BUSCA OPEN SOURCE, ANALÍTICA E PLATAFORMA DE IA
Elasticsearch
O Elasticsearch é um mecanismo de busca e análise distribuído e de código aberto, desenvolvido para velocidade, escala e aplicações de IA. Na forma de uma plataforma de recuperação, ele armazena dados estruturados, não estruturados e vetoriais em tempo real, fornecendo busca híbrida e vetorial rápida, melhorando a observabilidade e a análise de segurança, além de permitir aplicações orientadas por IA com alto desempenho, precisão e relevância.
O que torna o Elasticsearch uma potência em busca, analítica e IA?
Isso ocorre porque o Elasticsearch é um ...


Recursos poderosos. Surpreendentemente simples.

Desempenho de busca extremamente rápido
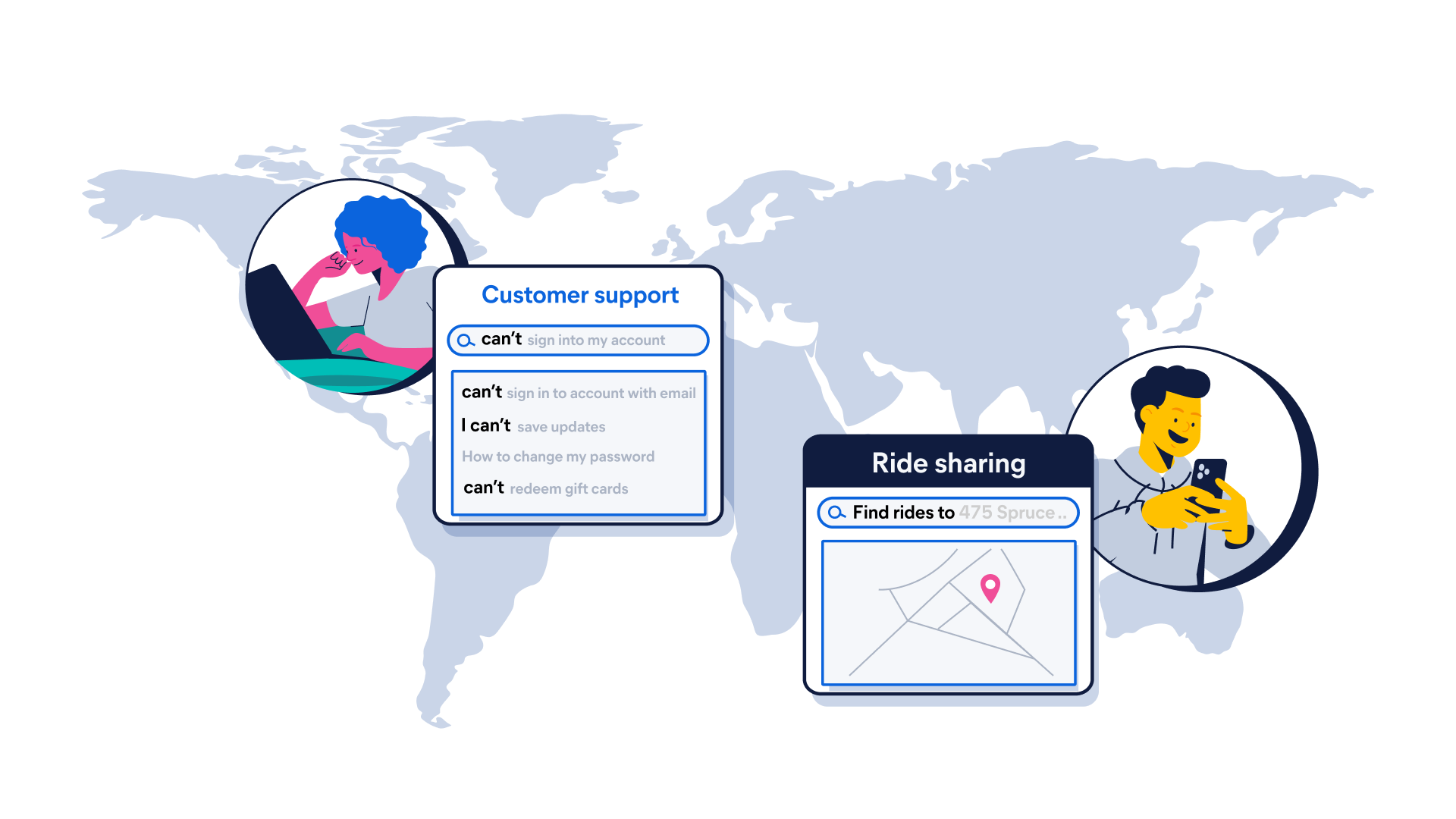
Crie aplicações de buscaBusca com latência de milissegundos, alimentada pelo Lucene. Respostas instantâneas, não importa a velocidade com que os dados se movem.
Escalabilidade distribuída global
Escale sem esforço. O Elasticsearch redimensiona automaticamente, reequilibra, replica e melhora o processamento de petabytes, sem tempo de inatividade e sem drama. Precisa de alcance global? A busca entre clusters oferece busca federada sem complicações.
Dados versáteis e flexibilidade de casos de uso
Texto? Registros de data e hora? Vetores? Sim. Uma plataforma para fazer de tudo. De buscas à observabilidade e segurança, o Elasticsearch é criado uma vez e reutilizado em todos os lugares. Desenvolvido para tudo o mais que seus dados possam imaginar.
De bare metal a arquiteturas sem servidor. É você quem decide.
De um notebook a um cluster de 100 nós, o Elasticsearch funciona da mesma forma em todos os lugares. No local, na nuvem ou entre nuvens. Nós estaremos lá.
Elastic Cloud Serverless
Faça menos com serverless
Operações sem complicações com uma oferta sem servidor totalmente gerenciada, a maneira mais fácil de aumentar a busca, a observabilidade e a segurança.
Elastic Cloud Hosted
Implante o Elasticsearch e o Kibana hospedados na AWS, no Google Cloud e no Azure
Inicie uma implantação totalmente carregada no provedor de serviços em nuvem de sua escolha. Como somos a empresa por trás do Elasticsearch, oferecemos os nossos recursos e suporte para os seus clusters da Elastic na nuvem.
No local
Baixar Elasticsearch
Obtenha uma instalação novinha e comece a executar o Elasticsearch no computador em apenas algumas etapas.
Crie com um rico ecossistema e integrações
Mais de 350 integrações, flexibilidade infinita. O Elasticsearch reúne seus dados onde quer que estejam, com APIs, clientes de linguagem e pipelines de ingestão que simplificam a conexão, o envio e a busca de qualquer lugar.









Programe com a linguagem que você já usa
Programe do seu jeito. Clientes para Java, Python, GO e muito mais, além de acesso à API nativa quando você quiser. Rápido, fácil, flexível e projetado para dar suporte a seus projetos no Elasticsearch.







Elasticsearch na prática
Confira o Elasticsearch Labs, o destino único para aprender a construir experiências de busca como GenAI, modelos de incorporação, recursos de reclassificação e muito mais.
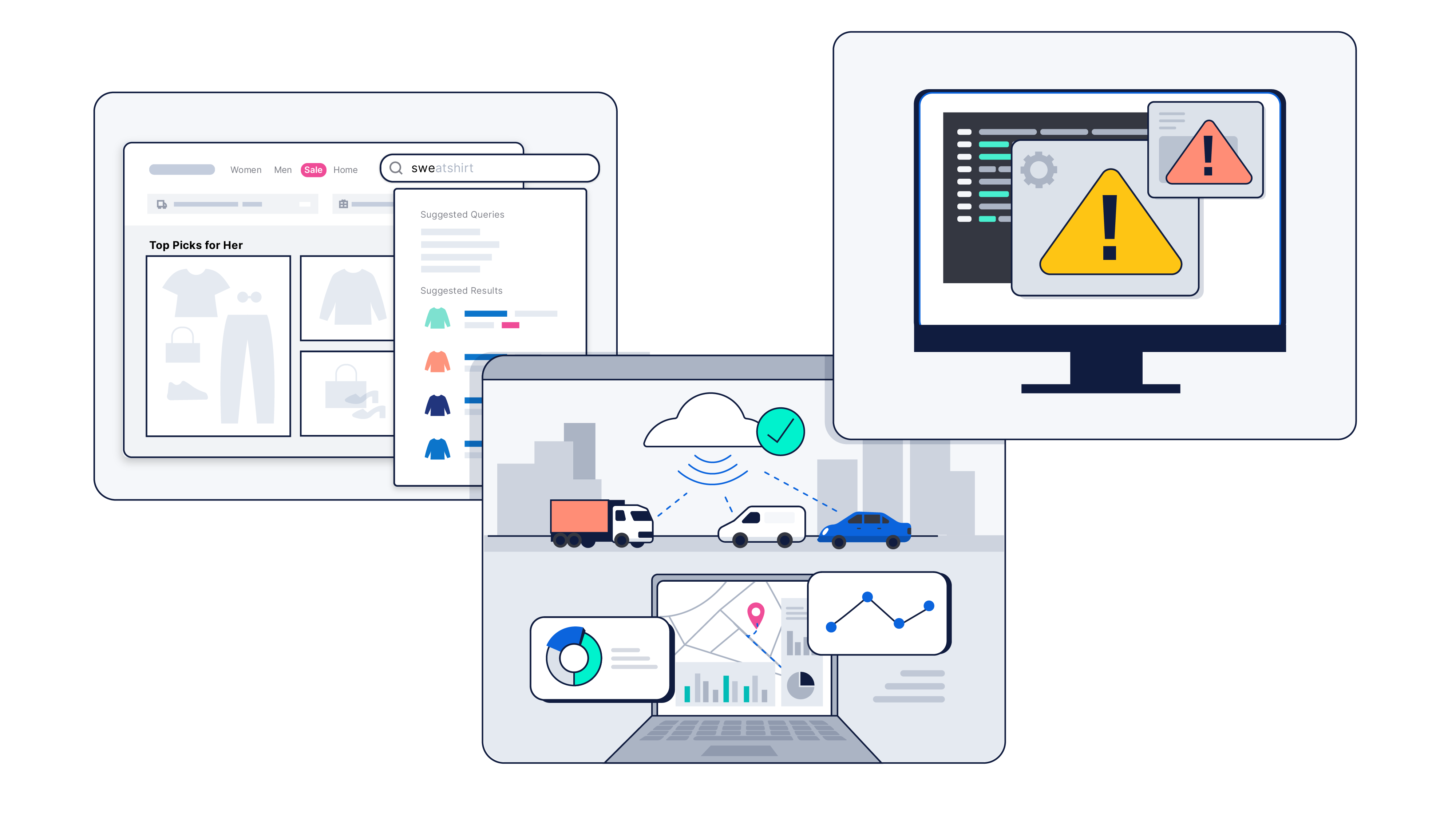
Armazene, analise e redimensione com segurança todos os tipos de dados — estruturados, não estruturados, séries temporais, logs, eventos, geoespaciais, vetores e mais. Não é necessário mover dados para um local central nem refatorar dados para que se encaixem.
POST /my-index/_doc/1 { "timestamp": "2025-02-19T14:30:00Z", "log_level": "ERROR", "message": "Unauthorized access attempt detected", "event_id": "abc123xyz", "user": { "id": "user_456", "username": "jdoe", "ip_address": "192.168.1.100" }, "geo": { "lat": 39.7392, "lon": -104.9903, "city": "Denver", "region": "Colorado", "country": "US" }, "http": { "method": "POST", "url": "/admin/login", "status_code": 401, "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" }, "security": { "alert_type": "Failed Login", "severity": "high", "action_taken": "Blocked IP", "detection_engine": "SIEM" }, "server": { "hostname": "webserver-01", "environment": "production" } } }
POST /my-index/_doc/1
{ "timestamp": "2025-02-19T14:30:00Z", "log_level": "ERROR", "message": "Unauthorized access attempt detected", "event_id": "abc123xyz", "user": { "id": "user_456", "username": "jdoe", "ip_address": "192.168.1.100" }, "geo": { "lat": 39.7392, "lon": -104.9903, "city": "Denver", "region": "Colorado", "country": "US" }, "http": { "method": "POST", "url": "/admin/login", "status_code": 401, "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" }, "security": { "alert_type": "Failed Login", "severity": "high", "action_taken": "Blocked IP", "detection_engine": "SIEM" }, "server": { "hostname": "webserver-01", "environment": "production" } } }
Texto? Registros de data e hora? Vetores? Sim.
O Elasticsearch potencializa a busca, a observabilidade e a segurança, tudo em uma plataforma. Crie uma vez, reutilize em todos os lugares. Com APIs flexíveis para busca de IA, recuperação de vetores e muito mais, ele oferece resultados rápidos em qualquer escala.
Desenvolvido para criadores
Desenvolvedores como você estão melhorando a próxima geração de aplicativos de IA de pesquisa que redimensionam em qualquer lugar com a Elastic.
Cliente em destaque

Chat Leap usa a Elastic para melhorar campanhas globais que alcançam milhões de clientes para tudo, de vendas da Black Friday até eventos esportivos globais.
Cliente em destaque

A Brolly otimizou todo o gerenciamento de incidentes com o Elastic Observability.
Cliente em destaque

O Lawrence Livermore National Laboratory maximiza a disponibilidade do sistema HPC para pesquisas científicas e de segurança nacional inovadoras com o Elastic Security.
Junte-se à comunidade
Explore o que outros desenvolvedores estão fazendo com o Elasticsearch, faça perguntas e receba ajuda quando tiver dificuldades.

Mergulhe nos fóruns da Elastic. Discuta, aprenda, ensine, solucione problemas e explore com a comunidade global.

Converse sobre o trabalho, compartilhe vitórias de busca e interaja com colegas em seu encontro local da comunidade Elastic.

Relaxe do jeito certo. Junte-se ao canal da Elastic no Slack e fique conectado com outros ninjas da busca.