RAG(検索拡張生成)とは
検索拡張生成(RAG)の定義
検索拡張生成(RAG)とは、テキスト生成をプライベートデータソースまたは独自のデータソースからの情報で補完する技術のことです。これは、大規模なデータセットやナレッジベースを検索するように設計された検索モデルと、その情報を受け取って読みやすいテキスト応答を生成する大規模言語モデル(LLM)のような生成モデルを組み合わせたものです。
検索拡張生成は、追加のデータソースからコンテキストを追加したり、トレーニングからLLMの元のナレッジベースを補完することで、検索エクスペリエンスの関連性を向上させることができます。これにより、モデルを再トレーニングする必要なしに、大規模言語モデルの出力を向上させることができます。追加の情報ソースの範囲は、LLMがトレーニングしていないインターネット上の新しい情報から、独自のビジネスコンテキスト、企業に属する機密の内部文書まで多岐にわたります。
RAGは質問に対する回答やコンテンツを生成するタスクなどに有用です。なぜなら、生成AIシステムが外部の情報ソースを利用して、より正確で文脈を意識した回答を生成することを可能にするからです。探索的検索手法(通常はセマンティック検索またはハイブリッド検索)を実装し、ユーザーの意図に応え、より関連性の高い結果を提供します。
検索拡張生成(RAG)について掘り下げ、このアプローチがどのように貴社独自のリアルタイムデータと生成AIモデルをリンクさせ、エンドユーザーエクスペリエンスと精度を向上させるのかについてご確認ください。
情報検索とは
情報検索(IR)とは、知識ソースやデータセットから関連する情報を検索し、抽出するプロセスを指します。これはインターネット上で検索エンジンを使って情報を探すこととよく似ています。クエリを入力すると、探している情報が含まれている可能性の高い文書やWebページをシステムが検索し、表示します。
情報検索には、大規模なデータセットを効率的にインデックスし、検索する手法が用いられます。これにより、利用できる膨大なデータプールから特定の必要な情報にアクセスしやすくなります。Web上の検索エンジンのみならず、IRシステムはデジタルライブラリ、文書管理システム、および各種の情報アクセスアプリケーションでよく使用されています。
AI言語モデルの進化
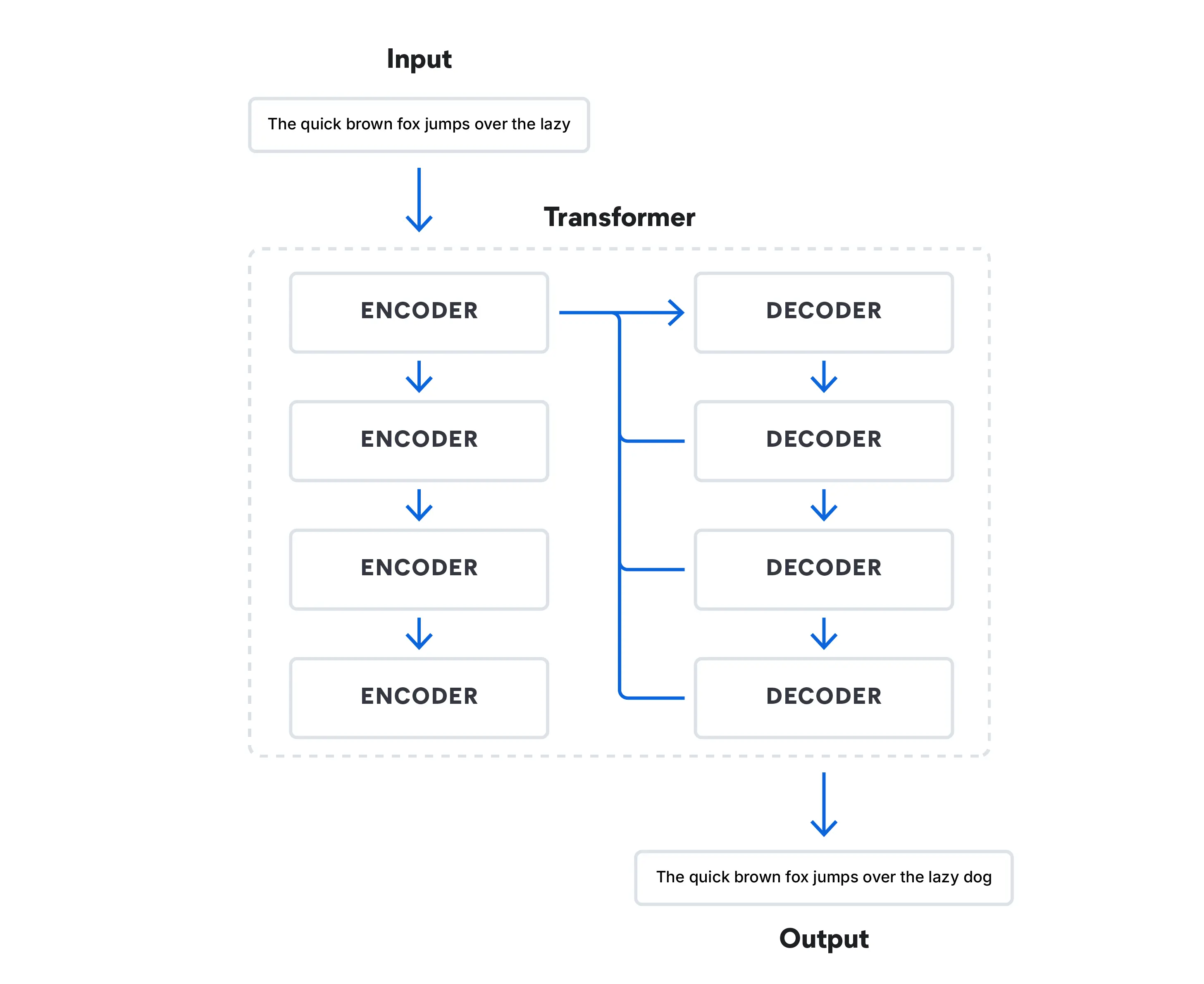
AI言語モデルは、長年にわたって大幅に進化してきました。
- 1950年代と1960年代、この分野は黎明期にあり、限られた言語のみを理解できるベーシックなルールベースシステムでした。
- 1970年代と1980年代に、エキスパートシステムが導入されました。これらは問題解決のために人間の知識をコード化しましたが、言語機能は非常に限られていました。
- 1990年代には統計的手法が登場し、言語タスクにデータ駆動型のアプローチが用いられました。
- 2000年代までには、機械学習技術、たとえばサポートベクターマシン(高次元空間でさまざまな種類のテキストデータを分類する)が登場しましたが、ディープラーニングはまだ初期段階にありました。
- 2010年代は深層学習の大きな転換期となりました。Transformerアーキテクチャーにモデルが入力シーケンスの異なる部分に焦点を当てて処理することを可能にするAttentionメカニズムが採用され、自然言語処理を変えました。
今日のTransformerモデルは、一連の単語の中で次に来る単語を予測することで人間の発話をシミュレートできる方法でデータを処理しています。こうしたモデルはこの分野に革命をもたらし、GoogleのBERT(Bidirectional Encoder Representations from Transformers)のようなLLMの台頭につながっています。
事前にトレーニングされた大規模なモデルと、特定のタスクのために設計された特殊なモデルが現在は用いられています。RAGのようなモデルは、生成AI言語モデルの範囲を標準的なトレーニングの限界を超えて拡張し、牽引し続けています。2022年にOpenAIが発表したChatGPTは、Transformerアーキテクチャーに基づくLLMとしておそらく最も有名なものです。その競合には、Google BardやMicrosoftのBing Chatといったチャットベースの基礎モデルがあります。MetaのLLaMa 2は消費者向けチャットボットではなく、オープンソースのLLMであり、LLMの仕組みに詳しい研究者が自由に利用できるようになっています。
RAGの仕組み
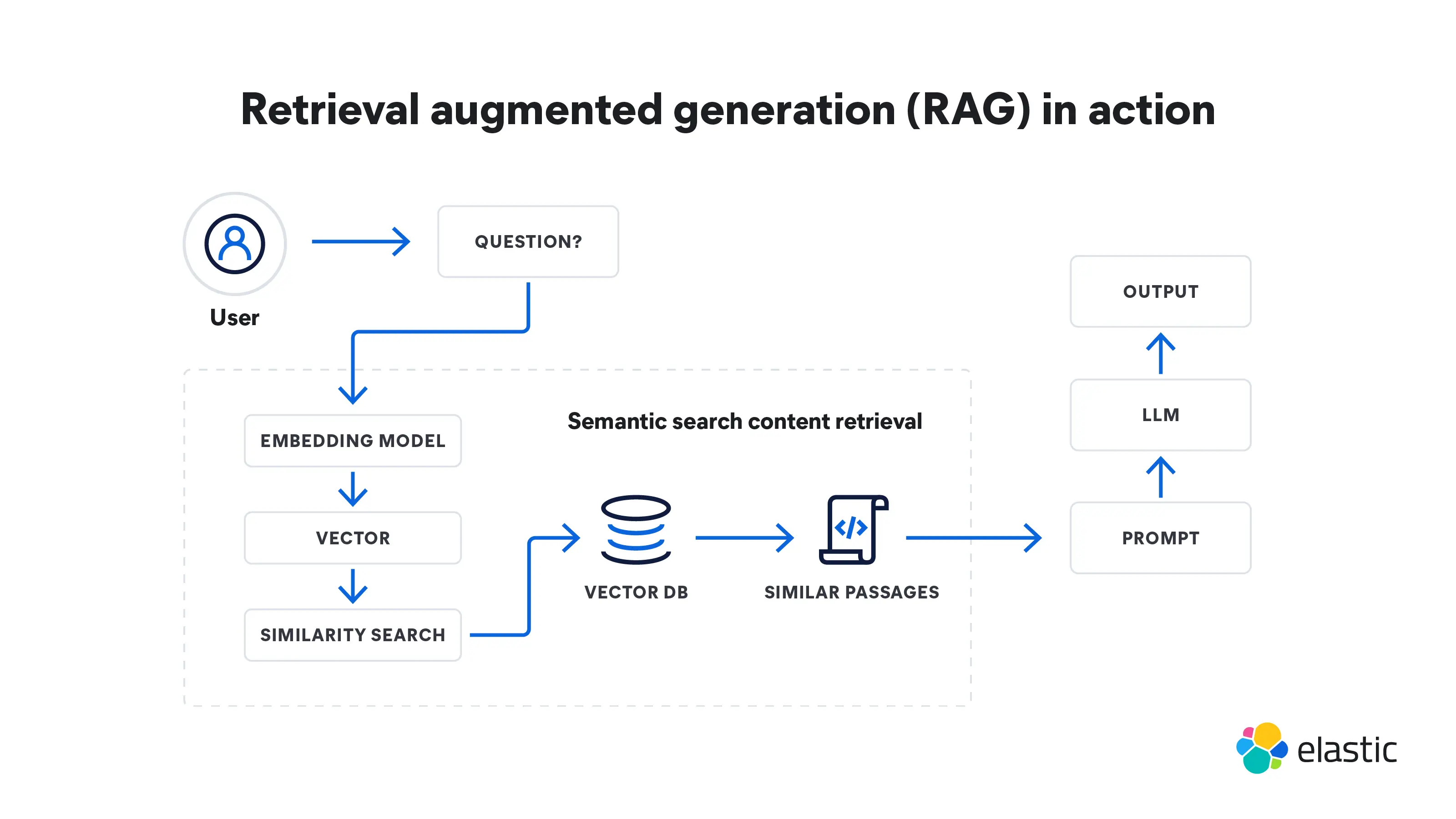
検索拡張生成は、検索から始まり、生成へとつながる多段階のプロセスです。その仕組みを以下に説明します。
検索
- RAGはクエリの入力から始まります。これはユーザーの質問、または詳細な回答を必要とするなんらかのテキストです。
- 検索モデルが、知識ベース、データベース、または外部ソースから、あるいは複数のソースから一度に適切な情報を取得します。モデルが検索する場所は、入力クエリが質問している内容によって異なります。この検索した情報は、モデルが必要とする事実やコンテキストの参照元となります。
- 検索した情報は、高次元空間のベクトルに変換されます。これらの知識ベクトルは、ベクトルデータベースに格納されます。
- 検索モデルは、入力クエリとの関連性に基づいて検索した情報をランク付けします。最もスコアの高い文書または文章が選択され、さらなる処理が行われます。
生成
- 次に、LLMなどの生成モデルが、検索した情報を使用してテキスト回答を生成します。
- 生成されたテキストは、文法的に正しく、筋が通っていることを確認するために、さらに後処理のステップを踏むことがあります。
- これらの回答は、検索モデルが提供した補足情報に基づいて生成されているため、全体的に正確性が高く、文脈上もより理にかなったものとなります。この機能は、公共のインターネットデータが不十分な特殊な領域では特に重要です。
RAGの利点
検索拡張生成には、単独で動作する言語モデルにはないメリットがいくつかあります。検索拡張生成がテキスト生成と回答を向上させた方法をいくつかご紹介します。
- RAGは外部参照を定期的に更新できるため、モデルが最新の事実や関連情報にアクセスできるようになっています。これにより、RAGが生成する回答に、問い合わせをしているユーザーに関連する可能性のある最新の情報が確実に組み込まれます。また、ドキュメントレベルのセキュリティを実装して、データストリーム内のデータへのアクセスを制御し、特定のドキュメントへのセキュリティ権限を制限することもできます。
- RAGは、必要な計算量とストレージが少ないため、より費用対効果の高いオプションです。つまり、自分でLLMを持つ必要もなければ、モデルの微調整に時間とお金を費やす必要もありません。
- 正確性を主張することと、それを実際に証明することは別です。RAGは、外部ソースを引用してユーザーに提供し、回答を裏付けることができます。ユーザーが選択すれば、そのソースを評価し、受け取った回答が正確であることを確認することができます。
- LLMを活用したチャットボットは、以前のスクリプト化された回答よりもパーソナライズされた回答を作ることができますが、RAGはさらにその回答を調整することができます。これは、意図を判断して回答を合成する際に、探索的検索手法(通常はセマンティック検索)を使って、コンテキストに基づいたさまざまなポイントを参照する機能があるからです。
- トレーニングされていない複雑なクエリに直面すると、LLMは時に「ハルシネーション」を見て不正確な回答をすることがあります。RAGは、関連するデータソースからの追加参照を基に回答することで、曖昧な問い合わせに対してより正確に回答することができます。
- RAGモデルは汎用性が高く、対話システム、コンテンツ生成、情報検索など、あらゆる自然言語処理タスクに適用できます。
- 人工のAIでは、どんなものでもバイアスが問題になり得ます。吟味された外部の情報ソースに依拠することで、RAGは回答におけるバイアスを軽減できます。
検索拡張生成とファインチューニングの違い
検索拡張生成とファインチューニングは、AI言語モデルのトレーニングにおける2つの異なるアプローチです。RAGが幅広い外部知識の検索とテキスト生成を組み合わせるのに対し、ファインチューニングは明確な目的のために狭い範囲のデータに焦点を当てます。
ファインチューニングでは、事前にトレーニングされたモデルを特殊なデータでさらにトレーニングし、タスクのサブセットに適応させます。これは新しいデータセットに基づいてモデルのウェイトとパラメータを修正することで、最初の事前トレーニングで得た知識を保持しながら、タスク固有のパターンを学習できるようにします。
ファインチューニングはあらゆる種類のAIに使えます。基本的な例は、インターネット上の猫の写真を識別するコンテキストで子猫を認識するように学習することです。言語ベースのモデルでは、ファインチューニングはテキスト生成に加えて、テキスト分類、感情分析、名前付きエンティティ認識などを補助できます。しかし、このプロセスには大変な時間とコストがかかる場合があります。RAGはこのプロセスをスピードアップし、計算量とストレージの必要性を減らして、これらのコストを統合します。
RAGは外部のリソースにアクセスできるため、Webや企業のナレッジベースからリアルタイムあるいは動的な情報を取り入れて、情報に基づいた回答を生成する必要があるタスクに特に有効です。ファインチューニングにはさまざまな強みがあります。目下のタスクが明確に定義されており、そのタスクのパフォーマンスだけを最適化することが目的であれば、ファインチューニングは非常に効率的です。どちらの手法も、タスクごとにLLMをゼロからトレーニングする必要がないというメリットがあります。
検索拡張生成の課題と限界
RAGには大きなメリットがある一方で、いくつかの課題や限界もあります。
- RAGは外部の知識に依存します。検索した情報が間違っていれば、不正確な結果を出す可能性があります。
- RAGの検索コンポーネントには、大規模な知識ベースやWebの検索が含まれており、計算コストが高く、時間がかかります。しかし、それでもファインチューニングよりは高速で低コストです。
- 検索と生成のコンポーネントをシームレスに統合するには、慎重な設計と最適化が必要であり、トレーニングやデプロイが難しくなる可能性があります。
- 外部ソースから情報を取得することで、機密データを取り扱う際にプライバシーの問題を引き起こす可能性があります。プライバシーおよびコンプライアンス要件の遵守により、RAGがアクセスできる情報源も制限される場合があります。ただし、これは特定のロールにアクセスとセキュリティ許可を与えることができるドキュメントレベルのアクセスによって解決することができます。
- RAGは事実の正確性をベースにしています。想像上のコンテンツや架空のコンテンツの生成に苦戦する可能性があり、創造的なコンテンツ生成における使用には限界があります。
検索拡張生成の今後の動向
検索拡張生成の今後の動向は、RAGテクノロジーをより効率的にし、さまざまなアプリケーションにわたり適応できるようにすることに焦点が当てられています。注目すべき動向をいくつかご紹介します。
パーソナライゼーション
RAGモデルは今後もユーザー固有の知識を取り入れて続けます。これにより、特にコンテンツ提案やバーチャルアシスタントのようなアプリケーションにおいて、よりパーソナライズされた回答を提供できるようになるでしょう。
カスタマイズ可能な動作
パーソナライゼーションに加えて、RAGモデルがどのように動作し、どのように回答するかをユーザー自身がよりコントロールできるようになり、求めている結果を得られやすくなるでしょう。
スケーラビリティ
RAGモデルは、現在よりもさらに膨大なデータとユーザーとのインタラクションを処理できるようになるでしょう。
ハイブリッドモデル
RAGと他のAI技術の統合(例:強化学習)により、さまざまなデータタイプやタスクを同時に処理できる、より多用途でコンテキストを意識したシステムが可能になるでしょう。
リアルタイムおよび低レイテンシーの導入
RAGモデルの検索速度と応答時間が向上するにつれて、迅速な対応を必要とするアプリケーション(チャットボットやバーチャルアシスタントなど)でより多く使用されるようになるでしょう。
2024年の技術的な検索トレンドの詳細こちらのウェビナーでは、ベストプラクティス、新たな手法、および2024年のトップトレンドが開発者に与える影響について解説していますので、ぜひご視聴ください。
Elasticsearchの検索拡張生成
Elasticsearchを使えば、生成AIアプリ、website、顧客、従業員エクスペリエンスのためのRAG対応検索を構築できます。Elasticsearchが提供する包括的ツールキットでは、以下のことが可能になります。
- 独自のデータやその他の外部知識ベースを保存・検索し、そこからコンテキストを引き出す
- テキスト検索、ベクトル検索、ハイブリッド検索、セマンティック検索など、さまざまな方法でデータから関連性の高い検索結果を生成する
- ユーザーにとってより正確な回答とエンゲージメントの高い体験を提供する
RAGに関するリソースを探索
- AI Playgroundについて知る
- RAG応用編
- Elasticsearch – RAG向けの最も関連性の高い検索エンジン
- LLMの選択:2024年版オープンソースLLM入門ガイド
- AI検索アルゴリズムを解説
- チャットボットの製作方法:AI主導の世界で開発者がすべきこと・すべきでないこと
- 2024年の技術トレンド:進化する検索と生成AI技術の現状
- プロトタイプ作成とLLMとの統合を迅速化
- 世界で最もダウンロードされているベクトルデータベース — Elasticsearch
- ChatGPTを徹底解説:AI検索を構築するためのさまざまな方法
- Retrieval vs. poison — Fighting AI supply chain attacks(検索vs毒 - AIサプライチェーン攻撃との戦い)