Kibanaの計算式とタイムトラベルで、10個のよくある質問に回答
Kibanaを使えば、すべてのデータを最大限に活用して質問・回答したり分析フローに従うことが簡単にできるようになります。多くの場合、質問に答えるにはクエリされたデータに基づいて計算する必要があります。計算式を使うと、演算で複数の集計フィールドを組み合わせて独自のメトリックを作成できます。
また、データの時間と空間を移動して再実行することで、これまでの状況を確認し、現状についてのさらなるインサイトを把握できます。
以下のセクションに、10個の質問例を示しています。この質問には、Kibanaのダッシュボードデータや可視化マップ、計算式、タイムシフト、データの時間移動などを使って回答できます。ご自身のデータまたはKibanaのサンプルデータセットを使って、以下の質問に回答してみてください。ご質問やご不明点がおありの場合は、ディスカッションフォーラムをご覧ください。
質問例は次のとおりです。
- エラー率は上昇しているか?
- パフォーマンスは先週と比較してどうか?
- このデータは同業他社と比較してどうか?
- 平均値に最も影響を与えているものは?
- 過去と比較した生の損益は?
- 過去の実績に対する損益の割合は?
- データはどのようにして現在の状態になったか?
- 空間でダッシュボードをインタラクティブに探索するにはどうすればよいか?
- 単位当たりのメトリックは?
- 前期の業界固有の計算値(ネットプロモータースコアなど)は?
1)エラー率は上昇しているか?
比率は、全体合計に対する割合を示したり、"この集計方法で値が増えているように見えるのは、全体的にデータが増えたからというだけだろうか?"というような、生のカウント数では答えられない質問に回答するのに役立ちます。 比率は、データのサブセットをフィルタリングして、フィルタリングされていない全体合計と比較することで求めることができます。カスタム計算式で、このフィルターの役割を果たすKQLを使って比率を求めてみましょう。
以下の例は、ユニークユーザー全体に対してHTTPエラーコード(HTTP 200より大きいresponse.code)が表示されたユニークユーザーの比率を示しています。インサイトを得やすくするために、時間帯を行に、曜日を列にして可視化しています。データにこのようなフィールドがない場合は、いつでもランタイムフィールドとして追加できます。
unique_count(clientip, kql='response.keyword > 200') / unique_count(clientip)
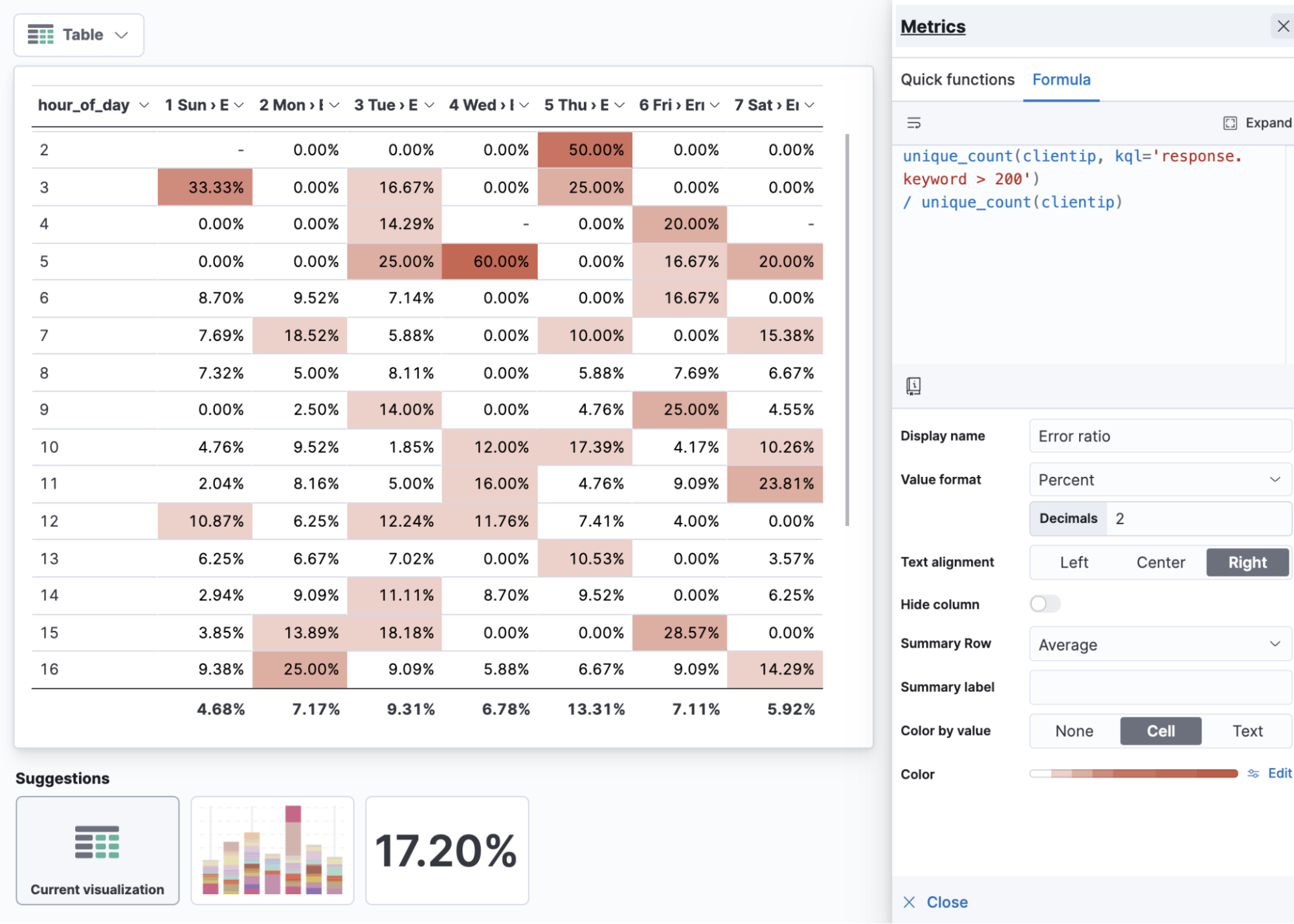
時間帯と曜日別のエラー率テーブル
可視化のプラクティス:比率
比率を可視化する際は、パーセント値の形式を適用します。メトリックの名前は「比率」にします。エラー率などを可視化する場合は、テーブルに時間帯と曜日を設定するとわかりやすくなります。比率の場合、平均値が列ごとのインサイトとなります(この場合は、曜日ごとの平均エラー率)。
2)パフォーマンスは先週と比較してどうか?
前期比は過去と比較した現在のパーセンテージを表し、100%は完全一致です。
この例は、前週と比べて帯域幅が14倍(1400%)に増加したことを示しています。
median(bytes) / median(bytes, shift='1w')
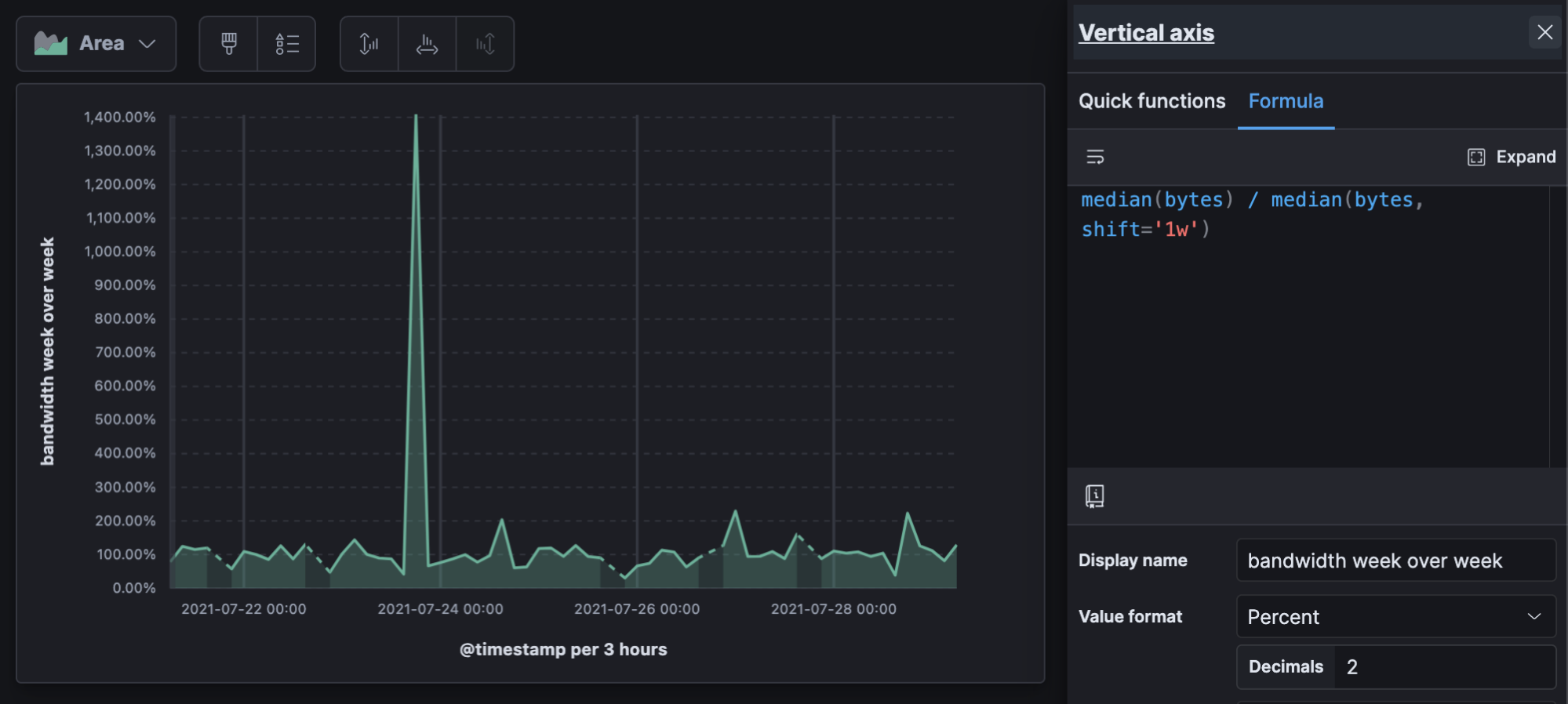
帯域幅の前週比の経時的変化
可視化のプラクティス:前期比
前期比は、ほぼすべてのデータの可視化に有効です。前期比を経時的に見ると、期間変化そのものが時間とともに変化しているかどうかを確認できます。この計算ではもう1つの割合が出力されるため、値の形式を忘れないようにしてください。折れ線グラフのデータがまばらな場合、"直線"の欠測値オプションを使えば見た目を損なわずに表示できます。
3)このデータは同業他社と比較してどうか?
全体合計を使うと、あらゆるデータを全体に対する割合として表示できるため比較しやすくなります。
以下の例では、「ceph」イメージが最も多くのデータを生成していることがわかります。カウント数を見るのではなく、割合として値を確認できます。
count() / overall_sum( count() )
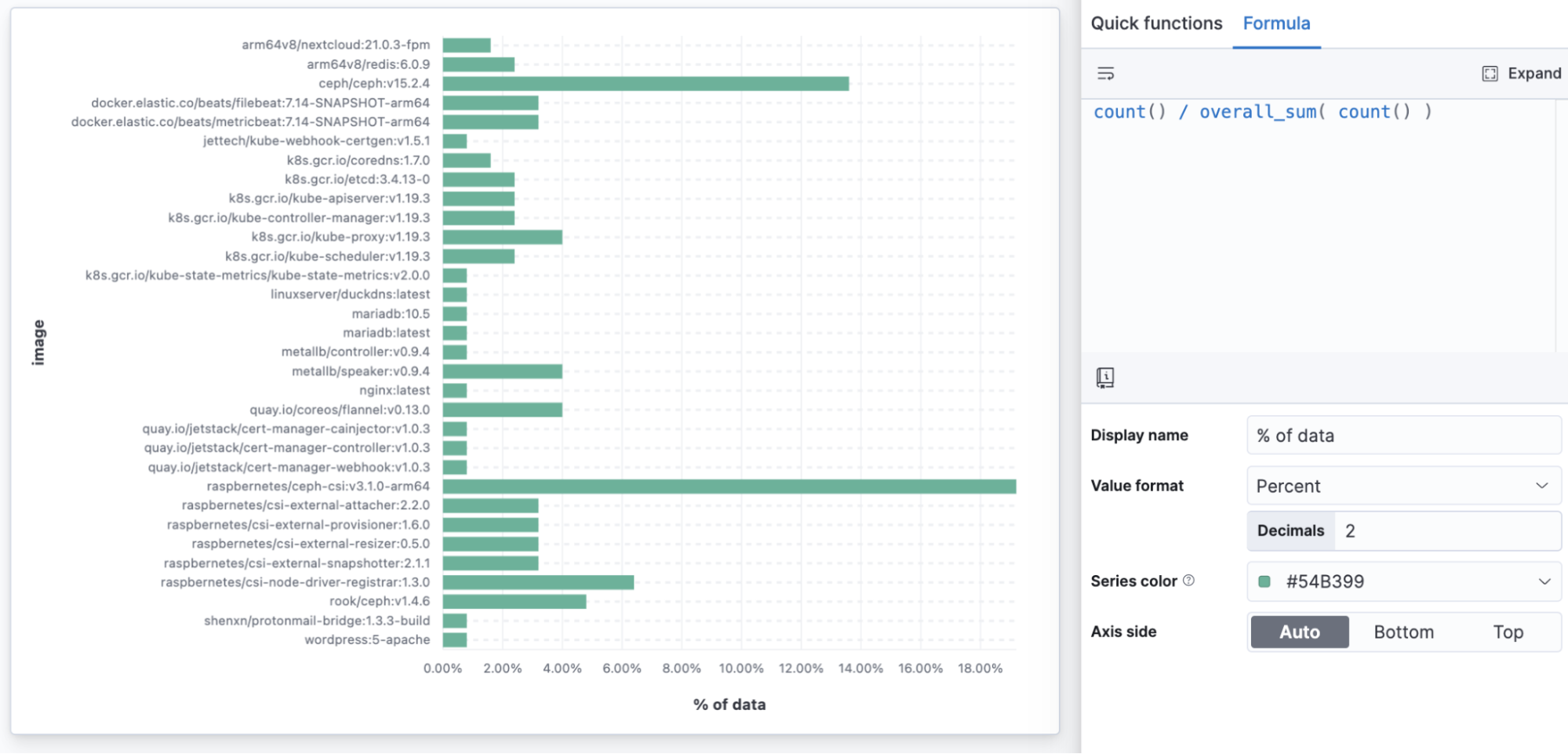
コンテナーイメージ別インフラデータの割合
可視化のプラクティス:全体合計の割合
計算式を使って全体合計の割合を求めると、データ全体に対する割合を可視化できます。これまではツリーマップや、円グラフ、ドーナツグラフでしか可視化できませんでした。横棒グラフを使って全体の割合を表示すると、すべてのデータポイントを読み取れるようになります。
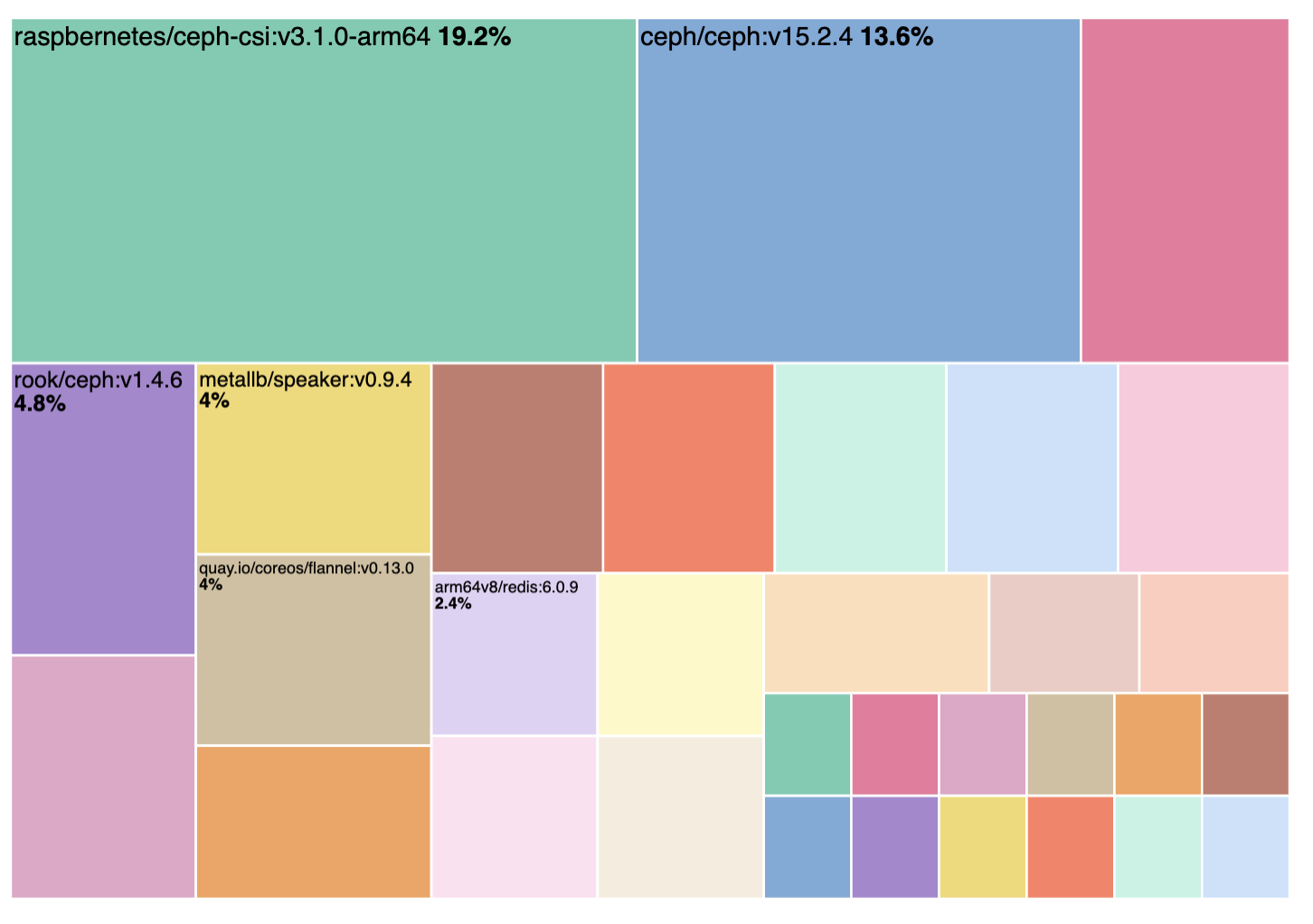 ツリーマップや、円グラフ、ドーナツグラフはデータの割合を自動生成するが見にくい
ツリーマップや、円グラフ、ドーナツグラフはデータの割合を自動生成するが見にくい
4)平均値に最も影響を与えているものは?
全体平均のような関数を使うと、全レポートのすべての値の平均値との比較計算を実行できます。
この例では、総売上高の全体平均よりも売上が多いカテゴリを確認できます。2つの衣料品カテゴリが全体平均を引き離しています。
sum(taxless_total_price) - overall_average(sum(taxless_total_price))
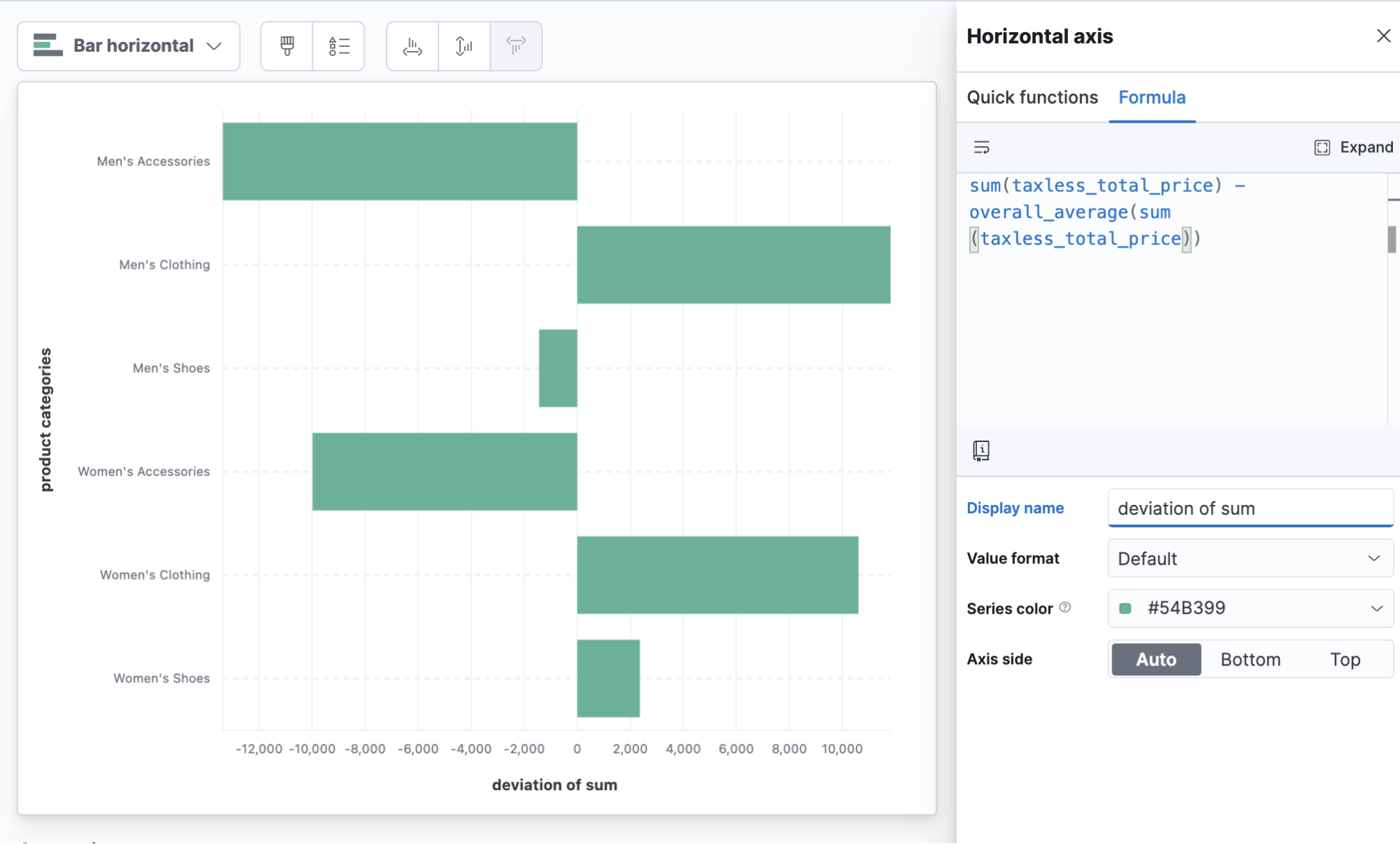
製品カテゴリの平均売上高からの偏差
可視化のプラクティス:偏差
ゼロを中心としてメトリックを可視化する場合は、横棒グラフを使用すると特にわかりやすくなります。必ず、メトリックを説明する名前を付けてください。
5)過去と比較した生の損益は?
タイムシフトの差では、時間を過去に戻して同じメトリックを比較します。現在の値から過去の値を差し引く場合に役立ちます。ゼロを中心にして可視化され、正の値は過去からどれだけ増加したかを表します。
ここでは、KubernetesノードにおけるCPUの平均使用率を6時間前と比較した例を示しています。この例では、除算を使ってCPUナノコアをコアに変換しています(注:計算式で変換するのではなく、メトリック変換として追加して他のユーザーがフィールドリストで確認できるようにするならランタイムフィールドが適しています)。
( average(kubernetes.node.cpu.usage.nanocores) - average(kubernetes.node.cpu.usage.nanocores, shift='6h') ) / 1000000000
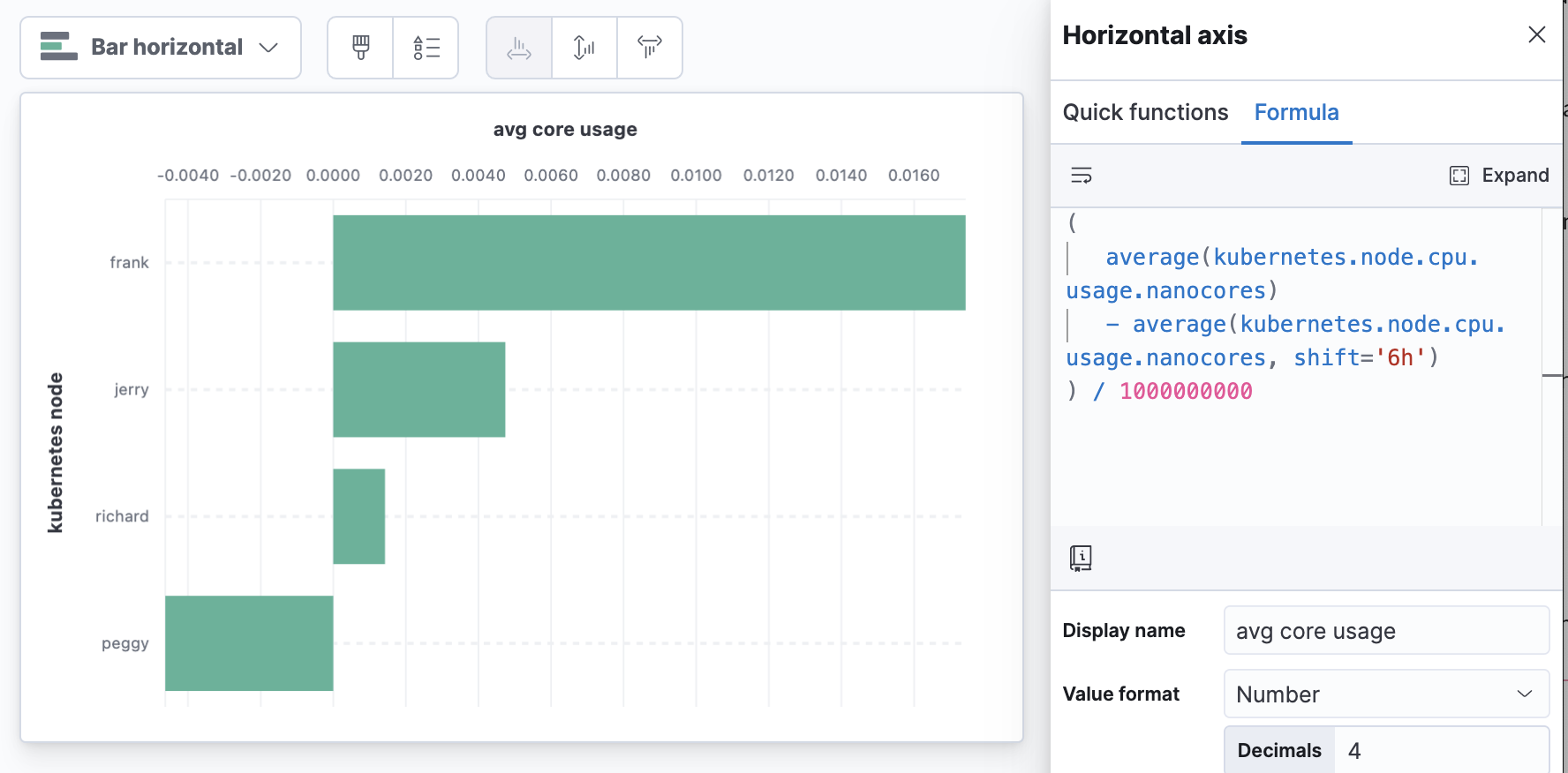
6時間前と比較したノードのCPUコア使用率の変化
可視化のプラクティス:タイムシフトの差と変化の単位
可視化した図の上部に軸を移動すると、大きい数値を重要な数値として可視化した図の上部に表示できます。
6)過去の実績に対する損益の割合は?
タイムシフトの差とは少し違った解釈として割合変化を使うと、生の差ではなく過去の値からの増加を割合として確認できます。成長率を説明する場合によく使われます。
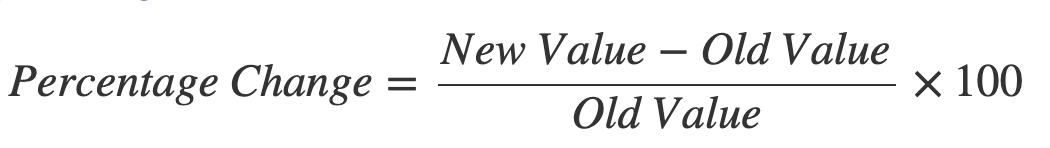
割合変化の計算例
以下の例は、KubernetesによるCPU使用率の割合変化を示しています。
( ( average(kubernetes.node.cpu.usage.nanocores) - average(kubernetes.node.cpu.usage.nanocores, shift='3d') ) / ( average(kubernetes.node.cpu.usage.nanocores, shift='3d') ) )
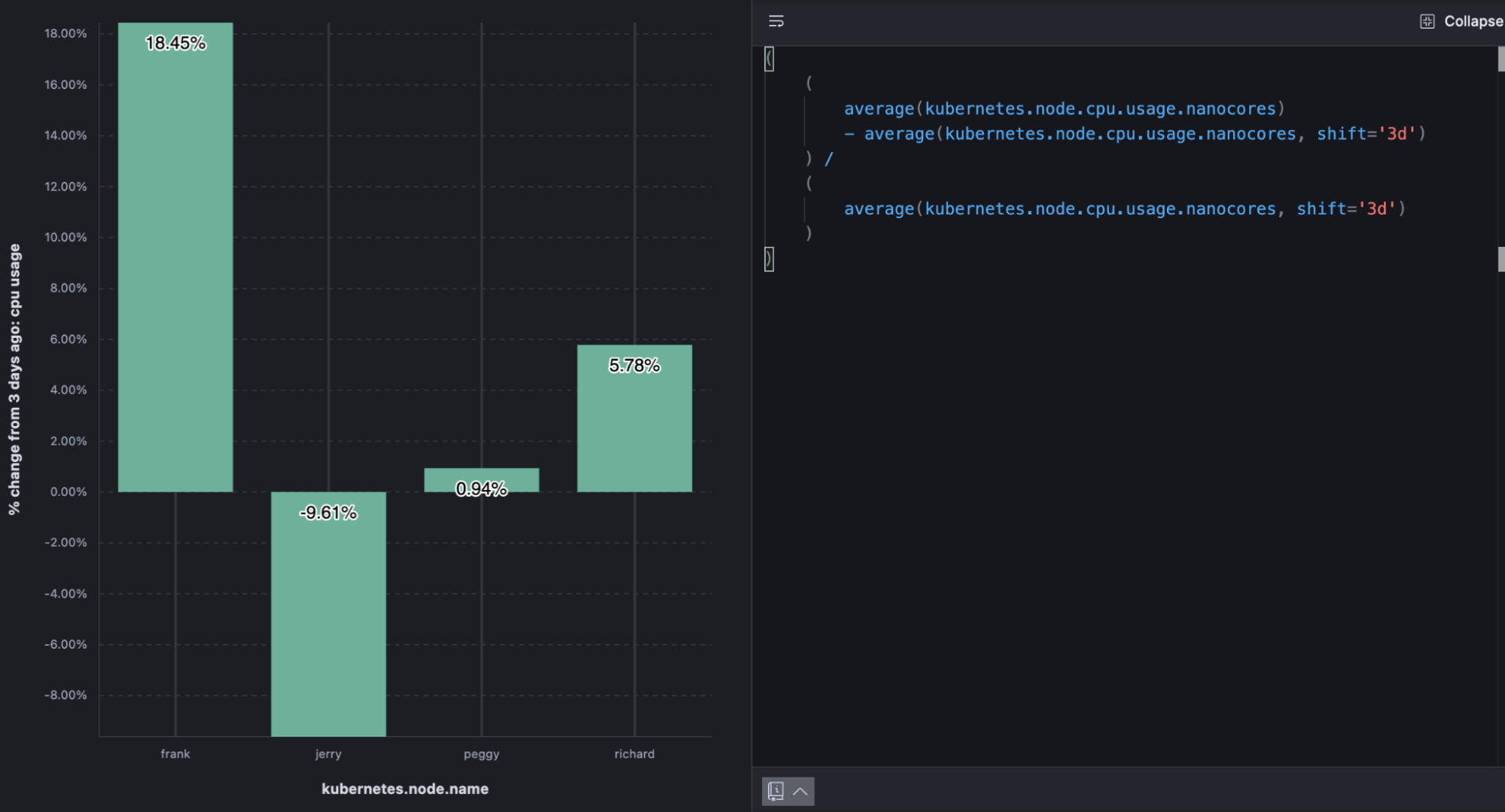
ノードのCPU使用率の3日前からの割合変化
可視化のプラクティス:割合変化
パーセント値の形式を使う場合、値に100を乗算する必要はありません。余裕があれば、値にラベルを付けると可視化したデータがわかりやすくなります。
7)データはどのようにして現在の状態になったか?
データの地理空間的な情報を把握するにはマップが最適です。しかし、マップはただのスナップショットにすぎず、15分前のデータなのか昨年のデータなのかは判別できません。実際には、1分単位または1日単位でマップを見るとさまざまなことがわかる場合があります。タイムスライダーを使うと、メトリックを再生して、時間の単位ごとに経時的変化を確認できます。これまでは検出されなかったパターンや、さらに調査が必要な異常が見つかる可能性があります。タイムスライダーによって、データがどのようにして今日の状況に至ったかが示されます。
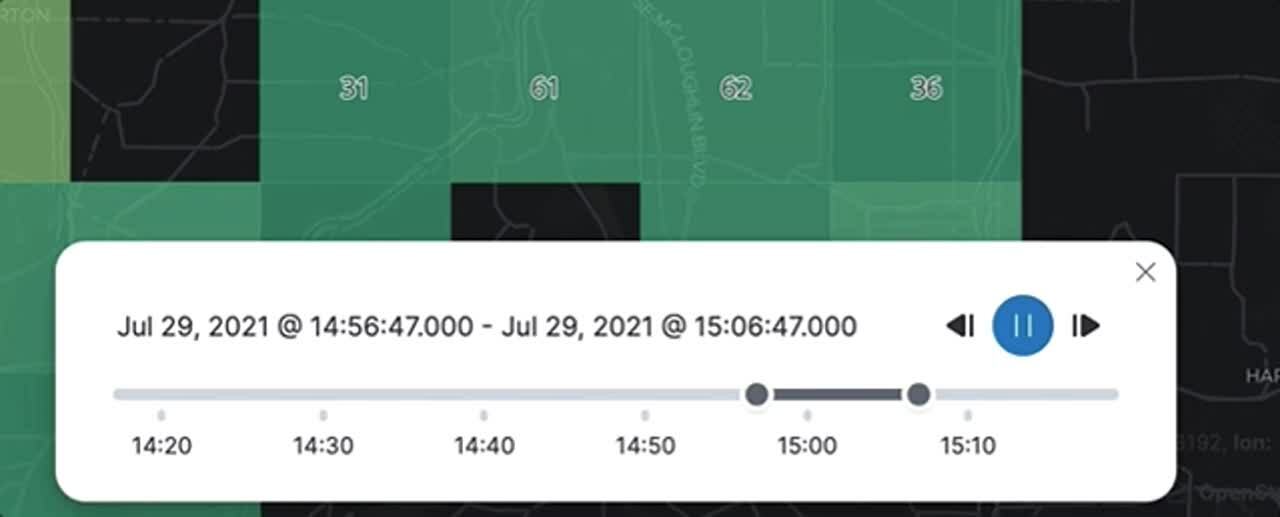
Elasticマップのタイムスライダーコントロール
8)空間でダッシュボードをインタラクティブに探索するにはどうすればよいか?
場所によって質問への回答が変わることがあります。他のユーザー向けにダッシュボードを作成する場合は、ダッシュボード全体のフィルターとしてマップを使用できるようにしてください。ダッシュボードで、マップの横に主要なメトリックを並べて可視化してみましょう。そうすると、空間でフィルタリングして非空間的なメトリックを可視化できます。また、比較や異常検知もパワフルに実行できます。
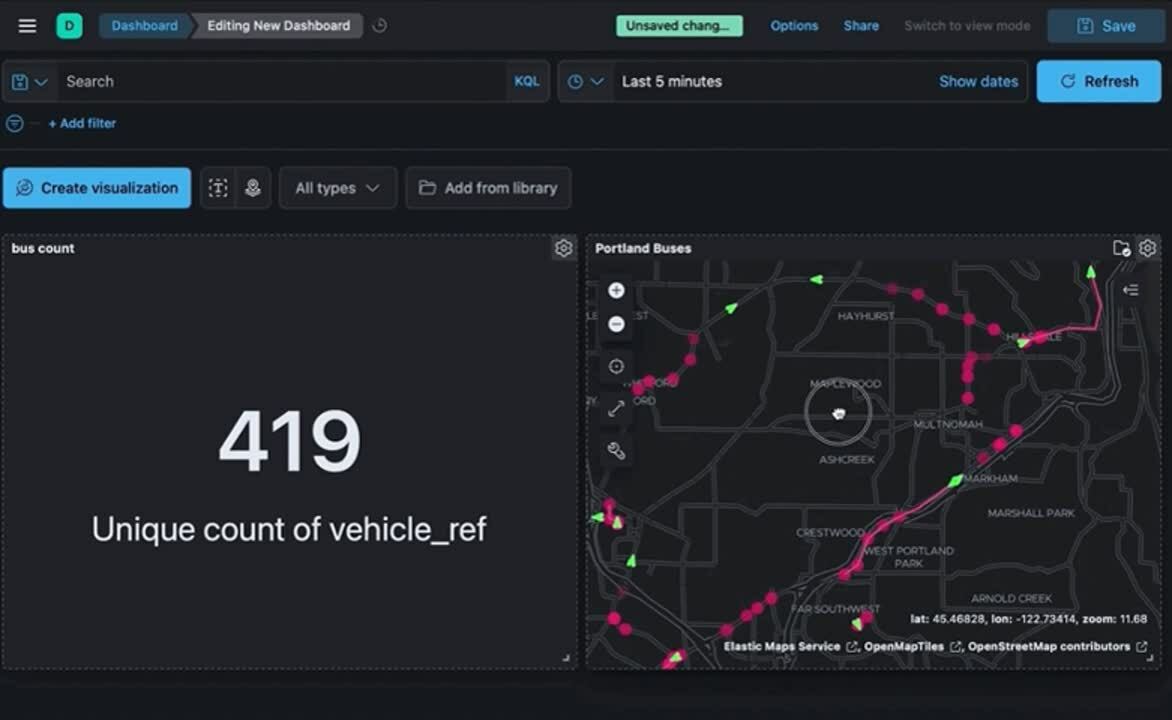
ダッシュボードのフィルターとしてのマップ
9)単位当たりの効率は?
カスタム計算式を使うことで、要約データを削減しつつ単位当たりのメトリックを取得できます。単位当たりのメトリックは、データの形式、メトリックの内容、データの"単位"に依存します。
以下の例は、一定間隔(30秒ごとなど)のクラウドメトリックテレメトリを示しています。メトリックの合計値(たとえばCPU使用率)とその合計値が示すイベントの数(リクエスト)を計算式で表すと、リクエスト当たりの平均CPU使用率を求められます。さらに、新しいメトリックの経時的なトレンドから負荷が増加したときの効率を把握することもできます。可視化したグラフを見ると、グラフの"谷"の部分は負荷が大きいときにシステムの効率が上がることを示しています。
average(kubernetes.pod.cpu.usage.node.pct) //平均メトリック counter_rate(max(nginx.stubstatus.requests)) //リクエスト当たり
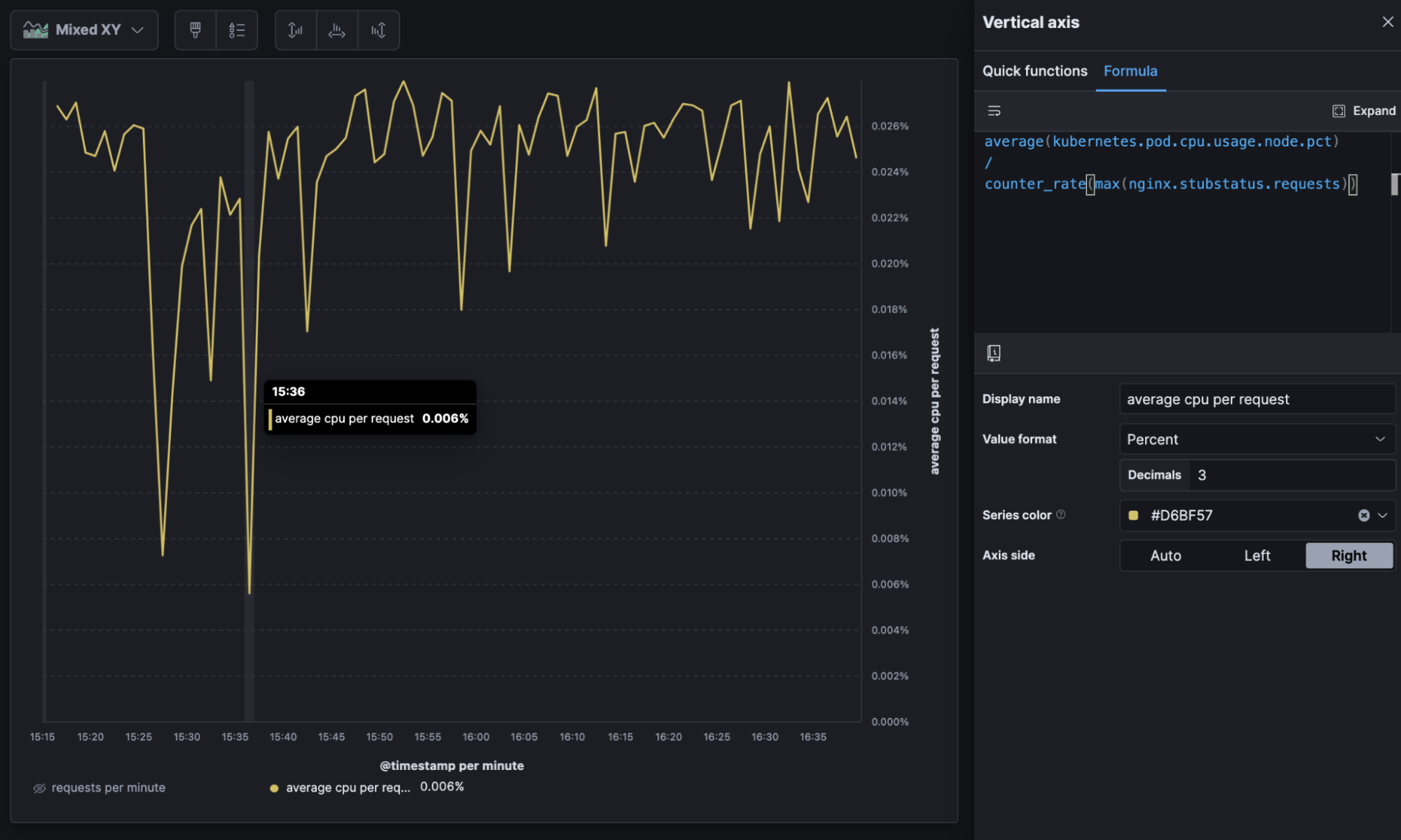 リクエスト当たりの経時的な平均CPU
リクエスト当たりの経時的な平均CPU
可視化のプラクティス:単位当たり
単位当たりのメトリックを使う場合は、使用する集約メトリックと単位の両方を必ずメトリック名に含めてください。計算式の単位を別のダッシュボードパネルや数列で可視化する際に便利です。
10)前期の業界固有の計算値(ネットプロモータースコアなど)は?
組織が、特定の方法で計算する固有のメトリックを採用しているとします。たとえば、データにアンケートの質問が含まれている場合、"ネットプロモータースコア"を計算したいと考える組織もあります。このスコアは、"プロモーター"(程度を尋ねる質問に対して上位2つのスコアを選択した人)の割合から"デトラクター"(程度を尋ねる質問に対して下位2つのスコアを選択した人)の割合を差し引くことによって求められ、-100%から100%までの1つのスコアで表されます。この種のビジネスメトリックは計算式としては単純です。計算式は報告時に計算されるため、メトリックや定義の進化に合わせて簡単に再定義できます。
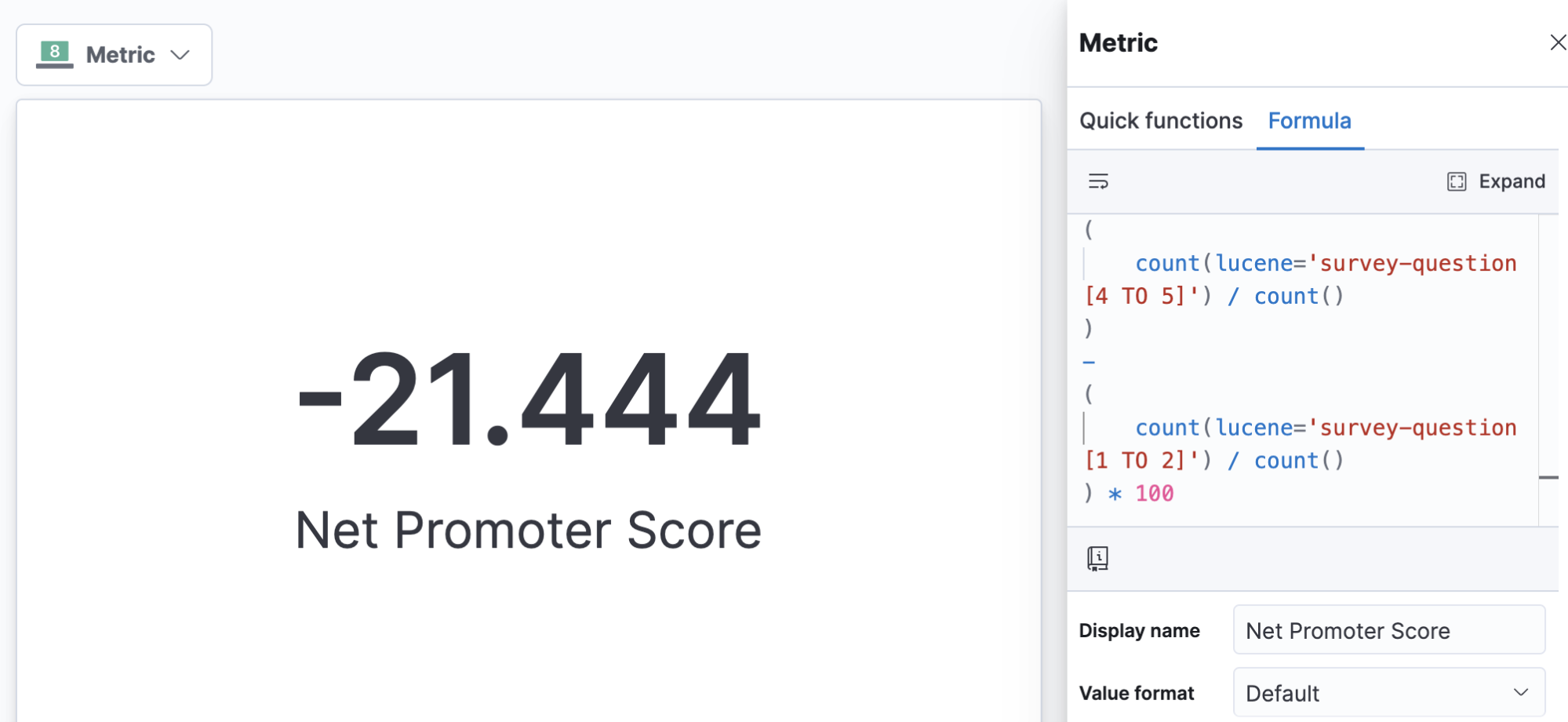
ネットプロモータースコアなど業界固有のメトリックの計算
データについてご質問がある場合
Elastic Cloudの無料トライアルに登録するか、Elastic Stackの無料のセルフマネージドバージョンをダウンロードして、ご自身で上記の例をお試しください。開始についてさらにご質問がある場合は、Kibanaフォーラムにアクセスするか、Kibanaのドキュメントガイドをご確認ください。