Machine Learning in der Cybersicherheit: Trainieren überwachter Modelle zur Erkennung von DGA-Aktivität
Werbeanrufe von irgendwelchen Telefonnummern können nerven. Und da hilft es auch nichts, die Nummer zu sperren, denn der nächste Anruf kommt von einer neuen Nummer. Dieselben schmutzigen Tricks werden von Cyberkriminellen verwendet: Malware-Entwickler setzen Domain-Generation-Algorithmen (DGAs) ein, die die Quelle ihrer Command‑&-Control-Infrastruktur verschleiern, um nicht aufgespürt zu werden und Security-Analysten das Leben schwerzumachen, die dieses Treiben unterbinden möchten.
In dieser zweiteiligen Serie werden wir mithilfe von Elastic-Machine-Learning ein Modell zur Erkennung solcher Domain-Generation-Algorithmen erstellen und evaluieren. In diesem Teil 1 behandeln wir die folgenden Themen:
- Schritte zum Extrahieren unabhängiger Variablen (Features) aus den Domain-Rohinformationen
- Schritte zum Finden geeigneter Variablen
- Trainieren und Evaluieren eines Machine-Learning-Modells mit dem Elastic Stack
In Teil 2 wird es dann darum gehen, wie sich das trainierte Modell in einer Ingestions-Pipeline bereitstellen lässt, damit es Packetbeat-Daten beim Ingestieren mit Informationen anreichern kann. Die entsprechenden Konfigurationsdateien und unterstützendes Material sind im Beispiele-Repository zu finden.
Wenn Sie das Ganze mit Ihren eigenen Daten durchexerzieren möchten, empfehle ich Ihnen, das Angebot zu nutzen, unseren Elasticsearch Service kostenlos auszuprobieren. Sie erhalten für den Probezeitraum vollen Zugriff auf alle unsere Machine-Learning-Funktionen. Okay, legen wir los.
DGA: Hintergrundinformationen
Viele Schadprogramme versuchen nach erfolgreichem Eindringen in das Zielsystem, einen Remote-Server – „Command-&-Control-Server“, „C&C-Server“ oder „C2-Server“ genannt – zu kontaktieren, um Daten zu übertragen und Anweisungen oder Aktualisierungen zu erhalten. Das bedeutet, dass das Schadprogramm entweder die IP-Adresse des C&C-Servers oder die Domain kennen muss. Wenn diese IP-Adresse oder Domain im Schadprogramm hartcodiert ist, ist es für Verteidigungsmaßnahmen relativ leicht, diese Kommunikation zu unterbinden: Die Domain muss lediglich einer Sperrliste hinzugefügt werden.
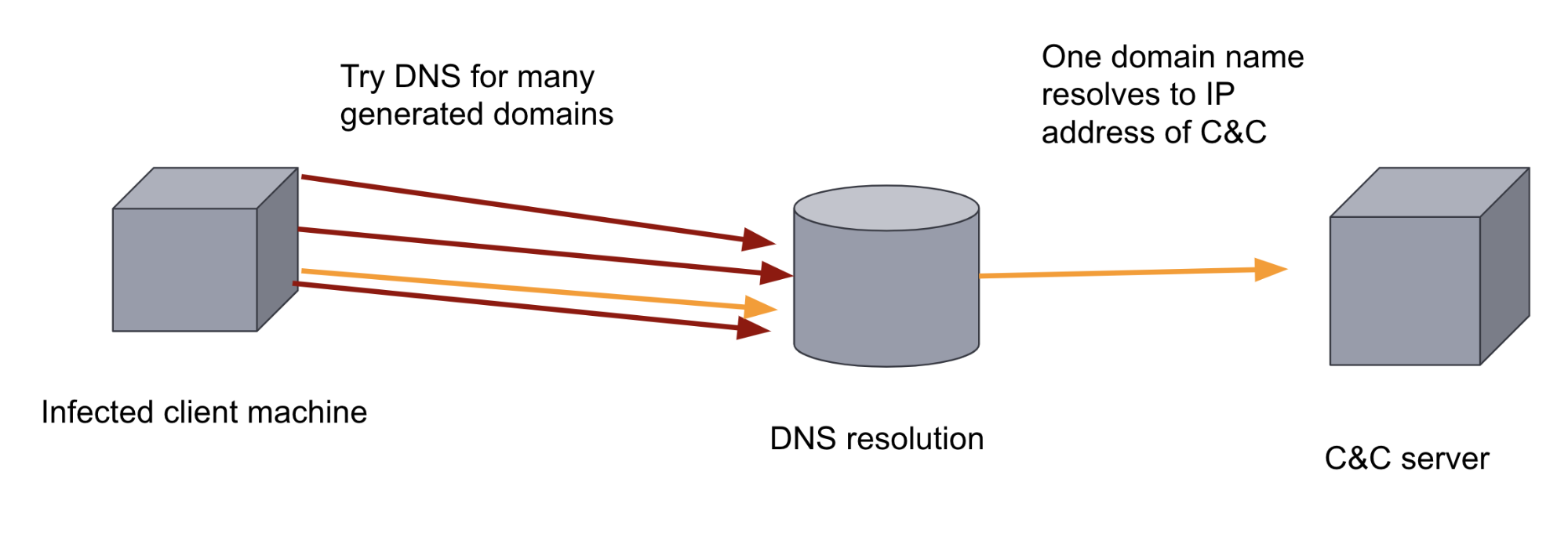
Um diese Verteidigungsmaßnahmen zu umgehen, können die Entwickler der Malware einen DGA hinzufügen. DGAs generieren Hunderte oder Tausende von zufällig aussehenden Domains. Die Malware auf der infizierten Maschine geht dann jede einzelne dieser generierten Domains durch und versucht, die Domain-Namen aufzulösen, um zu sehen, welche der Domains als C&C-Server registriert worden ist. Aufgrund der schieren Menge und Zufälligkeit der Domains ist es für einen regelbasierten Verteidigungsansatz schwierig, diesen Kommunikationskanal auszuschalten. Auch Analysten haben daran zu knabbern, denn DNS-Traffic ist in der Regel mit einem sehr hohen Datenaufkommen verbunden. Beide dieser Faktoren machen dies zu einem idealen Anwendungsfall für das Machine Learning.
Trainieren eines Machine-Learning-Modells zur Klassifizierung von Domains
Beim überwachten Machine Learning setzen wir dem Machine-Learning-Modell einen „gelabelten“ Trainingsdatensatz mit gutartigen und Schad-Domains vor, damit es lernen kann, gutartige von Schad-Domains zu unterscheiden. Anschließend wird dieses Modell dazu eingesetzt, bisher noch nicht bekannte Domains als gutartig oder schädlich einzustufen.
Es gibt verschiedene Arten von DGAs – nicht alle sehen gleich aus. Einige DGAs generieren zufällig aussehende Domains, während andere Wortlisten nutzen. In Produktionsumgebungen können andere Variablen und Modelle genutzt werden, um die Merkmale der verschiedenen Algorithmen zu erfassen. In diesem Beispiel trainieren wir ein einzelnes Modell auf der Grundlage der Merkmale der gängigsten Algorithmen.
Zum Trainieren unseres Modells nutzen wir einen Datensatz, der aus gutartigen Domains sowie Schad-Domains aus verschiedenen Malware-Familien besteht.

cryptolocker, banjori und suppobox
Feature-Engineering
Zum Erstellen eines effektiven Machine-Learning-Modells werden unabhängige Variablen („Features“) benötigt, die die charakteristischen Merkmale der von den DGAs generierten Domains erfassen können. Daher müssen wir dem Modell mitteilen, welche Aspekte der Zeichenfolge für die Unterscheidung zwischen gutartigen und Schad-Domains wichtig sind. Dieser Schritt wird im Machine-Learning-Universum „Feature-Engineering“ genannt.
Das Ermitteln der Variablen, die am besten geeignet sind, gutartige von Schad-Domains zu unterscheiden, ist ein iterativer Vorgang. Nehmen wir an, wir haben mit ein paar einfachen Variablen, wie Domain-Namen-Länge und Domain-Namen-Entropie, begonnen, aber die sich daraus ergebenden Modelle konnten hinsichtlich ihrer Zuverlässigkeit nicht mit anderen Methoden wie LSTM mithalten. Diese Modelle nutzen die sequenziellen Merkmale der Zeichenfolgen, weshalb wir uns andere Variablen angesehen haben, die Sequenzen effektiver encodieren.
Nachdem wir es mit den verschiedensten Feature-Engineering-Methoden versucht haben, sind wir zu dem Schluss gekommen, dass das beste Merkmal zur Unterscheidung zwischen gutartigen und Schad-Domains das Vorhandensein unterschiedlich langer Subzeichenfolgen ist.
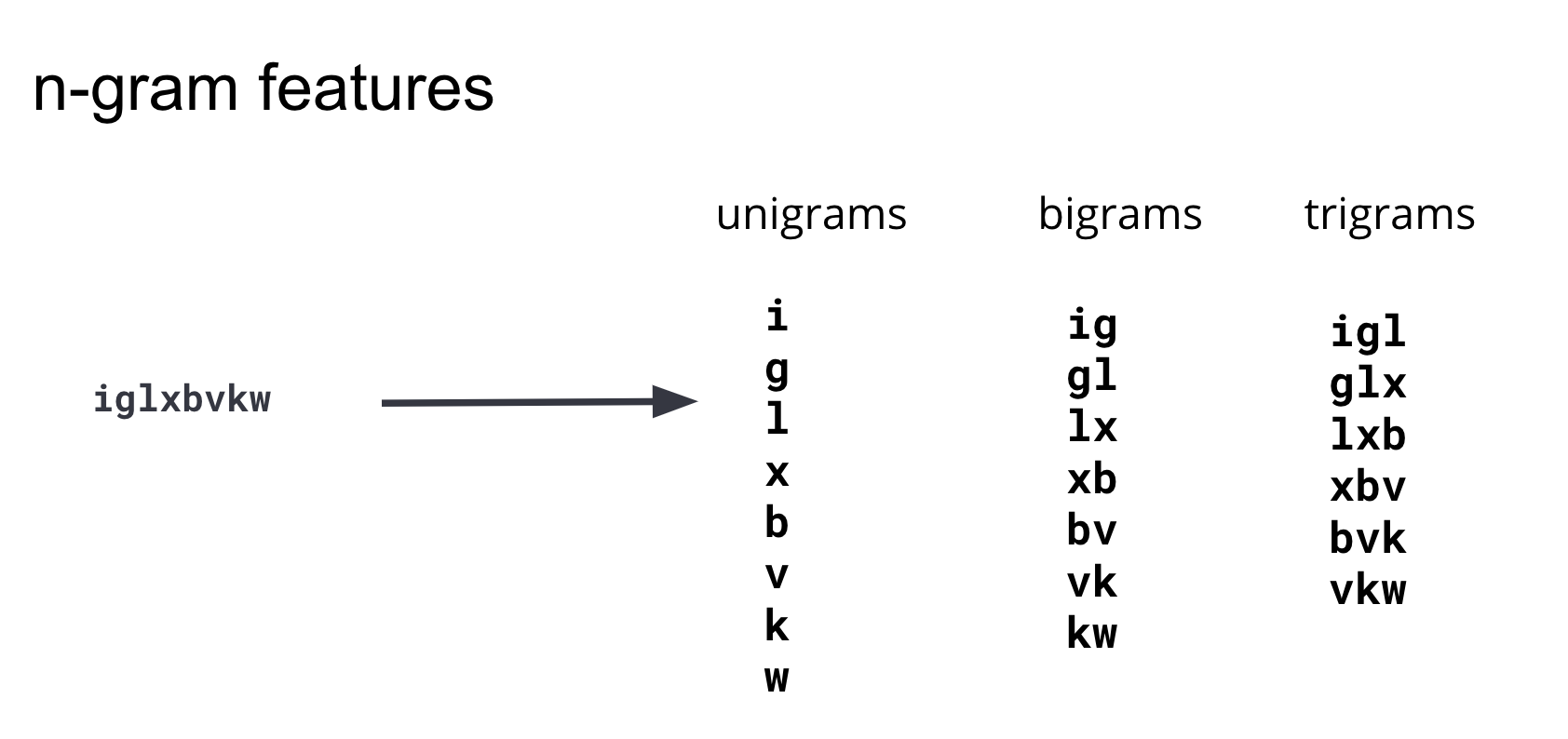
Diese Subzeichenfolgen werden üblicherweise als „N-Gramme“ bezeichnet. Bei der Ermittlung geeigneter Variablen ist es wichtig, die Zahl der Variablen (Dimensionalität des Training-Datensatzes) und die Komplexität ihrer Berechnung gegen den Nutzen für das Modell aufzuwiegen. Nach mehreren Iterationen und Tests von N-Grammen verschiedener Längen haben wir festgestellt, dass N-Gramme ab einer Länge von 4 dem Modell keine signifikanten prädiktiven Informationen hinzufügen, sodass wir uns bei unserem Variablensatz auf Unigramme, Bigramme und Trigramme beschränken können. Abbildung 3 zeigt, wie diese Variablen aus einer Beispiel-Domain generiert werden.
Zum Generieren eines Elasticsearch-Index, bei dem jede DGA-Domain in Unigramme, Bigramme und Trigramme aufgeteilt wird, können Sie den originalen Ausgangsindex mit einem Painless-Skript-Prozessor zum Reindexieren durch eine Ingestions-Pipeline schicken. Ein Beispiel dafür sehen Sie in Abbildung 4 unten. Ausführliche Konfigurationen, Anleitungen und verschiedene Anpassungsoptionen finden Sie im Beispiele-Repository.
POST _scripts/ngram-extractor-reindex
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount , int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['domain'].length();i++){
ctx[Integer.toString(params.ngram_count)+'-gram_field'+Integer.toString(i)] = nGramAtPosition(ctx['domain'], i, params.ngram_count)
}
"""
}
}
Im Normalfall sind zusätzliche Vorverarbeitungsschritte nötig, um die Subzeichenfolgen der Längen 1, 2 und 3 für den Machine-Learning-Algorithmus in numerische Vektoren umzuwandeln. In unserem Fall kümmert sich aber Elastic Machine Learning um diese „Encodieren“ genannte Umwandlung in numerische Werte. Elastic Machine Learning sieht sich auch die Variablen an und wählt automatisch diejenigen aus, die die meisten Informationen enthalten.
Erstellen eines Klassifizierungsjobs mit Data Frame Analytics
Der nächste Schritt besteht darin, mithilfe der „Data Frame Analytics“-Benutzeroberfläche einen Klassifizierungsjob zu erstellen. Ich habe in den folgenden Screenshots einige der wichtigsten Aspekte hervorgehoben.
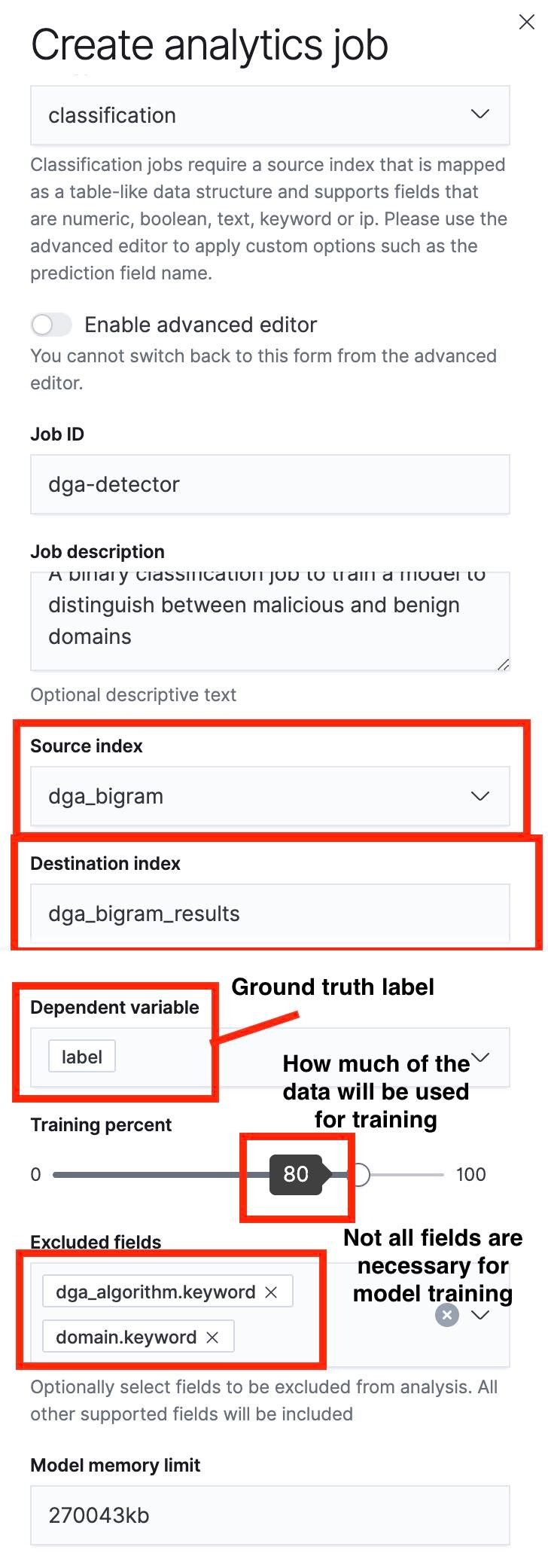
Es sei darauf hingewiesen, dass wir mithilfe des Schiebereglers den Anteil der für das Training verwendeten Daten und damit ein Training-Test-Verhältnis festlegen können. Im Screenshot in Abbildung 5 liegt der Anteil der für das Training verwendeten Daten bei 80 %, das heißt, dass 80 % der Dokumente im Ausgangsindex zum Trainieren des Modells verwendet werden, während 20 % für das Testen verbleiben.
Nach Abschluss des Trainingsprozesses können wir zur Ergebnisansicht in der „Data Frame Analytics“-Benutzeroberfläche gehen und uns dort die Performance des Modells ansehen. Da wir unseren Ausgangsindex in einen Trainingssatz und einen Testsatz aufgeteilt haben, können wir für beide Anwendungsfälle Aussagen zur Performance des Modells treffen. Nun geben zwar sowohl die Informationen zur Performance des Trainingssatzes als auch die Angaben zur Performance des Testsatzes wertvolle Anhaltspunkte, uns interessiert aber hier vor allem die Performance des Modells beim Test-Datensatz, denn daraus lassen sich Rückschlüsse auf den Generalisierungsfehler des Modells ziehen. Dieser Fehler gibt an, wie gut das Modell in der Lage sein wird, Prognosen für Datenpunkte abzugeben, die es bisher noch nicht gesehen hat.
Evaluieren eines Machine-Learning-Modells
Nachdem wir das Training abgeschlossen haben, können wir uns zur Job-Management-Seite der Elastic-Machine-Learning-Benutzeroberfläche durchklicken und uns dort die Ergebnisse ansehen.
Auf der Ergebnisseite (siehe Abbildung 6) finden wir zwei wichtige Informationen: eine Wahrheitsmatrix, die zusammenfasst, wie sich unser Modell geschlagen hat, und eine Ergebnistabelle, über die wir per Drilldown für einzelne Datenpunkte feststellen können, wie sie vom Modell eingestuft wurden. Zum Wechseln zwischen der Anzeige von Wahrheitsmatrix und Zusammenfassungstabelle des Testdatensatzes und des Trainingsdatensatzes stehen die Filterschaltflächen „Testing“ und „Training“ rechts oben über der Tabelle zur Verfügung.
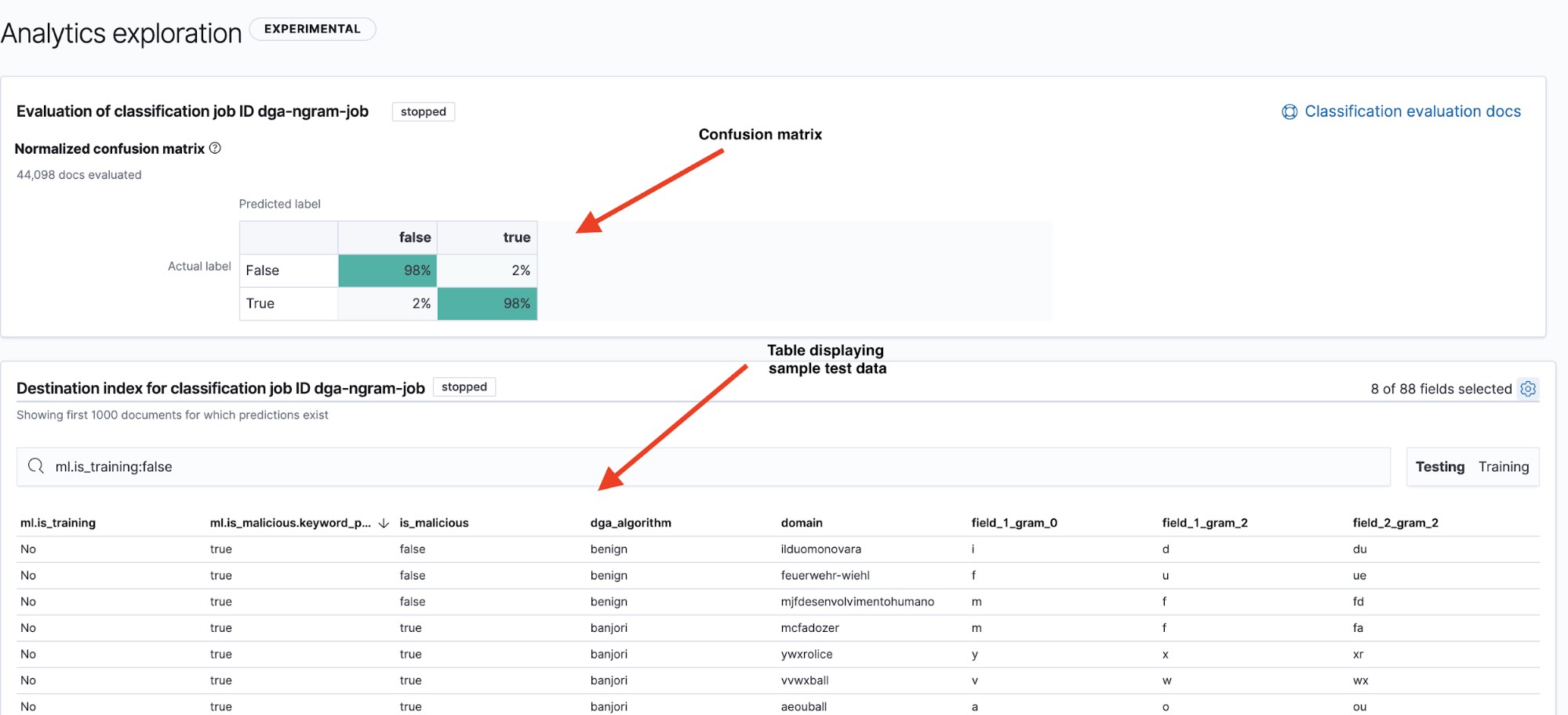
Ein häufig genutztes Mittel zur Anzeige der Performance eines Modells ist die Wahrheitsmatrix genannte Visualisierung. Sie gibt Auskunft über den Anteil der richtig positiv eingestuften Datenpunkte (Schad-Domains, die das Modell als Schad-Domains klassifiziert hat und die tatsächlich Schad-Domains waren), den Anteil der richtig negativ eingestuften Datenpunkte (gutartige Domains, die das Modell als gutartig eingestuft hat), den Anteil der falsch positiven Datenpunkte (fälschlich als Schad-Domains eingestufte gutartige Domains) und den Anteil der falsch negativen Datenpunkte (fälschlich als gutartig eingestufte Schad-Domains).
Wie ihr Name bereits sagt, lässt sich der Wahrheitsmatrix schnell entnehmen, ob ein Modell bei seinen Einstufungen im Wesentlichen die Wahrheit sagt oder beides oft durcheinanderbringt.
In Abbildung 6 sehen wir für unser Modell im Hinblick auf den Testdatensatz eine Richtig-positiv-Quote von 98 %. Das bedeutet, dass wir bei einer Implementierung dieses Modells in eine Produktionsumgebung hinsichtlich der Einstufung ankommender DNS-Daten mit einer Falsch-positiv-Quote von ca. 2 % rechnen müssen. Dies mag zwar nach einer recht geringen Zahl aussehen, aber angesichts der großen Datenmengen beim DNS-Traffic käme dabei trotzdem eine ziemlich hohe Zahl von Alerts zustande. Daher werden wir uns in Teil 2 ansehen, wie sich die Zahl der falsch positiven Alerts durch Anomalieerkennung reduzieren lässt.
Fazit
In diesem Blogpost haben wir uns einen Überblick darüber verschafft, wie sich mit Elastic Machine Learning ein Machine-Learning-Modell für die DGA-Erkennung entwickeln und evaluieren lässt. Wir haben uns die Schritte zum Extrahieren unabhängiger Variablen („Features“) aus den rohen gutartigen und Schad-Domains angesehen und den Prozess zur Ermittlung geeigneter Variablen betrachtet. Schließlich haben wir einen Blick auf das Trainieren und Evaluieren eines Machine-Learning-Modells mit dem Elastic Stack geworfen.
Im zweiten Teil der Serie wird es darum gehen, wie man mithilfe von Inferenzprozessoren in Ingestions-Pipelines dieses Modell so einsetzen kann, dass es ankommende Packetbeat-Daten mit prädiktiven Informationen zur Schädlichkeit der Domain anreichern kann. Außerdem sehen wir uns an, wie Anomalieerkennungsjobs die Zahl falsch positiver Alerts reduzieren können. Bis dahin empfehle ich Ihnen, unsere Machine-Learning-Funktionen kostenlos auszuprobieren und sich so ein Bild davon zu machen, was für Einblicke und Erkenntnisse Sie gewinnen können, wenn Sie das Rauschen in Ihren Daten hinter sich gelassen haben.