Bereitstellen eines Heiß-Warm-Logging-Clusters auf dem Elasticsearch Service
Wenn Sie mehr über die Unterschiede zwischen dem Amazon Elasticsearch Service und unserem offiziellen Elasticsearch Service erfahren möchten, sehen Sie sich unseren AWS-Elasticsearch-Vergleich an.
Wir haben in letzter Zeit den Elasticsearch Service auf Elastic Cloud mit einer Vielzahl neuer Features ausgestattet, von denen alle Ihre Anwendungsfälle profitieren werden – Logging, Such-Analytics und viele andere mehr. Eine der wichtigsten Neuerungen war dabei die Einführung von Vorlagen für Heiß-Warm-Architektur-Deployments, mit denen Sie, zusammen mit reduzierten Preisen, ein besseres Preis-Leistungs-Verhältnis bei der Nutzung des Elasticsearch Service für Logging-Anwendungsfälle erhalten.
In diesem Blog-Post beschäftigen wir uns damit, wie Sie die neue Vorlage für Heiß-Warm-Deployments zusammen mit anderen leistungsfähigen Elastic Stack-Features, wie Machine Learning und Alerting, nutzen können, um in Ihren Log-Daten zusätzliche Einblicke zu erhalten – und das alles in weniger als 10 Minuten. Wenn Sie noch kein Elasticsearch Service-Konto haben, nutzen Sie das kostenlose 14-tägige Probeabo.
Was bedeutet „Heiß-Warm-Architektur“?
Das Modell der Heiß-Warm-Architektur bietet die nützliche Möglichkeit, ein Elasticsearch-Deployment in „heiße“ und „warme“ Datenknoten aufzuteilen. Die heißen Datenknoten speichern alle frisch eingehenden Daten und sind mit schnelleren Speichermedien ausgestattet, damit Daten schnell ingestiert und abgerufen werden können. Die warmen Knoten verfügen über eine höhere Speicherdichte und können Logging-Daten kostengünstiger über längere Zeiträume speichern. Die Kombination dieser beiden Arten von Datenknoten ermöglicht es, eingehende Daten effektiv zu verarbeiten und für Abfragen bereitzustellen und gleichzeitig Daten ohne exorbitante Kosten über längere Zeiträume hinweg aufzubewahren.
Dies ist besonders für Logging-Anwendungsfälle hilfreich, in denen der Fokus vor allem auf den neueren Log-Einträgen (z. B. die der letzten beiden Wochen) liegt, während das Abfragen der älteren Einträge (die aus Compliance- oder anderen Gründen aufbewahrt werden müssen) etwas länger dauern darf.
Erstellen eines Heiß-Warm-Deployments
Mit dem Elasticsearch Service ist das Bereitstellen einer Heiß-Warm-Architektur leicht zu bewerkstelligen. Das gilt auch für die Verwaltung der Indexkuratierungsrichtlinien, in denen festgehalten wird, wann und wie Daten von den heißen Datenknoten auf die warmen Datenknoten verlagert werden sollen – ein Feature, das Elastic Cloud den anderen gehosteten Elasticsearch-Anbietern voraus hat. Wie leicht ist es wirklich? Im Beispiel, das wir in diesem Blog-Post beschreiben, dauert es keine 5 Minuten, bis das Heiß-Warm-Logging-Cluster fix und fertig eingerichtet ist – einschließlich eines kostenlosen 1-GB-Machine-Learning-Knotens und eines 1-GB-Kibana-Knotens.
Zunächst müssen wir zur Elasticsearch Service-Konsole wechseln und dort auf Create Deployment (Deployment erstellen) klicken.
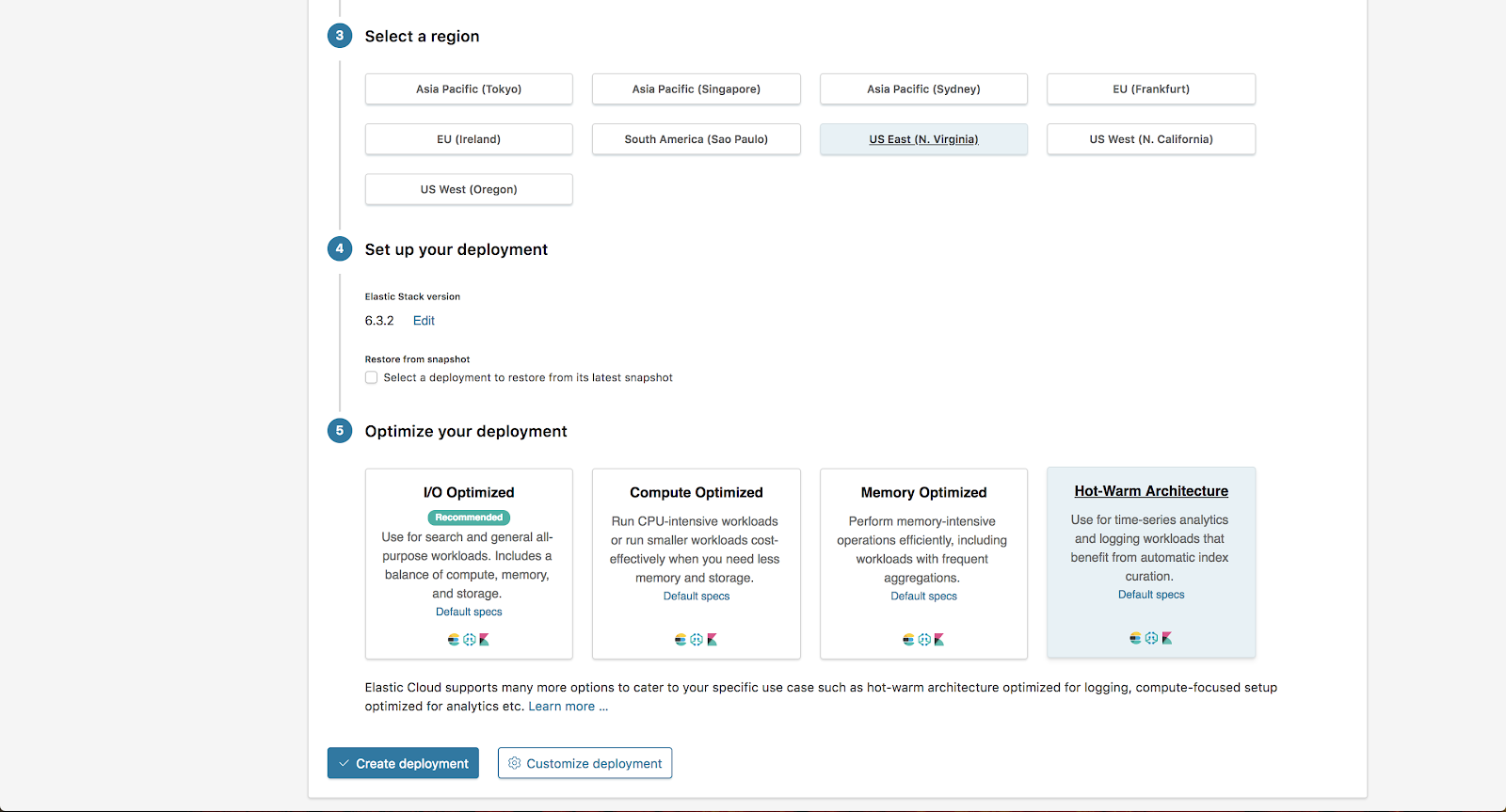
In unserem Beispiel wählen wir für AWS die Region „US East“ sowie im Abschnitt „Optimize your deployment“ (Deployment optimieren) die Option „Hot-Warm Architecture“ (Heiß-Warm-Architektur). Anschließend klicken wir auf Customize Deployment (Deployment anpassen).
Auf der Seite „Customization“ (Individuelle Anpassung) können wir die heiße und die warme Instanzkonfiguration unabhängig voneinander skalieren. Mehr darüber, wie Sie den Größenbedarf dieser Instanzen für Ihre konkreten Anforderungen ermitteln können, finden Sie in unserem Blog-Post zu Überlegungen zum Größenbedarf von Heiß-Warm-Architekturen.
Für unser Beispiel belassen wir die Werte so, wie sie standardmäßig eingestellt sind.
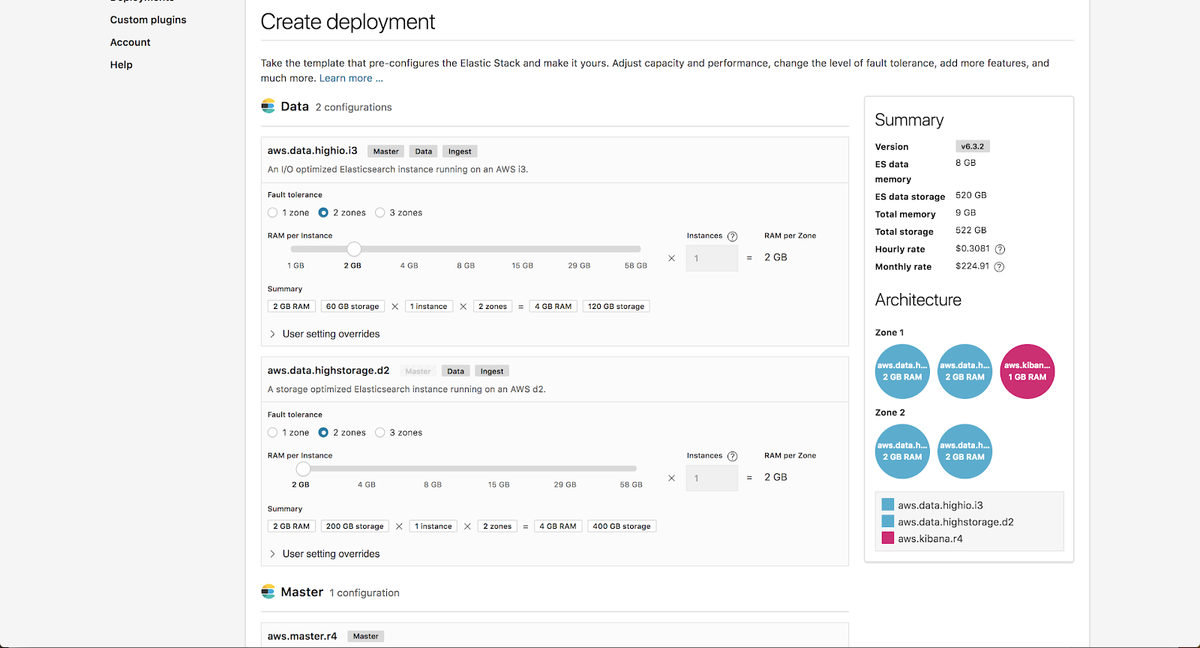
Zusätzlich werden wir für unser Deployment Machine Learning aktivieren. Alle Deployments auf Elasticsearch Service beinhalten einen kostenlosen 1-GB-Machine-Learning-Knoten und einen 1-GB-Kibana-Knoten.
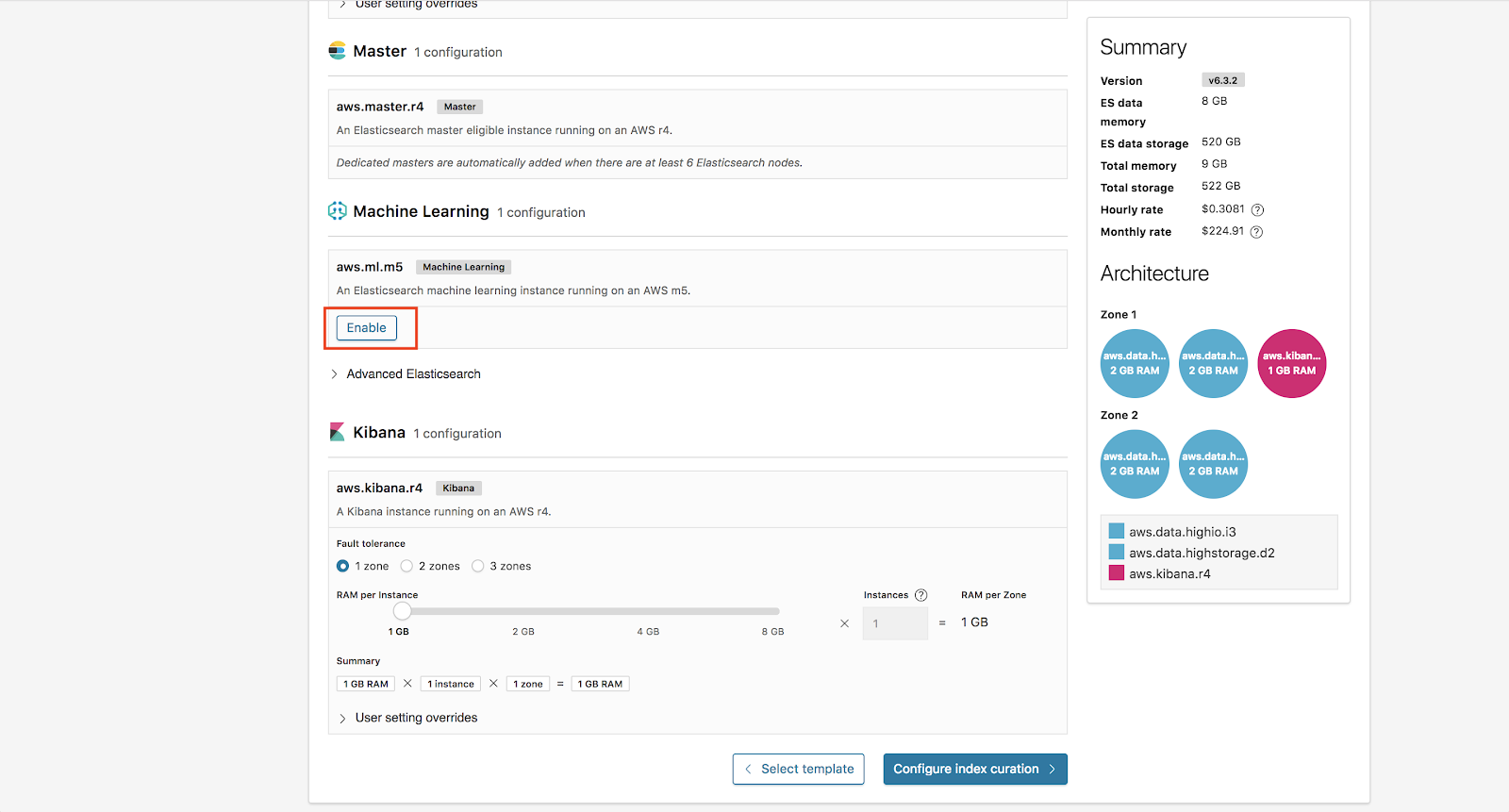
Von hier klicken wir jetzt auf Configure Index Curation (Indexkuratierung konfigurieren).
Indexkuratierung
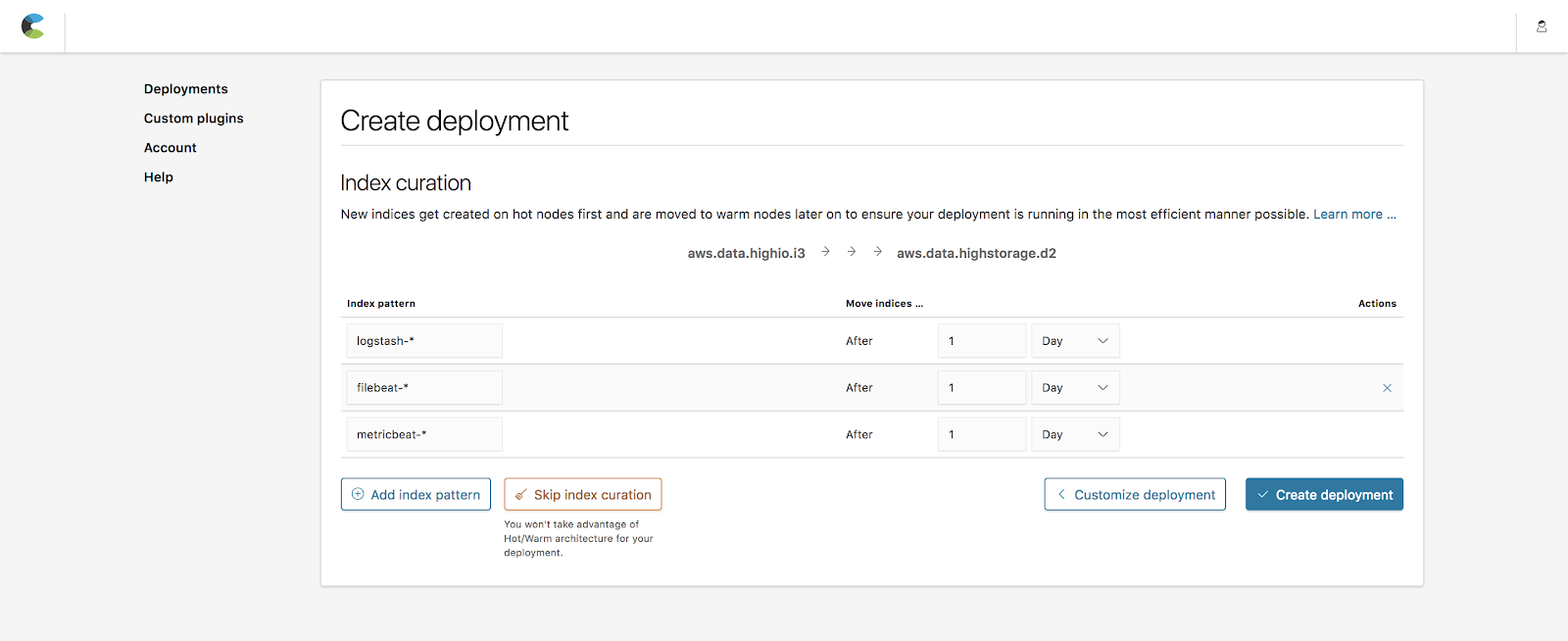
Die Indexkuratierungsfunktion ermöglicht es Ihnen festzulegen, wie lange Indizes auf heißen Knoten verbleiben, bevor sie auf warme Knoten verlagert werden. Zu den Standardwerten gehören beliebte Indizes, die von Beats (metricbeat-*, filebeat-*) und Logstash (logstash-*) erstellt werden und bei denen die Aufbewahrungszeit bis zur Umschichtung 1 Tag beträgt. Für unser Beispiel belassen wir die Standardwerte bei.
Hinweis: Sie können diese Werte für das fertig erstellte Deployment auf der Seite „Operations“ jederzeit ändern.
Wenn das erledigt ist, klicken wir auf Create Deployment (Deployment erstellen).
Das war’s auch schon – Sie verfügen jetzt über eine leistungsfähige Heiß-Warm-Architektur!
Senden von Daten
Nachdem wir nun unser Heiß-Warm-Deployment eingerichtet haben, können wir damit beginnen, ihm ein paar Logging-Daten zu senden. Zu diesem Zweck werden wir auf unserer lokalen Maschine Beats installieren und dann die Elasticsearch Service-Cloud-ID und das Passwort verwenden, das wir über unser Deployment generiert haben, um mit dem Senden von Daten zu beginnen. Wenn Sie mehr über das Einrichten von Beats und Elasticsearch Service erfahren möchten, lesen Sie unseren Blog-Post zur Nutzung von Metricbeat mit dem Elasticsearch Service.
Die Cloud-ID wird auf der Seite „Deployments“ angezeigt:
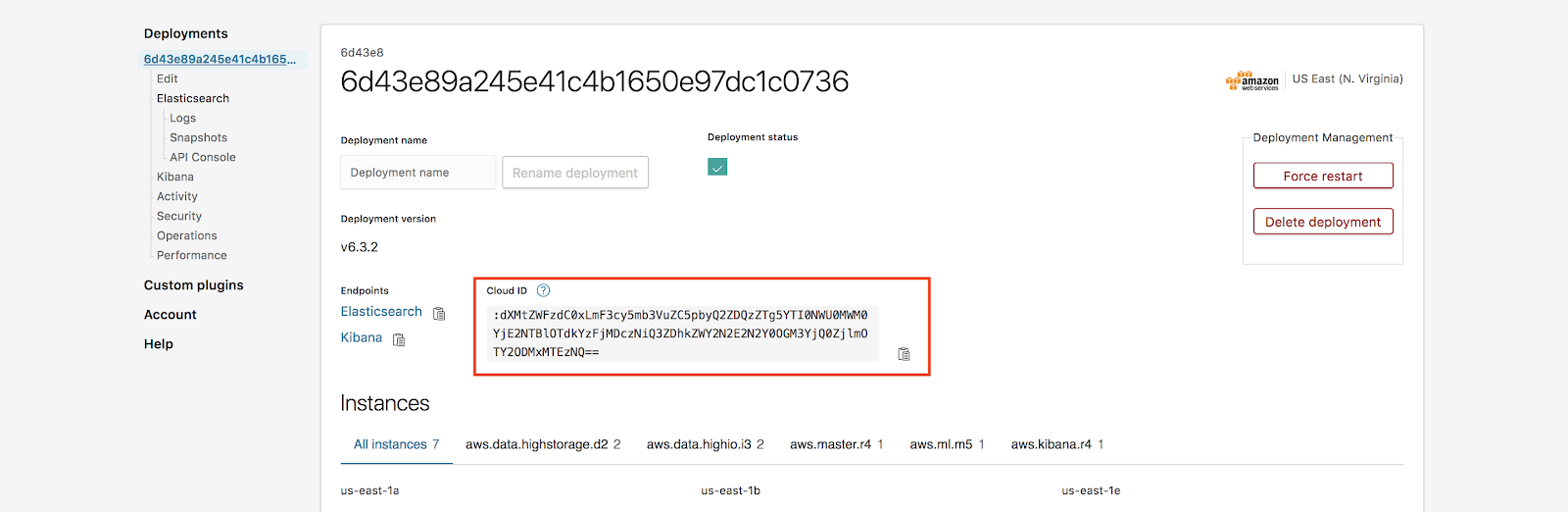
Hinweis: Passwort vergessen? Kein Problem! Sie können Ihr Elastic-Nutzerpasswort in Elasticsearch Service unter „Deployment“ > „Security“ (Sicherheit) > „Reset password“ (Passwort zurücksetzen) zurücksetzen.
Nachdem wir nun eingerichtet haben, dass Daten von unserer lokalen Maschine gesendet werden, können wir uns bei Kibana anmelden und einen Blick auf das Dashboard werfen. Wenn sich die Speichermedien auf den Knoten mit Daten füllen und immer neue Daten hinzukommen, beginnt Elasticsearch Service damit, jeden Tag Daten von den heißen Knoten auf die warmen Knoten zu verlagern.
Hinzufügen von Machine Learning
Eine weitere hilfreiche Neuerung ist, dass der Elasticsearch Service jetzt Machine Learning unterstützt. Außerdem haben alle Nutzer die Möglichkeit, ihren Deployments kostenlos einen 1-GB-Machine-Learning-Knoten hinzuzufügen. Da dieser bereits Bestandteil unseres Deployments ist, können wir zu Kibana wechseln und die Machine-Learning-App öffnen, um Machine-Learning-Jobs zu erstellen.
Weitere Informationen zum Machine Learning und zu anderen Anwendungsfällen finden Sie auf dieser Elastic-Seite zum Machine Learning.
Fazit
Die neuen Features des Elasticsearch Service erleichtern das Einrichten von und das Arbeiten mit leistungsfähigen Heiß-Warm-Architekturen – ein paar einfache Klicks genügen. Dies, gekoppelt mit anderen Elastic Stack-Features, wie Machine Learning und Security, trägt dazu bei, dass Sie mit dem Elasticsearch Service so einfach wie noch nie Logs und Metriken überwachen können.
Neugierig geworden? Sehen Sie sich das Ganze mit eigenen Augen an – nutzen Sie unser 14-tägiges Probeabo.