.png)

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Hello from the Elastic DevRel team! In this newsletter, we cover jina-embeddings-v5-omni, the latest blogs and videos, and upcoming events.
What’s new?
Elastic acquired Jina AI in late 2025, and jina-embeddings-v5-omni is now available on the Elastic Inference Service in both small and nano variants. The model handles text, images, audio, and video in a single shared embedding space, so you can query across all media types with one index and one query.
One index for everything you can't search today
You know this situation: Something exists somewhere, like a PDF attachment, a meeting recording, or one of 120 files all named “weekly stakeholder presentation”, but your search engine can only work with text and can’t find it.
Today, building multimodal search means accepting one of two compromises. The first is using a separate embedding model and index per modality, then somehow ranking and merging results at query time. The second is a single large multimodal model, but those tend to run to seven billion parameters or more, are slow and expensive, and the frontier ones are closed-weight, so you cannot run them locally or inspect what is inside.
jina-embeddings-v5-omni takes a different path: a compact model family that maps all four modalities into the same vector space, so a text query can directly retrieve a relevant video frame, audio clip, or scanned document with no cross-index merging needed.
Cross-modal search in practice

To demonstrate video search, the Elastic team took the 1961 Breakfast at Tiffany's trailer (158 seconds), split it into 28 scenes using pyscenedetect, and embedded each scene with jina-embeddings-v5-omni-small into a single Elasticsearch index. Querying with the word "cat" returned the cat scene as the top result. Querying "kiss" returned only kiss scenes. All from plain text with no video-specific pipeline.
The same principle extends across every modality:
Audio → image: Speaking "meow" into the model produces an embedding that retrieves cat images from the dataset since both audio and images share the same vector space
Image → document: Uploading a photo of an invoice finds matching invoices in a document collection without any OCR or text extraction step
Multimodal query: A sketch of a car combined with the text "white" retrieves images of white cars with both modalities folded into a single query vector
Text → music genre: A text description of a genre returns matching audio clips — useful for cataloguing media libraries
On the Charades-STA benchmark for moment retrieval inside video, v5-omni-small scores 55.57. ByteDance's Seed 1.6, a closed-weight model, scores 29.3. The paper notes that moment retrieval (finding the right segment inside a longer video) is where the omni model particularly shines.
Benchmarks: Best open-weight model under 5B parameters
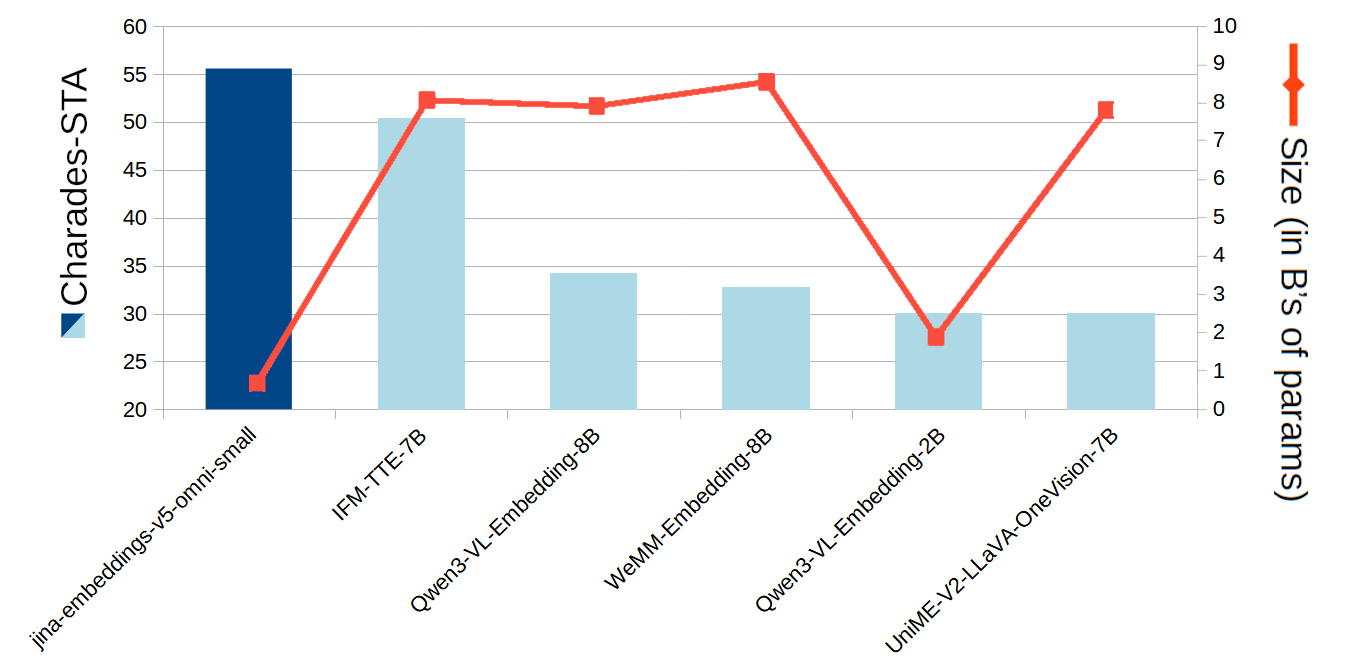
The v5-omni-small was tested across four standard benchmarks: MMTEB for text, MIEB for images, MMEB for video, and MAEB for audio. Its average score across all four is 53.93 — the highest of any open-weight model under five billion parameters.
On visual document retrieval (ViDoRe benchmark), v5-omni-small, using under one billion active parameters, scores better than a leading three billion parameter model and close to one that is seven billion parameters that is nearly eight times its size. For text-only queries, it inherits the full jina-embeddings-v5-text baseline, which already leads its size class on MMTEB, making it the strongest text performer of any comparable omni model.
Elasticsearch integration: Backwards-compatible and storage-efficient
Because the text backbone in v5-omni is completely unchanged from v5-text, the model produces bit-identical text embeddings. If you already have a text index built on jina-embeddings-v5-text, you can add images, audio, and video to it without rebuilding the index or re-embedding any existing documents.
v5-omni also inherits both of Elasticsearch's major storage optimizations:
Better Binary Quantization (BBQ): Binarizes vectors to achieve 93% storage reduction with less than 3% accuracy loss. See the BBQ documentation for configuration details.
Matryoshka representation learning: Embeddings can be truncated to as few as 32 dimensions. Truncation sensitivity varies by modality; video is more sensitive than text or images, so check the tradeoff charts before picking a dimension budget.
Truncating to 256 dimensions and applying binary quantization together cut the index footprint substantially while retaining most retrieval quality.
On the Elastic Inference Service, inference endpoints and Kibana connectors for both jina-embeddings-v5-omni-small and jina-embeddings-v5-omni-nano are created automatically with no manual configuration required. The Elastic documentation covers local deployment via Hugging Face as well. Both models are also available on the Jina API and Hugging Face (CC-BY-NC-4.0).
The full technical write-up, including architecture details and benchmark breakdowns, is on the Elasticsearch Labs blog and the GELATO paper on arXiv. The original video walkthrough is on YouTube.
Blogs, videos, and interesting links
Credits: Subscribe to Elastic Cloud via AWS Marketplace or Microsoft Marketplace to receive $1,000 in credits.
Persistent agent memory: Join Jeff Vestal as he explains how to provide AI agent persistent cross-session memory using Elasticsearch in Claude Code.
Vector search: Jeffrey Rengifo shares six vector search tips for building AI search applications on Elasticsearch.
OGX with Elasticsearch: Learn how to configure Elasticsearch as an OGX vector store, ingest PDFs, and build a Python RAG agent with Enrico Zimuel.
Network Topology: Explore the Network Topology plugin for Kibana with Connor Pierce, which provides a ready-to-deploy Logstash pipeline, a structured schema, and a topology view.
Streams: Edward Lewis showcases how to configure downsampling in Elastic Streams alongside retention and tiers with a live preview and validation.
Security: Jamie Hynds and Mia LaVada explain how Elastic Security ingests Google Threat Intelligence. Monitor Claude activity in Elastic Security with Jamie Hynds and Sumana Mannem.
Check out these videos:
Your AI coding agent got dumber and you didn't notice by JP Hwang
Search algorithms explained in 12 levels (BM25, vectors, RAG & more) by Jon Avezbaki
Elasticsearch's new default embedding model: Explained by JD Armada
Featured blogs from the community:
TLS certificate monitoring made simple with Elastic Stack by Raihan Iqbal
Implementing a virtual filesystem over Elasticsearch by Leonie Monigatti
Upcoming events
Learn Elastic at no cost: Explore self-paced modules to build your Elastic skills.
Find Elastic at these upcoming conferences:
San Francisco, CA, USA: AI Engineer World’s Fair — June 29–July 2 (booth + workshop)
Bengaluru, India: AWS Community Day — July 11 (booth + talk)
London, UK: Typescript AI Conference — July 23 (talk)
Berkeley, CA, USA: Agentic AI Summit — August 1–2 (booth)
Join your local Elastic User Group chapter for the latest news on upcoming events! You can also find us on meetup.com. If you’re interested in presenting at a meetup, send an email to meetups@elastic.co.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all. In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use. Elastic, Elasticsearch, and associated marks are trademarks, logos or registered trademarks of elasticsearch B.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print