Elasticsearch 功能
Elasticsearch 是一个分布式的 RESTful 搜索和分析引擎,可用来集中存储您的数据,以便您对形形色色、规模不一的数据进行搜索、索引和分析。
管理和运行
管理和运行
可扩展性和弹性
Elasticsearch 运行在一个分布式的环境中,从设计之初就考虑到了这一点,目的只有一个,让您永远高枕无忧。我们的集群可以随着您需求的增长而增长 — 只需再添加节点即可。
集群和高可用性
集群指一个或多个节点(服务器)的集合,它们共同存储您的全部数据并在所有节点上都提供联合索引和搜索功能。Elasticsearch 集群的一大特征是具有主分片和副本分片,可在节点发生故障时自动实现故障切换。当主分片遇到故障时,副本分片会取而代之。
了解集群和 HA自动节点恢复
当节点离开集群时(无论出于何种原因,有意为之还是其他情况),主节点会进行应对,具体做法是使用副本来替代节点并对分片进行再平衡。这些操作的目的是通过确保尽快完全复制每个分片,保护集群不会损失数据。
了解节点分配水平可扩展性
随着使用量的增加,Elasticsearch 可以进行扩展。添加更多数据和更多用例,当您开始遇到资源不足问题时,只需向集群中再添加一个节点以提高容量和可靠性即可。而且当您向集群中添加更多节点时,集群会自动分配副本分片,所以您可以从容应对未来变化。
了解如何进行水平扩展机架意识
您可以将定制节点属性作为意识属性,从而让 Elasticsearch 在分配分片时将实体空间配置考虑在内。如果 Elasticsearch 知道哪些节点在同一个实体服务器上、同一个机架上,或者位于同一个区内,Elasticsearch 就能相应地分配主分片和副本分片,从而将万一发生故障时丢失所有分片副本的风险降至最低。
了解分配意识灾难恢复:如果主集群发生故障,备用集群可以作为热备份。
地理邻近度:可以在本地满足读取需求,从而降低网络延时。
跨数据中心复制
长期以来,对于 Elasticsearch 上的任务关键型应用程序而言,跨数据中心复制一直都是一项硬性要求,之前通过利用其他技术这一问题在部分程度上得到了解决。现在,通过 Elasticsearch 内的跨集群复制功能,再也无需依赖其他技术来跨数据中心、跨地区或者跨 Elasticsearch 集群来复制数据了。
了解跨数据中心复制管理和运行
管理
Elasticsearch 自带各种管理工具和 API,可让您完全控制数据、用户、集群操作等方方面面。
从快照恢复
现在,使用云对象存储的 Elasticsearch 集群,可以从 ES 节点和对象存储传输某些数据,例如分片复制和分片恢复,而不是在 ES 节点之间传输数据,从而降低数据传输和存储成本。
了解如何从快照恢复索引生命周期管理
通过索引生命周期管理 (ILM),用户能够定义并自动执行政策,进而控制某个索引在四个阶段中分别应该停留多长时间,还可以定义并自动执行在各个阶段针对索引所采取的行动集合。由于可以将数据置于不同的资源等级,所以这样能够更好地帮助节省运行成本。
了解 ILM热节点:主动进行更新,也可查询
温节点:不再进行更新,但仍可查询
冷/冻节点:不再进行更新,也很少查询(尽管仍可以搜索,但速度会很慢)
删除:不再需要
数据层
数据层是通过节点角色属性将数据划分为热、温和冷节点的形式化方法,该属性自动定义节点的索引生命周期管理策略。通过分配热节点、温节点和冷节点角色,可以大大简化将数据从成本较高、性能较高的存储移到成本较低、性能较低的存储的过程,并促进整个过程的自动化,所有这些都不会影响您获得洞见的能力。
了解数据层- 热节点:在大多数性能实例上主动进行更新和查询
温节点:在性能较低的实例上查询数据的频率较低
冷节点:只读、很少被查询、显著减少存储而不降低性能,由可搜索快照提供支持
快照生命周期管理
作为后端的快照管理工具,快照生命周期管理 (SLM) API 能够允许管理员定义对 Elasticsearch 集群进行快照的频率。通过专属 UI,SLM 能够让用户为 SLM 政策配置保留期,自动创建/删除快照,并自动预先安排好快照事宜——这能够确保以合理频率对特定集群进行快照,从而按照客户的 SLA 进行恢复。
了解 SLM可搜索快照
可搜索快照使您能够直接查询快照,相比一次典型的从快照完成还原所需的时间,用时极短,因为仅需读取每个快照索引的必要部分即可完成请求。可搜索快照与冷层一起使用,可以在基于对象的存储系统(如 Amazon S3、Azure Storage 或 Google Cloud Storage)中备份副本分片,同时仍提供对它们的完全搜索访问权限,从而显著降低数据存储成本。
了解可搜索快照数据汇总
保存历史数据以进行分析是一项十分有用的实践,但人们经常会由于存档大量数据带来的巨大财务成本而不这么做。因此,保留期限的长短由财务现实决定,而不会取决于大量历史数据的帮助作用。汇总功能为人们提供了一种汇总和存储历史数据的方法,这样人们仍可用其来进行分析,但是成本与存储原始数据相比却要小得多。
了解数据汇总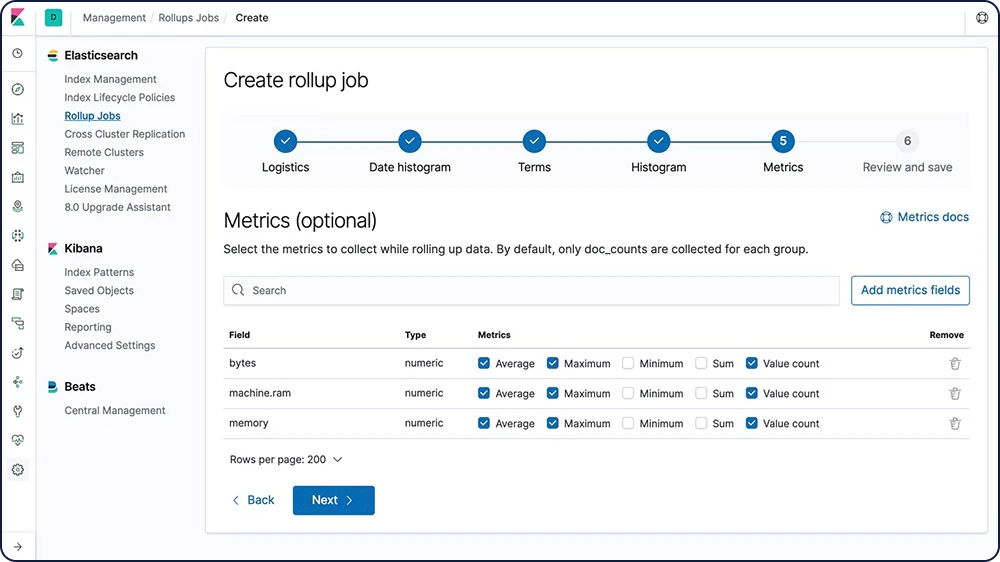
Transforms
Transforms 是两维的表格式数据结构,可以让索引后的数据更加易于分解。Transforms 能够执行聚合,对您的数据进行透视,形成以实体为中心的新索引。通过对数据进行转化和汇总,您便有可能通过其他方法(包括将其作为其他 Machine Learning 分析的数据源)对这些数据进行可视化和分析。
了解 Transforms升级助手 API
通过升级助手 API,您能够检查 Elasticsearch 集群的升级状态,并对在之前重大版本中创建的索引进行重新索引。这一助手能够帮助您为下一次 Elasticsearch 重大版本升级做好准备。
了解升级助手 APIAPI 密钥管理
API 秘钥的管理过程必须足够灵活,以便允许用户管理他们自己的秘钥,限制他们各自角色的访问权限。通过专属 UI,用户能够创建 API 秘钥并用其来提供长期凭据,同时与 Elasticsearch 进行交互;对自动化脚本和与其他软件间的工作流集成而言,这一交互过程十分常见。
了解如何管理 API 密钥管理和运行
安全性
Elastic Stack 的安全功能会向正确的人员授予正确的访问权限。IT、运营和应用程序团队能够依赖这些功能来管理善意用户并阻隔恶意破坏人员;与此同时,Elastic Stack 中存储的数据始终享有可靠的安全保障,公司高管和客户都能高枕无忧。
Elasticsearch 安全设定
某些设置很敏感,所以仅仅依靠文件系统权限来保护它们的值是不够的。对于这一用例,Elasticsearch 会提供密钥库来防止在未经授权的情况下访问敏感的集群设置。用户还可以选择对密钥库进行密码保护,从而进一步增强安全性。
详细了解安全设置数据静态加密支持
虽然 Elastic Stack 不能直接实施数据静态加密,但我们建议在所有主机上都配置磁盘级别加密。此外,快照目标也必须确保对数据进行静态加密。
基于属性的访问控制 (ABAC)
Elastic Stack 的 Security 功能同时还提供基于属性的访问控制 (ABAC) 机制,通过该机制,您能够使用属性来限制搜索查询和聚合中文档的访问权限。这一功能可让您在角色定义中实施访问政策,这样用户只有在拥有全部必备属性时,才能读取特定文档。
了解 ABACIP 筛选
您可以针对应用程序客户端、节点客户端或者传输客户端(而不仅局限于尝试加入集群的其他节点)应用 IP 筛选。如果某节点的 IP 地址在黑名单中,Elasticsearch 安全功能虽允许其连接至 Elasticsearch,但会立即断开连接且不会处理任何请求。
IP 地址或范围
xpack.security.transport.filter.allow: "192.168.0.1" xpack.security.transport.filter.deny: "192.168.0.0/24"
白名单
xpack.security.transport.filter.allow: [ "192.168.0.1", "192.168.0.2", "192.168.0.3", "192.168.0.4" ] xpack.security.transport.filter.deny: _all
IPv6
xpack.security.transport.filter.allow: "2001:0db8:1234::/48" xpack.security.transport.filter.deny: "1234:0db8:85a3:0000:0000:8a2e:0370:7334"
主机名
xpack.security.transport.filter.allow: localhost xpack.security.transport.filter.deny: '*.google.com'了解 IP 筛选
Security Realm
Elastic Stack 的 Security 功能会使用 Realm 或者一个或多个基于令牌的身份验证服务来验证用户身份。Realm 可基于身份验证令牌来解决问题并验证用户身份。Security 功能提供大量内置 Realm。
了解 Security Realm单点登录 (SSO)
通过将 Elasticsearch 作为后端服务,Elastic Stack 支持通过 SAML 单点登录方式 (SSO) 登录 Kibana。通过 SAML 身份验证,可以允许用户使用外部身份提供商服务(例如 Okta 或 Auth0)登录 Kibana。
了解 SSO管理和运行
Alerting
Elastic Stack 的 Alerting 功能可让您充分利用 Elasticsearch 查询语言,当数据发生令您感兴趣的变化后,您能够发现这些变化。换言之,如果您能够在 Elasticsearch 中查询某些数据,就能够创建相应的告警。
高可用性、可扩展警报
这么多大大小小的公司/组织信得过使用 Elastic Stack 来满足他们的告警需求,肯定有其原因。通过可靠且安全地采集任何来源、任何格式的数据,分析师可以实时搜索、分析和可视化关键数据,而且完成所有这一切时都能使用定制、可靠的告警。
了解告警通过电子邮件、Webhook、IBM Resilient、Jira、Microsoft Teams、PagerDuty、ServiceNow、Slack 和 xMatters 传送的通知
利用针对电子邮件、IBM Resilient、Jira、Microsoft Teams、PagerDuty、ServiceNow、xMatters 和 Slack 的内置集成功能关联告警。通过 Webhook 输出与任何其他第三方系统进行集成。
了解告警通知选项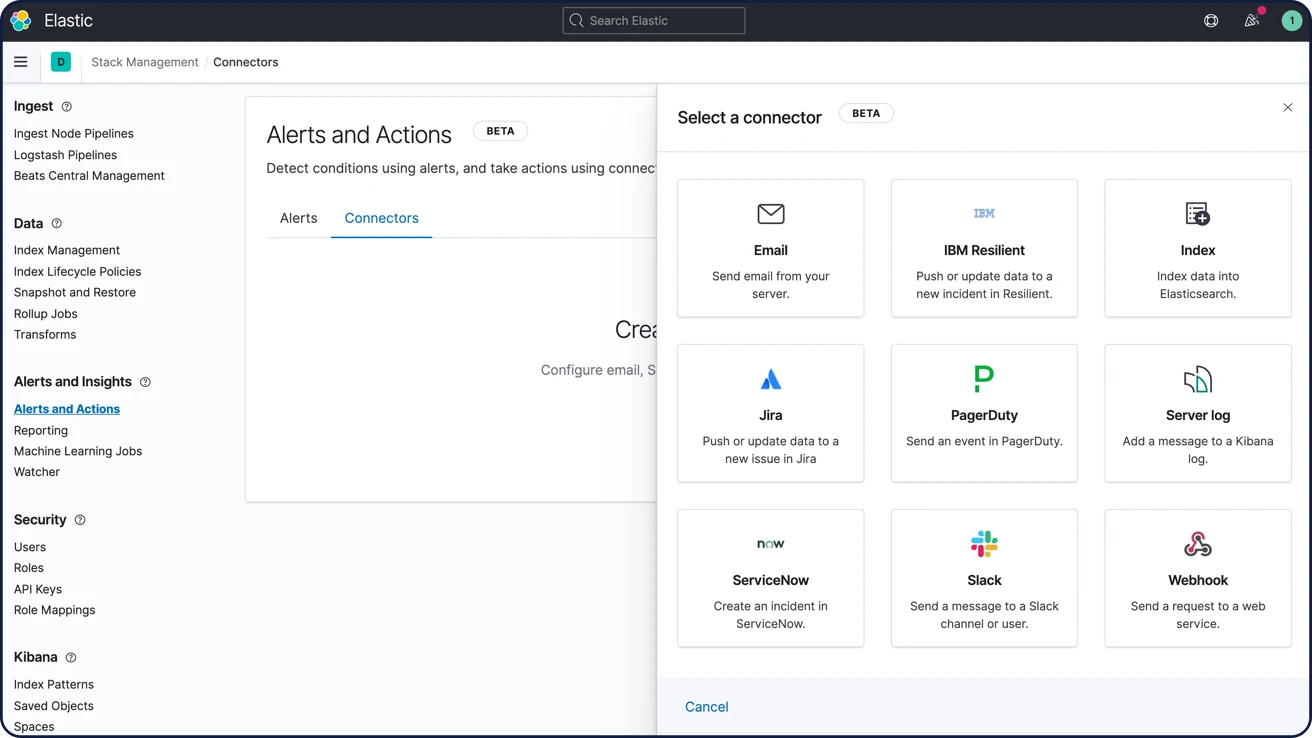
管理和运行
客户端
Elasticsearch 让您能够以自己最舒适的方式处理数据。我们为您提供灵活的支持,包括 REST 风格的 API、语言客户端、强大的 DSL,以及其他工具(甚至包括 SQL),确保您不会受到局限。
语言客户端
Elasticsearch 使用的是 RESTful 风格的标准 API 和 JSON。此外,我们还构建和维护了很多其他语言的客户端,例如 Java、Python、.NET、SQL 和 PHP。与此同时,我们的社区也贡献了很多客户端。这些客户端使用起来简单自然,而且就像 Elasticsearch 一样,不会对您的使用方式进行限制。
探索可用的语言客户端Elasticsearch DSL
Elasticsearch 提供一套基于 JSON 的完整查询 DSL(域特定语言),可用来定义查询。查询 DSL 为全文本搜索(包括词汇和短语匹配、模糊匹配、通配符、regex、嵌套查询、地理查询等等)提供了强大的搜索选项。
了解 Elasticsearch DSLGET /cn/_search
{
"query": {
"match" : {
"message" : {
"query" : "this is a test",
"operator" : "and"
}
}
}
}
Elasticsearch SQL
Elasticsearch SQL 这项功能可以允许针对 Elasticsearch 实时执行类似 SQL 的查询。无论使用的是 REST 界面、命令行,还是 JDBC,所有客户端都能在 Elasticsearch 中以原生方式使用 SQL 进行数据搜索和聚合。
了解 Elasticsearch SQL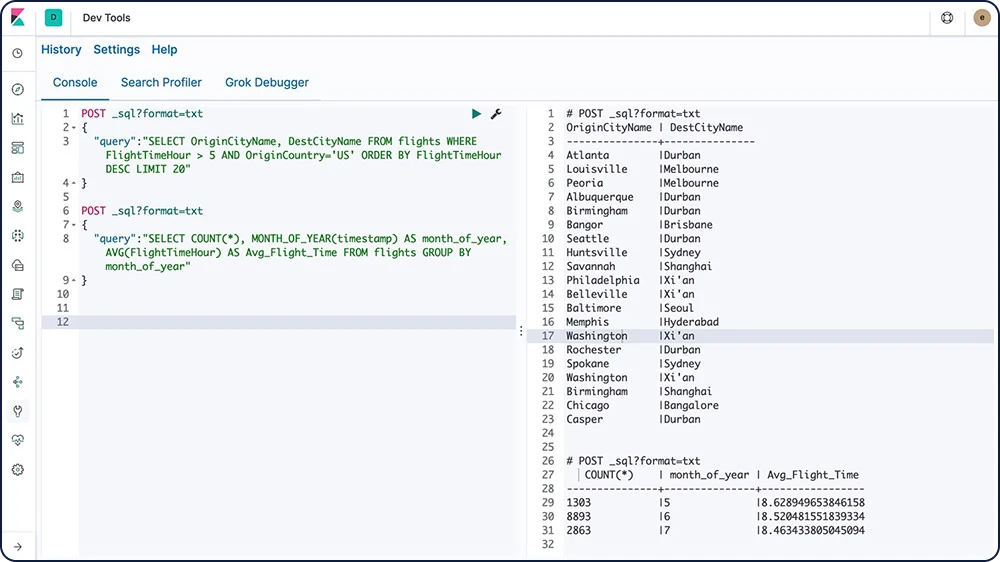
JDBC 客户端
Elasticsearch SQL JDBC 驱动程序是一个适用于 Elasticsearch 的 JDBC 驱动程序,功能全面丰富。这是一个 Type 4 驱动程序,所以它不依赖于任何平台,是一个直接连到数据库的独立且纯粹的 Java 驱动程序,可以将 JDBC 调用转化为 Elasticsearch SQL。
了解 JDBC 客户端ODBC 客户端
Elasticsearch SQL ODBC 驱动程序是一个适用于 Elasticsearch 的 3.80 ODBC 驱动程序,功能丰富。这是一个核心层级的驱动程序,提供可通过 Elasticsearch SQL ODBC API 访问的全部功能,将 ODBC 调用转换为 Elasticsearch SQL。
了解 ODBC 客户端面向 Elasticsearch 的 Tableau 连接器
借助面向 Elasticsearch 的 Tableau 连接器,Tableau Desktop 和 Tableau Server 的用户能够轻松访问 Elasticsearch 中的数据。
下载 Tableau 连接器管理和运行
REST API
Elasticsearch 提供了全面且强大的 REST API,供您用来与自己的集群进行交互。
搜索 API
借助 Elasticsearch 的搜索 API,您实施项目时不再局限于全文本搜索。这些 API 还能帮助您实施提示器(词语、短语、补全等等),执行排名评估,甚至就搜索时为何返回或未返回某个文档提供反馈。
探索可用的搜索 API聚合 API
聚合框架可以基于搜索查询帮助提供聚合后的数据。该框架的基础是称为聚合的简单构建基块,人们可以对这些构建基块进行编辑以生成有关数据的复杂汇总。可以将聚合看做一个工作单元,用来针对一组文档创建分析信息。
探索可用的聚合 API指标聚合
桶聚合
管道聚合
矩阵聚合
累计基数聚合
Geohexgrid 聚合
管理 API
借助各种各样的管理类 API 来通过程序方式管理您的 Elasticsearch 集群。我们提供适用于各种情况(包括索引管理和映射、集群和节点、许可和安全,等等)的 API。而且,如果您需要获得人类易读格式的结果,只需使用 cat API 就可以了。
管理和运行
集成
Elasticsearch 是一个开源且不区分语言的应用程序,所以您可以使用插件和集成选项轻松扩展 Elasticsearch 的功能。
Elasticsearch-Hadoop
Elasticsearch for Apache Hadoop(亦称 Elasticsearch-Hadoop 或 ES-Hadoop)是一个免费开源、单体可执行的独立小型库,支持 Hadoop 作业与 Elasticsearch 进行交互。有了这一工具,您可以轻松构建动态的嵌入式搜索应用来处理 Hadoop 数据,还可以使用全文本、空间地理查询和聚合来执行深入的低延时分析。
了解 ES-HadoopApache Hive
Elasticsearch for Apache Hadoop 为 Apache Hive 提供出色支持;Apache Hive 是一个适用于 Hadoop 的数据仓库系统,可以协助轻松地完成多项任务,例如数据汇总、临时查询,以及对存储在 Hadoop 兼容文件系统中的大型数据集进行分析。
了解 Apache Hive 集成Apache Spark
Elasticsearch for Apache Hadoop 为 Apache Spark(一款快速的通用型集群计算系统)提供出色的支持。它提供 Java、Scala 和 Python 格式的高级 API,同时还提供可支持通用执行图表的优化引擎。
了解 Apache Spark 集成插件和集成
Elasticsearch 是一款免费开源且不区分语言的应用程序,您可以使用插件和集成选项轻松扩展 Elasticsearch 的功能。通过各种插件,您能够以定制方式增强核心 Elasticsearch 功能,而多种集成选项能够让您更轻松地使用 Elasticsearch 的外部工具或模块。
探索可用的 Elasticsearch 插件API 扩展插件
告警插件
分析插件
发现插件
采集插件
管理插件
映射工具插件
安全插件
快照/恢复存储库插件
存储库插件
管理和运行
部署
从公共云到私有云,我们都能够让您轻松地运行和管理 Elasticsearch。
下载并安装
轻松入门,历来如此。只需下载并安装存档形式的 Elasticsearch 和 Kibana,也可使用文件包管理工具进行下载和安装。您瞬间即可对数据进行索引、分析和可视化。而且,使用默认分发包的话,您还可以通过 30 天的免费试用计划体验白金级功能,例如 Machine Learning、Security、图表分析等等。
下载 Elastic StackElastic Cloud
Elastic Cloud 是我们不断壮大的 SaaS 产品套件系列,旨在让您轻松地在云中部署、操作和扩展 Elastic 产品和解决方案。从易用的托管式和受管式 Elasticsearch 体验到功能强大、直接可用的搜索解决方案,Elastic Cloud 都是无缝实现让 Elastic 为您效劳的一个跳板。免费试用任何 Elastic Cloud 产品,14 天内免费 — 无需提供信用卡。
开始使用 Elastic Cloud开始免费试用 Elasticsearch Service
Elastic Cloud Enterprise
通过 Elastic Cloud Enterprise (ECE),您可以配置、管理和监控任何规模、任何基础设施中的 Elasticsearch 和 Kibana,同时通过单个控制台管理一切。您可以选择要在哪里运行 Elasticsearch 和 Kibana:物理硬件、虚拟环境、私有云、公有云中的私有区域,或者只是普通的公有云(例如,Google、Azure 和 AWS)。所有这些我们都支持。
欢迎试用 ECE,30 天内免费Elastic Cloud on Kubernetes
基于 Kubernetes Operator 模式,Elastic Cloud on Kubernetes (ECK) 扩展了 Kubernetes 的基本编排功能,支持在 Kubernetes 上设置和管理 Elasticsearch 和 Kibana。使用 Elastic Cloud on Kubernetes 后,对于在 Kubernetes 中运行 Elasticsearch,这可简化在部署、升级、快照、扩展、高可用性和安全性等方面的流程。
使用 Elastic Cloud on Kubernetes 进行部署采集和扩充
采集和扩充
采集
无论您想用何种方式将数据采集到 Elastic Stack,都没有问题!REST 风格的 API、语言客户端、采集节点、轻量型采集器或者 Logstash,统统都可供您使用。您不会受限于语言列表,而且由于我们的开源性质,您甚至在采集的数据类型方面也有无尽选择。如果您需要采集专有的数据类型,我们可以提供相应的库和步骤,让您创建自己独有的采集方法。而且,如果愿意的话,您还可以反哺社区,分享您的方法,让后来者避免无谓的重复。
客户端和 API
Elasticsearch 使用的是 RESTful 风格的标准 API 和 JSON。此外,我们还构建和维护了很多其他语言的客户端,例如 Java、Python、.NET、SQL 和 PHP。与此同时,我们的社区也贡献了很多客户端。这些客户端使用起来简单自然,而且就像 Elasticsearch 一样,不会对您的使用方式进行限制。
采集节点
Elasticsearch 提供大量的节点类型,其中有一种便是专门针对数据采集的。采集节点可以执行预处理管道(由一个或多个采集处理器构成)。取决于采集处理器所执行操作的类型以及所需的资源,比较合理的一种做法可能是设立专门的采集节点,让它们仅执行此项具体任务。
Beats
Beats 是开源数据采集器,您可以将其作为代理安装在服务器上,从而将运行数据发送到 Elasticsearch 或 Logstash。Elastic 提供各种 Beats 来采集各类常见日志、指标以及其他各种数据类型。
Auditbeat,适用于 Linux 审计日志
Filebeat,适用于日志文件
Functionbeat,适用于云端数据
Heartbeat,适用于可用性数据
Journalbeat,适用于 systemd 日志
Metricbeat,适用于基础设施日志
Packetbeat,适用于网络流量
Winlogbeat,适用于 Windows 事件日志
Logstash
Logstash 是一个开源的数据采集引擎,具有实时管道传输功能。Logstash 能够将来自单独数据源的数据动态集中到一起,对这些数据加以标准化并传输到您所选的地方。清理并民主化您的全部数据,将其用于多样化的高级下游分析和可视化用例。
社区贡献的采集器
如果您有特定的用例需要解决,我们鼓励您创建一个社区 Beat。我们创建了一个基础架构来简化这一流程。libbeat 库完全以 Go 写成,可以提供一个 API,所有 Beat 都可使用该 API 向 Elasticsearch 输送数据、配置输入选项、实施日志以及完成其他操作。
现在社区贡献的 Beats 有 100 多个,所以现在能提供专门针对下列内容的代理:Cloudwatch 日志和指标、GitHub 活动、Kafka 主题、MySQL、MongoDB Prometheus、Apache、Twitter,不可胜数。
探索社区开发的可用 Beats采集和扩充
数据扩充
Elasticsearch 提供各种各样的分析器、分词器、筛选器以及扩充选项,助您将原始数据转化为有价值的信息。
Elastic Common Schema
使用 Elastic Common Schema (ECS) 统一分析来自不同来源的数据。通过 ECS,用户可以更加广泛地应用检测规则、Machine Learning 作业、仪表板以及其他安全内容,可以更加具有针对性地创建搜索,还能更轻松地记住字段名称。
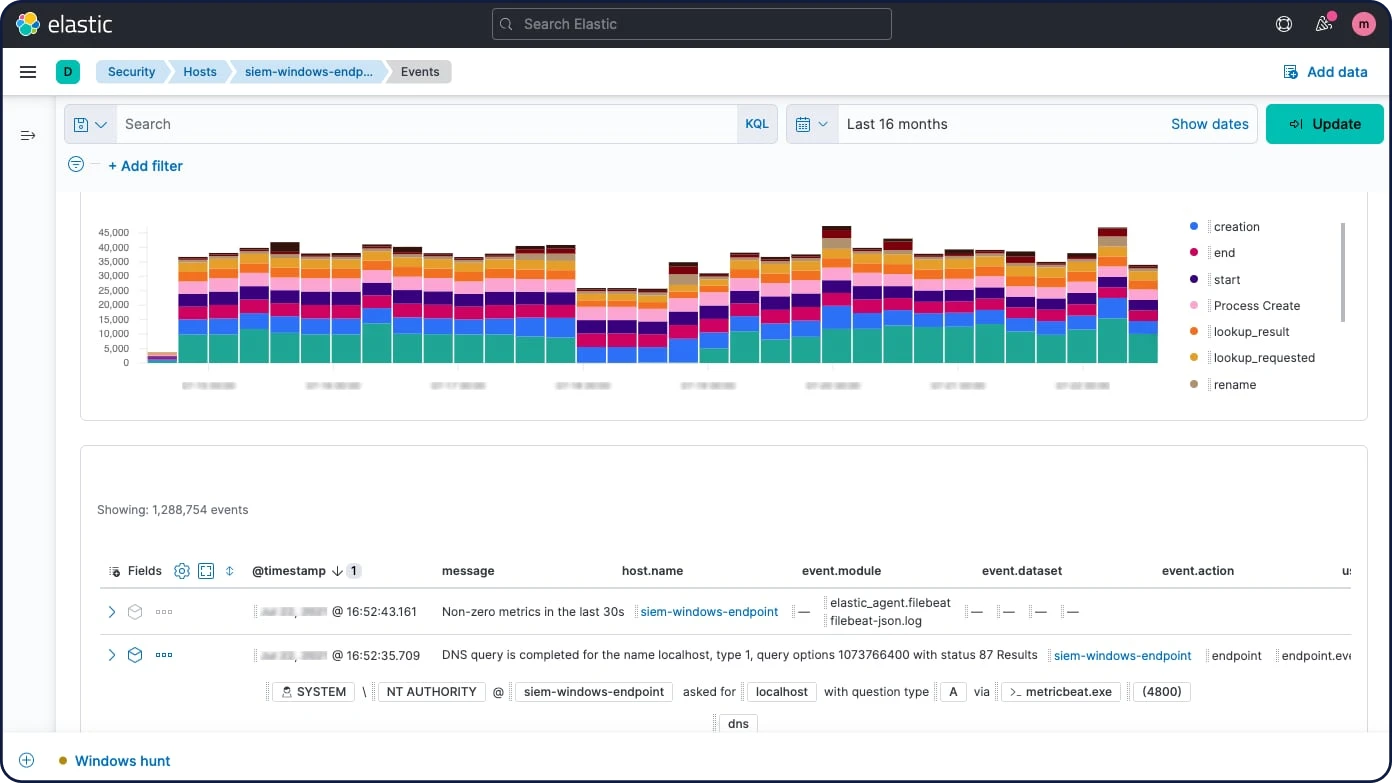
处理器
在真正索引文档之前,使用采集节点对文档进行预处理。采集节点会拦截批量或索引请求,对其进行转化,然后再将这些文档传回索引或批量 API 中。采集结点提供超过 25 种不同的处理器,包括附加、转化、日期、分解、丢弃、失败、grok、连接、移除、设置、拆分、排序、删除字符等等。
Match enrich 处理器
match 采集处理器能够允许用户在采集时查询数据并指明从哪个索引中提取已扩充数据。这可帮助到需要向数据中添加元素的 Beats 用户,他们现在无需从 Beats 转换到 Logstash,可以直接参考采集管道。用户还能够使用处理器对数据进行标准化,从而取得更好的分析效果,并完成更多常见查询。
Geo-match enrich 处理器
geo-match enrich 处理器十分实用,能够让用户改善搜索和汇总功能,因为借助这一工具,用户无需以地理坐标形式定义查询和汇总,便能利用自己的地理数据。与 match enrich 处理器类似,用户可以在采集时查询数据并找到需从中提取已扩充数据的最佳索引。
数据存储
数据存储
灵活性
Elastic Stack 是一套强大的解决方案,几乎适用于任何用例。尽管 Elastic Stack 最为人们所熟知的是高级搜索功能,但其灵活设计也使得它成为满足很多不同需求(包括文档存储、时序分析和指标,以及地理空间分析)的理想工具。
数据类型
Elasticsearch 针对文档中的字段支持大量不同的数据类型,而且这些数据类型中的每一种都拥有各自的多个子类型。这能够让您以十分高效和有效的方式存储、分析和利用任何数据。Elasticsearch 已针对某些数据类型进行优化,这些数据类型包括:
文本
形状
数字
向量
Histogram
日期/时序
扁平字段
地理地点/地理形状
非结构化数据 (JSON)
结构化数据
全文本搜索(倒排索引)
Elasticsearch 使用的是一种名为倒排索引的结构,这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引包含一个由所有文档中出现的唯一词语构成的列表,对于每一个词语而言,则为该词语所在文档的列表。如要创建倒排索引,我们首先要将每个文档的内容字段拆分成单独的词语(我们称为词汇或分词),然后创建一个包含所有唯一词汇的有序列表,再然后列出每个词语出现在哪个文档中。
文档存储库(针对非结构化数据)
即使是非结构化数据,Elasticsearch 也能进行采集和分析(但进行结构化后可提高速度)。这一设计使得人们可以轻松上手,同时也使得 Elasticsearch 成为一个有效的文档存储库。尽管 Elasticsearch 不是 NoSQL 数据库,其仍能提供类似功能。
时序/分析(列式存储库)
借助倒排索引,查询能够快速地查找搜索词语,但是排序和聚合却需要一套不同的数据访问模式。这些查询不会查找词语并寻找文档,相反它们需要能够查找文档并找到存在于文章字段中的词语。文档值是 Elasticsearch 中的磁盘数据结构,是在文档索引时创建的,正是这一结构使得此数据访问模式成为可能,允许以列式方式进行搜索。这一点使得 Elasticsearch 在处理时序和指标分析时表现十分突出。
数据存储
安全性
对于安全性,绝不能停留于集群层面。使用 Elasticsearch,可确保直至字段级的数据安全。
数据静态加密支持
虽然 Elastic Stack 不能直接实施数据静态加密,但我们建议在所有主机上都配置磁盘级别加密。此外,快照目标也必须确保对数据进行静态加密。
数据存储
管理
Elasticsearch 能够让您完全管理自己的集群以及其中的节点、自己的索引以及其中分片,而且更重要的是,您能够管理其中存储的所有数据。
集群式索引
集群指一个或多个节点(服务器)的集合,它们共同存储您的全部数据并在所有节点上都提供联合索引和搜索功能。通过此架构,您能够非常轻松地进行水平扩展。Elasticsearch 提供全面且强大的 REST API 和 UI,供您用来管理自己的集群。
汇总索引
保存历史数据以进行分析是一项十分有用的实践,但人们经常会由于存档大量数据带来的巨大财务成本而不这么做。因此,保留期限的长短由财务现实决定,而不会取决于大量历史数据的帮助作用。汇总功能为人们提供了一种汇总和存储历史数据的方法,这样人们仍可用其来进行分析,但是成本与存储原始数据相比却要小得多。
搜索和分析
搜索和分析
全文搜索
Elasticsearch 以其强大的全文本搜索功能而闻名。速度之所以这么快,因为 Elasticsearch 核心采用的是倒排索引;它功能之所以这么强大,是因为采用了可调相关度分数、高级查询 DSL 以及可提升搜索能力的诸多功能。
倒排索引
Elasticsearch 使用的是一种名为倒排索引的结构,这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引包含一个由所有文档中出现的唯一词语构成的列表,对于每一个词语而言,则为该词语所在文档的列表。如要创建倒排索引,我们首先要将每个文档的内容字段拆分成单独的词语(我们称为词汇或分词),然后创建一个包含所有唯一词汇的有序列表,再然后列出每个词语出现在哪个文档中。
运行时字段
运行时字段是一种在查询时评估的字段(读时模式)。您可以随时引入或修改运行时字段(包括对文档编制了索引后),并且可以将运行时字段定义为查询的一部分。运行时字段和索引字段均通过相同的接口公开给查询,因此一个字段在某数据流的有些索引中可以是运行时字段,而在该数据流其他索引中可以是索引字段,而查询不需要知道这一点。索引字段可提供最优查询性能,运行时字段则可在对文档编制索引后允许灵活地更改数据结构,因此与索引字段形成了优势互补。
查找运行时字段
查找运行时字段可让您灵活地将查找索引中的信息添加到主索引的结果中,具体方式是在这两个索引上定义一个关联各文档的键。与运行时字段一样,这项功能在查询时使用,可以灵活地进行数据扩充。
相关性评分
相似度(相关性评分/排名模型)定义对匹配文档进行评分的方式。默认情况下,Elasticsearch 使用 BM25 相似度,但同时还提供很多其他相似度选项;BM25 相似度是一种基于 TF/IDF 的高级相似度,其中包含针对短字段(例如名称)的内置 tf 标准化。
向量搜索 (ANN)
凭借 Lucene 9 新发布的近似最近邻搜索功能或基于 HNSW 算法的 ANN 支持,新的 _knn_search API 终端通过向量相似度,促进了可扩展性和性能更优的搜索体验。为实现这一点,它在查全率和性能之间进行了权衡,也就是说,在查全率上做一些微小的妥协,针对非常大的数据集大幅提升性能(与现有的向量相似度蛮力法相比)。
查询 DSL
全文本搜索要求一种强大的查询语言。Elasticsearch 提供一套基于 JSON 的完整查询 DSL(域特定语言),可用来定义查询。创建简单查询以匹配词汇和单元,或者开发复杂查询来将多个查询整合到一起。此外,在查询时可以应用筛选器,以便先移除文档再计算相关性分数。
Highlighter
通过 Highlighter(高亮显示工具),您能够从搜索结果的一个或多个字段中高亮显示内容片段,以便向用户展示查询匹配之处。当您请求高亮显示时,响应内容会包含每一条搜索匹配结果中的高亮元素,其中包括高亮字段和高亮片段。
自动补全 (auto-complete)
补全提示器可提供 auto-complete/search-as-you-type(自动完成/输入即搜索)功能。这项导航功能能够在用户输入时引导用户找到相关结果,从而提高搜索精准度。
提示器 (did-you-mean)
短语提示器通过在词语提示器的基础上构建更多逻辑,向搜索体验中加入 did-you-mean(您指的是 XXX 吗)功能,让用户能够选择改正后的整个短语,而不再是基于 ngram 语言模型计算权重后的单个分词。在实际应用中,此提示器就基于固定搭配和频率应该选择哪个分词,能够做出更好的决策。
Percolator
标准做法是通过查询来找到存储在索引中的文档,但是 Percolator(过滤器)却颠覆了这种做法,您可用其来将文档与索引中所存储的查询进行匹配。percolate 查询自身即包含文档,这些文档将会用作查询与所存储的查询进行匹配。
查询剖析器/优化器
剖析 API 可以提供搜索请求中有关单独组件执行情况的详细时间信息。它能够让您从详尽层面深入了解搜索请求的执行过程,以便您可以理解为何某些请求的处理速度慢,进而采取措施加以改进。
动态可更新同义词
通过使用 analyzer reload API,您可以触发操作以重新加载同义词的定义。将会重新加载已配置同义词文件的内容,并对筛选所用的同义词定义进行更新。_reload_search_analyzers API 可在一个或多个索引上运行,并且会触发操作以便从配置好的文件中重新加载同义词。
结果固定
提升选定文档的排名,使其高于与特定查询相匹配的文档。这一功能通常用来引导搜索用户找到您精心整理的文档,因为这些文档的排名已被提升至高于任何“搜索的有机匹配结果”。这些提升后的或“固定后”的文档通过存储在 _id 字段中的文档 ID 加以识别。
搜索和分析
分析
数据搜索只是个开始。借助 Elasticsearch 强大的分析功能,您能够更深入地挖掘所搜索的数据,找到其中所蕴含的洞见。无论要对结果进行聚合,想确定文档间的关系,还是希望基于阈值创建告警,所有这些都需要有强大的搜索功能做支撑。
聚合
聚合框架可以基于搜索查询帮助提供聚合后的数据。该框架的基础是称为聚合的简单构建基块,人们可以对这些构建基块进行编辑以生成有关数据的复杂汇总。可以将聚合看做一个工作单元,用来针对一组文档创建分析信息。
指标聚合
桶聚合
管道聚合
矩阵聚合
Geohexgrid 聚合
随机采样器聚合
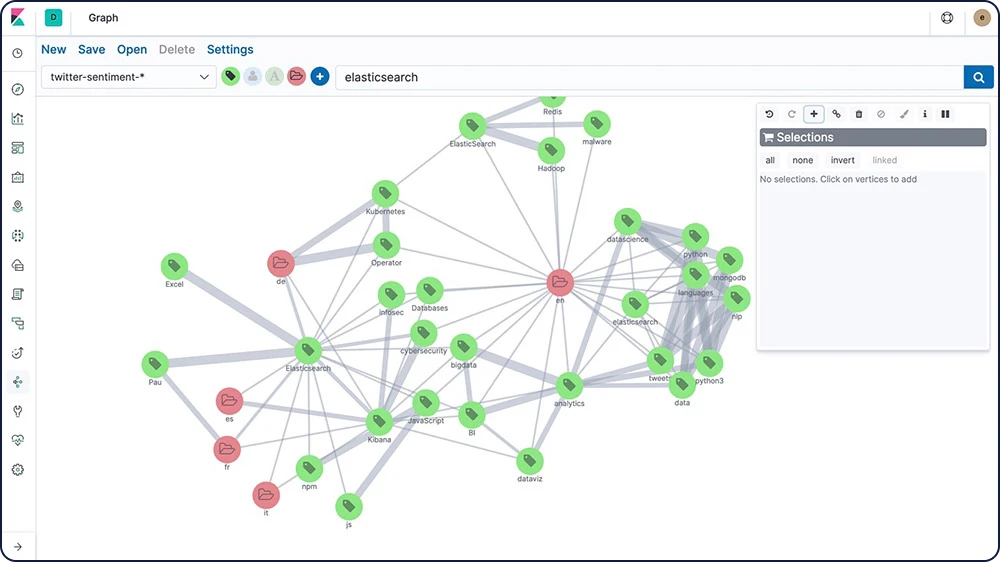
Graph 探索
通过 Graph 探索 API,您能够提取并汇总 Elasticsearch 索引中文档和词语的相关信息。了解此 API 行为的最好方法就是使用 Kibana 中的 Graph 来探索彼此间的联系。
搜索和分析
Machine Learning
Elastic Machine Learning 功能可以自动对 Elasticsearch 数据的行为(例如趋势、周期等等)进行实时建模,从而更快地发现问题,简化问题根源分析,降低误报率。
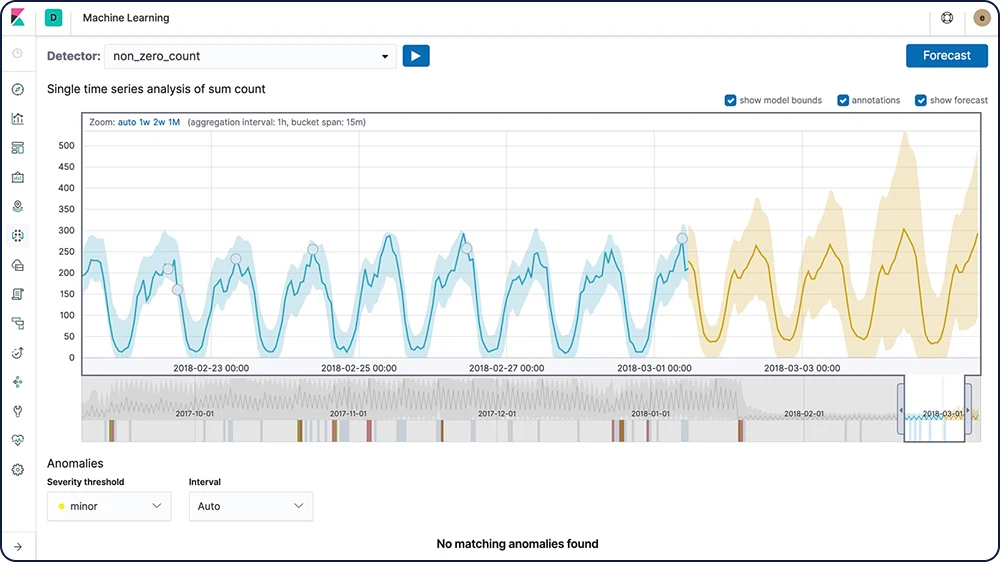
时序型预测
Elastic Machine Learning 针对您的数据的正常行为创建基线之后,您可以使用这些信息来推测未来行为。然后,即可创建一套预测方法,来估计未来特定日期的时序值,或者预估未来出现某个特定时序值的几率。
时序型数据异常监测
Elastic Machine Learning 功能通过为数据中的正常行为创建准确基线并且识别数据中的异常模式,可实现时序型数据分析的自动化。通过使用专有的 Machine Learning 算法,可以检测到异常情况,对其进行评分,并将其与数据中具有重大统计意义的影响因素联系在一起。
与临时偏离数值、计数或频率有关的异常情况
统计学意义上的罕见事件
群体中某一成员的异常行为
推理
通过推理,您不仅可以将监督型 Machine Learning 进程(例如回归或分类)用作批量分析,而且还可用于持续分析。通过推理,您可以针对入站数据应用已训练的 Machine Learning 模型。