Elasticsearch 확장성을 향상시킨 3가지 방법


 Share on Twitter
Share on Twitter트위터에서 공유하기

 Share on LinkedIn
Share on LinkedIn링크드인에서 공유하기

 Share on Facebook
Share on Facebook페이스북에서 공유하기

 Share by Email
Share by Email이메일로 공유하기

 Print this page
Print this page인쇄하기
“사람은 한계에 도전할 때 비로소 한계를 발견한다.”
Herbert A. Simon
Elastic은 대규모로 운영 가능하고 정확도가 높은 결과를 통해 사용자에게 가치를 제공하는 데 주력하고 있습니다. 속도, 확장성, 정확도는 Elastic의 핵심입니다. Elasticsearch 7.16에서는 확장성에 초점을 맞추고 Elasticsearch의 한계를 뛰어넘어 검색 속도를 더 높이고 메모리 사용량을 줄이며 클러스터를 더 안정적으로 만들었습니다. 그 과정에서 샤딩의 다양한 차원을 발견했고 Elasticsearch의 속도를 새로운 차원으로 끌어올렸습니다.
지금까지는 관련 리소스 오버헤드로 인해 클러스터에 너무 많은 샤드를 생성하지 않도록 권장해왔습니다. 그러나 Fleet의 새로운 데이터 스트림 색인 전략으로 보안 및 통합 가시성 사용 사례에서 더 작은 크기의 샤드가 점점 더 많이 생성될 것이므로 증가하는 샤드 수에 대응할 수 있는 새로운 방법을 찾아야 합니다. 이 블로그에서는 Elasticsearch의 3가지 확장 과제와 7.16 이상에서 이러한 경험을 어떻게 개선했는지 살펴보겠습니다.

권한 부여 간소화
술집에 들어간다고 상상해보세요. 입구에서 신분증을 확인한 다음 술을 주문할 때마다 신분증을 다시 확인해야 합니다. 이것이 7.16 이전의 권한 부여 방식이었습니다. 모든 노드(입구)에서 권한 확인이 필요했고 모든 샤드(술 주문)에서도 권한 확인이 필요했습니다. 하지만 입구에서 한 번의 신분증 확인으로 둘 다 처리할 수 있다면 어떨까요? Elasticsearch의 권한 부여 방식에도 같은 아이디어를 적용해 보겠습니다!
Elasticsearch에서는 사용자가 역할/속성 기반 액세스 제어를 설정하여 필드별, 문서별 또는 인덱스 수준별로 세분화된 권한을 부여할 수 있습니다. 이전에는 권한이 없는 요청이 허가되지 않은 데이터에 액세스하지 못하도록 검색 쿼리의 여러 단계에서 authorize가 제시되었습니다. 그러나 이렇게 경계를 강화한 권한 부여 기능에는 대가가 따르며, 일부 로직은 클러스터 크기의 증가에 맞춰 수평적으로 확장되지 않습니다. 예를 들어 대규모 클러스터에 있는 모든 인덱스의 모든 필드에 대한 필드 기능을 가져오려면 완료하는 데 수십 초 또는 수 분이 걸릴 수 있습니다. 실행 시간의 대부분이 승인 관련 작업에 소비되기 때문입니다.
7.16에서는 다음과 같은 두 가지 측면에서 이러한 문제를 해결합니다.
- 권한 부여 알고리즘이 개선되어 개별 요청을 더 빠르게 승인할 수 있습니다. 이는 REST 요청을 승인할 때와 전송 계층 통신(즉, 모든 내부 노드 간 네트워킹) 중에 Elasticsearch 클러스터 내부의 노드 간 통신을 승인할 때 모두 해당됩니다.
- 내부 요청의 승인은 이전에 확인한 결과에서 상속되거나 많은 경우 훨씬 더 저렴하게 이루어집니다. 7.16 이전의 Elasticsearch는 클러스터 내에서 내부 전송 요청을 승인할 때 초기 외부 요청을 승인할 때와 동일한 승인 로직을 실행했었습니다. 이는 내부 노드 간 통신에서 공격 표면을 노출시키지 않음으로써 공격자가 내부 요청을 조작하여 승인 로직을 우회하지 못하게 하려는 의도였습니다. 이 작업은 이제 하위 요청에서 와일드카드 확장을 건너뛰고, 동일 노드 내에서 노드-로컬 요청에 대한 승인을 건너뛰고, 검색과 같은 작업에 필요한 전체 요청 수를 줄임으로써 훨씬 더 저렴해졌습니다.
pre-filter 단계에서 샤드 요청 수 줄이기
7.16에서는 pre-filter 단계에서 새로운 검색 전략이 구현되어 샤드 요청 수를 일치하는 노드당 한 번으로 줄였습니다. 7.16 이전에는 검색의 첫 번째 단계, 즉 관련 데이터가 없는 것으로 알려진 모든 샤드를 쿼리에서 필터링하는 단계에서는 조정 노드에서 데이터 노드로 샤드당 하나의 요청이 필요했습니다. 한 번에 수천 개의 샤드를 쿼리하는 경우 조정 노드로부터 검색 요청 당 수천 개의 요청을 전송하고, 조정 노드에서 수천 개의 응답을 처리하고, 데이터 노드에서 이 모든 요청을 처리하고 응답해야 했습니다. 클러스터를 더 많은 수의 데이터 노드로 확장하면 데이터 노드에서 수많은 요청을 처리하는 성능이 향상되지만, 조정 노드에서 이 작업을 수행하는 성능에는 도움이 되지 않습니다.
7.16부터는 pre-filter 단계를 실행하는 전략이 노드당 하나의 요청만 전송하여 해당 노드의 모든 샤드를 처리하는 방식으로 바뀌었습니다. 이는 아래 그림 1에서 확인할 수 있습니다. 3개의 데이터 노드에 걸쳐 수천 개의 샤드로 구성된 클러스터에서는 검색하는 샤드 수와 관계없이 초기 검색 단계의 네트워크 요청 수가 수천 개에서 3개 이하로 줄어드는 것을 볼 수 있습니다. 7.16 이전에 전송된 샤드당 요청에는 모든 샤드(즉, 검색 쿼리)에 걸쳐 거의 동일한 데이터가 포함되어 있으므로 노드당 하나의 요청만 전송하면 여러 요청에서 이 정보가 중복되지 않아 네트워크를 통해 전송해야 하는 바이트 수가 크게 줄어듭니다.
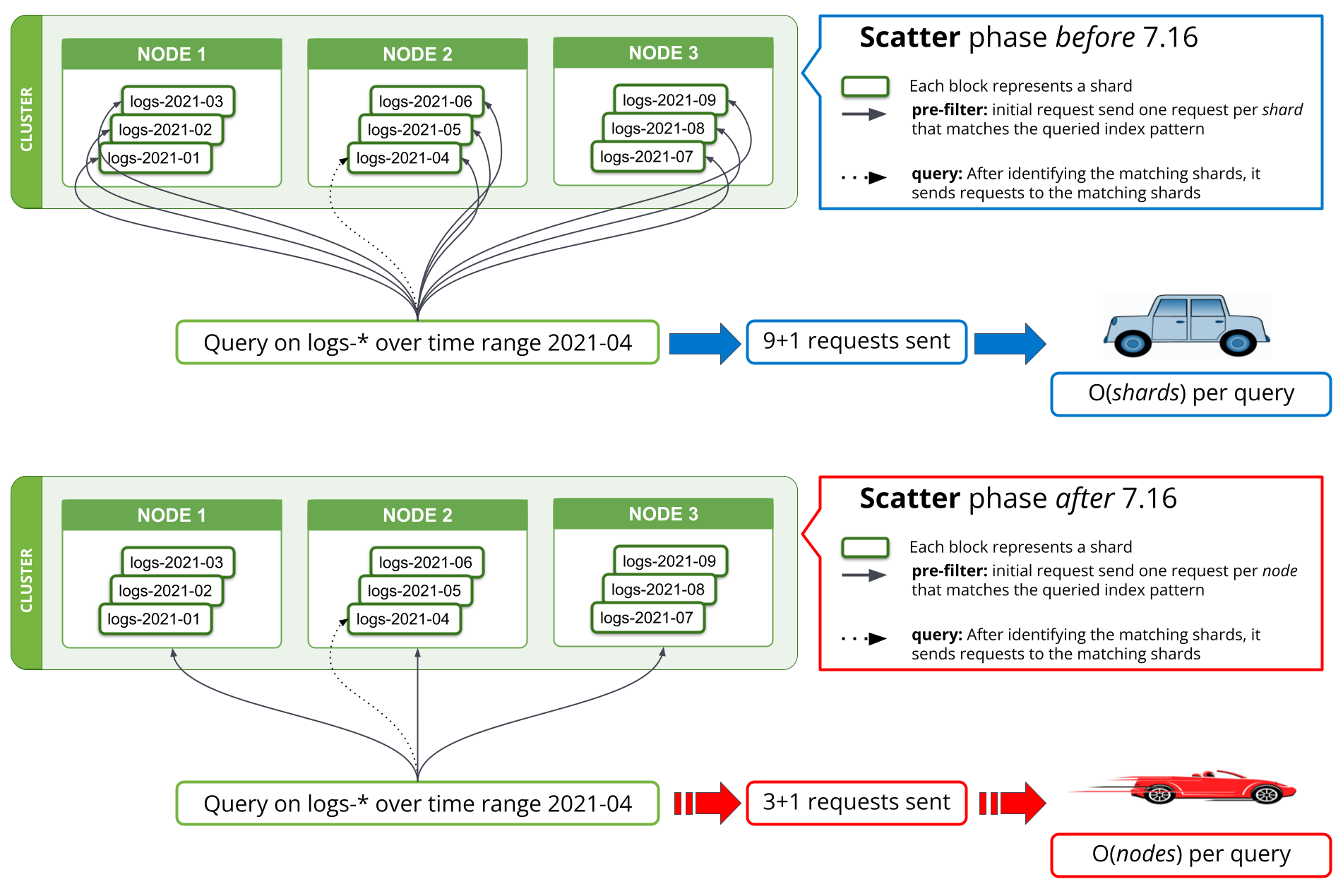
Kibana 및 *QL 쿼리에서 사용하는 field_caps에도 유사한 구현 방식이 적용되었습니다. 이론적으로 보면, 네트워크 요청에 저장된 검색 요청이 쿼리당 O(shards)에서 O(nodes)로 감소했습니다. 실제로 벤치마킹 결과에 따르면 대규모 로깅 클러스터에서 수개월 동안의 데이터에 대한 로그 쿼리 시간이 몇 분에서 10초 미만으로 단축되었습니다. 이렇게 감소한 요청 수는 네트워크 요청 수뿐만 아니라 이러한 요청과 관련된 메모리 및 CPU 사용량을 줄이는 데도 도움이 되었습니다.
메모리 공간 줄이기
놀라실지도 모르지만, 샐러드에서 올리브 한 개를 제거하고 더 얇은 유리그릇을 사용하고, 잡지를 더 작은 크기로 인쇄함으로써 항공사들은 무게를 상당히 줄일 수 있습니다. Elasticsearch에서도 필드당 메모리 비용을 줄임으로써 유사한 방식을 도입하고 있습니다. 필드당 몇 킬로바이트에 불과하지만, 클러스터의 모든 인덱스에서 수백만 개의 필드를 곱하면 엄청난 양의 힙을 절감할 수 있습니다.
Elasticsearch 데이터 노드의 힙 사용량은 인덱스 수, 인덱스당 필드 수, 클러스터 상태에 저장된 샤드 수에 따라 달라집니다. 인덱스 수가 많다는 것은 노드의 부하와 관계없이 힙 메모리가 지속적으로 사용됨을 의미합니다. 7.16에서는 텍스트 및 숫자 필드의 필드 빌더를 재구성하여 메모리 공간을 줄이고 이러한 필드 구조를 유지하는 데 사용되는 메모리를 90% 이상 줄였습니다.
수집하고 검색하고 정복하는 Elastic
7.16이 릴리즈된 후 실제 워크로드 클러스터에서 개선이 이루어진 것을 확인할 수 있었습니다. 다음은 업그레이드가 60개의 데이터 노드로 이루어진 클러스터에 미치는 영향을 보여주는 몇 가지 차트입니다.
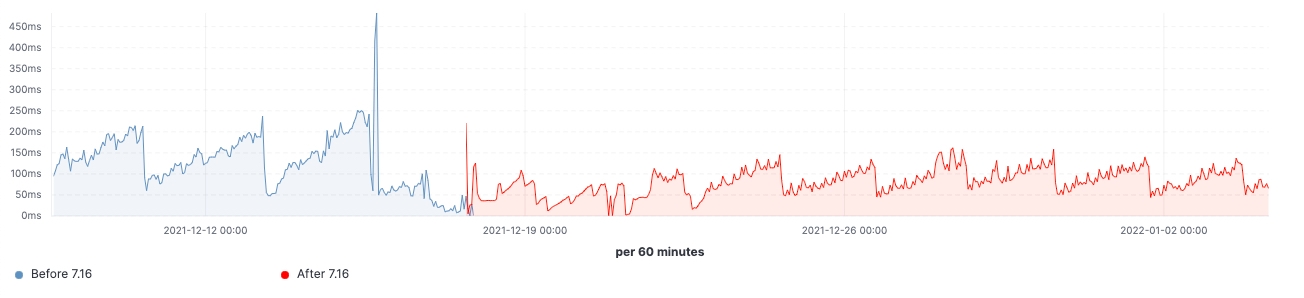
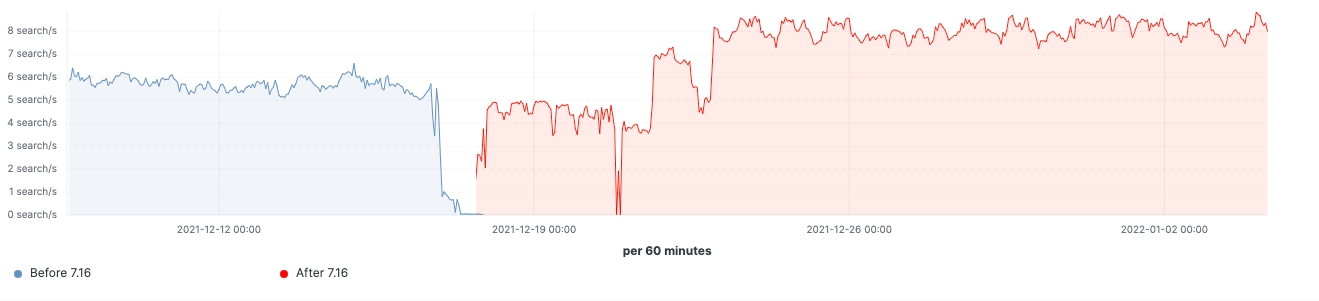
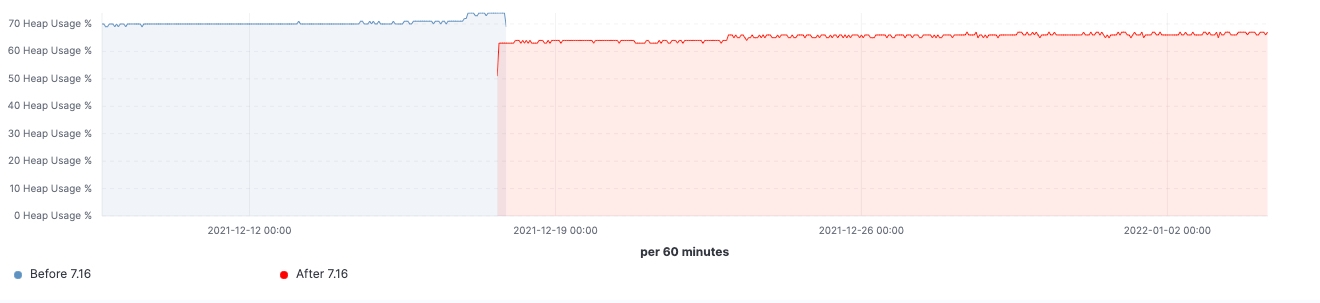
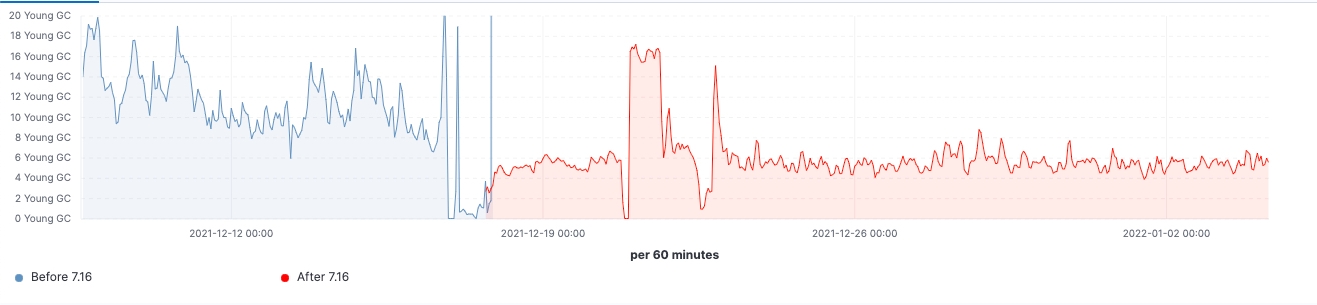
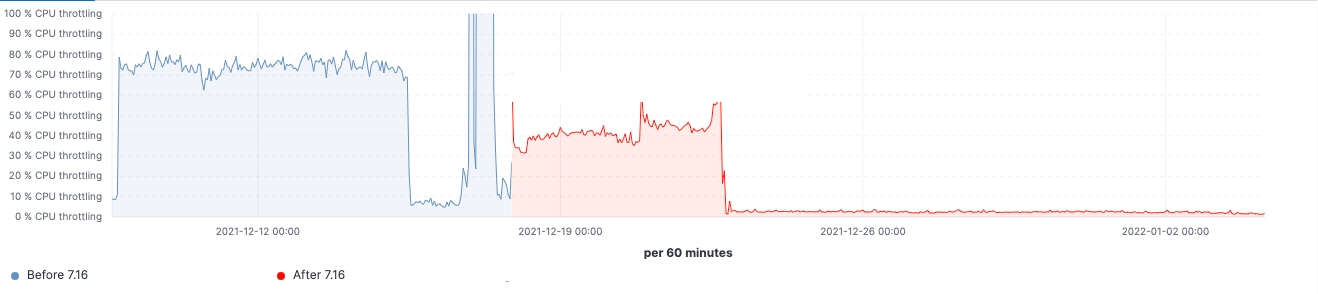
이 클러스터의 경우 업그레이드 전과 후에 일관된 워크로드를 관찰할 수 있었으며, 검색 지연 시간의 99%가 균일하게 감소했고, 검색 속도(처리량)가 증가했으며, 데이터 구조 저장에 필요한 메모리 공간이 감소하여 프로즌 노드의 힙 사용량이 지속적으로 감소했습니다. 이는 모든 데이터 티어에 영향을 미칠 것으로 예상되지만, 색인, 쿼리 및 기타 작업에 힙을 사용할 수 있는 핫 노드와 달리 데이터 구조를 저장하는 데 힙이 주로 사용되는 프로즌 노드에서 영향이 가장 두드러집니다. 노드 역할별로 분류하면 pre-filter 단계에서 샤드 요청 수를 줄인 덕분에 조정 노드에서 최신 가비지 수집(young GC) 수가 눈에 띄게 감소했습니다. 마지막으로 클러스터 상태 관리가 개선됨에 따라 마스터 노드의 CPU 스로틀링 요구가 크게 줄어들었습니다.
수만 개의 샤드로 확장할 때 Elasticsearch에 성능 문제가 발생하는 이유를 조사하고 Elasticsearch 7.16에서는 확장성 개선을 목표로 잡았습니다. 엄청난 수의 샤드와 매핑의 폭발적 증가는 Elasticsearch 장애의 주요 요인으로 알려져 있으므로 이는 여전히 피해야 하지만, 개선된 7.16에서는 이러한 영향이 훨씬 줄어들 것으로 예상됩니다. 이번 릴리즈에서 개선 사항은 클러스터의 전반적인 크기에 중점을 두어 더 작은 마스터 크기에서 클러스터 상태 업데이트를 처리하고 많은 수의 인덱스에서 검색 조정을 간소화할 수 있도록 했습니다.
7.16에서 제공하는 Elasticsearch의 강력한 기능을 통해 이제 검색 엔진의 속도가 빨라지고, 메모리 사용량이 감소하고, 클러스터 안정성이 강화됩니다. 업그레이드만 하면 이 모든 이점을 누리실 수 있습니다! Elastic에서는 확장성 측면에서 다양한 부분을 계속해서 개선하고 있으며 8.x에서 더 많은 개선 사항을 선보일 예정입니다.
더 확장할 준비가 되셨나요?
기존 Elastic Cloud 고객은 Elastic Cloud 콘솔에서 이 중 많은 기능을 바로 이용하실 수 있습니다. Elastic Cloud를 처음 접하시는 경우, 빠른 시작 안내서(빠른 시작을 위한 짤막한 길이의 교육용 비디오)나 무료 기초 교육 과정을 살펴보세요. Elastic Cloud 14일 무료 체험판을 통해 언제든지 무료로 시작하실 수 있습니다. 또는 자체 관리형 버전의 Elastic Stack을 무료로 다운로드하실 수도 있습니다.
이러한 기능 및 자세한 내용은 Elastic 7.16 릴리즈 노트를 참조하시고, Elastic Stack에 대한 다른 주요 내용은 Elastic 7.16 발표 게시물을 참조하세요.공유하기
- Share on Twitter
트위터에서 공유하기
- Share on LinkedIn
링크드인에서 공유하기
- Share on Facebook
페이스북에서 공유하기
- Share by Email
이메일로 공유하기
- Print this page
인쇄하기