情報検索とは?
情報検索の略史
情報検索のルーツは、古代にまでさかのぼることができます。当時は、学術論文の索引付けやアルファベット表記など、情報を整理し保存するために図書館や文書館が設立されました。1800年代には、情報処理のためにパンチカードが使用されるようになり、1931年には、エマヌエル・ゴルトベルクが初めて電気機械式の文書検索装置の特許を取得し、成功を収めました。これは"統計機械"として知られ、フィルムに符号化されたデータを検索するために設計されたものです。
情報検索が科学的な学問分野として正式な形をとり始めたのは、20世紀半ば、近代的なコンピューターの発達に伴ってのことでした。初期の自動文書検索モデルを開拓したのは、ジェラルド・サルトンとハンス・ピーター・ルーンです。コーネル大学のサルトン教授と同僚たちは、1960年代にSMART情報検索システムを開発しました。このシステムは、用語-文書マトリックス、ベクトル空間モデル、関連性フィードバック、ロッキオ分類など、現代のIR技術や重要な概念の基礎を築いたと評価されています。
1970年代には、より高度な検索技術、確率モデル、完全に明確化されたベクトル処理のフレームワークが登場し、この分野は大きく発展しました。1990年代後半には検索エンジンが登場し、かつては学術機関や図書館の専売特許であったIRシステムやモデルが普及しました。
情報検索モデルの種類
情報検索モデルには、特定の課題に取り組み、関連情報を検索するプロセスを確立するために設計されたさまざまな種類があります。この分野の基盤を形成する古典的なモデル、伝統的なアプローチの限界に対処しようとする非古典的なモデル、そして機械学習や言語モデルのような高度な技術を統合した、さらに進んだ代替IRモデルがあります。一般的なレベルで最もよく使われる情報検索モデルには、以下のようなものがあります。
ブールモデル
最もシンプルな初期の情報検索モデルの1つであるブールモデルは、ブール論理に基づいており、AND、OR、NOTなどの演算子を使用してクエリ用語を結合します。文書は用語の集合として表現され、クエリは指定された条件に一致する文書を特定するために処理されます。ブールモデルはクエリの正確な一致には効果的ですが、関連性に基づいて文書をランク付けしたり、部分一致を抽出したりすることはできません。
ベクトル空間モデル
このモデルは、文書やクエリを多次元空間のベクトルとして表します。各次元が一意な用語に対応し、各次元の値が文書やクエリにおける用語の重要度と頻度を表します。クエリのベクトルと文書のベクトル間のコサイン類似度を計算することで、クエリに対する文書の関連性が決定付けられます。ベクトル空間モデルはブールモデルの欠点に対処するために開発されたもので、関連性のスコアに基づいてランク付けされた結果を提供することができ、テキスト検索で広く使用されています。
確率モデル
このモデルは、文書が与えられたクエリに対して適切であることの確率を推定します。適合性の確率を計算する際は、用語の頻度や文書の長さといった要素が考慮されます。大量のデータを扱う場合に特に有効です。このモデルは重み付きの統計で機能するため、ランク付けされた結果を提供するのに理想的です。
潜在的意味インデックス(LSI)
LSIは特異値分解(SVD)を使い、用語と文書間の意味的関係を捉えることができます。セマンティック検索と同様に、セマンティックインデックスも意図と文脈を利用し、たとえ正確な用語を共有していなくても、概念的に関連する文書を特定することができます。LSIはこの重要な機能により、テキスト本文中の単語の文脈的意味を抽出するのに有用です。
Okapi BM25
BM25は、確率的モデルの中でもよく使われる検索関連度ランク付け関数の1つです。検索エンジンが検索クエリに対する文書の適合性を推定するのに使われます。文書内の用語間の相互関係に関係なく、各文書内に出現するクエリ用語に基づいて文書群をランク付けし、異なる構成要素とパラメータを持つ多くのスコアリング関数で構成されています。BMは"ベストマッチング"を意味します。
情報検索が重要な理由とは?
情報化時代において、データはかつて想像もできなかった規模で、常に生成されています。情報にアクセスする有効な手段がなければ、データは事実上無用の長物となります。情報過剰のノイズが増大する中で、ユーザーが必要な関連情報を確実に入手できるようにするのがIRシステムです。
情報検索は、学術、eコマース、医療、防衛に至るまで、現代世界のほぼすべての産業と分野で重要な役割を果たしています。これは、企業レベルと個人レベル双方における意思決定、研究、知識発見を支援するヒューマンマシンインターフェイスです。ローカライズされたデスクトップ検索から世界のニュースの発見まで、あるいはゲノム研究からスパムフィルターまで、情報検索は私たちの生活のほぼすべての局面で不可欠なものとなっています。
検索エンジンは、正確な検索結果の提供のために情報検索モデルに依存しています。eコマースのプラットフォームは、ユーザーの嗜好や行動に基づいて商品を推薦するために情報検索モデルを利用しています。デジタルライブラリーは、ユーザーのリサーチを支援するために情報検索科学に依存しています。医療分野では、関連する患者記録、医学研究、治療プロトコルのデータベース検索をIRシステムが支援しています。また、法律の専門家は、大量の判例を探すために情報検索を利用しています。
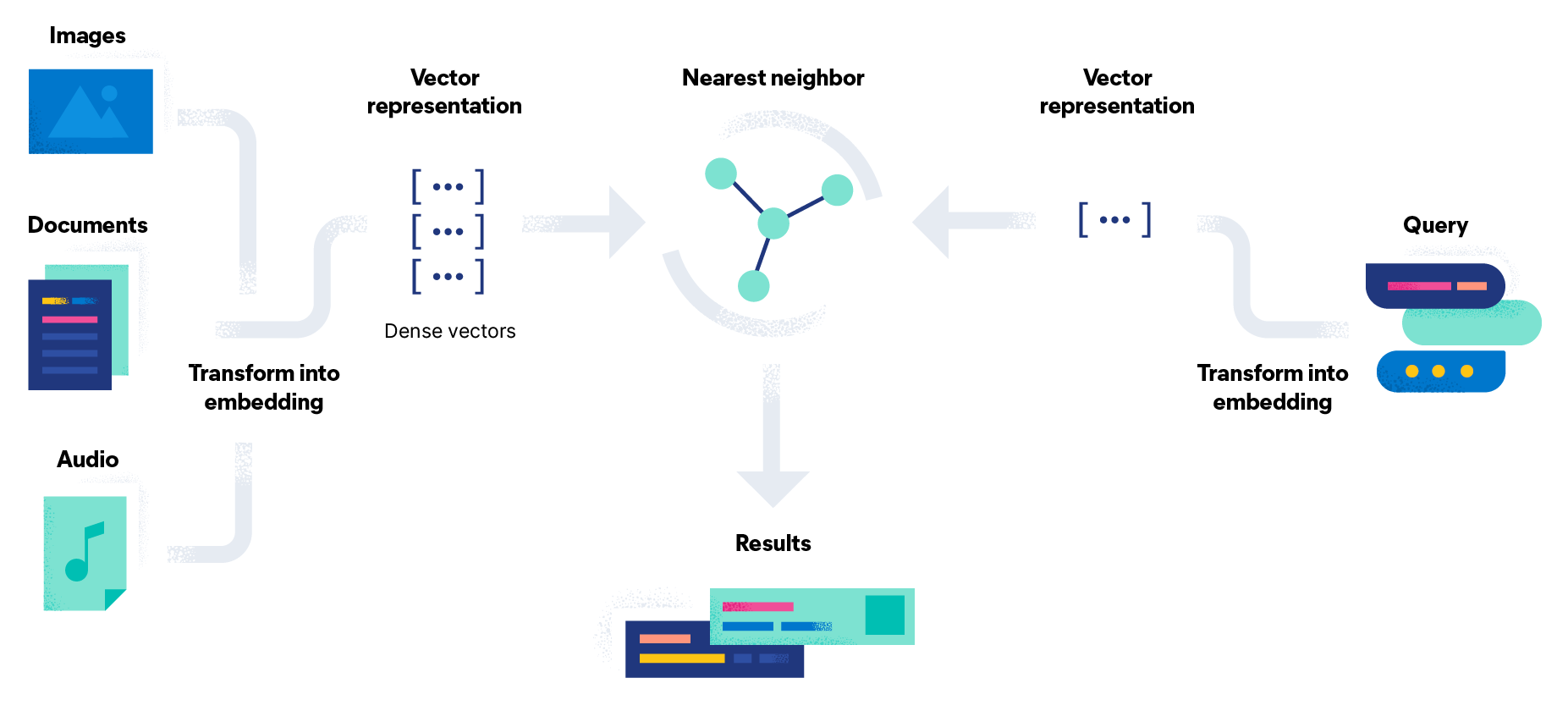
情報検索システムのしくみ
情報検索プロセスは通常、ユーザーがシステムに正式なクエリを入力し、情報の必要性を示したときに開始します。IRシステムは、コンテンツのコレクションや情報データベース内の文書のインデックスを作成します。テキスト文書、画像、音声、映像などのデータオブジェクトが処理され、関連する用語や代替データが抽出されるとともに、データ構造を使用して、それらのエンティティを効率的に格納・検索します。
ユーザーがクエリを送信すると、システムがそれを処理して関連用語を特定し、その重要性を判断します。システムは次に、クエリとの関連性に基づいて文書をランク付けします。多くの場合、IRモデルとアルゴリズムを使用して、コレクションまたはデータベース内のオブジェクトとクエリの一致度に基づいた数値スコアを計算します。多くのクエリは完全には一致せず、最も関連性の高い文書がランク付けされたリストとしてユーザーに提示されます。このランク付けされた結果が、情報検索サーチとデータベースサーチの重要な違いのひとつです。
情報検索システムの主な構成要素
情報検索システムの主な構成要素は以下の通りです。
文書のコレクション
システムが情報を検索できる文書の集合体。
インデックス作成コンポーネント
ソースデータと文書を処理してインデックスを作成し、それを含む文書に用語とデータをマッピングします。多くの場合、専用の最適化されたデータ構造になっています。
クエリプロセッサ
ユーザーのクエリとキーワードを分析し、インデックス化されたエンティティとのマッチングを準備します。
ランキングアルゴリズム
クエリに対する文書の適合性を判断し、スコアを割り当てます。BM25(Best Match 25)ランキングアルゴリズムが最も一般的で、用語の頻度を修正するアプローチにより、キーワードや繰り返される用語で文書が過度に飽和するのを回避できます。
ユーザーインターフェイス
UIは、ユーザーがシステムと対話し、クエリを送信し、結果が表示されるディスプレイのことです。ここでは、ユーザーのクエリに対する適合度に基づいて結果を調整することができる。UIによっては、検索された文書の関連性についてユーザーがフィードバックを提供できるしくみもあり、今後の検索の改善に役立てることができます。
情報検索モデルのメリット
情報検索モデルの重要な利点は以下の通りです。
- 効率的な情報アクセス:IRシステムは、何といっても人々の膨大な時間と労力を節約します。情報検索により、ユーザーは膨大な文書やデータを手作業で検索することなく、関連情報にすばやくアクセスできます。
- 知識の発見:情報検索は、データの意味を理解するための強力なツールです。IRによって、最初はわからないようなデータ内の傾向、パターン、関係を特定することができます。
- パーソナライゼーション:IRシステムの中には、ユーザーの嗜好や行動に基づいて、個々のユーザーに合った有意義な結果を提供するものもあります。
- 意思決定サポート:必要なときに最も適切な情報にアクセスできるため、専門家が十分な情報に基づいた意思決定を行えるようになります。
情報検索の課題と限界
情報検索は著しく進歩したものの、完璧であったことは一度もありません。以下のような既知の問題、課題、限界が残っています。
曖昧性 自然言語は本質的に曖昧性があり、ユーザーのクエリを正確に解釈することは困難です。曖昧性と不確実性の同様の問題は、特に画像や映像のようなオブジェクトのインデックス作成と評価プロセスに影響する恐れがあります。
関連性 関連性の判断は主観的なものであるため、ユーザーの文脈や意図によって異なる場合があります。価値と重要性を決定するために使用する基準も、個々のユーザーの特定のニーズを反映しない、不完全で一般的な基準に支配される可能性があります。
意味的なギャップ 検索システムは、テキスト表現と人間の理解とのギャップのために、コンテンツの深い意味を捉えることが困難な場合があります。情報やユーザーの表現が明確でないことが、IRを成功させる際の大きな障害となっています。AIによる高度な自然言語処理が、意味や曖昧さのギャップを埋めようと努めています。
スケーラビリティ データ量が増えるにつれて、効率的かつ効果的な検索とインデックス作成の維持がより複雑になり、より多くのリソースと演算能力が必要になります。
情報検索の今後の動向
最近の生成AIと機械学習におけるブレークスルーにより、現在の情報検索は、変革の時を迎えようとしているようです。
先進の機械学習技術は、ユーザーとのやり取りから学習し、変化する文脈、場所、嗜好に適応することで、すでに検索機能を強化しています。改善された自然言語処理とセマンティック分析が、ユーザーのクエリと文書コンテンツのより良い理解を生み出しています。検索システムもまた、増え続けるマルチメディアコンテンツをより効果的に扱えるように進化しています。
情報検索における生成AIのインパクトは、革命を起こす可能性を秘めています。私たちが使い慣れているランク付けされた検索結果リストでは、既存のリンクや文書をユーザー自身で分類して探しものを見つける必要がありますが、その代わりに質問への実質的な回答を受け取ることができるようになります。文脈が質問から質問へと引き継がれ、複雑で多段階の問い合わせが会話のように可能になり、人間の言語処理と意図の障壁はほとんど取り除かれます。私たちが自分で答えをつなぎ合わせるのではなく、検索エンジンが代わりにその作業をするようになります。検索エンジンは、情報を合成して特定のカスタマイズされた結果に落とし込みます。それはオリジナルコンテンツという形で、必要とするものを的確に提供し、そうでないものは提供しません。
「Deep dive into 2024 technical search trends(2024年の技術的な検索トレンドを読み解く)」。こちらのウェビナーでは、ベストプラクティス、新たな手法、および2024年のトップトレンドが開発者に与える影響について解説していますので、ぜひご視聴ください。
Elasticsearchの情報検索
Elasticは、Elastic Stackで提供している情報検索機能の向上に常に努めています。最新の検索モデルであるElastic Learned Sparse Encoderにより、事前学習済みの言語モデルによって、Elasticのすぐに使える検索機能を強化しています。また、真のワンクリックエクスペリエンスを実現するために、新しいElasticsearch Relevance Engineを統合しました。
Elasticsearchはさらに、優れた語彙検索機能と、ハイブリッド検索と呼ばれるコンセプトの、異なるクエリの結果を組み合わせるための豊富なツールを備えています。また、NLPとベクトル検索によるチャットボット機能の強化、テキスト埋め込み用サードパーティ製自然言語処理モデルのリリース、BEIRのサブセットを使用した性能評価も行っています。
情報検索のリソースをさらに見る
- Improving information retrieval in the Elastic Stack: Introducing Elastic Learned Sparse Encoder, our new retrieval model(Elastic Stackで情報検索を改善:新しい検索モデル、Elastic Learned Sparse Encoderの紹介)
- Improving information retrieval in the Elastic Stack:Steps to improve search relevance(Elastic Stackで情報検索を改善:検索関連性を向上させるステップ)
- Improving information retrieval in the Elastic Stack:Benchmarking passage retrieval(Elastic Stackで情報検索を改善:経路検索のベンチマーク)
- Improving information retrieval in the Elastic Stack:Hybrid retrieval(Elastic Stackで情報検索を改善:ハイブリッド検索)
- AI検索アルゴリズムの解説
次にやるべきこと
準備ができたら、ビジネスのデータから得られるインサイトを活用するための次の4つのステップに進みましょう。
- 無料トライアルを開始して、Elasticがビジネスにどのように役立つのかを実感してください。
- ソリューションのツアーで、Elasticsearchプラットフォームの仕組みと、ソリューションがニーズにフィットする仕組みを確認してください。
- 生成AIを企業に導入する方法を確認してください。
- 興味を持ってくれそうな人とこの記事を共有してください。メール、Twitter、Facebookで共有しましょう。