Do sonho à realidade: anunciamos a ES|QL, a linguagem de consulta com barras verticais da Elastic


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Hoje temos a satisfação de anunciar a prévia técnica da nova linguagem de consulta com barras verticais da Elastic®, a ES|QL (Elasticsearch Query Language), que transforma, enriquece e simplifica as investigações de dados. Alimentada por um novo mecanismo de consulta, a ES|QL oferece recursos avançados de busca com processamento simultâneo, melhorando a velocidade e a eficiência, independentemente da fonte e da estrutura dos dados. Resolva problemas rapidamente criando agregações e visualizações em uma única tela para ter um fluxo de trabalho iterativo e suave.

Evolução no Elasticsearch
Nos últimos 13 anos, o Elasticsearch® evoluiu significativamente, adaptando-se às necessidades dos usuários e ao cenário digital em constante mudança. Originalmente para busca de texto completo, o Elasticsearch se expandiu para oferecer suporte a um conjunto mais amplo de casos de uso com base no feedback do usuário. Ao longo dessa jornada, a Query DSL do Elasticsearch, nossa primeira linguagem de busca adotada, forneceu um conjunto avançado de consultas para filtros, agregações e outras operações. Essa DSL baseada em JSON acabou se tornando a base do nosso endpoint de API _search.
Ao longo dos anos e com a diversificação das necessidades, ficou evidente que os usuários queriam mais do que a Query DSL oferecia. Começamos a adotar e incorporar DSLs adicionais em nossa Query DSL para scripts ou para eventos em investigações de segurança e muito mais. No entanto, por mais versáteis que fossem, essas adições não atendiam inteiramente alguns dos requisitos de nossos usuários.
Os usuários queriam uma linguagem de consulta que pudesse:
- Simplificar as investigações de ameaças e segurança enquanto observa e resolve problemas de produção por meio de uma única consulta que oferece uma abordagem abrangente e iterativa
- Otimizar as investigações de dados buscando, enriquecendo, agregando e visualizando, além de muito mais, tudo em uma única interface
- Usar recursos de busca avançados, como pesquisas com processamento simultâneo, melhorando a velocidade e a eficiência para consultar grandes quantidades de dados, independentemente da fonte e da estrutura
Do sonho à realidade: apresentamos a ES|QL
Nós ouvimos e temos a satisfação de apresentar a Elasticsearch Query Language (ES|QL), nossa nova e inovadora linguagem de consulta com barras verticais — um método e uma linguagem unificados para interagir com os dados no Elasticsearch e, ao mesmo tempo, eliminar a custosa necessidade de transferi-los para sistemas externos para processamento especializado. Ao contrário de outras linguagens que a Elastic adotou ao longo dos anos, como a Query DSL, a ES|QL foi projetada e desenvolvida desde o início para simplificar imensamente as investigações de dados e ser acessível para iniciantes, mas também poderosa para especialistas.
Exemplo de comando da ES|QL:
from logstash-*
| stats avg_bytes = avg(bytes) by geo.src
| eval avg_bytes_kb = round(avg_bytes/1024, 2)
| enrich geo-data on geo.src with country, continent
| keep avg_bytes_kb, geo.src, country, continent
| limit 4Exemplo de saída da ES|QL:
| avg_bytes_kb | geo.src | país | continente |
| 8.84 | BD | Bangladesh | Ásia |
| 6.92 | BR | Brasil | Américas |
| 2.75 | CI | Costa do Marfim | África |
| 4.55 | CL | Chile | Américas |
Simplicidade otimizada: uma UI personalizada para fluxos de trabalho aprimorados e iterativos
Para você poder ligar os pontos de um ataque em andamento ou navegar por dados de observabilidade, é necessário filtrar, buscar, transformar e agregar uma quantidade extraordinária de dados. A ES|QL oferece essa funcionalidade a partir de uma única consulta.
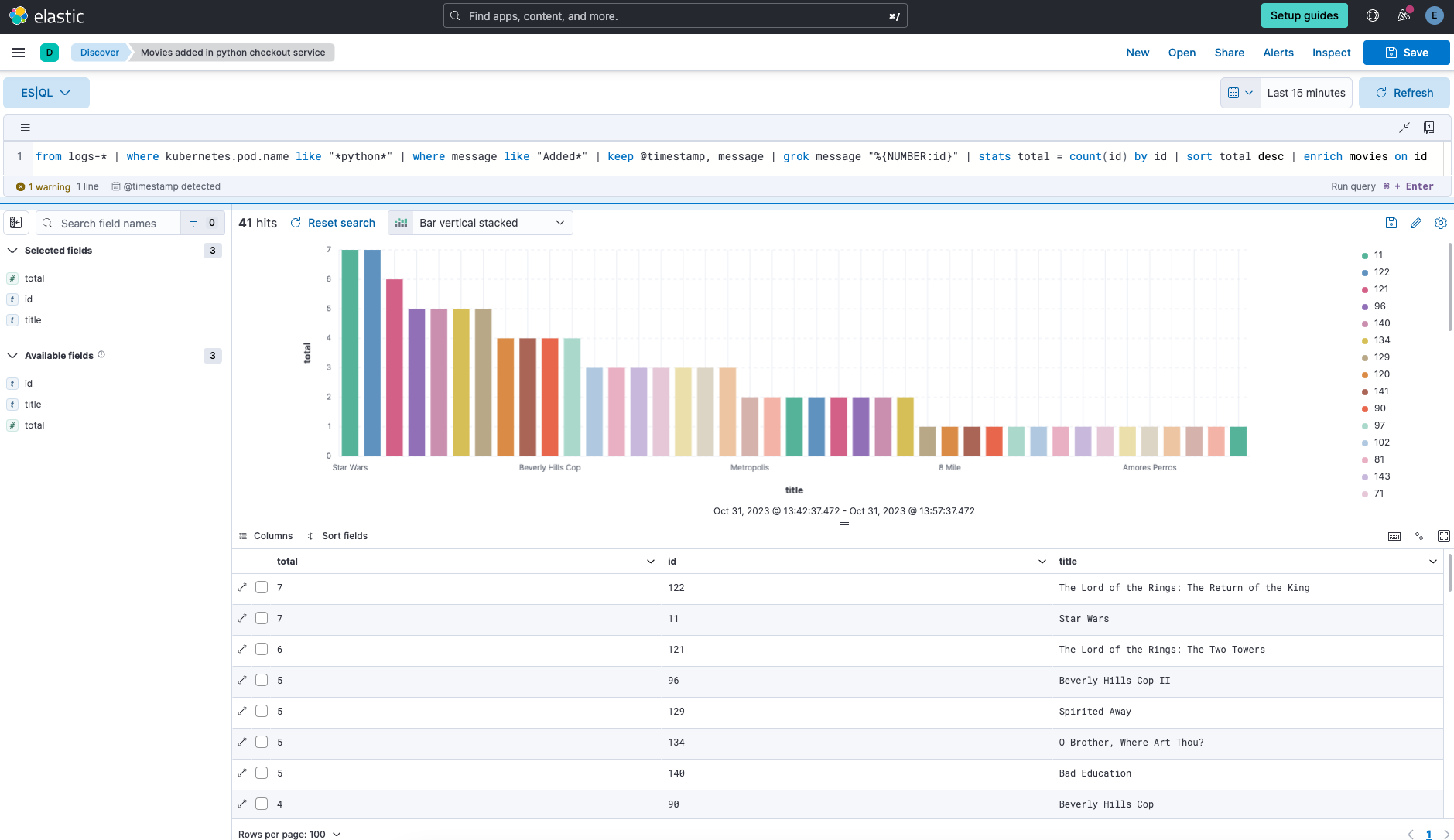
Mudar de contexto ou tentar encontrar o que você procura em muitas telas pode ser um atraso de vida, além de causar frustração. A partir de uma exibição unificada, a ES|QL fornece sintaxe de preenchimento automático, integra a documentação do produto e visualiza os resultados da busca, garantindo um fluxo de trabalho ininterrupto e eficiente para consultas de dados. Seja para segurança, observabilidade ou busca, a ES|QL aumenta a eficiência, a velocidade e a profundidade da exploração dos dados.
Simultaneidade da ES|QL — dois threads são melhores que um
Alimentada por um mecanismo de consulta robusto, a ES|QL oferece recursos de busca avançados com processamento simultâneo, permitindo que os usuários consultem facilmente diversas fontes e estruturas de dados.
Não há tradução ou transpilações para a Query DSL; em vez disso, cada consulta na ES|QL é inicialmente dividida, interpretada quanto ao seu significado, validada quanto à precisão e, em seguida, aprimorada para melhor desempenho. Em seguida, um processo é definido para executar a consulta em vários nós do cluster. Os nós de destino lidam com a consulta, fazendo ajustes imediatos no plano de execução usando o framework fornecido pela ES|QL. O resultado são consultas extremamente rápidas que você obtém imediatamente. Por exemplo, veja os benchmarks noturnos para comparação.
A inovação da plataforma impulsiona os benefícios das soluções da Elastic
Todas as soluções da Elastic — Search, Observability e Security — se beneficiam dos recursos e inovações fornecidos no Elasticsearch e no Kibana®. A ES|QL muda fundamentalmente a experiência de uso dessas soluções e fornece um fluxo de trabalho de investigação de dados simples, mas poderoso.
A ES|QL aprimora o Elastic Security
A ES|QL muda fundamentalmente a forma como os analistas perseguem as ameaças e fortalece a detecção. Desenvolvida em resposta às ricas contribuições da comunidade, ela libera o poder das consultas com barras verticais na velocidade do Elasticsearch, aprimorando os recursos de SIEM, segurança de endpoint e segurança na nuvem do Elastic Security.
- Pesquise de forma rápida e iterativa. Seguir a trilha de uma ameaça emergente requer uma ação rápida e uma linguagem que forneça um fluxo de trabalho iterativo.
- Enriqueça os resultados com contexto. A ES|QL permite que os analistas correlacionem endereços IP suspeitos com bancos de dados de inteligência de ameaças conhecidas, fornecendo clareza imediata sobre possíveis ameaças.
- Transforme os dados. A ES|QL possibilita que os usuários manipulem seus dados definindo novos campos ou analisando dados não normalizados, garantindo a clareza e a relevância dos dados.
- Agregue os dados. Os resultados podem ser consolidados e agregados, abrindo caminho para análises mais profundas e extração de insights.
A Elastic é a única plataforma de busca que combina a eficiência de uma arquitetura de esquema na gravação com a experiência de busca iterativa de uma linguagem de consulta com barras verticais de esquema na leitura. Com busca incrivelmente rápida e resultados de consulta à vista, os analistas podem chegar mais perto de seu alvo a cada barra vertical sucessiva.
A ES|QL também aprimora o poderoso mecanismo de detecção do Elastic Security. Para reduzir a fadiga dos alarmes, melhorar a relevância dos alertas e fornecer outro caminho para a detecção comportamental, as organizações podem incorporar valores agregados nas regras de detecção. Com a avaliação inline, os profissionais podem desenvolver e aprimorar iterativamente regras baseadas em ES|QL. As consultas são formatadas em texto simples, simplificando a colaboração e oferecendo suporte à detecção como código.
A ES|QL impacta o Elastic Observability
Os SREs que usam o Elastic Observability podem aproveitar a ES|QL para analisar logs, métricas, traces e dados de criação de perfil, permitindo identificar gargalos de desempenho e problemas do sistema com uma única consulta. Os SREs obtêm as seguintes vantagens ao gerenciar dados de alta dimensionalidade e alta cardinalidade com a ES|QL no Elastic Observability:
- Remover ruído de sinal. Com os alertas da ES|QL, melhore a precisão da detecção concentrando-se em tendências significativas em vez de incidentes individuais, minimizando alarmes falsos e fornecendo notificações práticas. Os SREs podem gerenciar esses alertas por meio da API da Elastic e integrá-los aos processos de DevOps.
- Análise aprimorada com insights. A ES|QL pode processar diversos dados de observabilidade, incluindo aplicações, infraestrutura, dados de negócios e muito mais, independentemente da fonte e da estrutura. A ES|QL pode facilmente enriquecer os dados com campos e contexto adicionais, permitindo a criação de visualizações para dashboards ou análise de problemas com uma única consulta.
- Redução no tempo médio até a resolução. A ES|QL, quando combinado com o AIOps e o AI Assistant do Elastic Observability, aumenta a precisão da detecção identificando tendências, isolando incidentes e reduzindo falsos positivos. Essa melhoria no contexto facilita a rápida identificação e resolução de problemas.
A ES|QL no Elastic Observability não apenas melhora a capacidade de um SRE de gerenciar a experiência do cliente, a receita de uma organização e SLOs de forma mais eficaz, mas também facilita a colaboração com desenvolvedores e DevOps, fornecendo dados agregados contextualizados.
A ES|QL promove avanços no Elastic Search
Com a ES|QL, você pode recuperar, agregar, calcular e transformar dados em uma única consulta. Ela conta com recursos importantes, como a capacidade de definir campos no momento da consulta, realizar pesquisas de enriquecimento de dados e processar consultas simultaneamente. Entenda e explore seus dados com a ES|QL de diversas maneiras. Desde a utilização de clientes para integração direta de API/código até a visualização de resultados diretamente em uma única tela, a ES|QL agiliza suas investigações de dados, garantindo que você aproveite ao máximo seus conjuntos de dados com facilidade e simplicidade.
O foco do design da ES|QL é evidente em sua capacidade de reduzir a complexidade do código, resultando em economia de tempo e custos. Ao facilitar a reutilização dos resultados da consulta em buscas subsequentes, a ES|QL minimiza a sobrecarga computacional, eliminando a necessidade de scripts complicados e consultas redundantes. A ES|QL não é apenas uma API, mas uma maneira simples e poderosa de transformar sua abordagem para a busca.
Embarque na sua jornada com a ES|QL
O futuro da exploração e manipulação de dados chegou. A Elastic convida analistas de segurança, SREs e desenvolvedores a experimentar essa linguagem transformadora em primeira mão e revelar novos horizontes em suas tarefas de dados. Saiba mais sobre as possibilidades da ES|QL ou inicie sua avaliação gratuita agora em prévia técnica.
O lançamento e o tempo de amadurecimento de todos os recursos ou funcionalidades descritos neste post permanecem a exclusivo critério da Elastic. Os recursos ou funcionalidades não disponíveis atualmente poderão não ser entregues dentro do prazo previsto ou nem chegar a ser entregues.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir