Elasticsearch 기능
Elasticsearch는 분산형 RESTful 검색 및 분석 엔진으로서, 모든 형태와 크기의 데이터를 검색, 색인, 분석할 수 있도록 데이터를 중앙 집중식으로 저장합니다.
관리 및 작업
관리 및 작업
확장성 및 복원력
Elasticsearch는 처음부터 끝까지 분산형으로 설계된 환경에서 가동되기 때문에 사용자가 오류를 염려할 필요가 없습니다. 저희 클러스터는 사용자의 필요에 따라 확장 가능하므로, 필요시 또 다른 노드를 추가하기만 하면 됩니다.
클러스터링 및 고가용성
클러스터는 하나 이상의 노드(서버)의 모음으로, 이것들이 합쳐져 함께 사용자의 데이터를 유지하고, 모든 노드에 걸쳐 연결된 색인 및 검색 기능을 제공합니다. Elasticsearch 클러스터는 기본 샤드와 복제 샤드가 기능하며 한 노드가 중지되는 경우 장애 조치를 제공합니다. 기본 샤드가 중지되면, 복제 샤드가 그 자리를 대신합니다.
클러스터링 및 고가용성에 대해 알아보기자동 노드 복구
의도적이든 그 밖에 다른 어떤 이유로든 노드가 클러스터를 떠나면, 마스터 노드는 복제 노드로 그 노드를 대체하고 샤드의 균형을 다시 조정함으로써 이에 대응합니다. 이러한 작업은 모든 샤드가 가능한 한 빨리 전체적으로 복제되도록 함으로써 데이터 손실로부터 클러스터를 보호하기 위한 것입니다.
노드 할당에 대해 알아보기자동 데이터 재조정
Elasticsearch 클러스터 내의 마스터 노드는 어느 샤드를 어느 노드에 할당할 지, 그리고 클러스터의 균형을 다시 맞추기 위해 언제 노드 간에 샤드를 이동할 지를 자동으로 결정하게 됩니다.
자동 데이터 리밸런싱에 대해 알아보기수평적 확장성
사용이 증가함에 따라, Elasticsearch도 함께 확장됩니다. 더 많은 데이터를 추가하고, 더 많은 사용 사례를 추가하세요. 리소스가 부족해지기 시작하면, 클러스터에 또 다른 노드를 추가하기만 하면 용량과 안정성을 늘릴 수 있습니다. 클러스터에 더 많은 노드를 추가할 때, 자동으로 복제 샤드를 할당하기 때문에 미래에 대비할 수 있습니다.
수평적 확장성에 대해 알아보기랙 구분
사용자 정의 노드 속성을 인식 속성으로 사용하여 샤드를 할당할 때 Elasticsearch가 사용자의 물리적 하드웨어 구성을 고려하도록 할 수 있습니다. 어느 노드가 동일한 물리적 서버에, 동일한 랙에, 또는 동일한 구역에 있는지 Elasticsearch가 아는 경우, 기본 샤드와 그 복제 샤드를 배포하여 장애가 발생하는 경우 모든 샤드 복사본을 잃게 되는 위험을 최소화할 수 있습니다.
할당 인식에 대해 알아보기클러스터 간 복제
클러스터 간 복제 기능(CCR) 기능은 원격 클러스터의 인덱스를 로컬 클러스터로 복제할 수 있게 합니다. 이 기능은 일반적인 사용 사례에서 사용할 수 있습니다.
CCR에 대해 알아보기재해 복구: 기본 클러스터에 장애가 생기면, 보조 클러스터가 hot 백업으로 기능할 수 있습니다.
지리 근접성: 읽기는 로컬에서 제공될 수 있으며, 네트워크 대기 시간을 줄입니다.
데이터 센터 간 복제
데이터 센터 간 복제 기능은 한동안 Elasticsearch의 중요 업무용 애플리케이션의 필수 요건이었으며 이전에는 추가 기술을 활용하여 부분적으로 해결되었습니다. Elasticsearch의 클러스터 간 복제 기능을 이용하면, 데이터 센터, 지역 또는 Elasticsearch 클러스터에서 데이터를 복제하기 위한 추가 기술이 필요하지 않습니다.
데이터 센터 간 복제에 대해 알아보기관리 및 작업
관리
Elasticsearch는 다양한 관리 도구 및 API와 함께 제공되어 데이터, 사용자, 클러스터 작업 등을 전체적으로 제어할 수 있게 해줍니다.
스냅샷에서 복구
클라우드 객체 스토리지를 사용하는 Elasticsearch 클러스터는 이제 ES 노드 간에 데이터를 전송하는 대신 ES 노드와 객체 스토리지에서 샤드 복제 및 샤드 복구와 같은 특정 데이터를 전송할 수 있으므로 데이터 전송 및 스토리지 비용이 절감됩니다.
스냅샷에서 복구에 대해 알아보기인덱스 수명 주기 관리
인덱스 수명 주기 관리(ILM)에서 사용자는 4단계의 단계별 인덱스 유지 기간 및 각 단계 동안 인덱스에 취해져야 하는 조처를 제어하는 정책을 정의하고 자동화할 수 있습니다. 이렇게 하면 작업 비용을 훨씬 더 잘 관리할 수 있으며, 데이터도 여러 다른 리소스 계층으로 분류해 넣을 수 있습니다.
ILM에 대해 알아보기Hot: 활동적으로 업데이트되고 쿼리됨
Warm: 더 이상 업데이트되지는 않지만 여전히 쿼리됨
Cold/Frozen: 더 이상 업데이트되지 않으며 아주 가끔씩만 쿼리됨(검색은 가능하지만 더 느림)
Delete: 더 이상 필요 없음
데이터 티어
데이터 티어는 노드에 대한 인덱스 수명 주기 관리 정책을 자동으로 정의하는 노드 역할 속성을 통해 데이터를 Hot, Warm, Cold 노드로 분할하는 공식화된 방법입니다. Hot, Warm, Cold 노드 역할을 할당하면 인사이트를 약화시키지 않고 더 높은 비용과 더 높은 성능의 스토리지에서 더 저렴한 비용과 보다 낮은 성능의 스토리지로 데이터를 이동하는 프로세스를 크게 단순화하고 자동화할 수 있습니다.
데이터 티어에 대해 알아보기- Hot: 가장 뛰어난 성능의 인스턴스에서 적극적으로 업데이트되고 쿼리됨
Warm: 보다 낮은 성능의 인스턴스에서 더 적은 빈도로 데이터가 쿼리됨
Cold: 읽기 전용, 거의 쿼리되지 않음, 검색 가능한 스냅샷을 통해 성능 저하 없이 스토리지 대폭 감소
스냅샷 수명 주기 관리
관리자는 백그라운드 스냅샷 관리자인 스냅샷 수명 주기 관리(SLM) API를 사용하여 Elasticsearch 클러스터의 스냅샷을 생성할 케이던스를 정의할 수 있습니다. SLM은 전용 UI를 통해 사용자가 SLM 보존 정책을 구성하고, 스냅샷을 자동으로 생성, 예약 및 삭제할 수 있도록 지원합니다. 이를 통해 고객 SLA를 준수하는 복구가 가능한 빈도로 해당 클러스터가 적절하게 백업됩니다.
SLM에 대해 알아보기스냅샷 및 복구
스냅샷은 Elasticsearch 클러스터 실행에서 얻어지는 백업입니다. 개별 인덱스나 전체 클러스터의 스냅샷을 찍어서 공유 파일 시스템의 리포지토리에 저장할 수 있습니다. 원격 리포지토리도 지원하는 플러그인이 제공됩니다.
스냅샷 및 복구에 대해 알아보기검색 가능한 스냅샷
검색 가능한 스냅샷을 사용하면 일반적인 스냅샷에서 스냅샷 복원을 완료하는 데 걸리는 시간을 단축하여 스냅샷을 직접 쿼리할 수 있습니다. 이 작업은 요청을 완료하기 위해 각 스냅샷 인덱스의 필요한 부분만 읽는 방식으로 이루어집니다. Cold 티어와 함께 검색 가능한 스냅샷은 Amazon S3, Azure Storage 또는 Google Cloud Storage와 같은 객체 기반 스토리지 시스템의 복제본 샤드를 백업하는 동시에 해당 시스템에 대한 전체 검색 액세스를 제공함으로써 데이터 스토리지 비용을 크게 절감할 수 있습니다.
검색 가능한 스냅샷에 대해 알아보기데이터 롤업
분석을 위해 과거 데이터를 유지하는 것은 극히 유용합니다. 그러나 막대한 양의 데이터를 보관하는 데 드는 경제적인 비용으로 인해 과거 데이터를 유지하지 못하는 경우가 자주 있습니다. 따라서 보존 기간은 방대한 과거 데이터의 유용성보다는 경제적인 현실에 따라 달라지게 됩니다. 롤업 기능은 과거 데이터를 요약하고 저장하는 수단을 제공함으로써, 원시 데이터 저장 비용의 극히 일부만으로도 분석을 위해 사용할 수 있게 해줍니다.
롤업에 대해 알아보기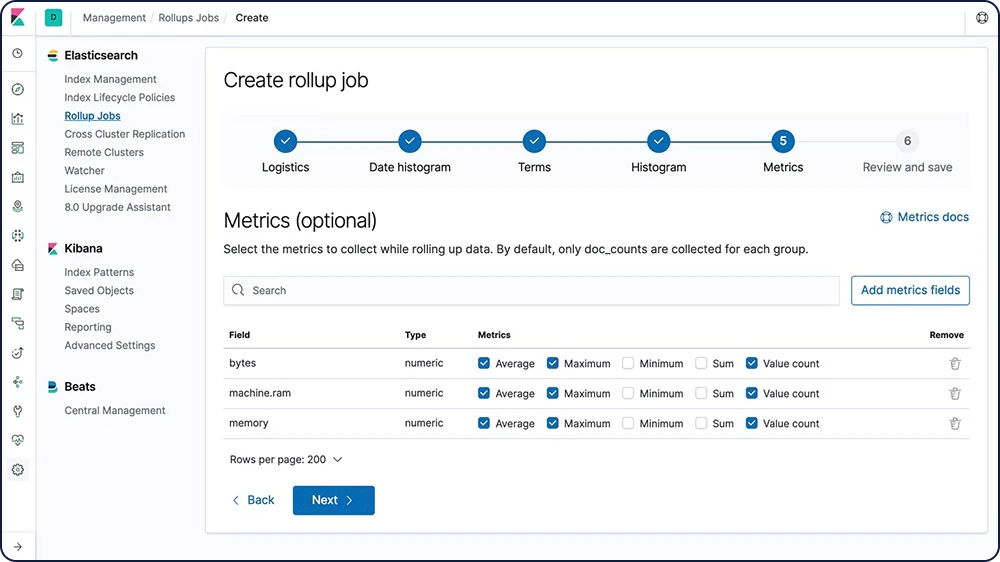
데이터 트랜스폼
데이터 트랜스폼은 2차원 표 형식 데이터 구조로서, 색인된 데이터를 좀 더 이해하기 쉽게 만들어줍니다. 데이터 트랜스폼은 데이터를 새로운 엔터티 중심의 인덱스로 피벗하는 집계를 수행합니다. 데이터를 변환하고 요약함으로써, 다른 머신 러닝 분석을 위한 소스로 활용하는 등 대안적인 방식으로 데이터를 시각화하고 분석할 수 있습니다.
데이터 트랜스폼에 대해 알아보기업그레이드 도우미 API
업그레이드 도우미 API는 사용자가 Elasticsearch 클러스터 업그레이드 상태를 확인하여, 이전의 메이저 버전에서 생성된 인덱스를 재색인할 수 있게 해줍니다. 도우미는 사용자가 Elasticsearch의 다음 번 메이저 버전에 대비할 수 있도록 도와줍니다.
업그레이드 도우미 API에 대해 알아보기API 키 관리
API 키 관리는 사용자가 자체 키를 관리하여 각 역할에 대한 액세스를 제한할 수 있을 정도로 유연해야 합니다. 전용 UI를 통해, 사용자는 API 키를 생성하고 이를 이용해 Elasticsearch와 상호 작용하는 동안 장기적인 자격증명을 제공할 수 있습니다. 이것은 자동화된 스크립트나 다른 소프트웨어와의 워크플로우 통합에서 흔히 있는 경우입니다.
API 키 관리에 대해 알아보기관리 및 작업
보안
Elastic Stack의 보안 기능은 적절한 사용자에게 적절한 액세스 권한을 부여합니다. IT, 운영, 애플리케이션 팀은 이 기능을 이용하여 선의의 사용자를 관리하고 악의적인 사용자를 감시할 수 있으며, 경영진과 고객은 Elastic Stack에 저장된 데이터가 안전하게 보호되고 있다는 사실을 알고 안심할 수 있습니다.
Elasticsearch 보안 설정
일부 설정은 민감하며, 그 값을 보호하기 위해 파일 시스템 사용 권한에만 의존하는 것은 충분하지 않습니다. 이러한 사용 사례의 경우, Elasticsearch는 민감한 클러스터 설정에 대한 원치 않는 액세스를 방지하지 위해 키 저장소를 제공합니다. 키 저장소는 한층 강화된 보안을 위해 원하는 경우 비밀번호로 보호할 수 있습니다.
보안 설정에 대해 알아보기암호화된 통신
SSL/TLS, 노드 인증 인증서 등을 사용한 트래픽 암호화를 통해 Elasticsearch 노드 데이터상의 네트워크 기반 공격을 막을 수 있습니다.
암호화된 통신에 대해 알아보기휴면 데이터 암호화 지원
Elastic Stack이 휴면 암호화를 기본으로 구현하지는 않지만, 모든 호스트 컴퓨터에서 디스크 수준의 암호화를 구성할 것을 권장합니다. 아울러, 스냅샷 대상 또한 데이터가 휴면 암호화되는지 확인해야 합니다.
역할 기반 액세스 제어(RBAC)
역할 기반 액세스 제어(RBAC)는 역할에 권한을 할당하고 사용자나 그룹에게 역할을 할당함으로써 사용자를 승인할 수 있게 해줍니다.
RBAC에 대해 알아보기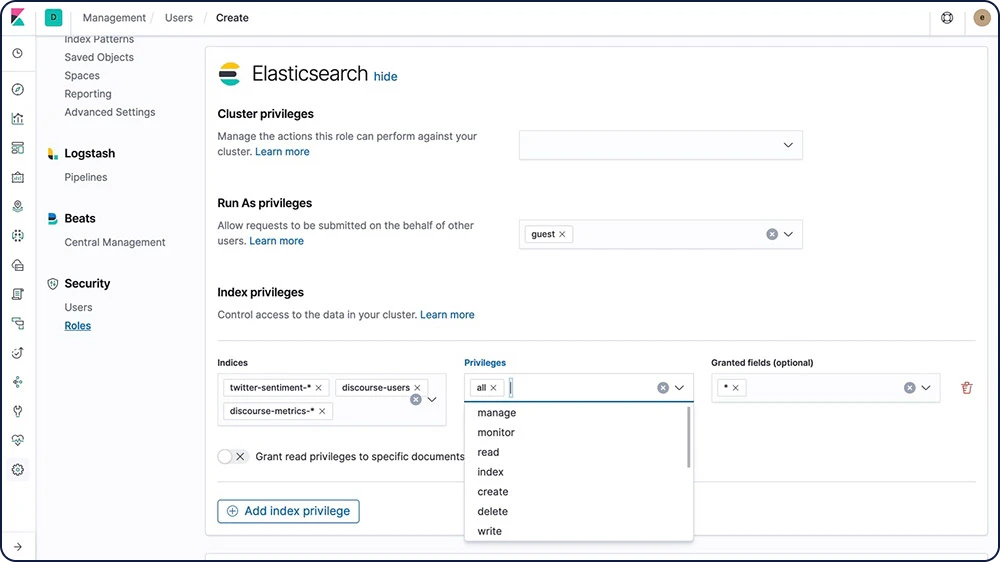
속성 기반 액세스 제어(ABAC)
Elastic Stack의 보안 기능은 또한 속성 기반 액세스 제어(ABAC) 메커니즘을 제공합니다. 이것은 사용자가 속성을 사용해 검색 쿼리와 집계에서 문서에 대한 접근을 제한할 수 있게 해줍니다. 이를 통해 역할 정의에서 액세스 정책을 구현하여, 사용자들이 모든 필요 속성을 갖는 경우에만 특정 문서를 읽을 수 있도록 할 수 있습니다.
ABAC에 대해 알아보기필드 및 도큐먼트 수준 보안
필드 수준 보안은 사용자가 읽기 액세스 권한을 갖는 필드를 제한합니다. 특히, 도큐먼트 기반 읽기 API에서 액세스할 수 있는 필드를 제한합니다.
필드 수준 보안에 대해 알아보기도큐먼트 수준 보안은 사용자가 읽기 액세스 권한을 갖는 도큐먼트를 제한합니다. 특히, 도큐먼트 기반 읽기 API에서 액세스할 수 있는 도큐먼트를 제한합니다.
도큐먼트 수준 보안에 대해 알아보기감사 로깅
감사를 활성화하여 인증 실패 및 접속 거부와 같은 보안 관련 이벤트를 추적할 수 있습니다. 이러한 이벤트를 로깅하면 사용자가 의심스러운 활동에 대해 클러스터를 모니터링할 수 있으며, 공격을 받을 경우 증거를 제공합니다.
감사 로깅에 대해 알아보기IP 필터링
IP 필터링을 클러스터에 합류하고자 하는 다른 노드에 더하여 애플리케이션 클라이언트, 노드 클라이언트, 또는 이동 클라이언트에 적용할 수 있습니다. 노드의 IP 주소가 블랙리스트에 있는 경우, Elasticsearch 보안 기능은 Elasticsearch로의 연결이 가능하도록 하지만 즉시 해제되며 아무 요청도 처리되지 않습니다.
IP 주소 또는 범위
xpack.security.transport.filter.allow: "192.168.0.1" xpack.security.transport.filter.deny: "192.168.0.0/24"
화이트리스트
xpack.security.transport.filter.allow: [ "192.168.0.1", "192.168.0.2", "192.168.0.3", "192.168.0.4" ] xpack.security.transport.filter.deny: _all
IPv6
xpack.security.transport.filter.allow: "2001:0db8:1234::/48" xpack.security.transport.filter.deny: "1234:0db8:85a3:0000:0000:8a2e:0370:7334"
호스트 이름
xpack.security.transport.filter.allow: localhost xpack.security.transport.filter.deny: '*.google.com'IP 필터링에 대해 알아보기
보안 영역
Elastic Stack의 보안 기능은 영역과 하나 이상의 토큰 기반 인증 서비스를 이용해 사용자를 인증합니다. 영역은 인증 토큰을 기반으로 사용자를 확인하고 인증하는 데 사용됩니다. 보안 기능은 수많은 기본 영역을 제공합니다.
보안 영역에 대해 알아보기싱글 사인온(SSO)
Elastic Stack은 Elasticsearch를 백엔드 서비스로 사용하여 Kibana에서 SAML 싱글 사인온(SSO)을 지원합니다. SAML 인증은 사용자가 Okta나 Auth0 같은 외부 ID 공급자를 이용해 Kibana에 로그인하게 해줍니다.
SSO에 대해 알아보기서드파티 보안 통합
Elastic Stack의 보안 기능으로 기본 지원되지 않는 인증 시스템을 사용하는 경우, 사용자를 인증하기 위해 사용자 정의 영역을 생성할 수 있습니다.
서드파티 보안에 대해 알아보기관리 및 작업
경보
Elastic Stack의 경보 기능은 Elasticsearch 쿼리 언어를 충분히 활용하여 관심 있는 데이터의 변경 사항을 식별할 수 있도록 지원합니다. 즉, Elasticsearch에서는 쿼리에 대한 경보를 받을 수 있습니다.
고가용성, 확장성 경보
크고 작은 조직들이 Elastic Stack을 믿고 필요한 경보들을 처리하는 데는 이유가 있습니다. 모든 소스에서 모든 형식의 데이터를 안정적으로 또 안전하게 수집함으로써, 분석가가 실시간으로 핵심 데이터를 검색, 분석, 시각화할 수 있습니다. 이 모든 것이 사용자 정의된 안정적인 경보 기능과 함께 제공됩니다.
경보에 대해 알아보기이메일, 웹훅, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, Slack, xMatters를 통한 알림
이메일, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, xMatters, Slack과 통합이 기본 제공되므로 간편하게 경보를 연결할 수 있습니다. 웹훅 출력을 통해 원하는 다른 타사 시스템과 통합할 수 있습니다.
경보 알림 옵션에 대해 알아보기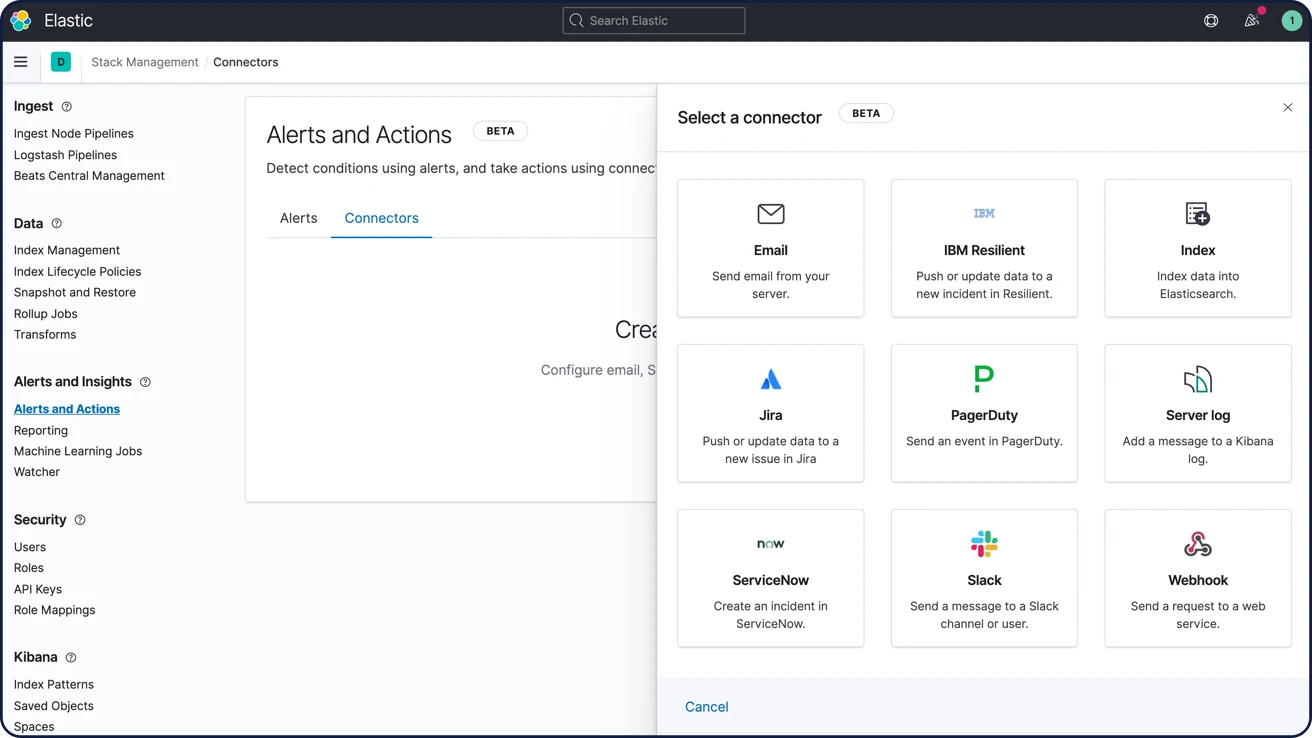
관리 및 작업
클라이언트
Elasticsearch는 사용자가 가장 편하게 생각하는 방식으로 데이터 작업을 할 수 있게 해줍니다. RESTful API, 언어 클라이언트, 강력한 DSL 등(심지어 SQL까지)을 이용한 유연함으로 사용자가 꼼짝 못하는 상황에 빠지지 않도록 지원해 드립니다.
언어 클라이언트
Elasticsearch는 표준 RESTful API와 JSON을 사용하며 자바, Python, .NET, SQL, PHP 같은 다양한 언어로 클라이언트를 구축하고 유지관리합니다. 또한 우리 커뮤니티는 훨씬 많은 것을 기여해 왔습니다. 이러한 클라이언트는 사용하기 간편하며 Elasticsearch처럼 사용자가 수행하는 작업에 제한이 없습니다.
사용 가능한 언어 클라이언트 탐색하기Elasticsearch DSL
Elasticsearch는 쿼리를 정의하기 위해 JSON에 기반한 전체 쿼리 DSL(도메인 특정 언어)를 제공합니다. 쿼리 DSL은 용어 및 구문 일치, 부분 일치, 와일드카드, 정규식, 네스트 쿼리, 위치 정보 쿼리 등 풀텍스트 검색을 위한 강력한 검색 옵션을 제공합니다.
Elasticsearch DSL에 대해 알아보기GET /kr/_search
{
"query": {
"match" : {
"message" : {
"query" : "this is a test",
"operator" : "and"
}
}
}
}
Elasticsearch SQL
Elasticsearch SQL은 SQL 같은 쿼리가 Elasticsearch에 대해 실시간으로 실행되도록 해주는 기능입니다. REST 인터페이스, 명령 줄 또는 JDBC, 어느 것을 사용하든, 모든 클라이언트는 Elasticsearch 내에서 기본적으로 SQL을 사용해 데이터를 검색하고 집계할 수 있습니다.
Elasticsearch SQL에 대해 알아보기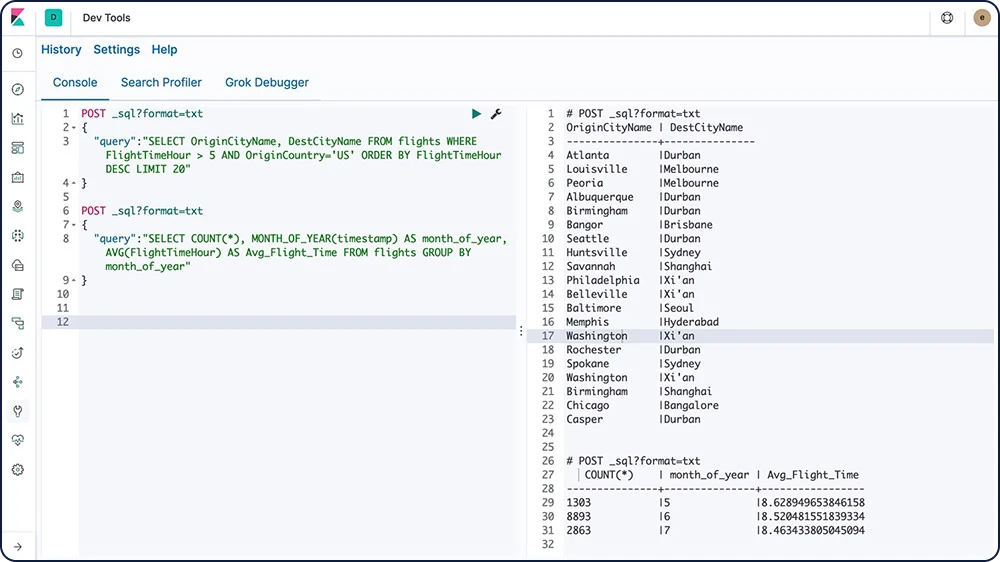
Event Query Language(EQL)
특정 조건과 일치하는 이벤트 시퀀스를 쿼리할 수 있는 기능을 갖춘 Event Query Language(EQL)는 보안 분석과 같은 사용 사례를 위해 특별히 구축되었습니다.
EQL에 대해 알아보기JDBC 클라이언트
Elasticsearch SQL JDBC 드라이버는 Elasticsearch를 위한 모든 기능이 갖추어진 풍부한 JDBC 드라이버입니다. Type 4 드라이버인데, 이 말은 JDBC 호출을 Elasticsearch SQL로 변환하는, 플랫폼과는 독립적으로 데이터베이스에 직접 작용하는 순수한 독립형 자바 드라이버라는 뜻입니다.
JDBC 클라이언트에 대해 알아보기ODBC 클라이언트
Elasticsearch SQL ODBC 드라이버는 Elasticsearch를 위한 모든 기능이 갖추어진 풍부한 3.80 ODBC 드라이버입니다. 핵심 레벨의 드라이버로서, Elasticsearch SQL ODBC API를 통해 접근 할 수 있는 모든기능을 노출시키며, ODBC 호출을 Elasticsearch SQL로 변환합니다.
ODBC 클라이언트에 대해 알아보기Elasticsearch용 Tableau 커넥터
Elasticsearch용 Tableau 커넥터를 사용하면 Tableau Desktop 및 Tableau Server 사용자가 Elasticsearch의 데이터에 손쉽게 액세스할 수 있습니다.
Tableau 커넥터 다운로드관리 및 작업
REST API
Elasticsearch는 사용자가 클러스터와 상호작용하는 데 사용할 수 있는 종합적이고 강력한 REST API를 제공합니다.
검색 API
Elasticsearch 검색 API는 사용자가 단순한 풀텍스트 검색 그 이상을 구현할 수 있게 해줍니다. 또한 제안 도구(용어, 문구, 완성 등)를 구현하고, 순위 평가를 수행하며, 왜 어느 문서가 검색을 통해 반환되었는지 또는 반환되지 않았는지에 대한 피드백까지도 제공하도록 도와줍니다.
사용 가능한 검색 API 탐색하기집계 API
집계 프레임워크는 검색 쿼리를 기반으로 집계된 데이터를 제공할 수 있도록 도와줍니다. 이것은 복잡한 데이터 요약을 구축하기 위해 구성될 수 있는 집계라고 하는 간단한 빌딩 블록을 기반으로 합니다. 집계는 문서 세트에 대해 분석적인 정보를 구축하는 작업 단위로 볼 수 있습니다.
사용 가능한 집계 API 탐색하기메트릭 집계
버킷 집계
파이프라인 집계
매트릭스 집계
누적 커디널리티 집계
위치 헥스그리드 정보 집계
수집 API
수집 API를 사용하여 데이터 파이프라인에서 CRUD 작업을 수행하거나 시뮬레이트 파이프라인 API를 사용하여 일련의 문서에 대해 특정한 파이프라인을 실행합니다.
사용 가능한 수집 API 탐색하기관리 API
다양한 관리 관련 API로 Elasticsearch 클러스터를 프로그래밍 방식으로 관리하세요. 인덱스의 관리, 매핑, 클러스터, 노드, 라이선싱, 보안 등을 위한 수많은 API가 있습니다. 그리고 사람이 읽을 수 있는 형식으로 결과가 필요하시면, cat API를 사용하시면 됩니다.
관리 및 작업
통합
언어 기반이 아닌 오픈 소스 애플리케이션으로서, 플러그인과 통합으로 Elasticsearch의 기능성을 쉽게 확장할 수 있습니다.
Elasticsearch-Hadoop
Apache Hadoop용 Elasticsearch(Elasticsearch-Hadoop 또는 ES-Hadoop)는 무료 개방형이자 자체적으로 포함된 독립 실행형 소규모 라이브러리로서, Hadoop 작업이 Elasticsearch와 상호작용할 수 있게 해줍니다. ES-Hadoop을 사용해 동적 임베디드 검색 애플리케이션을 손쉽게 구축하고, 풀텍스트 검색과 위치 정보 쿼리, 집계를 통해 보다 깊이 있고 지연 시간이 짧은 Hadoop 데이터 분석을 실시할 수 있습니다.
ES-Hadoop에 대해 알아보기Apache Hive
Apache Hadoop용 Elasticsearch는 Apache Hive에 대한 최고의 지원을 제공합니다. Apache Hive는 Hadoop을 위한 데이터 창고 시스템으로, 손쉬운 데이터 요약화, 임시 쿼리, 그리고 Hadoop 호환 파일 시스템에 저장된 대규모의 데이터 세트 분석을 용이하게 합니다.
Apache Hive 통합에 대해 알아보기Apache Spark
Apache Hadoop용 Elasticsearch는 빠른 범용 클러스터 계산 시스템인 Apache Spark에 대한 최고의 지원을 제공합니다. 이것은 자바, Scala, Python에서 고급 API와 일반 실행 그래프를 지원하는 최적화된 엔진을 제공합니다.
Apache Spark 통합에 대해 알아보기비즈니스 인텔리전스(BI)
JDBC와 ODBC 인터페이스 덕분에, 폭넓은 서드파티 BI 애플리케이션이 Elasticsearch SQL 기능을 사용할 수 있습니다.
사용 가능한 BI와 SQL 통합 탐색하기플러그인 및 통합
무료 개방형이며 언어에 구애받지 않는 애플리케이션으로서, 플러그인과 통합을 통해 Elasticsearch의 기능을 손쉽게 확장할 수 있습니다. 플러그인은 핵심 Elasticsearch 기능을 사용자 정의 방식으로 향상하는 방법이며, 통합은 한결 손쉽게 Elasticsearch를 가지고 작업할 수 있게 해주는 외부 도구 또는 모듈입니다.
사용 가능한 Elasticsearch 플러그인 탐색하기API 확장 플러그인
경보 플러그인
분석 플러그인
발견 플러그인
수집 플러그인
관리 플러그인
매퍼 플러그인
보안 플러그인
스냅샷/복구 리포지토리 플러그인
저장 플러그인
관리 및 작업
배포
퍼블릭 클라우드, 프라이빗 클라우드 또는 이 둘을 접목한 형태로든 Elasticsearch를 편리하게 운영하고 관리할 수 있도록 도와드리겠습니다.
다운로드 및 설치
정말 쉽게 시작할 수 있습니다. Elasticsearch와 Kibana를 아카이브로 또는 패키지 매니저와 다운로드하여 설치하면 됩니다. 금방 데이터를 색인, 분석, 시각화할 수 있습니다. 기본 배포를 이용하면, 30일 무료 체험판으로 머신 러닝, 보안, 그래프 분석 등과 같은 플래티넘 기능들을 시험 사용해 볼 수도 있습니다.
Elastic Stack 다운로드Elastic Cloud
Elastic Cloud는 계속 증가하는 Elastic SaaS 제품군으로서 클라우드에서 Elastic 제품을 쉽게 배포, 운영, 확장하게 해줍니다. 쉽게 사용할 수 있고 관리되는 호스트형 Elasticsearch 환경에서부터 기본 제공되는 강력한 검색 솔루션에 이르기까지, Elastic Cloud는 Elastic을 원활하게 사용할 수 있는 기본 토대입니다. Elastic Cloud 제품을 14일간 무료로 사용해 보세요. 신용카드는 필요 없습니다.
Elastic Cloud에서 시작하기Elasticsearch Service 무료 체험판 시작해 보기
Elastic Cloud Enterprise
Elastic Cloud Enterprise(ECE)를 이용해, 모든 규모 및 인프라에서 Elasticsearch와 Kibana를 프로비저닝, 관리, 모니터링하고 단일 콘솔에서 모든 것을 관리하세요. Elasticsearch와 Kibana를 실행할 실제 하드웨어, 가상 환경, 프라이빗 클라우드, 퍼블릭 클라우드 내 개인 영역, 또는 일반 퍼블릭 클라우드(예: Google, Azure, AWS)를 선택하세요. 모든 곳에서 이용 가능합니다.
ECE 30일 무료 체험판 사용해 보기Kubernetes의 Elastic Cloud
Kubernetes Operator 패턴 위에 구축된 Kubernetes의 Elastic Cloud(ECK)는 기본 Kubernetes 오케스트레이션을 확장하여 Kubernetes의 Elasticsearch와 Kibana 설정 및 관리를 지원합니다. Kubernetes의 Elastic Cloud는 배포, 업그레이드, 스냅샷, 확장, 고가용성, 보안 및 Kubernetes에서 Elasticsearch를 실행하기 위한 여러 가지를 간단하게 처리할 수 있도록 간소화합니다.
Kubernetes의 Elastic Cloud 배포수집 및 보강
수집 및 보강
수집
원하시는 방식으로 데이터를 Elastic Stack으로 가져오세요. RESTful API, 언어 클라이언트, 수집 노드, 경량 수집기 또는 Logstash를 사용하세요. 언어 목록에만 국한되지 않습니다. 오픈 소스이기 때문에, 수집 가능한 데이터 유형에도 제한이 없습니다. 고유한 데이터 유형을 수집해야 하는 경우, 고유한 수집 방법을 만들기 위한 라이브러리와 단계별 지침을 제공해 드립니다. 그리고 원하시는 경우, 그것을 다시 커뮤니티와 공유하여, 바로 그 작업을 해야 하는 다음 사람이 똑같은 과정을 거치지 않아도 되도록 할 수 있습니다.
클라이언트 및 API
Elasticsearch는 표준 RESTful API와 JSON을 사용하며 자바, Python, .NET, SQL, PHP 같은 다양한 언어로 클라이언트를 구축하고 유지관리합니다. 또한 우리 커뮤니티는 훨씬 많은 것을 기여해 왔습니다. 이러한 클라이언트는 사용하기 간편하며 Elasticsearch처럼 사용자가 수행하는 작업에 제한이 없습니다.
수집 노드
Elasticsearch는 다양한 노드 유형을 제공하는데, 그 중 하나는 특별히 데이터 수집을 위한 것입니다. 수집 노드는 하나 이상의 수집 프로세서로 구성되는, 미리 처리된 파이프라인을 실행할 수 있습니다. 수집 프로세서와 필요한 리소스가 수행하는 작업 유형에 따라, 이 특정 작업만 수행하게 되는 전용 수집 노드를 갖는 것이 합리적일 수 있습니다.
Beats
Beats는 Elasticsearch나 Logstash로 작업 데이터를 보내기 위해 서버에 에이전트로 설치하는 오픈 소스 데이터 수집기입니다. Elastic은 다양한 일반 로그, 메트릭 및 그 밖에 다양한 데이터 유형을 캡처하기 위해 Beats를 제공합니다.
Linux 감사 로그를 위한 Auditbeat
로그 파일을 위한 Filebeat
클라우드 데이터를 위한 Functionbeat
가용성 데이터를 위한 Heartbeat
systemd 저널을 위한 Journalbeat
인프라 메트릭을 위한 Metricbeat
네트워크 트래픽을 위한 Packetbeat
Windows 이벤트 로그를 위한 Winlogbeat
Logstash
Logstash는 실시간 파이프라인 역량을 갖춘 오픈 소스 데이터 수집 엔진입니다. Logstash는 서로 다른 소스의 데이터를 통합하여 데이터를 사용자가 선택하는 대상 위치로 정규화합니다. 다양한 고급 다운스트림 분석과 시각화 사용 사례를 위해 모든 데이터를 정리하고 자유롭게 이용하세요.
커뮤니티 수집기
해결할 특정 사용 사례가 있는 경우, 커뮤니티 Beat를 생성할 것을 권장합니다. 프로세스를 간소화하기 위해 인프라를 생성했습니다. Go에서 모두 작성되면, libbeat 라이브러리는 모든 Beats가 데이터를 Elasticsearch로 전송하고, 입력 옵션을 구성하며, 로깅을 구현하는 등에 사용하는 API를 제공합니다.
커뮤니티에서 기여한 100개 이상의 Beats와 더불어, Cloudwatch 로그와 메트릭, GitHub 활동, Kafka 주제, MySQL, MongoDB Prometheus, Apache, Twitter 외 다수를 위한 에이전트가 있습니다.
사용 가능한 커뮤니티 개발 Beats 탐색하기수집 및 보강
데이터 Enrich(보강)
다양한 분석기, 토크나이저, 필터 및 강화 옵션 등으로 Elastic Stack은 원시 데이터를 귀중한 정보로 바꿔줍니다.
Elastic Common Schema
Elastic Common Schema(ECS)로 다양한 소스의 데이터를 일관되게 분석하세요. 탐지 규칙, 머신 러닝 작업, 대시보드, 기타 보안 콘텐츠를 좀 더 폭넓게 적용하고, 검색을 한결 세부적으로 조정하며, 필드 이름을 더욱 쉽게 기억할 수 있습니다.
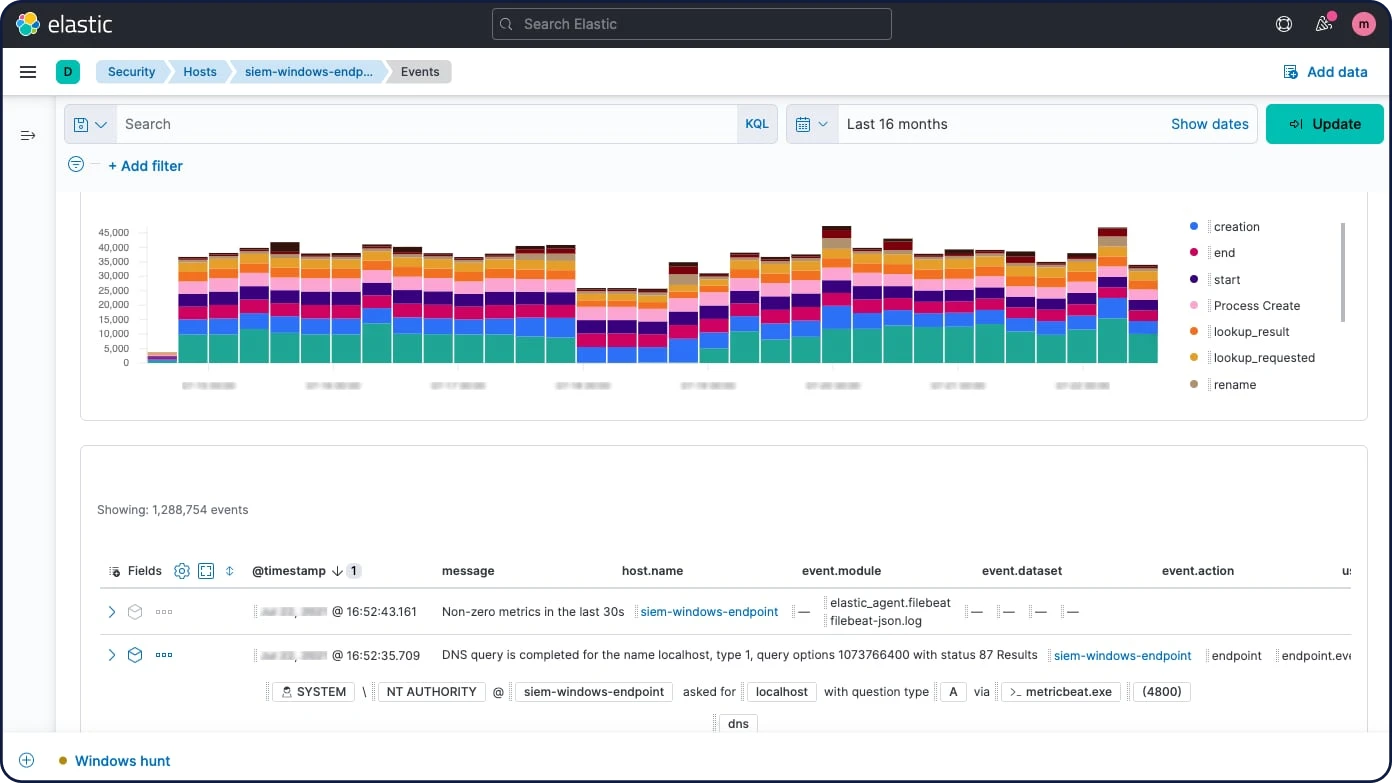
프로세서
실제 문서 색인이 발생하기 전에 수집 노드를 사용해 문서를 전처리합니다. 수집 노드는 대량 요청과 인덱스 요청을 가로채서 변환을 적용한 다음, 문서를 인덱스나 대량 API로 다시 보냅니다. 수집 노드는 append, convert, date, dissect, drop, fail, grok, join, remove, set, split, sort, trim 등 25개 이상의 여러 다른 프로세서를 제공합니다.
분석기
분석은 검색을 위한 역 인덱스에 추가되는 토큰이나 용어로 이메일 본문과 같은 텍스트를 변환하는 프로세스입니다. 분석은 분석기에 의해 수행됩니다. 이 분석기는 기본 분석기일 수도 있고, 토크나이저와 필터 조합을 사용해 인덱스별로 정의된 사용자 정의 분석기일 수도 있습니다.
예제: 표준 분석기 (기본 설정)
입력: "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
출력: the 2 quick brown foxes jumped over the lazy dog's bone
토크나이저
토크나이저는 캐릭터 스트림을 받아, 이를 개별 토큰들(보통은 개별 단어들)로 분할하여, 토큰 스트림으로 내보냅니다. 토크나이저는 또한 (구문과 단어 근접 연결 쿼리에 사용되는) 각 용어의 순서나 위치, 그리고 (검색 조각 강조 표시에 사용되는) 그 용어가 나타내는 원래 단어의 시작과 끝 캐릭터 오프셋을 기록할 책임을 담당합니다. Elasticsearch는 사용자 정의 분석기를 구축하는 데 사용할 수 있는 수많은 기본 토크나이저를 갖추고 있습니다.
예제: 공백 토크나이저
입력: "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
출력: The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.
필터
토큰 필터는 토크나이저로부터 토큰 스트림을 받아들여 토큰을 수정하거나(소문자로 변경 등), 토큰을 삭제하거나(중지 단어 삭제 등), 토큰을 추가(유의어 등)할 수 있습니다. Elasticsearch는 사용자 정의 분석기를 구축하는 데 사용할 수 있는 수많은 기본 토큰 필터를 갖추고 있습니다.
문자 필터는 토크나이저로 전달되기 전에 문자 스트림을 사전 처리하는 데 사용됩니다. 문자 필터는 원래 텍스트를 문자 스트림으로 받아서 문자를 추가, 삭제 또는 변경함으로써 스트림을 변환할 수 있습니다. Elasticsearch는 사용자 정의 분석기를 구축하는 데 사용할 수 있는 수많은 기본 문자 필터를 갖추고 있습니다.
문자 필터에 대해 알아보기언어 분석기
모국어로 검색하세요. Elasticsearch는 30개 이상의 다른 언어 분석기를 제공하며, 여기에는 러시아어, 아랍어, 중국어 같은 비라틴 문자를 사용하는 수많은 언어가 포함됩니다.
매칭 Enrich 프로세서
매칭 Enrich 프로세서는 사용자가 수집 시에 데이터를 찾을 수 있게 해주며 보강된 데이터를 가져올 최적화된 인덱스를 표시합니다. 이것은 Beats에서 Logstash로 피봇팅하기 보다는 데이터에 몇 가지 요소를 추가해야 하는 Beats 사용자를 도와줍니다. 따라서 사용자는 수집 파이프라인을 직접 확인할 수 있습니다. 사용자는 또한 보다 나은 분석과 보다 일반적인 쿼리를 위해 프로세서로 데이터를 정규화할 수 있게 됩니다.
위치 정보 매칭 Enrich 프로세서
위치 정보 매칭 Enrich 프로세서는 위치 정보 좌표 용어로 쿼리나 집계를 정의할 필요 없이 위치 정보 데이터를 활용함으로써 사용자가 검색과 집계 기능을 개선할 수 있게 해주는 유용하고 실용적인 방법입니다. 매칭 Enrich 프로세서와 비슷하게, 사용자는 수집 시에 데이터를 찾고, 보강된 데이터를 가져올 최적화된 인덱스를 발견할 수 있습니다.
데이터 저장 공간
데이터 저장 공간
유연성
Elastic Stack은 거의 모든 사용 사례에 적용할 수 있는 강력한 솔루션입니다. 그리고 고급 검색 역량으로 가장 잘 알려져 있긴 하지만, 유연한 디자인은 문서 저장 공간, 시계열 분석 및 메트릭, 위치 기반 정보 분석 등 수많은 다른 필요에 대해서도 최적의 도구입니다.
데이터 유형
Elasticsearch는 문서의 필드를 위한 많은 다른 데이터 유형을 지원하며, 그러한 각 데이터 유형은 그 자체의 여러 하위 유형을 제공합니다. 이를 통해 데이터와 상관없이 가능한 가장 효율적이고 효과적인 방법으로 데이터를 저장, 분석 ,활용할 수 있습니다. Elasticsearch가 최적화된 데이터 유형 몇 가지를 소개하면 다음과 같습니다.
텍스트
도형
숫자
벡터
히스토그램
날짜/시계열
병합된 필드
Geo-points/geo-shapes
비정형 데이터(JSON)
정형 데이터
풀텍스트 검색(역 인덱스)
Elasticsearch는 역 인덱스라고 하는 구조를 사용하는데, 이것은 아주 빠른 풀텍스트 검색을 할 수 있도록 설계된 것입니다. 역 인덱스는 문서에서 나타나는 모든 고유 단어 목록과 각 단어에 대해, 그 단어가 나타나는 문서 목록으로 구성됩니다. 역 인덱스를 만들려면, 먼저 각 문서의 콘텐츠 필드를 개별 단어(우리가 용어 또는 토큰이라고 부르는)로 분할하고, 모든 고유 용어의 분류된 목록을 만든 다음, 각 용어가 나타나는 문서 목록을 만듭니다.
(구조화되지 않은) 문서 저장소
Elasticsearch는 수집 또는 분석되기 위해 데이터가 (구조화되면 속도가 개선되기는 하지만) 구조화되어야 할 것을 요구하지 않습니다. 이러한 디자인은 간단하게 시작할 수 있지만, 아울러 Elasticsearch가 효과적인 문서 저장소가 되도록 해줍니다. Elasticsearch가 NoSQL 데이터베이스는 아니지만, 그래도 유사한 기능을 제공합니다.
시계열/분석(열 형식 저장소)
역 인덱스는 쿼리가 검색 용어를 신속하게 조회할 수 있게 해주지만, 정렬 및 집계에는 다른 데이터 액세스 패턴이 필요합니다. 용어를 조회하고 문서를 찾아내는 대신, 필드에서 가지고 있는 문서를 조회하고 용어를 찾아낼 수 있어야 합니다. doc values는 Elasticsearch의 디스크에 있는 데이터 구조이며, 문서 색인 시에 구축됩니다. 이것은 이 데이터가 가능한 패턴에 액세스할 수 있게 하여, 열 형식으로 검색이 발생할 수 있게 해줍니다. 이로써 Elasticsearch는 시계열 및 메트릭 분석에 뛰어나게 됩니다.
위치 기반 정보(BKD 트리)
Elasticsearch는 Lucene 내에서 BKD 트리 구조를 사용하여 위치 기반 정보 데이터를 저장합니다. 이렇게 하면 geo-points(위도와 경도) 및geo-shapes(사각형과 다각형) 양쪽 모두를 효율적으로 분석할 수 있습니다.
데이터 저장 공간
보안
보안은 클러스터 수준에서 끝나지 않습니다. Elasticsearch 내에서 데이터를 필드 수준까지 완전히 안전하게 유지하세요.
필드 및 문서 수준 API 보안
필드 수준 보안은 사용자가 읽기 액세스 권한을 갖는 필드를 제한합니다. 특히, 문서 수준 읽기 API에서 액세스할 수 있는 필드가 어느 것인지를 제한합니다.
문서 수준 보안은 사용자가 읽기 액세스 권한을 갖는 문서를 제한합니다. 특히, 문서 수준 읽기 API에서 액세스할 수 있는 문서가 어느 것인지를 제한합니다.
문서 수준 보안에 대해 알아보기휴면 데이터 암호화 지원
Elastic Stack이 휴면 암호화를 기본으로 구현하지는 않지만, 모든 호스트 컴퓨터에서 디스크 수준의 암호화를 구성할 것을 권장합니다. 아울러, 스냅샷 대상 또한 데이터가 휴면 암호화되도록 확인해야 합니다.
데이터 저장 공간
관리
Elasticsearch는 클러스터와 그 노드, 인덱스와 그 샤드, 그리고 가장 중요하게는, 그 안에 포함된 모든 데이터를 전체적으로 관리할 수 있는 역량을 제공합니다.
클러스터된 인덱스
클러스터는 하나 이상의 노드(서버)의 모음으로, 이것들이 합쳐져 함께 사용자의 데이터를 유지하고, 모든 노드에 걸쳐 연결된 색인 및 검색 기능을 제공합니다. 이 아키텍처는 수평적으로 쉽게 확장할 수 있게 해줍니다. Elasticsearch는 사용자가 클러스터를 관리하는 데 사용할 수 있는 종합적이고 강력한 REST API 및 UI를 제공합니다.
데이터 스냅샷 및 복구
스냅샷은 Elasticsearch 클러스터 실행에서 얻어지는 백업입니다. 개별 인덱스나 전체 클러스터의 스냅샷을 찍어서 공유 파일 시스템의 리포지토리에 저장할 수 있습니다. 원격 리포지토리도 지원하는 플러그인이 제공됩니다.
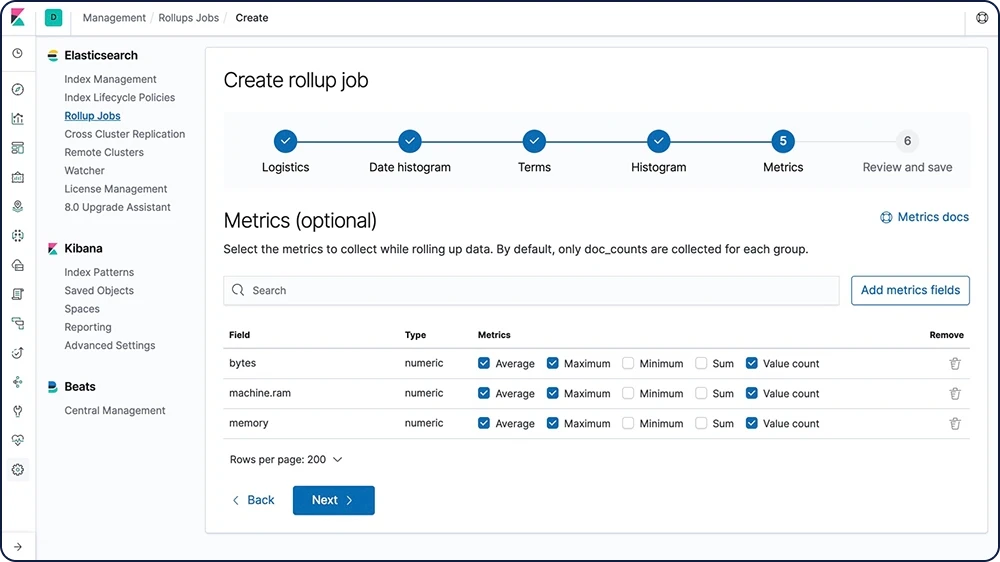
인덱스 롤업
분석을 위해 과거 데이터를 유지하는 것은 극히 유용합니다. 그러나 막대한 양의 데이터를 보관하는 데 드는 경제적인 비용으로 인해 과거 데이터를 유지하지 못하는 경우가 자주 있습니다. 따라서 보존 기간은 방대한 과거 데이터의 유용성보다는 경제적인 현실에 따라 달라지게 됩니다. 롤업 기능은 과거 데이터를 요약하고 저장하는 수단을 제공함으로써, 원시 데이터 저장 비용의 극히 일부만으로도 분석을 위해 사용할 수 있게 해줍니다.
검색 및 분석
검색 및 분석
풀텍스트 검색
Elasticsearch는 강력한 풀텍스트 검색 역량으로 유명합니다. 그 속도는 그 중심에 있는 역 인덱스 덕분이며, 그 강력한 성능은 튜닝이 가능한 정확도 점수, 고급 쿼리 DSL 그리고 광범위한 검색 개선 기능 덕분입니다.
역 인덱스
Elasticsearch는 역 인덱스라고 하는 구조를 사용하는데, 이것은 아주 빠른 풀텍스트 검색을 할 수 있도록 설계된 것입니다. 역 인덱스는 문서에서 나타나는 모든 고유 단어 목록과 각 단어에 대해, 그 단어가 나타나는 문서 목록으로 구성됩니다. 역 인덱스를 만들려면, 먼저 각 문서의 콘텐츠 필드를 개별 단어(우리가 용어 또는 토큰이라고 부르는)로 분할하고, 모든 고유 용어의 분류된 목록을 만든 다음, 각 용어가 나타나는 문서 목록을 만듭니다.
런타임 필드
런타임 필드는 쿼리 시간(읽기 스키마)에 평가되는 필드입니다. 런타임 필드는 문서가 색인된 후를 비롯하여 언제든지 도입하거나 수정할 수 있으며 쿼리의 일부로 정의할 수 있습니다. 런타임 필드는 색인된 필드와 동일한 인터페이스를 가진 쿼리에 노출되므로 필드는 데이터 스트림의 일부 인덱스에 있는 런타임 필드 및 해당 데이터 스트림의 다른 인덱스에 있는 색인된 필드일 수 있으며 쿼리는 이를 인식할 필요가 없습니다. 색인된 필드는 최적의 쿼리 성능을 제공하지만, 런타임 필드는 문서가 색인된 후 데이터 구조를 변경할 수 있는 유연성을 제공하여 이를 보완합니다.
런타임 필드 조회
런타임 필드 조회를 사용하면 문서를 링크하는 두 인덱스에서 키를 정의하여 룩업 인덱스의 정보를 기본 인덱스의 결과에 유연하게 추가할 수 있습니다. 런타임 필드와 마찬가지로, 이 기능은 쿼리 시에 유연한 데이터 강화를 제공하는 데 사용됩니다.
클러스터 간 검색
클러스터 간 검색(CCS) 기능은 모든 노드가 여러 클러스터에 걸쳐 연결된 클라이언트로 기능할 수 있게 해줍니다. 클러스터 간 검색 노드는 원격 클러스터에 합류하는 대신, 연결된 검색 요청을 실행하기 위해 가벼운 방식으로 원격 클러스터에 접속합니다.
정확도 점수
유사성(정확도 점수/순위 모델)은 일치하는 문서들이 어떻게 점수가 매겨지는지를 정의합니다. 기본 설정으로 Elasticsearch는 BM25 유사성 — 짧은 필드에 대해 최적화된 기본 tf 정규화를 갖춘 고급 TF/IDF-기반 유사성 —을 갖지만 수많은 다른 유사성 옵션이 제공됩니다.
벡터 검색(ANN)
HNSW 알고리즘에 기반한 Lucene 9의 새로운 최근접 유사 항목(ANN) 지원을 바탕으로, 새로운 _knn_search API 엔드포인트는 벡터 유사성을 통해 보다 확장성이 좋고 성능이 뛰어난 검색이 용이하도록 해줍니다. 이는 재현율과 성능 간의 절충을 통해 가능합니다. 즉, (기존의 브루트 포스 벡터 유사성 방법에 비해) 재현율 측면에서 약간의 절충을 함으로써 매우 큰 데이터 세트에서 훨씬 더 나은 성능이 가능해집니다.
Query DSL
풀텍스트 검색에는 강력한 쿼리 언어가 필요합니다. Elasticsearch는 쿼리를 정의하기 위해 JSON에 기반한 전체 쿼리 DSL(도메인 특정 언어)를 제공합니다. 용어와 구문에 일치하는 간단한 쿼리를 만들거나 여러 쿼리를 결합할 수 있는 복합 쿼리를 개발합니다. 아울러, 쿼리 시에 필터를 적용하여, 정확도 점수를 부여받기 전에 문서를 제거할 수 있습니다.
비동기 검색
비동기 검색 API를 사용하면 오래 실행되는 쿼리를 백그라운드에서 실행하고 쿼리 진행 상황을 추적하며 검색 결과가 이용 가능해지면 부분적인 결과를 검색할 수 있습니다.
하이라이터
하이라이터는 검색 결과에서 하나 이상의 필드로부터 강조 표시된 코드 조각을 얻을 수 있게 해주며 따라서 쿼리 일치가 어디에 있는지를 사용자에게 보여줄 수 있습니다. 강조 표시를 요청할 때, 응답에는 강조 표시된 필드와 강조 표시된 조각을 포함하는 각 검색 방문마다 추가적인 강조 표시 요소가 포함됩니다.
자동 완성
완성 제안기는 자동 완성/입력 시 검색 기능을 제공합니다. 이것은 사용자가 입력을 하고 있을 때 사용자에게 관련 결과를 안내하여 검색 정밀도를 개선하는 탐색 기능입니다.
제안 도구(검색어 추천)
문구 제안기는 엔그램 언어 모델에 기반해 가중치가 적용된 개별 토큰이 아니라 대신 정정된 전체 문구를 선택하는 용어 제안기에 더하여 추가 로직을 구축함으로써 검색에 “다음을 검색하려 하시나요?” 기능을 추가합니다. 실제적으로, 이 제안기는 동시 발생 및 빈도를 기반으로 어느 토큰을 선택할 것인지에 대해 보다 나은 결정을 내릴 수 있게 해줍니다.
수정(맞춤법 검사)
용어 제안기는 맞춤법 검사의 루트에 있으며, 편집 거리를 기반으로 용어를 제안합니다. 제공되는 제안 텍스트는 용어가 제안되기 전에 분석됩니다. 제안되는 용어는 분석된 제안 텍스트별로 제공됩니다.
퍼컬레이터
퍼컬레이터는 인덱스에 저장된 문서를 찾기 위해 쿼리를 사용하는 표준 검색 모델을 뒤집어, 인덱스에 저장된 쿼리에 문서를 매칭하는 데 사용될 수 있습니다. percolate 쿼리는 저장된 쿼리와 일치시키기 위해 쿼리로 사용되는 문서를 그 자체에 포함합니다.
쿼리 프로파일러/최적화 도구
프로파일 API는 검색 요청에서 개별 구성 요소의 실행에 대한 상세한 타이밍 정보를 제공합니다. 낮은 수준에서 검색 요청이 어떻게 실행되는지에 대한 인사이트를 제공하여, 사용자가 왜 특정 요청은 느린지, 그것을 개선하려면 어떤 단계를 밟아야 하는지 이해할 수 있습니다.
동적으로 업데이트 가능한 동의어
분석기 다시 로드 API를 사용하여, 동의어 정의 다시 로드를 트리거할 수 있습니다. 구성된 동의어 파일 콘텐츠가 다시 로드되고, 필터가 사용하는 동의어 정의가 업데이트됩니다. _reload_search_analyzers API는 하나 이상의 인덱스에 대해 실행되고, 구성된 파일로부터 동의어 다시 로드를 트리거하게 됩니다.
결과 고정
선택한 문서를 해당 쿼리에 매칭하는 것보다 더 높은 순위로 승격시킵니다. 이 기능은 통상적으로 검색과 매칭되는 모든 “유기적인” 매칭 이상으로 승격된 큐레이팅된 문서로 검색자를 안내하는 데 사용됩니다. 승격된 또는 “고정된” 문서는 _id 필드에 저장된 문서 ID를 사용해 식별됩니다.
검색 및 분석
분석
데이터 검색은 시작일 뿐입니다. Elasticsearch의 강력한 분석 기능은 사용자가 검색한 데이터를 가지고 훨씬 더 깊은 의미를 찾아낼 수 있도록 해줍니다. 결과 집계든, 문서 간의 관계 찾기든, 임계값에 기반한 알림 생성이든, 이 모든 것은 강력한 검색 기능의 토대 위에 구축됩니다.
집계
집계 프레임워크는 검색 쿼리를 기반으로 집계된 데이터를 제공할 수 있도록 도와줍니다. 이것은 복잡한 데이터 요약을 구축하기 위해 구성될 수 있는 집계라고 하는 간단한 빌딩 블록을 기반으로 합니다. 집계는 문서 세트에 대해 분석적인 정보를 구축하는 작업 단위로 볼 수 있습니다.
메트릭 집계
버킷 집계
파이프라인 집계
매트릭스 집계
위치 헥스그리드 정보 집계
랜덤 샘플러 집계
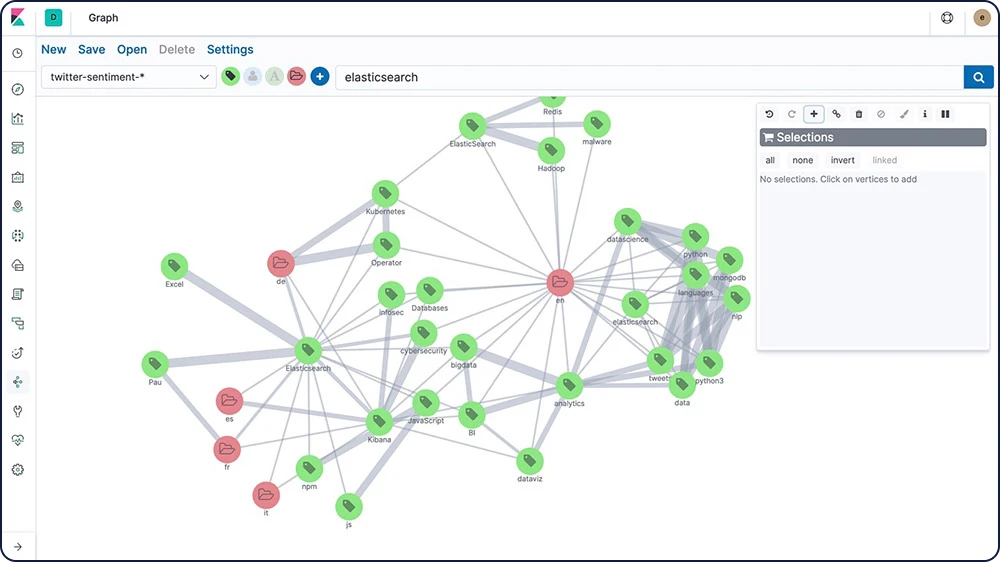
그래프 탐색
그래프 탐색 API는 사용자가 Elasticsearch 인덱스에서 문서와 용어에 대한 정보를 검색하고 요약할 수 있게 해줍니다. 이 API의 행동을 이해하는 가장 좋은 방법은 Kibana의 그래프를 사용해 연결을 탐색하는 것입니다.
검색 및 분석
머신 러닝
Elastic 머신 러닝 기능은 Elasticsearch 데이터의 트렌드, 주기성 등과 같은 동작을 자동으로 실시간 모델링하여 더 빠르게 문제를 식별하고 근본 원인을 분석하며 가양적(false positive) 결과를 줄입니다.
시계열 예측
Elastic 머신 러닝이 데이터의 정상적인 행동에 대한 기준선을 생성한 후, 사용자는 그 정보를 사용해 미래의 행동을 추론할 수 있습니다. 그 후 특정한 미래의 날짜에 대한 시계열 값 추정치를 예측하거나 시계열 값이 미래에 발생할 가능성을 추정합니다.
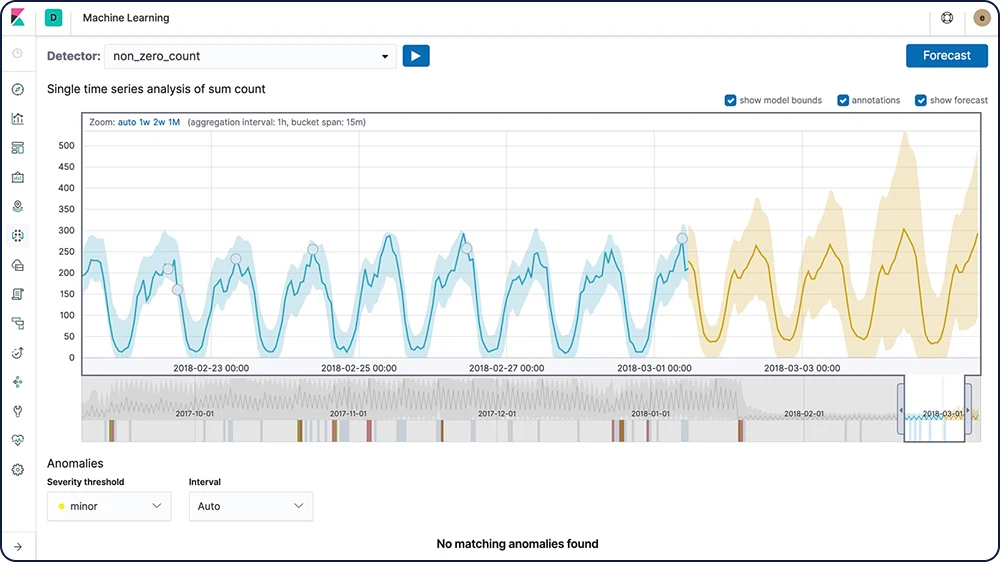
시계열에서의 이상 징후 탐지
Elastic 머신 러닝기능은 데이터에서 정상 동작의 정확한 기준선을 생성하고 해당 데이터의 비정상적인 패턴을 식별함으로써 시계열 데이터 분석을 자동화합니다. 독점 머신 러닝 알고리즘을 사용해 이상 징후가 탐색되고, 영향도가 지정되고, 데이터에서 통계적으로 의미있는 영향력 행사자와 연결됩니다.
값, 수 또는 빈도에서 임시 편차와 관련된 이상 징후
통계적 희귀성
인구 구성원의 비정상적인 행동
이상 징후 경보
비지도 학습 방식의 머신 러닝 기능으로 규칙과 임계값을 정의하기 어려운 변경 사항을 경보 기능과 결합하여 통상적이지 않은 데이터의 이상 행동을 감지합니다. 그리고 나서 알림 프레임워크의 이상 징후 점수를 이용해 문제가 발생하면 알림을 받습니다.
유추
유추는 일괄 분석으로서뿐만 아니라 지속적인 방식으로도 회귀나 분류 같은 지도 머신 러닝 프로세스를 사용할 수 있게 해줍니다. 유추 덕분에 들어오는 데이터에 대해 훈련된 머신 러닝 모델을 사용하는 것이 가능해집니다.