What’s new in Elasticsearch, Kibana, and Elastic Cloud for 7.15
Elastic Cloud customers can now ingest data more simply, quickly, and securely, and the latest updates to the core Elastic Stack provide users with new tools for maximizing performance and exploring their data.
The 7.15 release of Elastic Cloud brings new integrations with Google Cloud that allow customers to ingest Google Cloud services data directly into their Elastic Cloud deployments and take advantage of additional network security with Google Cloud Private Service Connect. Plus, the Elastic Stack brings enhancements to Elasticsearch and Kibana including improved data transfer, better resiliency, and more flexible data ingest and analysis.
Ready to roll up your sleeves and get started? We have the links you need:
- Try out the new features on Elastic Cloud
- Download the latest versions of Elasticsearch, Kibana, Elastic Cloud Enterprise, Elastic Cloud on Kubernetes
- Release notes: Elasticsearch, Kibana, Elastic Cloud, Elastic Cloud Enterprise, Elastic Cloud on Kubernetes
- Elasticsearch breaking changes
What’s new in Elastic Cloud for 7.15
Google Cloud Dataflow native integration
Introducing the first ever native Google Cloud data source integration for Elastic Cloud — Google Cloud Dataflow. This integration allows customers to ship Pub/Sub, Big Query, and Cloud Storage data directly into Elastic Cloud deployments without having to set up an extra intermediary data shipper, utilizing Google Cloud’s native serverless extract, transform, load (ETL) service. Customers benefit from simplified data architecture and increased speed when ingesting data into Elastic Cloud. Read our blog post on these integrations to learn more.
Google Cloud Private Service Connect
We’re excited to announce that support for Google Private Service Connect is now generally available. Google Private Service Connect provides private connectivity from Google Cloud virtual private cloud (VPC) to Elastic Cloud deployments. The traffic between Google Cloud and Elastic Cloud deployments on Google Cloud travels only within the Google Cloud network, utilizing Private Service Connect endpoints and ensuring that customer data stays off the Internet. Read the blog post to learn more.
ARM-based (Graviton2) instances on AWS
Soon, customers will be able to leverage Amazon Web Services (AWS) ARM-based Graviton2 virtual machines (VMs) for Elastic Cloud deployments running on AWS. VMs running on Graviton2 hardware provide up to 40% better price performance compared to previous generation x86-based instances. Check out the blog post to learn more.
What’s new in Elasticsearch 7.15
Improved data resiliency and reduced data transfer traffic
Since the inception of Elasticsearch, we’ve been on a mission to be the best and fastest search engine around. To further this mission, we’ve lowered the costs of storing and searching data, improved cluster resiliency and search performance, lowered memory heap usage, improved storage efficiency, and introduced faster aggregations in multiple Elasticsearch releases. In this release, we not only improve data resiliency but also reduce data transfer traffic — a change designed specifically to lower our customers’ Elastic Cloud bills.
By compressing specific inter-node traffic and using snapshot storage to shortcut relocating shards between nodes, we have reduced the amount of network traffic that traverses across the cluster, resulting in a reduction in Data Transfer and Storage (DTS) cost. This change will be most prominent for Elastic Cloud customers with heavy indexing or data migration between tiers.
New APIs to help optimize and improve Elasticsearch performance
The best decisions are always data driven. Three new experimental APIs in 7.15 give you the tools to help analyze how you are using Elasticsearch usage and ultimately drive improved performance.
The field usage API helps you decide how to index a field based on usage statistics. For example, if a field is used frequently, it should be created with schema on write or at ingest time by using a mapping. If the field is used infrequently, consider defining it at query time with runtime fields. Changing a text field with an inverted_index.term_frequencies of zero and low inverted_index.positions to match_only_text (added in 7.14) can save around 10% of disk.
With the index disk usage API you can see how much disk space is consumed by every field in your index. Knowing what fields take up disk, you can decide which indexing option or field type is best. For example, keyword or match_only_text may be better than text for certain fields where scoring and positional information is not important. Or, use runtime fields to create a keyword at query time for flexibility and saving space.
Finally, the vector tiles API provides a huge performance and scalability improvement when searching geo_points and geo_shapes drawn to a map (through use of vector tiles). Offloading these calculations to the local GPU significantly improves performance while also lowering costs by reducing network traffic both within the cluster and to the client.
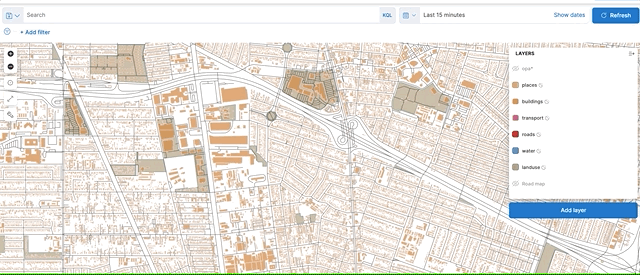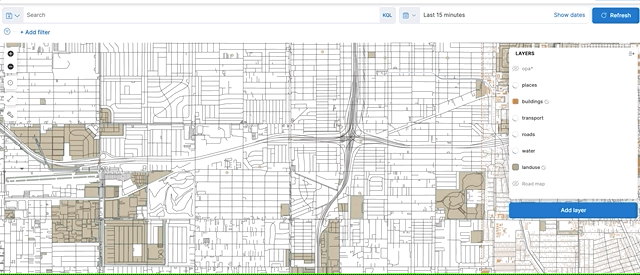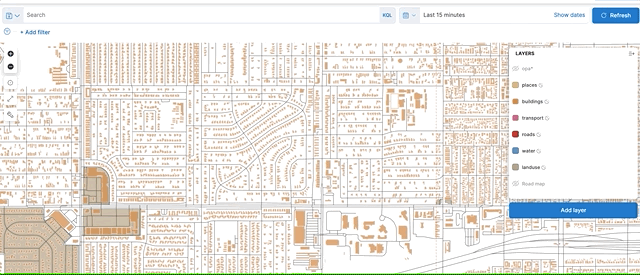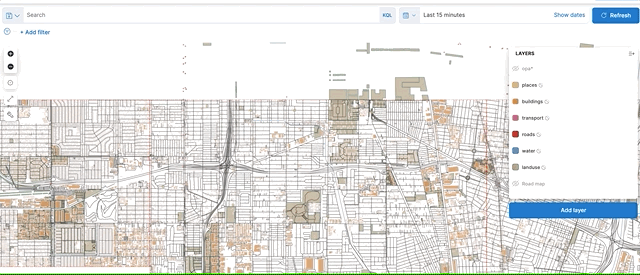
Composite runtime fields
Elastic 7.15 continues to evolve the implementation of runtime fields in Elasticsearch and Kibana.
In Elasticsearch, composite runtime fields enable users to streamline field creation using one Painless script to emit multiple fields, with added efficiencies for field management. Use patterns like grok or dissect to emit multiple fields using one script instead of creating and maintaining multiple scripts. Using existing grok patterns also makes it faster to create new runtime fields and reduces the time and complexity of creating and maintaining regex expressions. This development makes it easier and more intuitive for users to ingest new data like custom logs. See more on runtime fields in Kibana 7.15 below.
What’s new in Kibana 7.15
Runtime fields editor preview pane
Combined with the introduction of composite fields for Elasticsearch (above), a new preview pane in the runtime fields editor in Kibana 7.15 makes it even easier to create fields on the fly. The preview pane empowers users to test and preview new fields before creating them — for example, by evaluating a new script against documents to check accuracy in Index Patterns, Discover, or Lens. In addition, pinning specific fields in the preview pane simplifies script creation. This enhancement also includes better error handling for the editor, all to help streamline the field creation process and allow users to create runtime fields more quickly. More developments for runtime fields are on the horizon as we continue to make previously ingested data easier to parse from Kibana.
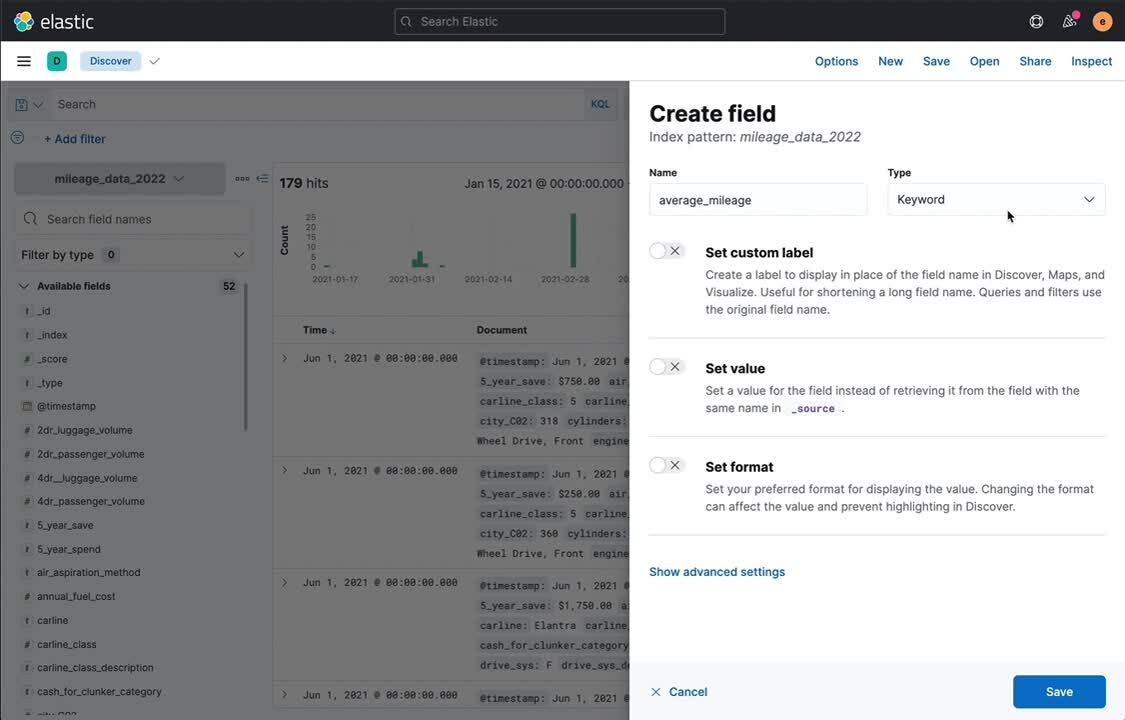
Other updates across the Elastic Stack and Elastic Cloud
Elastic Cloud
- Leverage more cost-effective hardware options on GCP: Google Compute Engine’s (GCE) N2 VMs for Elastic Cloud deployments running on Google Cloud offer up to 20% better CPU performance compared to the previous generation N1 machine types. Learn more in the blog post.
Elasticsearch
- Build complex flows with API keys: Search and pagination for API keys allow you to build complex management flows for keys, based on your own metadata.
Kibana
- Sync across time and (dashboard) space with your cursor: A new hover feature in Kibana charts that highlights corresponding data across multiple charts makes it easier for users to home in on specific time periods to observe and explore trends. In addition to time series, this will also highlight the same non-time data on multiple dashboard panels.
- Customize charts with legend-ary updates: Legends inside charts (great for busy dashboards) and multi-line series names in legends make it easier for teams to follow the data story on a dashboard.
- Get a head start on Maps exploration: Metadata for points and shapes is now auto-generated in Elastic Maps when a user creates an index and explores with edit tools. The user and timestamp data is saved for further exploration and management. Also, a new layer action allows users to view only the specific layer they are interested in.
- Learn more in the Kibana docs.
Machine learning
- Monitor machine learning jobs easily: Operational alerts for machine learning jobs simplify the process of managing machine learning jobs and models, and alerts in Kibana make it easier to track and follow up on errors.
- Adjust and reset models without the fuss: The reset jobs API makes working with models much easier across Kibana, from the Logs app to Elastic Security.
- Reuse and scale machine learning jobs: Jobs can now be imported and exported, allowing users to reuse jobs created in lab environments or in multiple-cluster environments. Sharing jobs across deployments makes jobs more consistent and easier to scale.
- Investigate transaction latency: Elastic APM correlations, powered by machine learning, streamline root cause analysis. The Elasticsearch significant terms aggregation was enhanced with a p_value scoring heuristic, and Kibana’s new transaction investigation page for APM aids analysts in a holistic exploration of transaction data. To learn more, read the Observability 7.15 blog.
- Learn more in the Kibana and Elasticsearch docs.
Integrations
- Run Elastic Package Registry (EPR) as a Docker image: now you can run your own EPR to provide information on external data sources to air-gapped environments. By using the EPR Docker image, you can integrate, collect and visualize data using Elastic Agents. For more information, please refer to this Elastic guide.
Try it out
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. If you’re new to Elastic Cloud, take a look at our Quick Start guides (bite-sized training videos to get you started quickly) or our free fundamentals training courses. You can always get started for free with a free 14-day trial of Elastic Cloud. Or download the self-managed version of the Elastic Stack for free.
Read about these capabilities and more in the 7.15 release notes (Elasticsearch, Kibana, Elastic Cloud, Elastic Cloud Enterprise, Elastic Cloud on Kubernetes), and other Elastic 7.15 highlights in the Elastic 7.15 announcement post.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.