Infrastructure- und Logs-Benutzeroberfläche: Neue Möglichkeiten für die Interaktion zwischen Ops und Elasticsearch
Seit Version 6.5 des Elastic Stack können Sie auf zwei neue Arten mit Ihren Daten interagieren: die Benutzeroberflächen für Infrastructure und Logs. Beide Komponenten sind in 6.5 noch im Betastatus, aber mehr dazu später, wenn ich Sie nach Ihrem Feedback frage. Ich möchte für beide Benutzeroberflächen jeweils die Themen Motivation, Benutzererlebnis und Konfiguration ansprechen. Lassen Sie uns mit der Logs-Benutzeroberfläche beginnen.
Logs-Benutzeroberfläche
Motivation
Den folgenden Satz habe ich zu oft gehört: „Gebt mir einfach die Logs, ich brauche nichts Ausgefallenes, alles was ich brauche steht in den Logs, ich möchte sie einfach nur lesen.“ Wir haben verstanden. Sie haben die Wahl
Ein aufgemotztes tail -f mit den neuesten Einträgen am Ende, ein grafisches Erlebnis mit Tabellen, Diagrammen, Tag Clouds usw. oder eine Tabellenansicht. Wir möchten, dass Sie so arbeiten können, wie es Ihnen am liebsten ist, und die Offenheit des Elastic Stack unterstützt Sie dabei.
 |  |  |
Benutzererlebnis
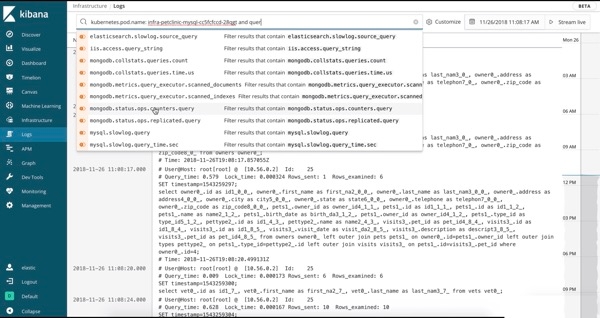
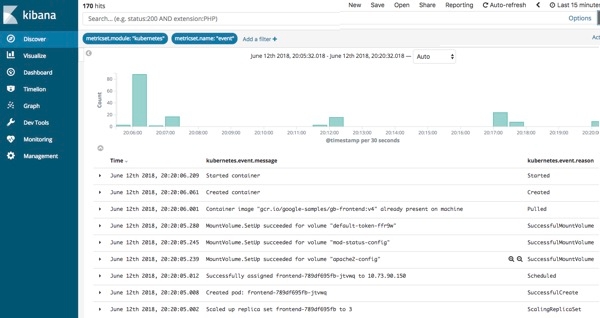
Die Logs-Benutzeroberfläche entspricht in etwa einem tail über eine Log-Datei, nur dass sämtliche Logs aus allen Systemen in einer einzigen Konsole verfügbar sind. Die Logs werden gestreamt, und am Ende der Ansicht steht der neueste Eintrag, genau wie mit tail -f. In der Logs-Benutzeroberfläche sehen Sie standardmäßig alle Einträge aus allen Logs, die Ihre Konfigurationskriterien erfüllen (mehr dazu im nächsten Abschnitt). Wenn Sie an einem speziellen Problem arbeiten und nicht alle Logs von allen Geräten durcheinander brauchen (die vermutlich schneller vorbeistreamen, als irgendjemand sie lesen kann), dann ändern Sie einfach die Interaktion, indem Sie Text in die Suchleiste am oberen Rand eingeben. Wenn ich beispielsweise nur 404-Fehler von den Apache httpd-Pods mit der Kubernetes-Ebenenbeschriftung = „frontend“ sehen möchte, dann gebe ich die ersten Buchstaben in die Suchleiste ein, und die Auto-Vervollständigung hilft mir, die richtigen Logs zu finden:
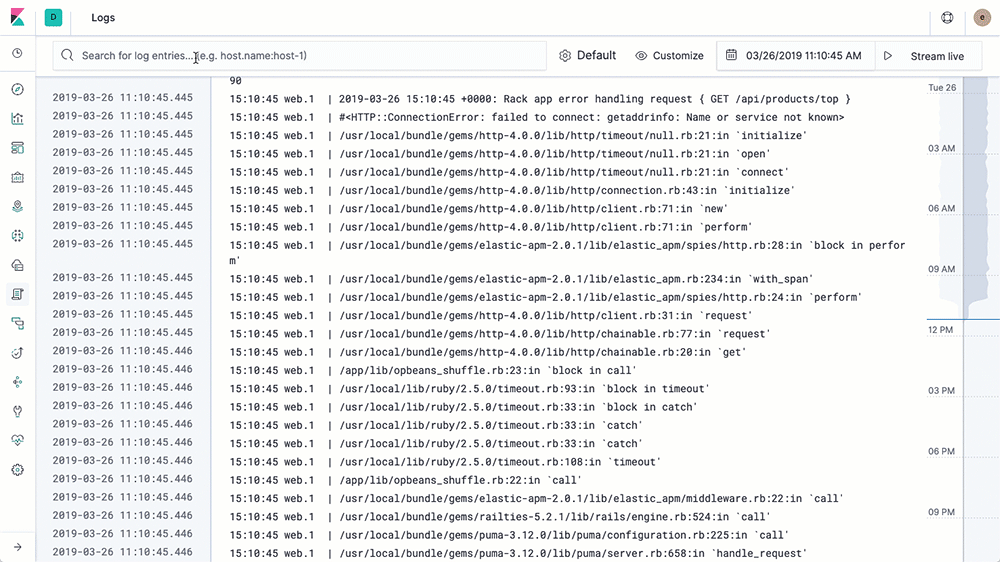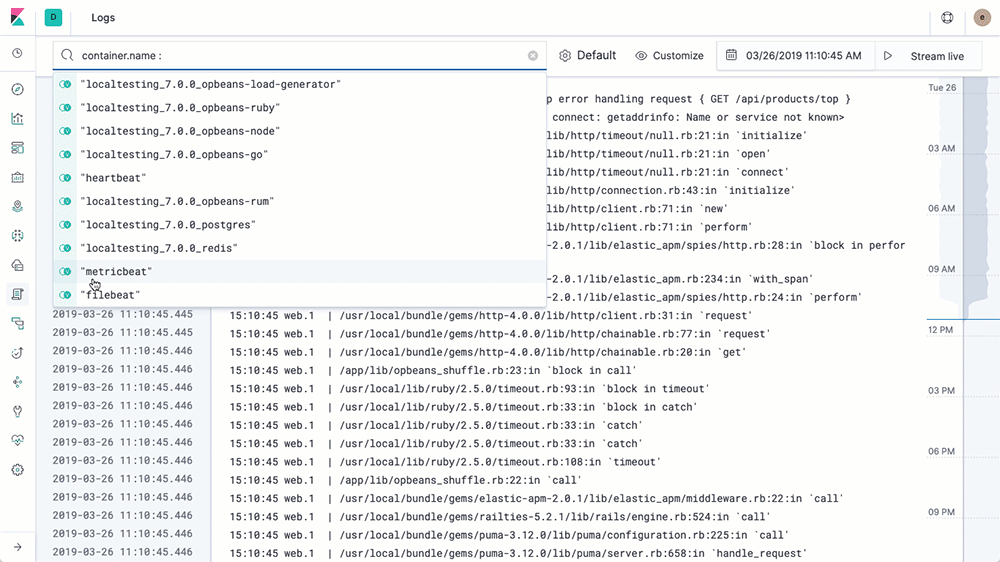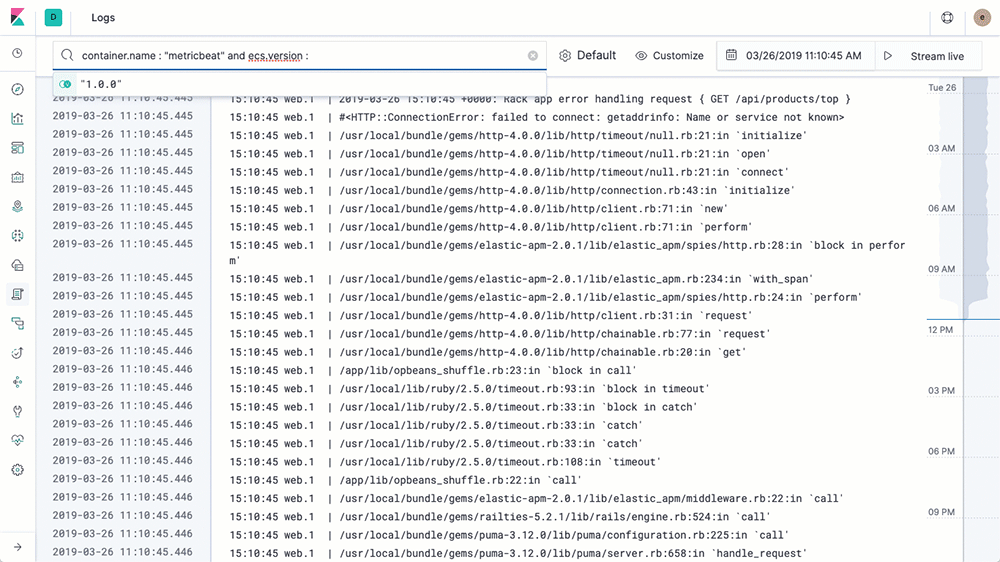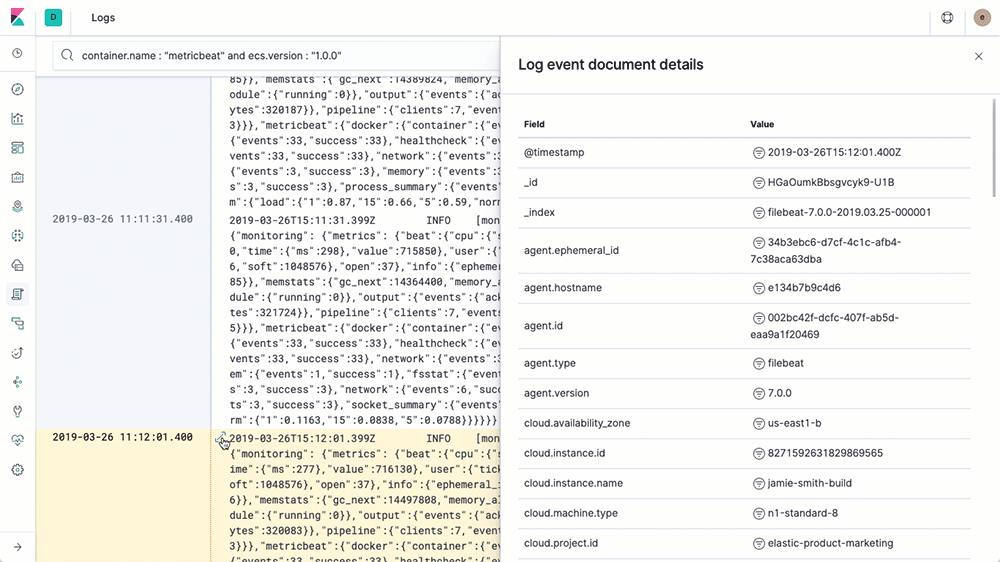
Vergleichen Sie dies mit dem bisherigen Verfahren: Terminal öffnen, beim k8s-Anbieter authentifizieren, herausfinden, welche Pods Sie brauchen, kubectl logs -f … | grep 404 ausführen (bzw. in einer Welt ohne Container die Hostnamen suchen, per SSH verbinden, tail über die Logs ausführen usw.). Wir möchten Ihr Leben erleichtern und Ihnen Ihre Daten auf möglichst hilfreiche Art präsentieren.
Konfiguration
Sie finden die Dokumentation der Logs-Benutzeroberfläche am üblichen Ort, aber ich möchte hier einige der Konfigurationsoptionen hervorheben. Hier ist die Standardkonfiguration, die Sie in config/kibana.yml einfügen und anschließen an Ihre Anforderungen anpassen können:
xpack.infra.sources.default.logAlias: "filebeat-*"
xpack.infra.sources.default.fields.timestamp: "@timestamp"
xpack.infra.sources.default.fields.message: ['message', '@message']
Die Konfiguration besteht aus einigen vordefinierten Zeilen, die in der Logs-Benutzeroberfläche im message-Feld aller Indizes auftauchen, die mit dem Alias filebeat-* übereinstimmen. Wie können Sie also all Ihre Logstash-Indizes hinzufügen? Bearbeiten Sie einfach den xpack.infra.sources.default.logAlias im Eintrag config/kibana.yml wie folgt und starten Sie Kibana neu:
#xpack.infra.sources.default.logAlias: "filebeat-*"
xpack.infra.sources.default.logAlias: "filebeat-*,logstash-*"
Vergessen Sie nicht, Kibana neu zu starten. Wenn Sie die Logs-Benutzeroberfläche erneut öffnen und auf „Live streamen“ klicken, sollten sämtliche Logstash- und Filebeat-Logs in die Logs-Benutzeroberfläche gestreamt werden.
Hinweis: Wenn sie die Elasticsearch-Aliase bevorzugen, können Sie xpack.infra.sources.default.logAlias auch auf den Namen des Alias festlegen und den Alias anschließend nach Bedarf aktualisieren. Das folgende Beispiel verwendet einen Alias von logs.
Alias erstellen:
curl -X POST "localhost:9200/_aliases" -H 'Content-Type: application/json' -d'
{
"actions" : [
{ "add" : { "indices" : ["logstash-*", "filebeat-*"], "alias" : "logs" } }
]
}
'
Konfiguration/kibana.yml aktualisieren:
#xpack.infra.sources.default.logAlias: "filebeat-*"
xpack.infra.sources.default.logAlias: "logs"
Infrastructure-Benutzeroberfläche
Motivation
Die Infrastrukturverwaltung kann in drei verschiedene Reifegrade unterteilt werden:
- Ich finde heraus, dass etwas kaputt ist, und öffne ein Überwachungssystem, um dem Problem auf den Grund zu gehen.
- Ich bilde wichtige Indikatoren für alle Systeme auf einem großen Dashboard ab und beobachte das Dashboard, bevor ich Problemen auf den Grund gehe.
- Ich automatisiere Ops: Machine-Learning-Algorithmen lernen das normale Verhalten kennen, erkennen aufkommende Probleme und warnen mich.
Mit der Infrastructure-Benutzeroberfläche kann Ihre Ops die Phase „wichtige Indikatoren auf einem Dashboard abbilden“ erreichen. Wir sind uns wohl einig darüber, dass wir mehr von der Phase „automatisiertes Machine Learning“ brauchen. Lesen Sie mehr über Elastic Machine Learning, und im Video am Ende dieses Beitrags finden Sie einen Workflow, der mit einer Warnung von einem Machine-Learning-Auftrag beginnt und anschließend die Phasen APM, verteiltes Tracing, Infrastruktur und Logs-Benutzeroberfläche durchläuft. Mit der Zusammenführung von Logs, Metriken, APM und verteiltem Tracing in Elasticsearch können Sie sämtliche Analyse- und Visualisierungstools über all Ihre Daten einsetzen.
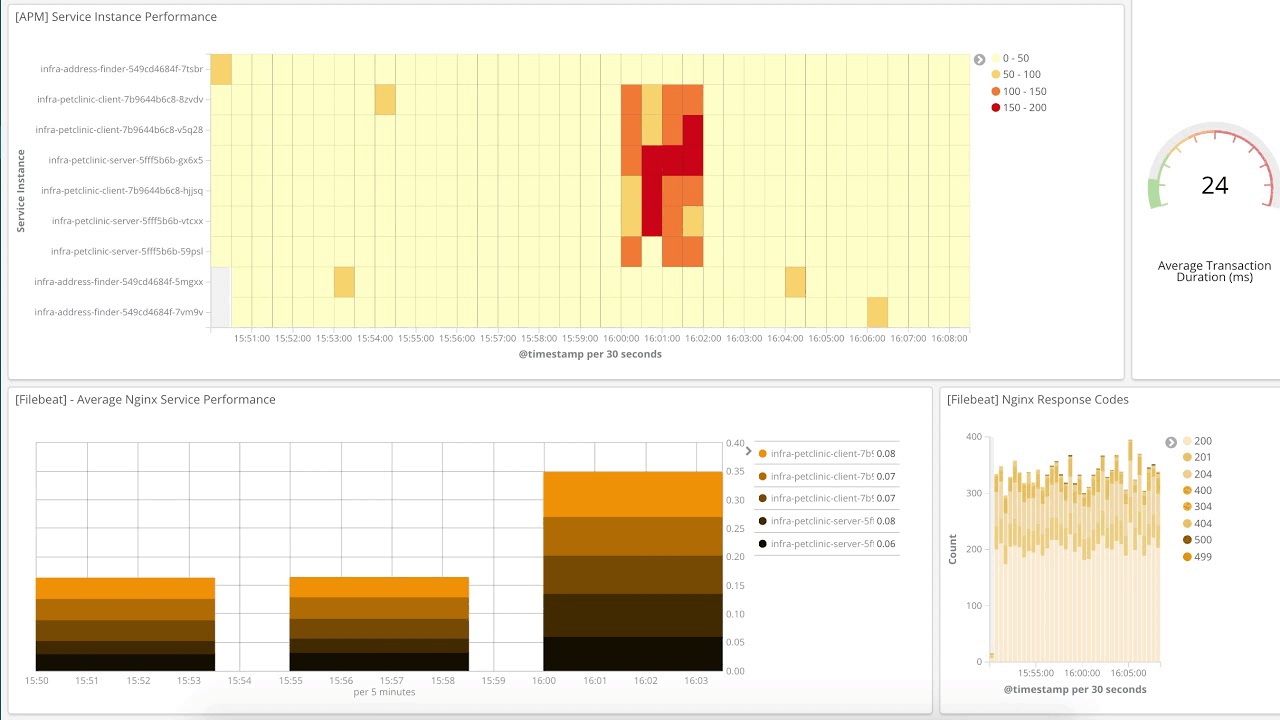
Ich werde Ihnen jetzt die Infrastructure-Benutzeroberfläche genauer vorstellen. In dieser Ansicht sehen wir verschiedene Kubernetes-Pods, die ich nach ihrem Namespace gruppiert habe. Ich sehe mir den eingehenden Netzwerkdatenverkehr an. Mit einem Rechtsklick auf einen der Pods kann ich zu den Logs oder zu einem kuratierten Metrik-Dashboard für den jeweiligen Pod springen.
Benutzererlebnis
Wir unterstützen momentan drei Arten von Geräten: Hosts, Kubernetes-Pods (k8s) und Docker-Container. Die Infrastructure-Benutzeroberfläche bietet den Vorteil, dass Sie den Status wichtiger Indikatoren für eine riesige Anzahl von Geräten sehen können. Für hohe Datenvolumen werden farbige Rechtecke ohne Text angezeigt, bis Sie einen Drilldown auf eine interessante Teilmenge ausführen, die Suchleiste verwenden oder auf eine Gruppe klicken. Außerdem können Sie die Logs für ein Gerät aufrufen oder ein Metrik-Dashboard öffnen.
Wenn ich von „wichtigen Indikatoren“ spreche, dann meine ich im Moment die folgende Liste. All diese Indikatoren stammen aus Metricbeat:
Hosts: CPU, Arbeitsspeicher, Last, eingehender Datenverkehr, ausgehender Datenverkehr und Lograte
Kubernetes: CPU, Arbeitsspeicher, eingehender Datenverkehr, ausgehender Datenverkehr
Docker: CPU, Arbeitsspeicher, eingehender Datenverkehr, ausgehender Datenverkehr
Mit der Gruppierung können Sie auf eine Liste von Geräten hereinzoomen. Wenn Sie eine bestimmte Anwendung unterstützen, die mit Kubernetes bereitgestellt wird, dann sollten Sie sich die Namespace-Gruppe ansehen. Wenn Sie den Verdacht haben, dass ein Problem durch einen überlasteten Knoten verursacht wird, dann können Sie nach Namespace und Knoten gruppieren, um die Aufteilung zu verfeinern. Momentan sind die folgenden Gruppierungen verfügbar (Sie können bis zu zwei Gruppierungen pro Gerätetyp verwenden):
Hosts: Verfügbarkeitszone, Maschinentyp, Projekt-ID, Cloudanbieter
Kubernetes: Namespace, Knoten
Docker: Host, Verfügbarkeitszone, Maschinentyp, Projekt-ID, Anbieter
Wenn sich keine dieser Gruppierungen für Ihre gewünschte Interaktion mit den Daten eignet, können Sie die Suchleiste verwenden. Geben Sie einige Buchstaben ein, und die Auto-Vervollständigungsfunktion der Kibana Query Language (KQL) unterstützt Sie. Im GIF der Logs-Benutzeroberfläche weiter oben habe ich beispielsweise kubernetes eingegeben, und Kibana hat mir labels und dann tier zusammen mit Auswahlmöglichkeiten auf Basis der in Elasticsearch indexierten Daten angeboten.
Wenn Sie die Ressourcen gruppiert haben, können Sie per Klick auf eine Gruppe hineindrillen, um weitere Details für die Gruppe anzuzeigen. Wenn Sie sich für einen bestimmten Host, Pod oder Container interessieren, können Sie so die entsprechenden Logs oder Metriken abrufen. Hier ist ein Teil der Metrikansicht für einen Host:
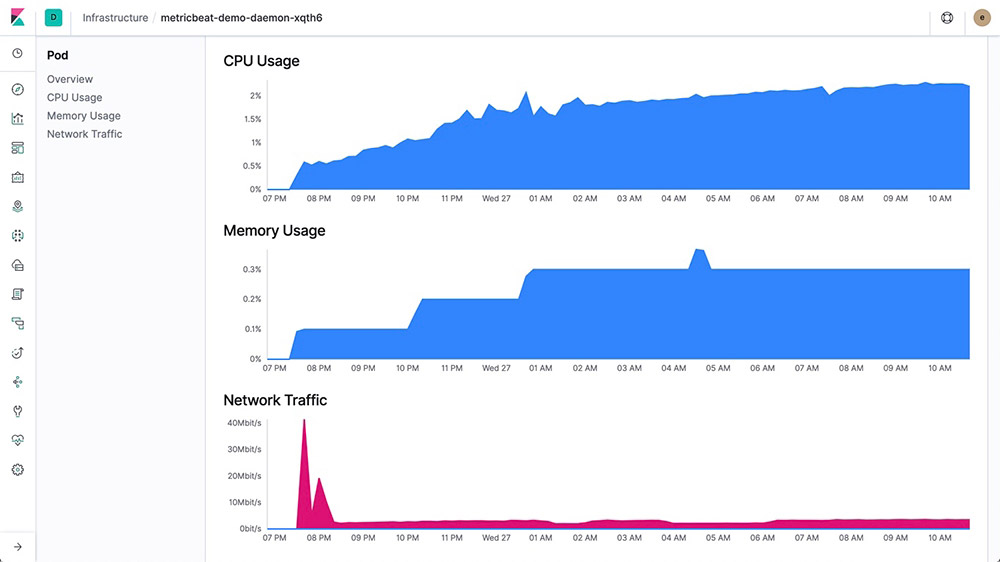
Konfiguration
Die Infrastructure-Benutzeroberfläche ist sehr einfach zu konfigurieren. Stellen Sie einfach Metricbeat bereit und aktivieren Sie das System-Modul. Wenn Sie Container verwenden, sollten Sie außerdem die Kubernetes- und Docker-Module aktivieren.
Das wars auch schon, es sei denn, Sie haben das Standard-Indexmuster (metricbeat-*) geändert. Weitere Details zu möglichen Anpassungen finden Sie in der Dokumentation zur Infrastructure-Benutzeroberfläche, und ich zeige Ihnen die wichtigsten Optionen hier:
xpack.infra.sources.default.metricAlias: "metricbeat-*"
xpack.infra.sources.default.fields.host: "beat.hostname"
xpack.infra.sources.default.fields.container: "docker.container.name"
xpack.infra.sources.default.fields.pod: "kubernetes.pod.name"
Sagen Sie uns Ihre Meinung
Diese beiden Benutzeroberflächen sind noch in der Betaphase, und wir freuen uns über Ihr Feedback (natürlich gerne auch nach der allgemeinen Veröffentlichung). Teilen Sie uns mit, wie Sie mit Ihren Daten interagieren möchten. Reichen die Gruppierungen in dieser Betaversion der Infrastructure-Benutzeroberfläche aus, um Ihre Teamorganisation abzubilden? Was können wir besser machen? Verwenden wir die richtigen Metriken für die Farbauswahl? Möchten Sie die Logs in der Logs-Benutzeroberfläche anders filtern? Wenn Sie die Metrikansicht aus der Infrastructure-Benutzeroberfläche starten, sehen Sie sofort die für Sie wichtigsten Metriken?
Besuchen Sie das Kibana-Diskussionsforum und schreiben Sie uns, was Ihnen gut oder weniger gut gefällt, was Ihrer Meinung nach fehlt usw. Die Entwickler lesen und beantworten diese Diskussionen und freuen sich über Ihr Feedback. Außerdem können Sie jederzeit ein Ticket eröffnen, einen PR übermitteln oder beides auf GitHub im Auge behalten.
Probieren Sie es aus
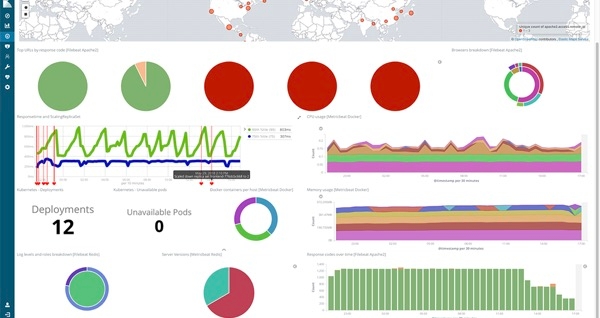
Unser Live-Demosystem enthält Logs und Metriken, die Sie durchsuchen, visualisieren und ausprobieren können. Klicken Sie auf die Infrastructure-Kachel, um die Infrastructure-Benutzeroberfläche zu öffnen:

Sie können zu den Kubernetes- oder Docker-Ansichten wechseln, die Objekte mit der Benutzeroberfläche gruppieren oder die Ansicht mit der Suchleiste eingrenzen. Klicken Sie auf einen Host, Pod oder Container, um die Logs-Benutzeroberfläche für das jeweilige Objekt zu öffnen. Wenn Sie demo.elastic.co besuchen, werfen Sie auch einen Blick auf die Dashboards und Visualisierungen. Sie können direkt von der Startseite zu verschiedenen Bereichen navigieren.
Demo ansehen
Dieses Video demonstriert den Workflow dieser Benutzeroberflächen (inklusive Machine Learning und APM mit verteiltem Tracing!). Vielen Dank für Ihr Interesse und Ihr Feedback!