Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
Stop guessing if your vector search benchmark results are accurate. Jingra is an open source, configuration driven framework that removes hidden warmup assumptions, inconsistent datasets, and vague definitions of when an index is actually ready to query. It runs the same dataset, workload, parameter sweeps, and reporting pipeline across Elasticsearch, OpenSearch, and Qdrant, producing reproducible recall versus latency curves you can rerun, compare, and trust.
How Jingra benchmarks vector search engines: three phases
Jingra organizes benchmarking into three phases: Load, Eval, and Analyze. The point of this structure is simple: Every engine should be measured against the same dataset, workload, and reporting pipeline, under conditions you can control and reproduce.
| Phase | What it does |
|---|---|
| Load | Ingests data; waits for index readiness |
| Eval | Runs warmup and measurement; supports param sweeps |
| Analyze | Produces recall curves, latency plots and CSVs |
1. Load: Establishing a known state
The Load phase ingests the dataset into the engine under test using configurable parallelism. More importantly, it lets you decide what "ready" means before evaluation begins. In practice, finishing ingestion doesn’t always mean the system has reached a stable state. Elasticsearch may still be merging segments in the background, and Qdrant has its own post-ingest optimization behavior. Those background tasks can materially affect query latency.
Jingra makes that choice explicit with the await_index_ready setting. If enabled, evaluation waits until the index reaches the state you intend to measure instead of assuming that document ingestion alone is enough.
Example load configuration:
2. Eval: Capturing true performance trade-offs
The Eval phase runs the query workload in two steps: warmup and measurement. In the warmup step, Jingra executes the configured queries a fixed number of times before collecting any reported results. It doesn’t clear caches or reset engine state between warmup and measurement. The measurement step simply begins after those warmup iterations complete.
This makes the benchmark behavior explicit: Jingra is measuring post-warmup, steady-state performance for the configured workload rather than cold-start latency. Keeping warmup separate from measurement reduces first-run effects without introducing extra coordination logic between the two steps.
Jingra also supports parameter sweeps, so instead of reporting a single benchmark point, you can generate recall versus latency curves across multiple settings in one run.
Example parameter sweep for recall versus latency:
Figure 1: Asymptotic recall versus latency plot that approaches a limit; higher num_candidates and k will get us closer to the limit at the cost of time.
3. Analyze: Structured reporting
After evaluation completes, Jingra's Analyze phase produces recall curves, latency plots and structured CSVs for further analysis. Results can be written to different sinks, including console output for quick iteration or an Elasticsearch index for longer-term storage and dashboarding.
Configuration-driven vector search benchmarking
Jingra is driven by YAML configuration rather than hard-coded benchmark logic. This makes benchmark definitions easy to commit and reuse, while keeping connection credentials in environment variables.
Switching between supported engines is straightforward. For example, you can swap engine: qdrant for engine: elasticsearch and point Jingra at a different cluster.
How does Jingra ensure benchmark results are accurate and reproducible?
A focus on deterministic, credible results led to several core design choices:
- No fixed sleeps for coordination. Jingra uses synchronization primitives and readiness checks instead of arbitrary delays, which makes benchmark execution more deterministic.
- Real engines in integration tests. The test suite uses Testcontainers to run Elasticsearch, OpenSearch, and Qdrant directly rather than relying on mocks.
- Defaults that reflect realistic operation. Jingra doesn’t assume an artificially idealized index state unless you explicitly ask for one.
- Strict quality gates. The project enforces full instruction and branch coverage with JaCoCo on every build.
Jingra is built in Java because Java is a good fit for this kind of infrastructure software: It has mature concurrency primitives, strong testing tools, and a well-understood runtime model. It’s also the language I know best, which made it easier to focus on the benchmarking methodology rather than on the implementation details.
How do I run a vector search benchmark with Jingra?
To get started quickly, the Jingra GitHub repository provides a set of end-to-end demos covering common benchmarking scenarios. These demos spin up an engine, download a public dataset, index it, and run the evaluation using Docker Compose, so no preexisting cluster is needed.
Prerequisites:
- Java 21
- Maven
- Docker
make
The quickest way to try it is running one of the end-to-end demos:
For custom scenarios, clone the repo, build the image, and run it directly against your own configuration:
The demo produces structured output that Jingra can turn into recall, latency, and throughput plots. The example below is illustrative only: It uses a very small dataset and a deliberately exaggerated workload so the demo generates visible curves quickly. These numbers are useful for showing the reporting flow, but they shouldn’t be interpreted as representative of production performance.
| RecallAtN | Engine | ParamKey | Recall | Recall Rounded | Latency_Avg | Latency_P95 | Throughput | Speedup |
|---|---|---|---|---|---|---|---|---|
| recall@10 | elasticsearch | k=10_num_candidates=10_oversample=1_size=10 | 0.9948 | 0.99 | 0.9602 | 1.1642 | 907.8117 | |
| recall@10 | elasticsearch | k=20_num_candidates=20_oversample=1_size=10 | 0.9973 | 1 | 1.0704 | 1.5249 | 818.5483 | |
| recall@10 | elasticsearch | k=50_num_candidates=50_oversample=1_size=10 | 0.9988 | 1 | 1.1183 | 1.4607 | 787.7582 | |
| recall@10 | elasticsearch | k=100_num_candidates=100_oversample=1_size=10 | 0.9993 | 1 | 1.1017 | 1.3583 | 802.9065 | |
| recall@10 | elasticsearch | k=200_num_candidates=200_oversample=1_size=10 | 0.9995 | 1 | 1.2505 | 1.5671 | 713.8778 | |
| recall@10 | elasticsearch | k=500_num_candidates=500_oversample=1_size=10 | 0.9995 | 1 | 1.4175 | 1.7896 | 636.0211 | |
| recall@10 | elasticsearch | k=1000_num_candidates=1000_oversample=1_size=10 | 0.9995 | 1 | 1.7012 | 2.0929 | 58.7924 |
From this output, Jingra can generate plots, such as:
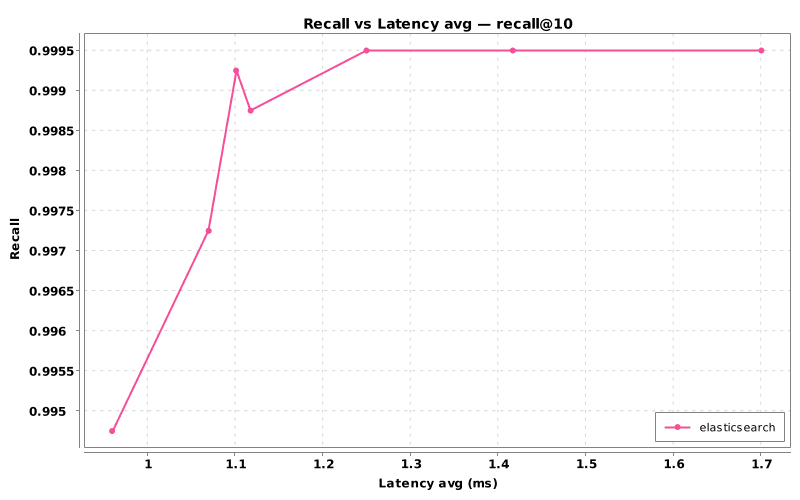
Figure 2: Recall versus latency curve, showing how higher search effort improves recall while increasing latency.
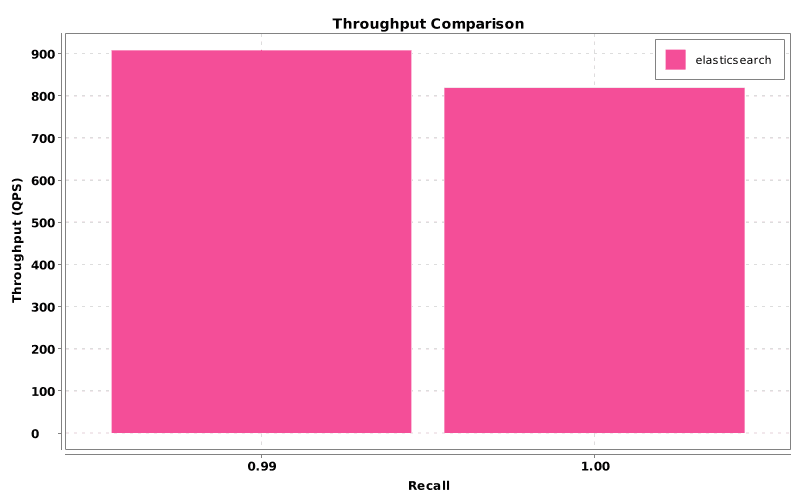
Figure 3: Throughput plot, showing the cost of those same parameter changes in queries per second.
In this demo, the workload is intentionally configured with 100 warmup rounds and 100 measurement rounds. That isn’t meant to model production traffic. It’s simply a convenient way to make the trade-off curves visible with a tiny dataset that would otherwise complete too quickly.
For production benchmarking, you should use larger datasets, realistic concurrency, and query volumes that reflect your actual workload. The purpose of this demo is to illustrate the benchmarking workflow and output format, not to establish performance baselines.
These demos currently focus on one engine at a time. A future release will include demos for engine versus engine comparisons, as well as profile versus profile comparisons within a single engine.
Conclusion: run your own vector search benchmark
If you want to compare vector search engines on your own data, Jingra gives you a repeatable way to do it without building the whole harness yourself. Try one of the demos, run it against your workload, and compare engines under the same conditions.
The project is open source, licensed under Apache 2.0, and available on GitHub.
Frequently asked questions
What is Jingra and what does it benchmark?
Jingra is an open source framework for running reproducible vector search benchmarks across Elasticsearch, OpenSearch and Qdrant. It uses the same dataset, workload and reporting pipeline for every engine, making cross-engine comparisons consistent and trustworthy. It is licensed under Apache 2.0 and available on GitHub.
Why do vector search benchmark results vary across different published studies?
Most published benchmarks differ in hidden assumptions: when the index is considered ready, how many warmup queries are run, and whether background optimization tasks have completed. Jingra makes these choices explicit through configuration: await_index_ready, warmup rounds and measurement rounds are all defined in YAML and reproducible across runs.
How does Jingra handle post-ingest index optimization in Elasticsearch and Qdrant?
Both engines perform background work after document ingestion (Elasticsearch merges segments, Qdrant runs its own optimization) and these tasks can materially affect query latency. Jingra's await_index_ready setting holds the evaluation phase until the index reaches the intended measurement state, rather than starting queries immediately after the last document is indexed.
How do I generate a recall versus latency curve with Jingra?
Jingra supports parameter sweeps: you define multiple num_candidates and k settings in the param_groups block, and a single run evaluates all of them. The Analyze phase then produces a recall-versus-latency curve showing how higher search effort improves recall at the cost of increased latency.
Can I run a Jingra benchmark without an existing cluster?
Yes. The demos in the Jingra GitHub repository use Docker Compose to spin up an engine, download a public dataset, index it and run the full benchmark with a single make command. No pre-existing Elasticsearch, OpenSearch or Qdrant cluster is needed.
What engines does Jingra support?
Jingra currently supports Elasticsearch, OpenSearch and Qdrant. Additional engines are planned. Engine-versus-engine comparison demos are also planned for a future release.
Is Jingra suitable for production benchmarking?
Jingra is designed for production-grade studies, but the included demos use small datasets and exaggerated workloads to generate visible curves quickly. For meaningful production comparisons, use larger datasets, realistic concurrency, and query volumes that reflect your actual workload.
Related Content

July 28, 2026
17% faster search, zero config: auto-calibrating vector quantization in Elasticsearch
Automatic calibration at merge time picks vector quantization parameters for each segment by predicting recall from a small sample. Here's how we built it into Elasticsearch's merge path.

July 16, 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

July 13, 2026
The disk that never woke up: what actually decided our Qdrant vector search benchmark rematch
On the same hardware, Elasticsearch and Qdrant land in the same range at 56 QPS. The io_uring disk scorer and memory claims turned out to be the two things that mattered least.

July 21, 2026
4 NVIDIA AI tasks, 1 Elasticsearch API: Embeddings, chat, completion, and rerank
Set up NVIDIA hosted models in Elasticsearch with one API key and a model ID. No custom integration code needed.

July 10, 2026
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.