internet oder aus Wissensdatenbanken des Unternehmens umfangreich gelöst und beantwortet werden können. Die Feinabstimmung hat unterschiedliche Stärken: Wenn die Aufgabe gut definiert ist und das Ziel darin besteht, die Leistung speziell für diese Aufgabe zu optimieren, kann die Feinabstimmung sehr effizient sein. Beide Techniken haben den Vorteil, dass kein LLM für jede Aufgabe von Grund auf trainiert werden muss.
Herausforderungen und Einschränkungen bei Retrieval Augmented Generation
RAG bietet zwar umfassende Vorteile, ist jedoch auch mit gewissen Herausforderungen und Einschränkungen verbunden:
- RAG verlässt sich auf externes Wissen. Wenn die abgerufenen Informationen falsch sind, wirkt sich dies auf die Genauigkeit der Ergebnisse aus.
- Die RAG-Abrufkomponente durchsucht große Wissensdatenbanken oder das Internet. Dieser Vorgang ist unter Umständen rechenintensiv und langsam, jedoch immer noch schneller und kostengünstiger als die Feinjustierung.
- Die nahtlose Integration der Abruf- und Generationskomponenten muss sorgfältig geplant und optimiert werden, was wiederum zu Schwierigkeiten in den Bereichen Schulung und Bereitstellen führen kann.
- Beim Abrufen von Informationen aus externen Quellen müssen Datenschutzbedenken berücksichtigt werden, wenn sensible Daten verarbeitet werden. Anforderungen im Hinblick auf Privatsphäre und Compliance können die für RAG verfügbaren Quellen einschränken. Diese Einschränkung lässt sich jedoch durch Zugriff auf Dokumentebene beheben, indem Sie einzelnen Rollen spezifische Zugriffs- und Sicherheitsberechtigungen erteilen.
- RAG basiert auf Fakten. Daher eignet sich das Modell weniger zum Generieren fantasievoller oder fiktiver Inhalte und ist für die kreative Inhaltserstellung nur begrenzt tauglich.
Zukunftstrends für Retrieval Augmented Generation
Die wichtigsten Zukunftstrends für Retrieval Augmented Generation befassen damit, Effizienz und Anpassbarkeit der RAG-Technologie für verschiedene Anwendungsbereiche zu steigern. Behalten Sie die folgenden Trends im Auge:
Personalisierung
RAG-Modelle werden weiterhin nutzer-spezifisches Wissen einbeziehen. Auf diese Weise können sie noch relevantere Antworten liefern, insbesondere in Anwendungsbereichen wie Inhaltsempfehlungen und virtuelle Assistenten.
Anpassbares Verhalten
Zusätzlich zur Personalisierung könnten die Benutzer selbst mehr Kontrolle darüber haben, wie sich RAG-Modelle verhalten und reagieren, um ihnen zu helfen, die gewünschten Ergebnisse zu erzielen.
**Skalierbarkeit**
RAG-Modelle werden in der Lage sein, immer größere Datenmengen und Nutzerinteraktionen zu verarbeiten.
Hybride Modelle
Integration von RAG mit anderen KI-Techniken (z.B. Verstärkendes Lernen) wird noch vielseitigere und kontextbewusstere Systeme ermöglichen, die verschiedene Datentypen und Aufgaben gleichzeitig bewältigen können.
**Echtzeit- und latenzfreie Bereitstellung**
Mit
zunehmender Abruf- und Antwortgeschwindigkeit werden RAG-Modelle immer häufiger in Anwendungen eingesetzt, die schnelle Antworten voraussetzen, wie etwa Chatbots und virtuelle Assistenten.
Technische Trends 2024 – Webinar zu den Entwicklungen bei Technologien in den Bereichen Suche und generative KI. Sehen Sie sich dieses Webinar an, um mehr über Best Practices, neue Verfahren und die Top-Trends zu erfahren, die für Entwickler:innen 2024 eine wichtige Rolle spielen werden.
Retrieval Augmented Generation mit Elasticsearch
Mit Elasticsearch können Sie RAG-basierte Sucherlebnisse für Ihre generative KI-Apps und Websites sowie für Ihre Kunden- oder Mitarbeitererlebnisse erstellen. Elasticsearch bietet ein umfassendes Toolkit mit den folgenden Möglichkeiten:
- Speichern und Durchsuchen proprietärer Daten und anderer externer Wissensdatenbanken als Kontextquellen
- Generieren extrem relevanter Suchergebnisse aus Ihren Daten mit vielfältigen Methoden: textbezogene, Vektor-, Hybrid- oder semantische Suche
- Exaktere Antworten und ansprechendere Erlebnisse für Ihre Nutzer
Finden Sie heraus, wie Elasticsearch Ihrem Unternehmen eine bessere generative KI bieten kann.
Weitere RAG-Ressourcen entdecken
- Erkunden Sie den KI-Spielplatz
- Gehen Sie über die RAG-Grundlagen hinaus
- Elasticsearch – die relevanteste Suchmaschine für RAG
- Die Wahl eines LLM: Der Einsteiger-Leitfaden für Open-Source-LLMs für das Jahr 2024
- Erläuterungen zu den Algorithmen für die KI-gestützte Suche
- Chatbot-Entwicklung: Tipps und Fallstricke für Entwickler in einer KI-gesteuerten Welt
- Technologie-Trends für 2024: Weiterentwicklung von Suche und generativen KI-Technologien
- Mit LLMs schneller Prototypen entwickeln und integrieren
- Die weltweit am häufigsten heruntergeladene Vektordatenbank – Elasticsearch
- Entmystifizierung von ChatGPT: Verschiedene Methoden zum Aufbau einer KI-Suchfunktion
- Retrieval vs. poison — Fighting AI supply chain attacks