Überlegungen zum Größenbedarf von Hot-Warm-Architekturen für Logging-Daten und Metriken im Elasticsearch Service auf Elastic Cloud
Wenn Sie mehr über die Unterschiede zwischen dem Amazon Elasticsearch Service und unserem offiziellen Elasticsearch Service erfahren möchten, sehen Sie sich unseren AWS-Elasticsearch-Vergleich an.
Was für aufregende Zeiten! Elasticsearch Service auf Elastic Cloud bietet seit einiger Zeit Unterstützung für eine breite Palette von Hardware-Optionen sowie Deployment-Vorlagen, womit sich der Service geradezu anbietet, für die effiziente Verarbeitung von Logging-Daten und Metriken eingesetzt zu werden. Diese neue Flexibilität ist mit einer Vielzahl von Wahlmöglichkeiten verbunden – und damit auch mit der Qual der Wahl. Es ist nicht immer einfach, die am besten geeignete Architektur für Ihren Anwendungsfall auszuwählen und abzuschätzen, wie groß der Cluster sein muss. Aber keine Angst, wir helfen Ihnen dabei!
In diesem Blog-Post stellen wir Ihnen die verschiedenen Architekturen vor, die für Logging- und Metriken-Anwendungsfälle üblicherweise genutzt werden, und wir verraten Ihnen, wann Sie welche Architektur verwenden sollten. Außerdem erfahren Sie, welche Überlegungen bezüglich der Größe und Verwaltung Ihrer Cluster angestellt werden sollten, damit diese optimal genutzt werden.
Welche Architekturen stehen für mein Logging-Cluster zur Verfügung?
Im einfachsten aller Elasticsearch-Cluster haben alle Datenknoten dieselbe Spezifikation und übernehmen alle Rollen. Mit der Zeit werden dieser Art von Clustern häufig Knoten für spezifische Aufgaben hinzugefügt, z. B. spezialisierte Master-, Ingest- und Machine-Learning-Knoten. Das entlastet die Datenknoten und ermöglicht ein effizienteres Arbeiten. In einem solchen Cluster wird die Indexierungs- und Abfragelast gleichmäßig auf alle Datenknoten verteilt. Da alle Knoten dieselbe Spezifikation haben, wird dieser Aufbau als homogene oder uniforme Cluster-Architektur bezeichnet.
Ein weiterer sehr verbreiteter Architekturansatz, der sich besonders für die Arbeit mit zeitbasierten Daten, wie Log-Einträgen und Metriken, eignet, ist die sogenannte Hot-Warm-Architektur. Diese Architektur beruht auf dem Prinzip generell unveränderlicher Daten, die in zeitbasierte Indizes indexiert werden können. Damit enthält jeder Index Daten für einen ganz bestimmten Zeitraum, wodurch die Aufbewahrung und die Lebenszyklusverwaltung der Daten vereinfacht werden – man kann einfach einen kompletten Index löschen. Bei dieser Architektur kommen zwei unterschiedliche Arten von Datenknoten mit unterschiedlichen Hardware-Profilen zum Einsatz: „hot“ und „warme“ Datenknoten.
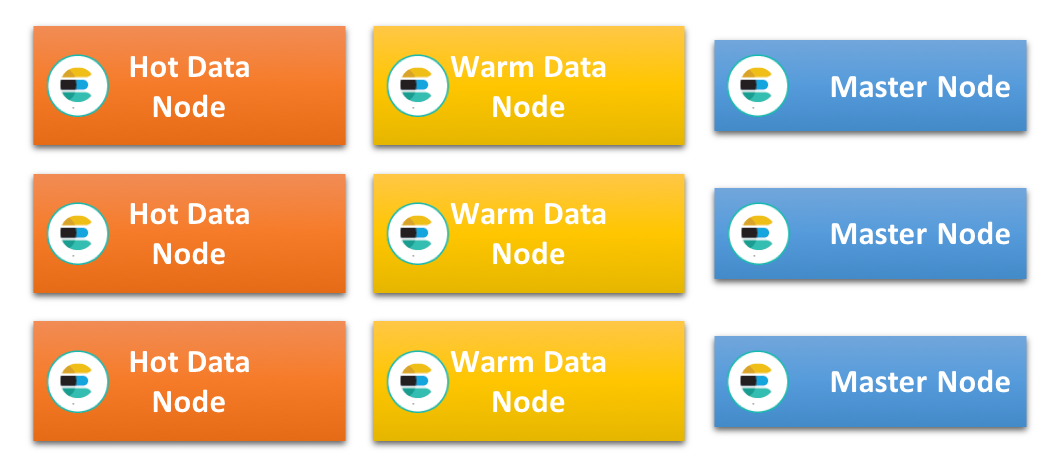
Auf den t werden die allerneuesten Indizes gespeichert und sie übernehmen damit die gesamte Indexierungslast im Cluster. Da die neuesten Daten in der Regel auch diejenigen Daten sind, die am häufigsten abgefragt werden, sind diese Knoten zumeist einer hohen Last ausgesetzt. Das Indexieren von Daten für Elasticsearch kann sehr CPU- und I/O-intensiv sein und die zusätzliche Belastung durch Abfragen bedeutet, dass diese Knoten leistungsfähig und mit sehr schnellen Speichermedien ausgestattet sein müssen. Das heißt im Allgemeinen, dass lokal angeschlossene SSDs zum Einsatz kommen.
Warme Datenknoten sind dagegen für die kostengünstige langfristige Speicherung schreibgeschützter Indizes im Cluster optimiert. Sie sind, was RAM und CPU angeht, in der Regel üppig bestückt, die Daten werden aber häufig nicht auf schnellen SSDs, sondern auf Festplatten oder im SAN gespeichert. Sobald die Aufbewahrungsfrist für einen Index auf den heißen Knoten zu Ende ist, werden keine Daten mehr in diesen Index geschrieben und der Index wird auf einen warmen Knoten verlagert.
In diesem Zusammenhang sei darauf hingewiesen, dass das Verlagern von Daten von einem heißen auf einen warmen Knoten nicht zwangsläufig mit längeren Abfragezeiten für diese Daten einhergeht. Da diese Knoten keine ressourcenintensiven Indexierungsaufgaben übernehmen müssen, können Sie häufig Abfragen für ältere Daten auch ohne SSD-basierte Speicherung in kürzester Zeit bearbeiten.
Da Datenknoten in dieser Art von Architektur sehr spezialisiert sind und unter hoher Last stehen können, wird empfohlen, mit dedizierten Master-, Ingest-, Machine-Learning- und Koordinierungsknoten zu arbeiten.
Welche Architektur ist die richtige für mich?
Bei vielen Anwendungsfällen kann jede dieser Architekturen funktionieren, sodass nicht immer klar ersichtlich ist, welche am besten ausgewählt werden soll. Es gibt jedoch gewisse Bedingungen und Einschränkungen, die die eine geeigneter als die andere machen können.
Ein wichtiger Faktor bei diesen Überlegungen ist die Art des für den Cluster verfügbaren Speichers. Die Hot-Warm-Architektur erfordert sehr schnelle Speichermedien an den heißen Datenknoten, weshalb sich diese Architektur nicht für Cluster eignet, denen nur langsamere Speichermedien zur Verfügung stehen. Wo dies der Fall ist, sollte auf eine homogene Architektur zurückgegriffen werden, in der das Indexieren und Abfragen auf möglichst viele Knoten verteilt werden kann.
Bei homogenen Clustern können oft lokale Festplatten oder SANs zum Einsatz kommen, die als Blockspeichermedien bereitstehen, aber auch hier ist der Trend zur SSD zu beobachten. Langsamere Speichermedien könnten bei einer sehr hohen Indexierungsgeschwindigkeit Schwierigkeiten bekommen, vor allem dann, wenn gleichzeitig Abfragen bedient werden müssen. Daher kann es lange dauern, bis der verfügbare Plattenspeicherplatz gefüllt ist. Das Speichern großer Datenmengen pro Knoten wäre daher nur dann möglich, wenn die Aufbewahrungsfrist angemessen lang ist.
Sollte im konkreten Anwendungsfall aber nur eine sehr kurze Aufbewahrungsfrist, z. B. weniger als 10 Tage, erforderlich sein, bleiben die Daten nach dem Indexieren nicht lange auf Abruf verfügbar. Das erfordert leistungsfähige Speichermedien. Eine Hot-Warm-Architektur kann funktionieren, aber ein homogener Cluster mit Knoten, auf denen nur heiße Daten abgelegt werden, ist möglicherweise die bessere und handhabbarere Lösung.
Wie viel Speicherplatz brauche ich?
Einer der Hauptfaktoren bei der Bestimmung der Cluster-Größe für Logging-Daten und/oder für Metriken ist die Menge an Speicherplatz. Das Verhältnis zwischen der Menge an Rohdaten und deren Platzbedarf nach dem Indexieren und Replizieren in Elasticsearch hängt zu einem Großteil davon ab, welche Daten wie indexiert werden. Das Diagramm unten zeigt die unterschiedlichen Phasen, die die Daten beim Indexieren durchlaufen.
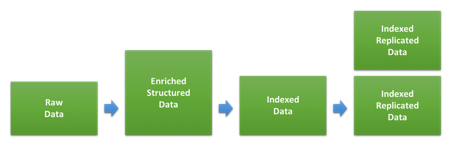
Der erste Schritt besteht in der Umwandlung der Rohdaten in die JSON-Dokumente, die wir in Elasticsearch indexieren werden. Wie sehr sich dies auf die Größe der Daten auswirkt, hängt zum einen vom ursprünglichen Format und der hinzugefügten Struktur ab und zum anderen von der Menge an Daten, die durch verschiedene Anreicherungen hinzukommt. Diese kann bei den einzelnen Datentypen sehr unterschiedlich sein. Wenn sich Ihre Log-Einträge bereits im JSON-Format befinden und Sie keine zusätzlichen Daten hinzufügen, kann es durchaus sein, dass die Größe gleichbleibt. Haben Sie jedoch textbasierte Webzugriffs-Logs, können die zusätzliche Struktur und die Informationen zum Nutzer-Agent und zum Standort zu einer deutlichen Vergrößerung der Daten führen.
Nachdem wir diese Daten in Elasticsearch indexiert haben, hängt es von den Indexeinstellungen und -Mappings ab, wie viel Platz auf dem Speichermedium benötigt wird. Die von Elasticsearch standardmäßig angewendeten dynamischen Mappings sind im Allgemeinen eher auf Flexibilität als auf möglichst wenig Speicherplatzbedarf optimiert. Sie können also Speicherplatz sparen, indem Sie die verwendeten Mappings durch benutzerdefinierte Indexvorlagen optimieren. Weitere Informationen dazu finden Sie in der Tuning-Dokumentation.
Um einzuschätzen, wie viel Speicherplatz eine bestimmte Art von Daten in Ihrem Cluster belegen wird, sollten Sie mindestens so viele Daten indexieren, dass Sie die Shard-Größe erreichen, die Sie wahrscheinlich in der Produktionsumgebung verwenden werden. Häufig wird der Fehler gemacht, dass mit zu kleinen Datenmengen getestet wird, was ungenaue Ergebnisse zur Folge haben kann.
Wie kann ich für das richtige Gleichgewicht zwischen Ingestieren und Abfrageverarbeitung sorgen?
Die meisten Nutzer ermitteln zur Bestimmung der Cluster-Größe oft als Erstes den maximalen Indexierungsdurchsatz des Clusters. Dieser Benchmark-Test lässt sich einfach einrichten und ausführen und die Ergebnisse können auch dazu genutzt werden zu ermitteln, wie viel Platz die Daten auf dem Speichermedium einnehmen werden.
Sobald die entsprechenden Feineinstellungen am Cluster und am Ingestionsprozess vorgenommen wurden und die maximale langfristige Indexierungsgeschwindigkeit feststeht, können wir berechnen, wie viel Zeit für das Füllen des Speichermediums an den Datenknoten nötig ist, wenn wir mit maximalem Durchsatz indexieren können. Damit erhalten wir einen Anhaltspunkt für die minimale Aufbewahrungsfrist bei diesem Knotentyp für den Fall, dass wir die Nutzung des verfügbaren Speicherplatzes maximieren möchten.
So verlockend es auch sein mag, sollten wir uns davor hüten, diesen Wert direkt zur Bestimmung der erforderlichen Größe zu verwenden, denn das würde uns keinerlei Reserven für die Verarbeitung von Abfragen lassen, da alle Systemressourcen mit dem Indexieren beschäftigt wären. Schließlich speichern die meisten Nutzer die Daten in Elasticsearch, um sie irgendwann einmal abfragen zu können, ohne dabei lange auf die Ergebnisse warten zu müssen.
Wie viel Reserve brauchen wir also für die Verarbeitung von Abfragen? Diese Frage kann man nur schwer allgemein beantworten, da viel von der Menge und der Art der zu erwartenden Abfragen sowie von den nutzerseitig erwarteten Reaktionszeiten abhängt. Am besten lässt sich dies ermitteln, indem man einen Benchmark-Test durchführt, bei dem realistische Abfrageaufkommen bei unterschiedlichen Datenmengen und Indexierungsgeschwindigkeiten getestet werden, wie in diesem Elastic{ON}-Talk zur quantitativen Größenbestimmung von Clustern und diesem Webinar zum Benchmarking und zur Größenbestimmung von Clustern mit Rally beschrieben.
Nachdem wir ermittelt haben, welchen Anteil am maximalen Indexierungsdurchsatz wir tatsächlich aufrechterhalten können, ohne die Fähigkeit zu verlieren, Abfragen mit annehmbaren Reaktionszeiten zu bedienen, können wir die erwartete Aufbewahrungsfrist an diese reduzierte Indexierungsgeschwindigkeit anpassen. Bei langsamerer Indexierung dauert es länger, bis die Speichermedien gefüllt sind.
Diese Anpassung kann es uns ermöglichen, kleine Traffic-Spitzen wegzustecken, sie geht aber im Großen und Ganzen von einer langfristig recht konstanten Indexierungsgeschwindigkeit aus. Wenn wir mit einem im Laufe des Tages schwankenden Traffic mit immer wieder auftretenden Spitzen rechnen, müssen wir davon ausgehen, dass die angepasste Indexierungsgeschwindigkeit dem Spitzenwert entspricht, und die mittlere Indexierungsgeschwindigkeit so weit herunterregeln, dass sie von jedem Knoten geschafft werden sollte. Sollten die Schwankungen vorhersehbar sein und jeweils länger anhalten, z. B. während der Bürozeiten, gäbe es auch die Möglichkeit, die Größe der „Hot Zone“ nur für diesen Zeitraum zu erhöhen.
Wie verwende ich all diesen Speicherplatz?
In Hot-Warm-Architekturen sind die warmen Knoten dafür eingerichtet, bei Bedarf große Datenmengen zu speichern. Das gilt auch für Datenknoten in einer homogenen Architektur, in der Daten lange aufbewahrt werden.
Wie viele Daten von einem Knoten tatsächlich gespeichert werden können, hängt oft davon ab, wie gut Sie die Heap-Nutzung in den Griff bekommen, denn diese ist bei Knoten mit hoher Speicherdichte häufig der Knackpunkt. Da die Heap-Nutzung in einem Elasticsearch-Cluster von einer Vielzahl von Faktoren abhängt – wie Indexierung, Abfragenverarbeitung, Caching, Cluster-Zustand, Felddaten und Shard-Overhead, um nur einige zu nennen –, sind die Ergebnisse von Anwendungsfall zu Anwendungsfall verschieden. Am besten lassen sich die Grenzen für Ihren konkreten Kontext ermitteln, indem Sie Benchmark-Tests anhand realistischer Daten und Abfragemuster durchführen. Es gibt jedoch eine Reihe allgemeiner Best Practices für Logging- und Metriken-Anwendungsfälle, die Ihnen dabei helfen, Ihre Datenknoten optimal zu nutzen.
Optimierte Mappings sind das A und O
Wie oben bereits erwähnt, hängt der Grad der Dichte Ihrer Daten auf den Speichermedien auch davon ab, welche Mappings Sie verwenden. Die Mappings können außerdem Auswirkungen auf die Menge der verwendeten Felddaten und auf die Heap-Nutzung haben. Wenn Sie zum Parsen oder Ingestieren Ihrer Daten Filebeat-Module oder Logstash-Module verwenden, verfügen diese bereits über optimierte Mappings und Sie müssen sich um diesen Punkt nicht allzu viele Gedanken machen. Wer allerdings benutzerdefinierte Log-Einträge parst und sich wesentlich auf die Fähigkeit von Elasticsearch zum dynamischen Mapping neuer Felder verlässt, sollte weiterlesen.
Beim dynamischen Mapping einer Zeichenfolge werden standardmäßig Multi-Felder verwendet, mit denen die Daten sowohl als Text (kann für die Freitextsuche ohne Rücksicht auf Groß- und Kleinschreibung genutzt werden) als auch als Keyword (wird beim Aggregieren von Daten in Kibana genutzt) zugeordnet werden. Diese Standardeinstellung bietet optimale Flexibilität, hat aber den Nachteil, dass die so erstellten Indizes auf der Platte relativ groß sind und viele Felddaten genutzt werden. Daher wird empfohlen, nach Möglichkeit die Mappings zu optimieren, um den Ressourcenbedarf bei wachsenden Datenmengen einzudämmen.
Bei Shards gilt: je größer, desto besser
Jeder Index in Elasticsearch enthält mindestens eine Shard und jede Shard ist mit Overhead verbunden, der eine gewisse Menge an Heap-Platz belegt. Wie in diesem Blog-Post zum Sharding beschrieben, ist das Verhältnis von Overhead zur Datenmenge bei kleineren Shards ungünstiger als bei größeren. Um also bei Knoten, die große Datenmengen speichern sollen, für eine möglichst geringe Heap-Belastung zu sorgen, ist es wichtig, die Shards so groß zu gestalten wie irgend möglich. Als Faustregel lässt sich sagen, dass die durchschnittliche Shard-Größe für die Langzeitaufbewahrung von Daten im Bereich zwischen 20 GB und 50 GB liegen sollte.
Da jede Abfrage oder Aggregation über einen einzelnen Thread pro Shard ausgeführt wird, ist die Mindestlatenzzeit bei Abfragen in der Regel von der Shard-Größe abhängig. Aber auch die Daten und die Abfragen selbst spielen eine Rolle, sodass es zwischen den Indizes innerhalb ein und desselben Anwendungsfalls durchaus Unterschiede geben kann. Bei einer konkreten Datenmenge und einem konkreten Datentyp ist es jedoch nicht sicher, dass die Performance bei einer größeren Zahl kleinerer Shards besser ist als bei einer einzelnen größeren Shard.
Um die Abfragenutzung und die Overhead-Größe optimal auszutarieren, ist es wichtig zu testen, wie sich verschiedene Shard-Größen auswirken.
Feinjustierung für optimales Speicherplatzvolumen
Die effiziente Komprimierung der JSON-Quelle kann sich deutlich darauf auswirken, wie viel Platz Ihre Daten auf dem Speichermedium belegen. Elasticsearch komprimiert diese Daten standardmäßig mit einem Komprimierungsalgorithmus, der Speicherplatz und Indexierungsgeschwindigkeit ausbalancieren soll, bietet mit dem best_compression-Codec aber optional auch einen aggressiveren Algorithmus an.
Dieser Codec kann für alle neuen Indizes verwendet werden, führt aber beim Indexieren zu einer Performance-Einbuße von ungefähr 5 bis 10 Prozent. Allerdings lässt sich dadurch oft auch viel Speicherplatz gewinnen, was den Verlust an Performance möglicherweise aufwiegen kann.
Wenn Sie dem Ratschlag im vorherigen Abschnitt gefolgt sind und Indizes zwangsweise zusammenführen, haben Sie auch die Option, unmittelbar vor dem zwangsweisen Zusammenführen die verbesserte Komprimierung anzuwenden.
Unnötige Lasten vermeiden
Der letzte Punkt mit Auswirkungen auf die Heap-Nutzung, der an dieser Stelle besprochen werden soll, ist die Verarbeitung von Anfragen. Alle Anfragen an Elasticsearch werden an dem Knoten koordiniert, an dem sie eintreffen. Die Arbeit wird dann aufgeteilt und an die Orte verteilt, wo sich die Daten befinden. Das gilt für das Indexieren genauso wie für die Abfragenverarbeitung.
Das Parsen und Koordinieren von Anfrage und Antwort kann recht Heap-intensiv sein. Sorgen Sie daher dafür, dass die Knoten, die als Koordinierungs- oder Indexierungsknoten fungieren, über genügend Heap-Reserven verfügen, um diese Aufgaben bewältigen zu können.
Bei Knoten, die für die Langzeitaufbewahrung eingerichtet sind, ist es oft sinnvoll, sie als dedizierte Datenknoten einzusetzen und alle anderen Aufgaben nach Möglichkeit von ihnen fernzuhalten. Dies kann erreicht werden, indem alle Abfragen entweder an heiße Knoten oder an nur für die Koordinierung zuständige Knoten geleitet werden.
Wie kann ich das auf mein Elasticsearch Service-Deployment anwenden?
Der Elasticsearch Service steht derzeit auf AWS und GCP zur Verfügung, und obwohl auf beiden Plattformen dieselben Instanzkonfigurationen und Deployment-Vorlagen verfügbar sind, unterscheiden sich die Spezifikationen ein wenig. In diesem Abschnitt sehen wir uns die verschiedenen Instanzkonfigurationen an und klären, wie diese zu den oben besprochenen Architekturen passen. Außerdem betrachten wir anhand eines Anwendungsfallbeispiels, was bei der Einschätzung der erforderlichen Cluster-Größe zu beachten ist.
Verfügbare Instanzkonfigurationen
Traditionell verfügt der Elasticsearch Service über Elasticsearch-Knoten, die von schnellem SSD-Speicherplatz unterstützt werden. Diese werden als highio-Knoten bezeichnet und warten mit einer ausgezeichneten I/O-Performance auf. Damit sind sie hervorragend als heiße Knoten in einer Hot-Warm-Architektur geeignet, können aber auch als Datenknoten in einer homogenen Architektur verwendet werden. Dies wird häufig für Knoten mit kurzen Aufbewahrungszeiten empfohlen, für die leistungsfähige Speichermedien benötigt werden.
Auf AWS und GCP haben highio-Knoten ein Speicherplatz-RAM-Verhältnis von 30 : 1, was bedeutet, dass pro 1 GB RAM 30 GB Speicherplatz verfügbar sind. Auf AWS stehen Knoten in den Größen 1 GB, 2 GB, 4 GB, 8 GB, 15 GB, 29 GB und 58 GB zur Verfügung, während die Knotengröße auf GCP 1 GB, 2 GB, 4 GB, 8 GB, 16 GB , 32 GB und 64 GB beträgt.
Ein weiterer Knotentyp, den es seit Kurzem auf Elastic Cloud gibt, ist der speicherplatzoptimierte highstorage-Knoten. Die Knoten dieses Typs sind mit großen Mengen langsameren Speicherplatzes ausgestattet und weisen ein Speicherplatz-RAM-Verhältnis von 100 : 1 auf. Ein 64-GB-highstorage-Knoten auf GCP verfügt über mehr als 6,2 TB Speicherplatz, während ein 58-GB-Knoten auf AWS 5,6 TB unterstützt. Diese Knotentypen werden auf den jeweiligen Plattformen mit denselben RAM-Größen wie die highio-Knoten angeboten.
Sie werden in Hot-Warm-Architekturen in der Regel als warme Knoten eingesetzt. Benchmark-Tests auf highstorage-Knoten haben gezeigt, dass dieser Knotentyp, selbst unter Berücksichtigung der unterschiedlichen Größen, auf GCP deutlich schneller ist als auf AWS.
Nutzung von 2 oder 3 Verfügbarkeitszonen
In den meisten Regionen haben Sie die Wahl zwischen 2 oder 3 Verfügbarkeitszonen und Sie können die Zahl der Knoten für jede Zone im Cluster getrennt festlegen. Wenn Sie innerhalb einer festen Zahl von Verfügbarkeitszonen bleiben, vergrößern sich die verfügbaren Cluster-Größen, zumindest bei kleineren Clustern, auf ungefähr das Doppelte. Dort, wo die Wahl zwischen 2 oder 3 Verfügbarkeitszonen besteht, können Sie die Größe in kleineren Schritten verändern, da beim Schritt von 2 auf 3 Verfügbarkeitszonen bei gleicher Knotengröße die Kapazität nur um 50 Prozent steigt.
Beispiel für Größenüberlegungen: Hot-Warm-Architektur
In diesem Beispiel geht es um die Überlegungen zum Größenbedarf eines Hot-Warm-Clusters, der Ingestionsgeschwindigkeiten von bis zu 100 GB roher Webzugriffs-Log-Daten pro Tag mit einer Aufbewahrungszeit von 30 Tagen unterstützt. Wir werden das Bereitstellen dieses Clusters mit Elastic Cloud auf AWS und auf GCP miteinander vergleichen.
Bitte beachten Sie, dass die hier verwendeten Daten lediglich ein Beispiel darstellen und in Ihrem konkreten Anwendungsfall sehr wahrscheinlich anders aussehen werden.
Schritt 1: Schätzen der Gesamtdatenmenge
Wir gehen in diesem Beispiel davon aus, dass die Daten mit Filebeat-Modulen ingestiert werden, was heißt, dass die Mappings optimiert sind. Aus Gründen der Einfachheit begnügen wir uns mit einem einzelnen Datentyp. Bei Benchmark-Tests für das Indexieren haben wir festgestellt, dass das Verhältnis zwischen der Größe der Rohdaten und der indexierten Größe auf dem Speichermedium bei ungefähr 1 : 1,1 liegt: 100 GB Rohdaten dürften nach dem Indexieren zu 110 GB Daten auf dem Speichermedium führen. Nach dem Replizieren liegt die Größe bei 220 GB.
Das ergibt über einen Zeitraum von 30 Tagen insgesamt 6600 GB indexierter und replizierter Daten, mit denen das Cluster als Ganzes umgehen können muss.
Bei diesem Beispiel wird davon ausgegangen, dass für alle Zonen eine gemeinsame Replizieren-Shard genutzt wird, was aus Performance- und Verfügbarkeitsgründen als Best Practice gilt.
Schritt 2: Bestimmen der Größe der heißen Knoten
Wir haben heiße Knoten, die diese Gruppe von Daten verwenden, einigen Benchmark-Tests unterzogen, um die maximalen Indexierungsanforderungen zu bestimmen, und dabei festgestellt, dass es bei Speichermedien auf highio-Knoten sowohl bei AWS als auch bei GCP ca. 3,5 Tage dauert, bis sie gefüllt sind.
Um etwas Reserve für die Abfragenverarbeitung und kleinere Spitzenwerte beim Traffic zu erhalten, nehmen wir an, dass wir nur eine Indexierungsgeschwindigkeit von 50 Prozent des Höchstwerts aufrechterhalten können. Wenn wir dafür sorgen möchten, dass der auf diesen Knoten verfügbare Speicherplatz vollständig genutzt wird, müssen wir daher für einen längeren Zeitraum in diese Knoten indexieren, was bedeutet, dass die Aufbewahrungszeit auf diesen Knoten angepasst werden muss.
Elasticsearch benötigt darüber hinaus etwas freien Speicherplatz für sich, um effizient arbeiten zu können. Damit wir die „Watermarks“ der Speichermedien nicht überschreiten, gehen wir davon aus, dass ein Polster von 15 Prozent zusätzlichem Speicherplatz benötigt wird. Dies spiegelt sich in der folgenden Tabelle in der Spalte Benötigter Speicherplatz wider. Diese Angaben genügen, um den RAM-Gesamtbedarf für die einzelnen Anbieter zu bestimmen.
| Plattform | Speicherplatz-RAM-Verhältnis | Fürs Füllen benötigte Zeit (Tage) | Effektive Aufbewahrungszeit (Tage) | Gespeicherte Datenmenge (GB) | Benötigter Speicherplatz (GB) | Erforderliche RAM-Größe (GB) | Zonenspezifikation |
| AWS | 30 : 1 | 3,5 | 7 | 1440 | 1656 | 56 | 29 GB, 2 VZ |
| GCP | 30 : 1 | 3,5 | 7 | 1440 | 1656 | 56 | 32 GB, 2 VZ |
Schritt 3: Bestimmen der Größe der warmen Knoten
Die Daten, bei denen die Aufbewahrungszeit auf den heißen Knoten abgelaufen ist, werden auf die warmen Knoten verlagert. Zur Bestimmung des benötigten Speicherplatzes können wir die Menge an Daten berechnen, für die auf diesen Knoten Platz sein muss, wobei wir den Overhead bei hohen „Watermark“-Werten berücksichtigen müssen.
| Plattform | Speicherplatz-RAM-Verhältnis | Effektive Aufbewahrungszeit (Tage) | Gespeicherte Datenmenge (GB) | Benötigter Speicherplatz (GB) | Erforderliche RAM-Größe (GB) | Zonenspezifikation |
| AWS | 100 : 1 | 23 | 5060 | 5819 | 58 | 29 GB, 2 VZ |
| GCP | 100 : 1 | 23 | 5060 | 5819 | 58 | 32 GB, 2 VZ |
Schritt 4: Hinzufügen weiterer Knotentypen
Zusätzlich zu den Datenknoten brauchen wir im Allgemeinen auch drei dedizierte Master-Knoten, um das Cluster robuster zu machen und eine hohe Verfügbarkeit zu gewährleisten. Da diese Knoten keinerlei Traffic bereitstellen müssen, können sie recht klein gehalten werden. Für den Anfang genügt es, Knoten mit 1 GB bis 2 GB über 3 Verfügbarkeitszonen einzurichten. Wenn das verwaltete Cluster größer wird, können diese Knoten dann auf ungefähr 16 GB über 3 Verfügbarkeitszonen skaliert werden.
Was kommt als Nächstes?
Wenn nicht bereits geschehen, starten Sie Ihr 14-tägiges kostenloses Probeabo des Elasticsearch Service und probieren Sie es selbst aus! Überzeugen Sie sich selbst, wie einfach es ist, den Elasticsearch Service einzurichten und zu verwalten. Wenn Sie Fragen haben oder zusätzliche Beratung zur Ermittlung der benötigten Größe Ihres Elasticsearch Service auf Elastic Cloud benötigen, kontaktieren Sie uns direkt oder besuchen Sie unser öffentliches Diskussionsforum.