Sem estado: seu novo estado de localização com o Elasticsearch
Desenvolvimento da arquitetura do Elasticsearch para simplificar a implantação



Compartilhar no Twitter


Compartilhar no LinkedIn


Compartilhar no Facebook


Compartilhar por e-mail


Imprimir
Como tudo começou
A primeira versão do Elasticsearch foi lançada em 2010 como um mecanismo de busca distribuído e escalável que permitia aos usuários buscar rapidamente insights críticos e colocá-los em evidência. Depois de doze anos e mais de 65 mil commits, o Elasticsearch continua a oferecer aos usuários soluções testadas em ambientes de produção para uma ampla variedade de problemas de busca. Graças aos esforços de mais de 1500 colaboradores, incluindo centenas de funcionários da Elastic em regime integral, o Elasticsearch cresceu continuamente para atender às novas demandas de busca do mercado.
Logo quando o Elasticsearch surgiu, quando começaram a aparecer as preocupações com perda de dados, a equipe da Elastic iniciou um projeto de vários anos para reescrever o sistema de coordenação de cluster e assim garantir que os dados reconhecidos fossem armazenados em segurança. Quando ficou claro que gerenciar índices em grandes clusters era uma dor de cabeça, a equipe trabalhou na implementação de uma solução do ILM extensa, com o objetivo de automatizar esse trabalho, permitindo que os usuários definissem previamente os padrões de indexação e ações de ciclo de vida. À medida que os usuários foram sentindo a necessidade de armazenar volumes significativos de dados de série temporal e de métricas, foram incluídos diversos recursos, como por exemplo métodos de compressão melhores, para reduzir o tamanho dos dados. Com o aumento do custo de armazenamento da busca de volumes extensos de dados cold, investimos na criação de snapshots buscáveis como uma maneira de buscar dados de usuário diretamente nos armazenamentos de objetos com baixo custo.
Esses investimentos servem como base para a próxima evolução do Elasticsearch. Os serviços nativos da nuvem e os novos sistemas de orquestração cresceram, então percebemos que tinha chegado a hora de aprimorar o Elasticsearch para uma melhor experiência nos sistemas nativos da nuvem. Acreditamos que essas mudanças geram oportunidades para aprimoramentos de operações, desempenho e custos ao trabalhar com o Elasticsearch no Elastic Cloud.
Para onde estamos indo: o futuro não tem estado definido
Um dos principais desafios na operação ou na orquestração do Elasticsearch é a dependência dele de inúmeros tipos de estados persistentes, o que o classifica como um sistema de estados. Os três tipos mais importantes são o translog, o armazenamento de índices e os metadados de cluster. O estado indica que o armazenamento precisa ser persistente e não pode ser perdido durante a reinicialização ou a substituição de um nó.
A arquitetura do Elasticsearch vigente no Elastic Cloud precisa duplicar a indexação por todas as diversas zonas de disponibilidade para oferecer redundância no caso de interrupções. Queremos que a persistência desses dados migre dos discos locais para um armazenamento de objetos, como o AWS S3. A confiabilidade de serviços externos para o armazenamento desses dados eliminará a necessidade de indexar a replicação, o que elimina de forma significativa o hardware associado à ingestão. Essa arquitetura também oferece uma durabilidade muito alta como garantia, devido à maneira como os armazenamentos de objetos da nuvem, como AWS S3, GCP Cloud Storage e Azure Blob Storage, replicam os dados pelas zonas de disponibilidade.
A ação de descarregar o armazenamento de índice em um serviço externo também permitirá renovar a arquitetura do Elasticsearch, separando as responsabilidades de indexação e de busca. Em vez de ter as instâncias principais e de replicação lidando com as duas cargas de trabalho, pretendemos ter uma camada de indexação e outra de busca. Quando essas duas cargas de trabalho são separadas, elas conseguem ser redimensionadas de forma independente, e a seleção do hardware pode então ser mais direcionada aos casos de uso respectivos. Dessa forma, a dificuldade persistente de resolver o problema do impacto da carga das buscas e da indexação que ocorre uma na outra pode ser resolvida.
Depois de uma fase experimental e de prova de conceito de vários meses, tivemos a certeza de que esses serviços de armazenamento de objetos atendem aos requisitos que imaginamos para o armazenamento de índices e os metadados de cluster. Nossos testes e parâmetros de referência indicam que esses serviços de armazenamento têm capacidade para atender às necessidades de indexação dos clusters mais robustos já vistos no Elastic Cloud. Além disso, o backup dos dados no armazenamento de objetos reduz os custos de indexação e permite o ajuste simples do desempenho da busca. Para buscar dados, o Elasticsearch usará o modelo de snapshots buscáveis testados em ambientes de produção no qual os dados são mantidos persistentemente e de forma permanente no armazenamento de objeto nativo da nuvem e discos locais são usados como caches para os dados acessados com frequência.
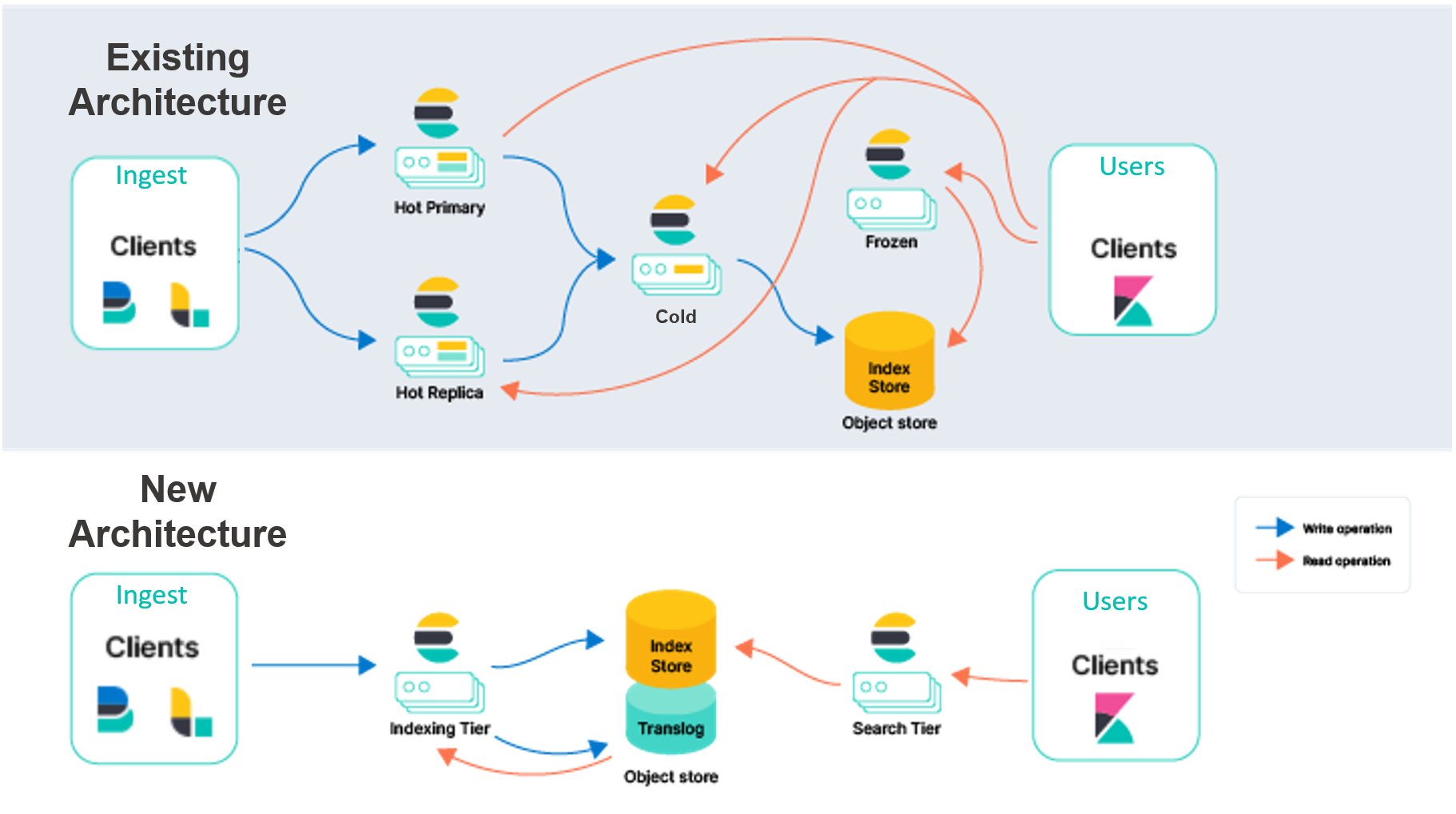
Para ajudar a diferenciar, descrevemos nosso modelo atual como replicação "nó a nó". Na camada hot desse modelo, os shards primários e de réplica realizam o mesmo trabalho pesado para lidar com as solicitações de busca de ingestão e atendimento. Esses nós têm "estados", uma vez que contam com seus discos locais para manter os dados para os shards que hospedam. Além disso, os shards primários e de réplica estão constantemente comunicando-se para manterem a sincronia. Eles fazem isso replicando as operações realizadas no shard primário para o shard de réplica, o que significa que o custo dessas operações (principalmente na CPU) é depositado em cada réplica especificada. Os mesmos shards e nós que realizam esse trabalho para a ingestão também atendem as solicitações de busca, portanto, a provisão e o redimensionamento precisam ser feitos com as duas cargas de trabalho em mente.
Além da busca e da ingestão, os shards do modelo de replicação nó a nó têm outras inúmeras responsabilidades, como a mesclagem de segmentos Lucene. Esse design tem seus méritos, e vimos muitas oportunidades com base no que aprendemos com os clientes ao longo dos anos e também a evolução do ecossistema da nuvem de forma mais ampla.
A nova arquitetura permite muitas melhorias imediatas e futuras, incluindo o seguinte:
- Você pode aumentar de maneira significativa a transferência de ingestão no mesmo hardware ou, considerando outro ponto de vista, aumentar incrivelmente a eficiência para a mesma carga de trabalho de ingestão. Esse aumento se origina da remoção da duplicação das operações de indexação para cada réplica. As operações de indexação que consomem intensivamente a CPU só precisam acontecer uma vez na camada de indexação, que então envia os segmentos resultantes para um armazenamento de objeto. De lá, os dados ficam prontos para serem consumidos, da forma que se encontram, pela camada de busca.
- Você pode separar a computação do armazenamento para simplificar sua topologia de cluster. Hoje, o Elasticsearch tem várias camadas de dados (conteúdo, hot, cold e frozen) para combinar os dados com o perfil de hardware. A camada hot serve para busca em tempo real; já a frozen é melhor para dados buscados com menos frequência. Apesar de oferecer valor, essas camadas aumentam a complexidade. Na nova arquitetura, as camadas de dados não serão mais necessárias, o que simplificará a configuração e a operação do Elasticsearch. Também estamos separando a indexação da busca, para reduzir ainda mais a complexidade e permitir o redimensionamento de ambas as cargas de trabalho de forma independente.
- Você pode ter custos de armazenamento melhorados na camada de indexação reduzindo o volume de dados que precisam ser armazenados no disco local. Atualmente, o Elasticsearch precisa armazenar uma cópia integral do shard nos nós hot (primário e de réplica) para fins de indexação. Com a abordagem sem estado de indexar diretamente para o armazenamento de objeto, apenas uma porção daqueles dados locais é necessária. Nos casos de uso para anexação somente, apenas determinados metadados terão que ser armazenados para a indexação. Isso reduzirá de significativamente o armazenamento local necessário para a indexação.
- Você pode reduzir os custos de armazenamento associados às consultas de busca. Ao tornar o modelo de snapshots buscáveis o modo nativo de busca de dados, você reduz incrivelmente o custo de armazenamento associado às consultas de busca. Dependendo das necessidades de latência de busca dos usuários, o Elasticsearch permitirá ajustes para aumentar o cache local nos dados requisitados com mais frequência.
Comparativo de referência: melhoria de 75% no throughput de indexação
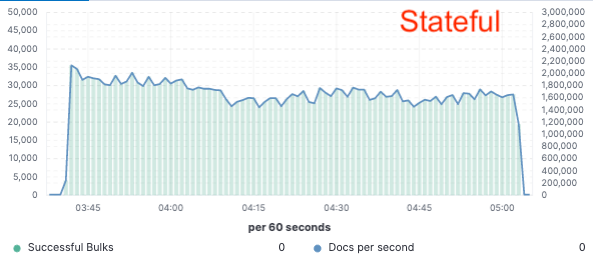
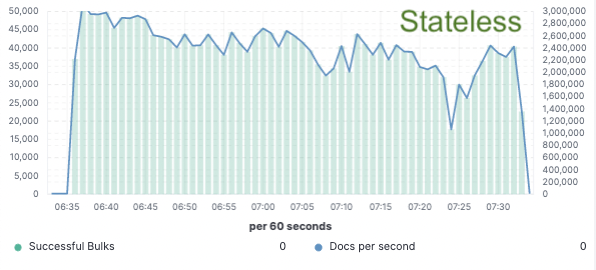
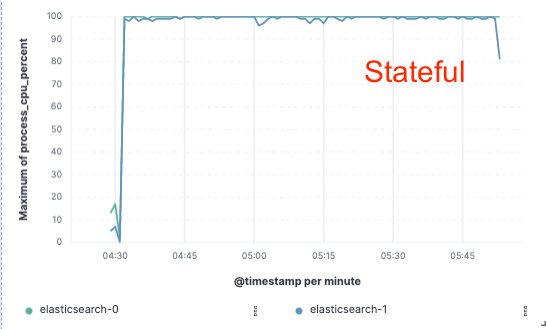
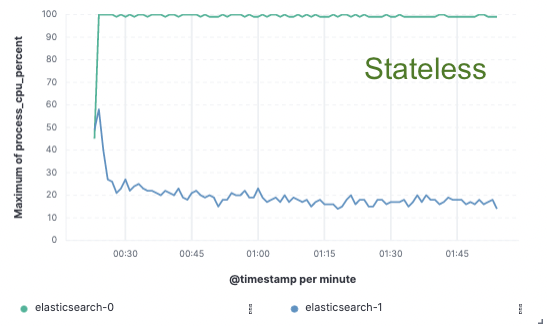
Com o objetivo de validar esse método, implementamos uma prova de conceito extensa na qual os dados foram indexados apenas em um único nó e a replicação foi conseguida por meio de armazenamentos de objeto na nuvem. Percebemos que uma melhoria de 75% no throughput de indexação poderia ser conseguida com a remoção da necessidade de dedicar hardware à replicação de indexação. Além disso, o custo de CPU associado à simples ação de inserir dados do armazenamento de objeto era muito menor do que o de indexar os dados e os gravar localmente, o que hoje é necessário na camada hot. Isso significa que os nós de busca poderão dedicar sua CPU integralmente à busca.
Esses testes de desempenho foram realizados em um cluster de dois nós em comparação com todos os três principais provedores de serviços em nuvem (AWS, GCP e Azure). Pretendemos continuar a gerar parâmetros de referência maiores em nossa busca por uma implementação de produção sem estado.
Throughput de indexação
Uso da CPU
Sem estado para nós, mais economia para você
A arquitetura sem estado no Elastic Cloud permitirá reduzir as despesas gerais com indexação, redimensionar de forma independente a ingestão e a busca, simplificar o gerenciamento de camada de dados e acelerar as operações, como redimensionamento ou atualização. Este é o primeiro marco na jornada em direção à modernização substancial da plataforma do Elastic Cloud.
Torne-se parte de nossa visão sem estado
Tem interesse em experimentar essa solução antes de todo mundo? Participe das discussões ou venha para nosso canal da comunidade Elastic no Slack. Vamos adorar receber o seu feedback para encontrarmos a direção ideal para nossa nova arquitetura.
Compartilhar
Compartilhar no Twitter
Compartilhar no LinkedIn
Compartilhar no Facebook
Compartilhar por e-mail
Imprimir

