Was versteht man unter Informationsabruf?
Definition: Informationsabruf
Informationsabruf (Information Retrieval, IR) ist ein Prozess zum effektiven und effizienten Abruf relevanter Informationen aus großen Mengen an unstrukturierten oder teilweise strukturierten Daten. IR-Systeme helfen beim Suchen, Auffinden und Anzeigen von Informationen, die mit den Suchabfragen oder dem Informationsbedarf von Nutzern übereinstimmen.
Der Informationsabruf ist die am häufigsten eingesetzte Methode des Informationszugriffs und wird tagtäglich von Milliarden von Menschen in Form von Suchmaschinen eingesetzt. Mit verschiedenen Modellen, Algorithmen und immer komplexeren Techniken (z. B. Vektorsuche) ermöglichen Informationsabrufsysteme Suchzugriffe über eine riesige und ständig wachsende Palette an Quellen, inklusive Dokumente, Elemente in Dokumenten, Metadaten sowie Datenbanken mit Texten, Bildern, Video und Audio.
Eine kurze Geschichte des Informationsabrufs
Die Geschichte des Informationsabrufs lässt sich bis in die Antike zurückverfolgen, als Bibliotheken und Archive eingerichtet wurden, um Informationen zu organisieren und zu speichern, inklusive der Indexierung und Alphabetisierung wissenschaftlicher Arbeiten. Im 19. Jahrhundert wurden Lochkarten eingesetzt, um Informationen zu verarbeiten, und im Jahr 1931 erhielt Emanuel Goldberg ein Patent für das erste erfolgreiche elektromechanische Informationsabrufgerät, die sogenannte „statistische Maschine“ zum Durchsuchen von auf Film kodierten Daten.
Bis Mitte des 20. Jahrhunderts hatte sich der Informationsabruf parallel zur Entwicklung moderner Computer zu einer wissenschaftlichen Disziplin normalisiert. Gerard Salton und Hans Peter Luhn entwickelten frühe Modelle für den automatisierten Dokumentabruf. In den 1960er-Jahren entwickelten Salton und seine Kollegen an der Cornell-Universität das SMART-Informationsabrufsystem. Dieser Meilenstein gilt als Fundament moderner Techniken und Konzepte für den Informationsabruf, wie etwa die Begriff-Dokument-Matrix, das Vektorraummodell, Relevanz-Feedback und die Rocchio-Klassifizierung.
In den 1970er-Jahren hatte sich das Gebiet mit fortschrittlichen Abruftechniken, probabilistischen Modellen und vollständig gegliederten Vektorverarbeitungssystemen bereits erheblich weiterentwickelt. Mit dem Aufkommen von Suchmaschinen gegen Ende der 1990er-Jahre wurden die früher hauptsächlich Universitäten, Instituten und Bibliotheken vorbehaltenen Informationsabrufsysteme und -modelle im Massenbetrieb eingesetzt.
Arten von Informationsabrufmodellen
Verschiedene Arten von Informationsabrufmodellen erfüllen spezifische Zwecke und verwenden bestimmte Prozesse, um relevante Informationen abzurufen. Neben klassischen Modellen, die das Fundament dieser Disziplin bilden, gibt es auch weniger klassische Modelle, die versuchen, die Einschränkungen herkömmlicher Ansätze zu lösen. Manche alternative Modelle gehen sogar noch weiter und nutzen moderne Technologien wie Machine Learning und Sprachmodelle. Einige der meistverwendeten Arten von Informationsabrufmodellen sind:
Boolesches Modell
Das Boolesche Modell ist eines der einfachsten und ältesten Informationsabrufmodelle. Es basiert auf der Booleschen Logik und verwendet Operatoren wie etwa UND, ODER und NICHT, um Abfragebegriffe zu kombinieren. Dokumente werden als Sätze von Begriffen dargestellt, und Abfragen werden verarbeitet, um Dokumente zu finden, die den angegebenen Bedingungen entsprechen. Das Boolesche Modell ist zwar effektiv für exakte Übereinstimmungen mit Abfragen, kann jedoch Dokumente nicht nach Relevanz ordnen oder teilweise Übereinstimmungen finden.
Vektorraummodell
In diesem Modell werden Dokumente und Abfragen als Vektoren in einem multidimensionalen Raum dargestellt. Jede Dimension entspricht einem einzigartigen Begriff, und der Wert in jeder Dimension entspricht der Bedeutung und der Häufigkeit des Begriffs im Dokument bzw. der Abfrage. Anschließend wird die Kosinus-Ähnlichkeit zwischen dem Abfragevektor und den Dokumentvektoren berechnet, um die Relevanz von Dokumenten für die Abfrage zu ermitteln. Das Vektorraummodell wurde unter anderem entwickelt, um die Einschränkungen des Booleschen Modells zu beheben. Es kann Ergebnisse nach einer Relevanzbewertung geordnet zurückgeben und wird häufig bei der Textsuche eingesetzt.
Probabilistisches Modell
Dieses Modell ermittelt die Wahrscheinlichkeit, mit der ein Dokument für eine bestimmte Abfrage relevant ist. Dabei werden Faktoren wie Begriffshäufigkeit und Dokumentlänge berücksichtigt, um die Relevanzwahrscheinlichkeit zu berechnen. Dieses Modell ist besonders hilfreich für den Umgang mit großen Datenmengen. Es verwendet gewichtete Statistiken und eignet sich daher hervorragend, um geordnete Ergebnisse zurückzugeben.
Latente semantische Indexierung (Latent Semantic Indexing, LSI)
LSI verwendet die Singulärwertzerlegung (Singular Value Decomposition, SVD), um die semantischen Beziehungen zwischen Begriffen und Dokumenten zu erfassen. Wie auch die semantische Suche arbeitet die semantische Indexierung mit Absicht und Kontext, um inhaltlich miteinander verwandte Dokumente zu identifizieren, auch wenn sie unterschiedliche Begriffe enthalten. Durch diese Fähigkeit ist LSI besonders hilfreich, um die kontextbezogene Bedeutung von Wörtern in einem Text zu extrahieren.
Okapi BM25
BM25 ist eine besonders beliebte Variante des probabilistischen Modells und wird eingesetzt, um Ergebnisse nach deren Suchrelevanz geordnet zurückzugeben. Mit dieser Methode ermitteln Suchmaschinen die Relevanz eines Dokuments für eine bestimmte Suchabfrage. Sie ordnet eine Reihe von Dokumenten anhand der Abfragebegriffe in den einzelnen Dokumenten, unabhängig von den Beziehungen zwischen den Begriffen in einem Dokument, und umfasst zahlreiche Bewertungsfunktionen mit unterschiedlichen Komponenten und Parametern. BM steht für „Best Matching“ (beste Übereinstimmung).
Warum ist der Informationsabruf wichtig?
Im Informationszeitalter wird jede Sekunde eine Menge an Daten generiert, die früher unvorstellbar war. Ohne brauchbare Zugriffsmethoden sind diese Daten in der Praxis nutzlos. Informationsabrufsysteme sorgen dafür, dass die Nutzer relevante Informationen im ständig wachsenden Datenrauschen finden können.
Der Informationsabruf ist entscheidend für praktisch alle Branchen und Fachbereiche in der modernen Welt, von Universitäten und E-Commerce bis hin zu Gesundheitswesen und Verteidigung. Diese Schnittstelle zwischen Mensch und Computer unterstützt uns bei Entscheidungen, in der Forschung und beim Erlernen neuer Fähigkeiten, sowohl auf der Unternehmens- als auch auf einer persönlichen Ebene. Egal ob wir auf unserem lokalen Desktop die Weltnachrichten durchsuchen, Genforschung betreiben oder Spam herausfiltern, der Informationsabruf ist für praktisch alle Bereiche unseres Lebens entscheidend.
Suchmaschinen verwenden Informationsabrufmodelle, um exakte Suchergebnisse zu liefern. E-Commerce-Plattformen nutzen Abrufmodelle, um Produkte anhand von Präferenzen und Verhaltensweisen der Nutzer zu empfehlen. Digitale Bibliotheken nutzen Informationsabrufwissenschaften, um die Nutzer bei ihren Nachforschungen zu unterstützen. Im Gesundheitswesen helfen Informationsabrufsysteme, Datenbanken nach relevanten Patientenakten, medizinischen Forschungsarbeiten und Behandlungsprotokollen zu durchsuchen. Juristen nutzen den Informationsabruf, um große Mengen an Gerichtsverfahren nach Präzedenzfällen zu durchsuchen.
Wie funktionieren Informationsabrufsysteme?
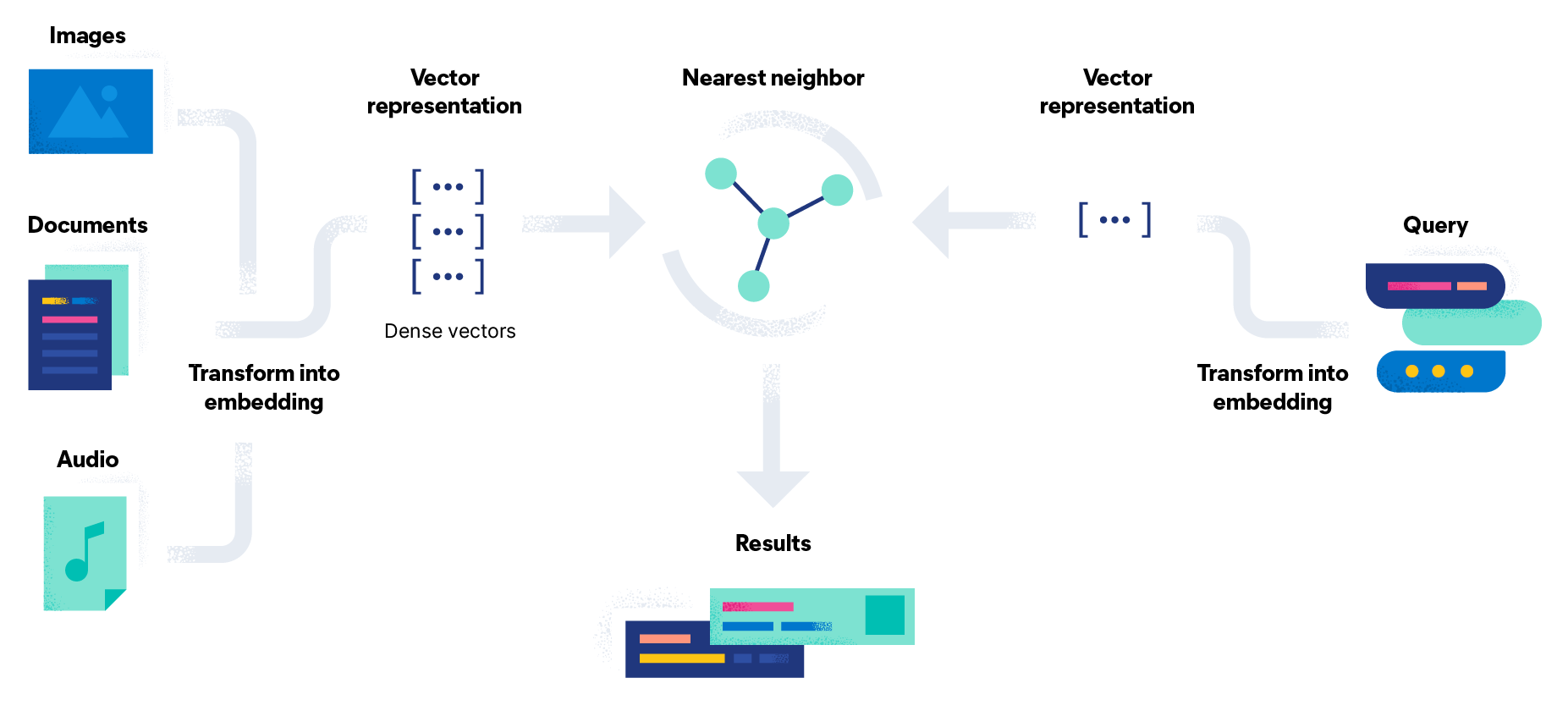
Der Informationsabruf wird normalerweise ausgelöst, wenn ein Nutzer eine formale Abfrage in ein System eingibt, um seinen Informationsbedarf auszudrücken. Das Informationsabrufsystem erstellt einen Index von Dokumenten in einer Inhaltssammlung oder einer Informationsdatenbank. Datenobjekte, beispielsweise aus Textdokumenten, Bildern, Audio und Video, werden verarbeitet, um relevante Begriffe und Sekundärdaten zu extrahieren. Diese Entitäten werden anschließend mithilfe von Datenstrukturen effizient gespeichert und abgerufen.
Die von Nutzern übermittelten Abfragen werden verarbeitet, um relevante Begriffe und deren Bedeutung zu identifizieren. Das System ordnet Dokumente nach ihrer Relevanz für die Abfrage. Informationsabrufmodelle und -algorithmen werden oft eingesetzt, um eine numerische Bewertung dafür zu errechnen, wie genau einzelne Objekte in der Sammlung oder Datenbank mit der Abfrage übereinstimmen. Viele Abfragen ergeben keine genaue Übereinstimmung. In diesen Fällen werden die relevantesten Dokumente als geordnete Liste zurückgegeben. Diese geordneten Ergebnisse sind einer der wichtigsten Unterschiede zwischen dem Informationsabruf und der Suche in Datenbanken.
Hauptkomponenten von Informationsabrufsystemen
Informationsabrufsysteme bestehen aus mehreren wichtigen Komponenten:
Dokumentsammlung
Die Sammlung der Dokumente, aus denen das System Informationen abrufen kann.
Indexierungskomponente
Quelldaten und Dokumente werden verarbeitet, um einen Index zu erstellen, der Begriffe und Daten mit den Dokumenten verknüpft, in denen sie vorkommen. Dazu werden oft dedizierte und optimierte Datenstrukturen verwendet.
Abfrageverarbeitungsmodul
Das Abfrageverarbeitungsmodul analysiert Nutzerabfragen und Schlüsselwörter, um sie für den Abgleich mit den indexierten Entitäten vorzubereiten.
Bewertungsalgorithmus
Der Bewertungsalgorithmus ermittelt die Relevanz von Dokumenten für eine Abfrage und weist ihnen Bewertungen zu. Der meistverwendete Bewertungsalgorithmus ist BM25 (Best Match 25). Er zeichnet sich durch seinen speziellen Umgang mit der Begriffshäufigkeit aus und vermeidet es, Dokumente mit Schlüsselwörtern und wiederholt auftretenden Begriffen zu übersättigen.
Benutzeroberfläche
Die Benutzeroberfläche ist die Schnittstelle, über die die Nutzer mit dem System interagieren, in der sie Abfragen eingeben und Ergebnisse angezeigt bekommen. Hier können die Ergebnisse justiert werden, je nachdem, wie relevant sie für die Nutzeranfrage sind. Beispielsweise können Mechanismen eingesetzt werden, mit denen die Nutzer Feedback zur Relevanz der abgerufenen Dokumente abgeben, um zukünftige Abrufvorgänge zu verbessern.
Vorteile des Informationsabrufs
Der Informationsabruf bietet unter anderem die folgenden wichtigen Vorteile:
- Effizienter Zugriff auf Informationen: Informationsabrufsysteme dienen hauptsächlich dazu, den Menschen unglaubliche Mengen an Zeit und Arbeit einzusparen. Mit dem Informationsabruf können Nutzer schnell auf relevante Informationen zugreifen, ohne gigantische Mengen an Dokumenten und Daten manuell zu durchsuchen.
- Wissensentdeckung: Der Informationsabruf ist ein leistungsfähiges Werkzeug, um Daten sinnvoll zu nutzen. Mit dem Informationsabruf können wir Trends, Muster und Beziehungen in Daten identifizieren, die andernfalls nicht erkennbar wären.
- Personalisierung: Manche Informationsabrufsysteme nutzen die Präferenzen und Verhaltensweisen der Nutzer, um möglichst relevante Ergebnisse zurückzugeben.
- Entscheidungshilfe: Experten können fundierte Entscheidungen treffen, wenn sie die wichtigsten Informationen zum richtigen Zeitpunkt griffbereit haben.
Herausforderungen und Einschränkungen beim Informationsabruf
Trotz aller wichtigen Fortschritte ist der Informationsabruf noch lange nicht perfekt. Es ist wichtig, die folgenden Probleme, Herausforderungen und Einschränkungen zu berücksichtigen:
Mehrdeutigkeit Natürliche Sprache ist von Natur aus mehrdeutig, was die exakte Auswertung von Nutzeranfragen erschwert. Verwandte Probleme wie Ungenauigkeit und Ungewissheit können sich auf Indexierung und Auswertung auswirken, insbesondere beim Umgang mit Bildern und Videos.
Relevanz Relevanz ist oft subjektiv und kann stark vom Kontext und der Absicht der Nutzer abhängen. Kriterien zur Ermittlung von Relevanz und Bedeutung unterliegen oft unvollkommenen und allgemeinen Normen, die nicht immer die spezifischen Anforderungen einzelner Nutzer wiedergeben.
Semantische Lücken Aufgrund der Lücke zwischen Textdarstellung und menschlichem Verständnis haben Abrufsysteme manchmal Schwierigkeiten damit, die tiefere Bedeutung von Inhalten zu erfassen. Mangelnde Klarheit der Informationen und der Ausdrucksweise von Nutzern ist eine bedeutende Hürde beim Informationsabruf. Durch erweiterte natürliche Sprachverarbeitung mit KI-Unterstützung wird versucht, diese Lücken im Hinblick auf Semantik und Mehrdeutigkeit zu schließen.
Skalierbarkeit Mit zunehmendem Datenvolumen ist es oft komplex, effiziente und effektive Abruf- und Indexierungsmechanismen zu pflegen, und der Bedarf an Ressourcen und Rechenleistung nimmt zu.
Zukunftstrends beim Informationsabruf
Angesichts aktueller Neuerungen in den Bereichen generative KI und Machine Learning steht der Informationsabruf möglicherweise vor einem transformativen Wandel.
Erweiterte Machine-Learning-Techniken werden bereits eingesetzt, um den Informationsabruf zu verbessern, indem sie durch Nutzerinteraktionen lernen und sich an Kontext, Standort und Präferenzen anpassen. Durch verbesserte natürliche Sprachverarbeitung und semantische Analysen wird das Verständnis von Nutzeranfragen und Dokumentinhalten verbessert. Abrufsysteme werden ebenfalls weiterentwickelt, um die ständig wachsende Flut an Multimedia-Inhalten effektiv verarbeiten zu können.
Generative KI hat das Potenzial, den Informationsabruf von Grund auf zu revolutionieren. Anstelle der geordneten Listen, an die wir uns gewöhnt haben und in denen wir vorhandene Links und Dokumente manuell suchen müssen, erhalten wir echte Antworten auf unsere Fragen. Der Kontext bleibt von Frage zu Frage erhalten und ermöglicht komplexe, mehrstufige Anfragen im Unterhaltungsformat, bei denen die Barrieren von menschlicher Sprachverarbeitung und Absicht praktisch eingerissen werden. Anstatt die Antworten selbst zusammenstückeln zu müssen, nehmen Suchmaschinen uns die Arbeit ab und stellen Informationen zu spezifischen, maßgeschneiderten Ergebnissen in der Form von Originalinhalten zusammen, die genau das enthalten, wonach wir gesucht haben, ohne unnötige Extras.
Technische Trends 2024 – Webinar zu den Entwicklungen bei Technologien in den Bereichen Suche und generative KI. Sehen Sie sich dieses Webinar an, um mehr über Best Practices, neue Verfahren und die Top-Trends zu erfahren, die für Entwickler:innen 2024 eine wichtige Rolle spielen werden.
Informationsabruf mit Elasticsearch
Elastic bemüht sich darum, die Informationsabruffunktionen im Elastic Stack ständig weiterzuentwickeln. Unser neuestes Abrufmodell, der Elastic Learned Sparse Encoder, erweitert die vorkonfigurierten Elastic-Abruffunktionen mit einem vorab trainierten Sprachmodell. Um Ihnen ein echtes Ein-Klick-Erlebnis zu bieten, haben wir diese Lösung mit der Elasticsearch Relevance Engine kombiniert.
Elasticsearch bietet auch herausragende lexikalische Abruffunktionen und umfassende Tools zum Kombinieren der Ergebnisse verschiedener Abfragen. Dieses Konzept wird auch als Hybrid-Abruf bezeichnet. Außerdem erweitern wir die Fähigkeiten von Chatbots mit NLP und Vektorsuche, veröffentlichen Drittanbietermodelle für natürliche Sprachverarbeitung für Texteinbettungen und überprüfen unsere eigene Leistung mit einer Teilmenge von BEIR.
Weitere Ressourcen zum Thema Informationsabruf (in englischer Sprache)
- Improving information retrieval in the Elastic Stack: Introducing Elastic Learned Sparse Encoder, our new retrieval model
- Improving information retrieval in the Elastic Stack: Steps to improve search relevance
- Improving information retrieval in the Elastic Stack: Benchmarking passage retrieval
- Improving information retrieval in the Elastic Stack: Hybrid retrieval
- Erläuterungen zu den Algorithmen für die KI-gestützte Suche
Nächste Schritte
Wir können Ihnen helfen, aus den Daten Ihres Unternehmens Erkenntnisse zu gewinnen. Hier sind vier Vorschläge für Sie, was Sie als Nächstes tun sollten:
- Probieren Sie Elastic Cloud kostenlos aus, um zu entdecken, wie Elastic Ihr Unternehmen unterstützen kann.
- Lernen Sie unsere Lösungen bei einer Tour kennen, entdecken Sie die Elasticsearch-Plattform und deren Vorteile für Ihre Anforderungen.
- Erfahren Sie, wie Sie generative KI in großen Unternehmen bereitstellen können.
- Wenn Sie Leute kennen, die diesen Artikel interessant finden könnten, leiten Sie ihn weiter. Teilen Sie den Artikel per E‑Mail, LinkedIn, X oder Facebook.