実践で学ぶBM25 - パート2:BM25のアルゴリズムと変数
この記事は、類似性ランキング(関連性)に関する3部構成の実践で学ぶBM25シリーズの、第2部にあたります。まだの方は、「パート1:How Shards Affect Relevance Scoring in Elasticsearch(Elasticsearchの関連性スコアリングにシャードが及ぼす影響)」からご覧ください。
BM25のアルゴリズム
ここでは、何が起きているのかを説明するために最小限必要な範囲で数学的な説明をします。BM25の式の構造がわかれば、何が起きているのかをある程度把握できるはずです。式全体を見てから、理解可能な要素に分解して見ていきましょう。
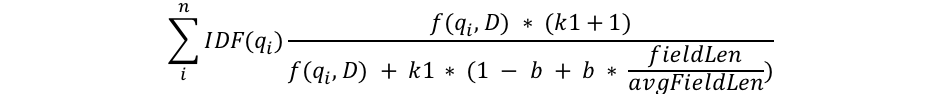
式を見てまず気付くのは、qi、IDF(qi)、f(qi,D)、k1、bといった共通の要素がいくつかあることと、フィールドの長さが何かの意味を持っていることです。それぞれについて解説します。
- qiは、i番目のクエリ単語を指します。
たとえば「shane」で検索したとすると、クエリ単語は1つしかないので、q0が「shane」になります。英語で「shane connelly」を検索したとすると、Elasticsearchにより空白文字が検知され、この検索ワードは2個の単語にトークン化されます。つまり、q0が「shane」、q1が「connelly」になります。これらのクエリ単語が方程式の他の部分に挿入され、合計されます。 - IDF(gi)は、i番目のクエリ単語の逆文書頻度です。
TF-IDFを扱ったことがある方なら、IDFの概念はご存じかもしれません。そうでなくても心配はいりません (ご存じない場合は、BM25ではTF-IDFとIDFのIDF式に違いがあることだけ抑えておいてください)。 式の中のIDF要素により、すべてのドキュメントにおける単語の出現頻度が測定され、頻出する単語に「ペナルティ」が課せられます。この目的のためにLucene/BM25で実際に使用される式は次のとおりです。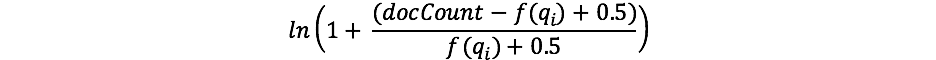
docCountは、シャード内で(search_type=dfs_query_then_fetchを使用している場合はシャード全体で)フィールドに値が存在するドキュメントの総数です。f(qi)は、i番目のクエリ単語が含まれるドキュメントの数です。この例では、「shane」は4つのドキュメント全部に出現するので、「shane」という単語について、IDF("shane")は次のように計算されます。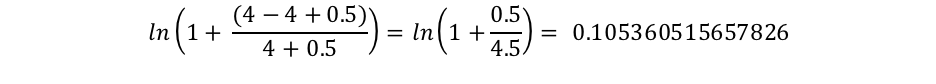
他方、「connelly」は2つのドキュメントのみに出現するので、IDF("connelly")は次のように計算されます。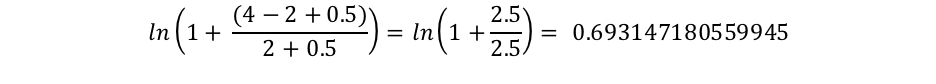
ご覧のように、比較的出現頻度が低い単語(4つのドキュメントからなるこの例のコーパスで「connelly」は「shane」よりも出現頻度が低い)は乗数が大きくなり、最終的なスコアに及ぼす影響も大きくなります。これは直感的に理解できます。「the」という単語は、ほぼすべての英語ドキュメントで出現します。したがってユーザーが「the elephant」を検索した場合に重要度が高く、スコアにより大きな影響を及ぼすべきなのは、ほぼすべてのドキュメントに含まれる「the」ではなく、「elephant」でしょう。
- 式を見ると、分母のところにfieldLen/avgFieldLenとあり、個々のフィールドの長さがフィールドの長さの平均で割られています。
平均的なドキュメントとの比較による、そのドキュメントの相対的な長さを表していると考えることができます。 ドキュメントが平均よりも長い場合は分母が大きく(スコアは低く)なり、平均よりも長い場合は分母が小さく(スコアは高く)なります。Elasticsearchにおけるフィールドの長さは、(文字数など別のものではなく)単語の数に基づいています。これはまさに、オリジナルのBM25論文に述べられているとおりですが、Elasticsearchではそこに特殊なフラグ(discount_overlaps)を加えて、必要に応じて同義語を扱えるようにしています。 ドキュメントに含まれる単語、とりわけクエリと一致しない単語が多いほど、ドキュメントのスコアは低くなるという発想です。これもまた、直感的に理解できます。Elasticの社名が1回だけ言及される300ページのドキュメントは、Elasticが1回だけ言及される短いツイートよりも、Elasticと関係がある可能性は低いでしょう。 - 式の分母には変数bがあり、先ほど取り上げたフィールドの長さの割合が乗じられています。bが大きいほど、平均的な長さと比較した各ドキュメントの長さが及ぼす影響は増幅されます。わかりやすくするため、bが0だと仮定してみると、長さの比率が及ぼす影響は完全に消え去り、ドキュメントの長さはスコアとまったく関係なくなります。Elasticsearchにおけるbのデフォルト値は0.75です。
- 最後に、スコアの構成要素のうち分子と分母の両方に登場するものが2つあります。k1とf(qi,D)です。上下にあるので、数式をさっと見ただけでその役割を理解するのは難しいですが、簡単に説明します。
- f(qi,D)は、「ドキュメントD内にi番目のクエリが出現する回数」です。 この例のすべてのドキュメントのf("shane",D)は1ですが、f("connelly",D)については違いがあります。ドキュメント3と4では1ですが、ドキュメント1と2では0です。仮に「shane shane」というテキストが含まれる5番目の ドキュメントがあるとすれば、そのドキュメントのf("shane",D)は2になります。先ほども述べたように、 分子と分母の両方にf(qi,D)と、次に説明する「k1」という特殊な因子があります。f(qi,D)については、ドキュメント内でクエリ単語が出現する回数が多いほど、スコアが高くなると考えることができます。これも直感的に理解できます。Elasticの社名が頻出するドキュメントの方が、Elasticの社名が1回しか現れないドキュメントよりも、Elasticに関連している可能性は高いでしょう。
- k1は、単語の出現頻度の飽和に関する特性を決定するための変数です。つまり、単一のクエリ単語が特定のドキュメントのスコアに及ぼす影響を制限します。制限は、漸近線に近付けることを通じて行われます。下のグラフでBM25とTF/IDFの違いをご覧ください。
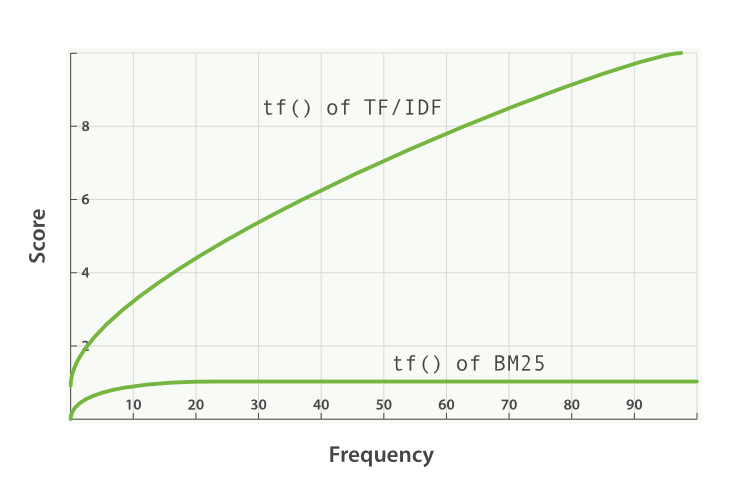
k1の値が大きくなったり小さくなったりすると、「tf() of BM25」曲線の勾配が変化します。これには、「余分に出現する単語により余分なスコアが追加される」しくみを変える効果があります。 k1は、平均的な長さのドキュメントについて、対象となる単語の最大スコアを半減する出現頻度の値と解釈されます。スコアに及ぼすtfの影響を示す曲線は、tf() ≤ k1の場合は急勾配になり、tf() > k1の場合は緩やかになります。
今回の例で言うと、「ドキュメントに追加された2つ目のshaneがスコアへに及ぼす影響を、1つ目のshaneや3つ目のshaneと比較してどの程度にするべきか」という問いに対する答えを、k1で制御しているということです。 k1が大きくなると、それぞれの単語のスコアは、その単語のインスタンスが増えるほど比較的大きな幅で増加し続けます。k1の値が0だと、IDF(qi)を除くすべての要素が無視されます。Elasticsearchにおけるk1のデフォルト値は1.2です。
新しい知識で検索結果を再確認する
peopleインデックスを削除して1つのシャードだけで再構成します。これにより、search_type=dfs_query_then_fetchを使用する必要がなくなります。学んだことを確認するため、3つのインデックスを設定してみましょう。1つ目のインデックスではk1の値を0にしてbの値を0.5に設定し、2つ目のインデックス(people2)ではbの値を0にしてk1の値を10に設定し、3つ目のインデックス(people3)ではbの値を1にしてk1の値を5に設定します。
DELETE people
PUT people
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0.5,
"k1": 0
}
}
}
}
}
PUT people2
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0,
"k1": 10
}
}
}
}
}
PUT people3
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 1,
"k1": 5
}
}
}
}
}
ここで、いくつかのドキュメントを3つのインデックスすべてに追加します。
POST people/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
POST people2/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
POST people3/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
ここで、以下を実行します。
GET /jp/people/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
peopleでは、すべてのドキュメントのスコアが0.074107975になります。これはk1が0という設定についての先ほどの説明と一致する結果です。つまり、検索単語のIDFだけがスコアに影響しています。
ではpeople2を見てみましょう。bは0、k1は10です。
GET /jp/people2/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
この検索結果から読み取るべきことが2つあります。
1つ目は、純粋に「shane」の出現回数に基づいてスコアが付けられているということです。ドキュメント1、2、3、4はどれも「shane」の出現回数は1回であり、それゆえスコアも0.074107975で共通しています。ドキュメント5には「shane」が2回出現するので、f("shane",D5) = 2となり、より高いスコア(0.13586462)になります。ドキュメント6については、f("shane",D6) = 3となるので、さらに高いスコア(0.18812023)が付けられます。これはpeople2のbを0に設定したことから直感的に予測される結果と一致します。長さ(ドキュメントに含まれる単語の総数)はスコアに影響せず、検索対象の単語の数と関連性のみがスコアに影響しています。
注目すべき点の2つ目は、これら6つのドキュメントのスコアの差は、一見すると非常に近く見えるにもかかわらず、実は非線形的だということです。
- 検索語が見つからない場合のスコアと、1回出現する場合のスコアの差は0.074107975です。
- 検索語が1回出現する場合のスコアと、2回出現する場合のスコアの差は0.13586462 - 0.074107975 = 0.061756645です。
- 検索語が2回出現する場合のスコアと、3回出現する場合のスコアの差は0.18812023 - 0.13586462 = 0.05225561です。
0.074107975は0.061756645とかなり近く、0.061756645は0.05225561とかなり近いですが、明らかに差は縮んでいます。これがほぼ線形に見えるのは、k1が大きいためです。少なくとも言えるのは、出現回数が増えてもスコアは線形的には増加しないということです。もし線形的に増加するなら、出現回数が増えるごとに同じ差でスコアが増えるはずです。この考え方については、people3をチェックしてから改めて検討します。
ではpeople3を見てみましょう。k1は5、bは1です。
GET /jp/people3/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
次の結果が得られました。
"hits": [
{
"_index": "people3",
"_type": "_doc",
"_id": "1",
"_score": 0.16674294,
"_source": {
"title": "Shane"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "6",
"_score": 0.10261105,
"_source": {
"title": "Shane Shane Shane Connelly Connelly Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "2",
"_score": 0.102611035,
"_source": {
"title": "Shane C"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "4",
"_score": 0.102611035,
"_source": {
"title": "Shane Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "5",
"_score": 0.102611035,
"_source": {
"title": "Shane Shane Connelly Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "3",
"_score": 0.074107975,
"_source": {
"title": "Shane P Connelly"
}
}
]
people3では、一致する単語(「shane」)の一致しない単語に対する割合が、関連性スコアリングに影響する唯一の要素になっています。3つの単語のうち1つだけが一致するドキュメント3は、全単語中ちょうど半分が一致するドキュメント2、4、5、6よりもスコアが低くなります。同様にドキュメント2、4、5、6は、すべての単語が検索語と一致するドキュメント1よりもスコアが低くなります。
people2と同じく、people3でも、スコアの高いドキュメントとスコアの低いドキュメントの間には「大きな」差を認めることができます。これもまた、k1の値が大きいためです。追加の演習として、people2やpeople3を削除し、たとえばk1を0.01にして改めて作成してみましょう。一致する単語が少ないドキュメント間のスコアの差が縮まっているはずです。bを0に、k1を0.01にしてみます。
- 検索語が見つからない場合のスコアと、1回出現する場合のスコアの差は0.074107975です。
- 検索語が1回出現する場合のスコアと、2回出現する場合のスコアの差は0.074476674 - 0.074107975 = 0.000368699です。
- 検索語が2回出現する場合のスコアと、3回出現する場合のスコアの差は0.07460038 - 0.074476674 = 0.000123706です。
このように、k1を0.01にすると、k1が5の時やk1が10の時と比べて、出現頻度が増えたときのスコアへの影響が急速に縮小することがわかります。4度目の出現によるスコアの増分は、3度目の出現の際よりもはるかに少なくなります。言い換えると、k1の値が小さいほど単語スコアは飽和しやすくなります。まさに予想したとおりです。
これらのパラメーターがさまざまなドキュメントセットに対して、どのような働きをするのかを理解できたでしょうか。この知識をもとに、次はbとk1の適切な値を選択する方法と、スコアを把握して各自のアプローチに反映させるためにElasticsearchが提供しているツールについて解説します。
シリーズは、「パート3:Considerations for Picking b and k1 in Elasticsearch(Elasticsearchでbとk1を選択する際の考慮事項)」に続きます。