Kibana 7.6.0 released
We are thrilled to introduce Kibana 7.6! With this release, we’re rolling out a host of new formatting capabilities for Elastic Maps, the ability to embed a map within a Canvas workpad, and our first steps towards supporting nested fields in both filters and search. 7.6 also brings an exciting announcement on the machine learning front — the ability to use a trained model for inference at the point of data ingest. Still craving more Kibana goodness? How about a 35x speedup when sorting on times, dates, and numbers (this, thanks to a huge 7.6 improvement from Elasticsearch)!
Excited already? Try 7.6 right now by deploying Elasticsearch and Kibana on Elastic Cloud — the only hosted Elasticsearch offering to include these new features — or simply take it for a test drive on your laptop by downloading the latest versions of Kibana and the Elastic Stack.
For a full list of bug fixes and other changes, be sure to look at the Kibana 7.6 release notes.
Machine learning inference
In the ongoing Elastic goal to make machine learning approachable enough for anyone in a company to use, we’re excited to announce the release of inference, the ability to apply a pre-trained model to new data at ingest time. Inference builds on supervised learning features such as classification, regression, and outlier detection, which were all launched in earlier 7.x releases.
For Kibana and Elasticsearch users this means end-to-end supervised machine learning is now a native part of the overall Elastic Stack. No new toolkit to learn or external library integration to navigate — simply focus on using machine learning to solve your use cases without worrying about operational complexities. For example, you can use the included language identification model in the inference ingest processor to make sure incoming documents are labeled with the correct language. Maybe it is using the classification capabilities that come natively in the Elastic Stack to build a bot detection model and then using that same model for inferring and labeling bot activity on incoming traffic. From observability to security to enterprise search — the possibilities are countless for how our end-to-end machine learning capabilities can now help you quickly solve problems.
Elastic Maps
We’ve been hard at work continuing to add features that you can use to deepen your geospatial analysis. With Kibana 7.6, we’ve got fun stuff to share.
Categorical styling
Want to color the data points on your map based on the discrete values in a categorical field? Say you have data with flights from cities across Europe and want every airport within the same country to have the same color. With categorical styling you can do all of that quickly using a single layer. Choose the custom colors you want or let Elastic Maps take care of that for you with a default palette.
Text labels
We are excited to introduce the ability to add and customize labels within the layer style panel. Provide your viewers with more information about the data you’re overlaying on your maps and even format the label size and color to fit your analysis. For example, if you were using the new geographic functions in Elastic machine learning to stream location anomalies of your input data and wanted to visualize (and label them) on your map — customizing the labels is now fast and easy.
Canvas
Embeddable maps
Canvas lets you create expressive, pixel-perfect reports backed by live data — making it a popular choice for management dashboards and highly visible large screen hallway displays. Location data is increasingly becoming a critical component within this kind of business reporting. Whether you’re looking at endpoint security threats, search metrics, or trying to gain a unified view of your logs, metrics, and APM traces — the need to incorporate a geospatial perspective is real. To support this effort we’re proud to rollout as part of the Kibana 7.6 release the ability to embed map elements directly into Canvas workpads.
Kibana Lens
In 7.5 we unveiled Kibana Lens, our bold step forward in making data visualization and exploration with the Elastic Stack easier and more intuitive. The response from the community has been amazing, and we are excited to bring more capabilities to Lens in 7.6.
Support for scripted fields
We’re pleased to announce the support for scripted fields for Kibana Lens in 7.6. Scripted fields are an ideal way to compute new fields on the fly directly from Kibana by transforming or combining existing fields, and using them in your visualizations like any other field in the index. For example, if your index contained a field for bytes, but you were interested in visualizing kilobytes, writing a simple scripted field to divide bytes by 1024 would quickly give you a new field in your index to do that. From that point on inside Kibana Lens you can simply drag and drop that scripted field like you would any other.
Reset layer
One of the really great things about Kibana Lens is the rapid pace at which you can iterate on an idea or investigate a hunch when working with your data. The power of drag and drop means your visualization can change as quickly as you can move your mouse. The ability to visualize data from multiple indices at the same time is another key part of the power of Lens, thanks to the way it creates editable data layers. With Kibana 7.6 we’re making that iterative flow even smoother by adding the ability inside of Lens to rapidly reset a layer with a single click instead of manually needing to remove data fields one at a time. Whether you are performing a comparative analysis using two index patterns and need to quickly start over, or simply want to pivot your approach against a single set of data, starting from a clean slate is now as easy as a single click of the mouse.
There are a few additional Kibana Lens features that we are rolling out as part of 7.6. This includes Lens automatically starting on the designated default index pattern within Kibana versus the previous behavior of it simply choosing the first one based on alphabetical sort. Also, the ability to drag a field into the break down by area of the layer pane and then specify how top values are chosen now supports numbers as well as strings.
We hope you enjoy these new Kibana Lens features. If you have ideas on what you would like us to tackle next with Lens please let us know via the Kibana product feedback form.
Nested field support
At Elastic, we love being able to deliver those features that are hard to crack, but oh so very useful. The ability to use nested fields as part of an analysis inside of Kibana is one of the most commented on issues in the Kibana repo and today we are pleased to introduce our first steps towards helping you accomplish that goal by introducing nested field support in the search bar and filters. We’ll also be expanding support for nested fields to other areas over the next several releases.
Looking at the below visual of a series of nested fields, the ability to search and filter these in 7.6 means you'll be able to query for a user whose first name is Tom and whose last name is Hanks, or a user whose first name is Tom and last name is Smith.
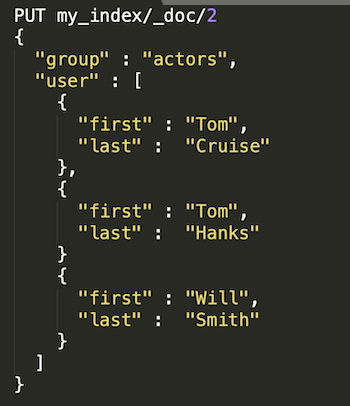
It’s no accident that searching and filtering nested datatypes is such an anticipated capability within Kibana. We hear time and time again from customers about the need to analyze, search and visualize data living in a nested relationship. We also hear the lengths they go to in trying to achieve these outcomes. From relational database approaches resulting in complex data structures with multiple dimensions that are cumbersome at best, to siloed niche solutions that require upkeep and continuous integration efforts. For all of these reasons we’re extremely excited to start offering an easier, out-of-the-box solution with Kibana 7.6 for dealing with nested fields in a way that keeps you in your existing Kibana workflows.
Elasticsearch performance increase = faster visualizations
You might remember that Elasticsearch got an incredibly powerful performance boost as part of the 7.0 launch with the affectionately termed “Magic WAND.” This improvement focused on the ability for Elasticsearch to skip text results (hits) identified early on as not being highly ranked (non-competitive). In 7.6 that same power is now also pointed at 64-bit integers (the “long” data type) meaning that sorting dates and numbers is in some cases 35 times faster. Kibana users will experience this benefit in many ways, especially when building time series analysis and drilling down within visualizations using dates.
Ready to try Kibana 7.6?
Jump right in and start testing out these great new features and improvements for yourself. Spin up an Elasticsearch cluster on Elastic Cloud or download Elasticsearch today (both come with Kibana). And be sure to let us know what you think on Twitter (@elastic) or in our forum. You can report any problems on the GitHub issues page.