フィールドが多すぎる!Elasticsearchのマッピング爆発現象を防止する3つの方法


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
オブザーバビリティが実現されているシステムには、ログ、メトリック、トレースの3つが存在します。メトリックとトレースの構造は予測可能ですが、ログ(特にアプリケーションログ)は非構造化データであることが多く、ログを本当の意味で活用するためには収集して解析する必要があります。そのため、オブザーバビリティを達成するうえで最も高いハードルは、ログの管理であると言えます。
この記事では、Elasticsearchでログを管理するための3つの効果的な戦略をご紹介します。さらに詳しく知りたい方は、こちらの動画をご覧ください。
[関連記事:Elastic導入で向上するクラウドのデータ管理とオブザーバビリティ]
データに応じたElasticsearchの設定
クラスターでは、受け取るログのタイプをこちらで管理できない場合があります。あるログ分析プロバイダが、顧客のログの保存のために専用の予算を計上しており、ストレージを安全な場所に保管する必要があるとします(Elasticでも、同様のケースをコンサルティング部門で多数扱っています)。
検索に必要なフィールドを念のために顧客にインデックスしてもらうことはよくあります。そのような場合には、コストを減らして本当に重要なクラスターパフォーマンスに注力するために、次のテクニックがきっと役立つはずです。
最初に、問題の内容を整理しましょう。message、transaction.user、transaction.amountという3つのフィールドを持つ、次のJSONドキュメントについて考えてみます。
{
"message": "2023-06-01T01:02:03.000Z|TT|Bob|3.14|hello",
"transaction": {
"user": "bob",
"amount": 3.14
}
}
このようなドキュメントを対象としたインデックスのマッピングは、たとえば次のようなものが考えられます。
PUT dynamic-mapping-test
{
"mappings": {
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}
しかしElasticsearchを使用すると、事前にマッピングを指定しなくても新しいフィールドをインデックスできます。新しいデータを簡単に取り込めることも、Elasticsearchの使いやすさの1つです。そのため、次のように元のマッピングから逸脱した方法でインデックスしても問題ありません。
POST dynamic-mapping-test/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field with arbitrary data"
}
}
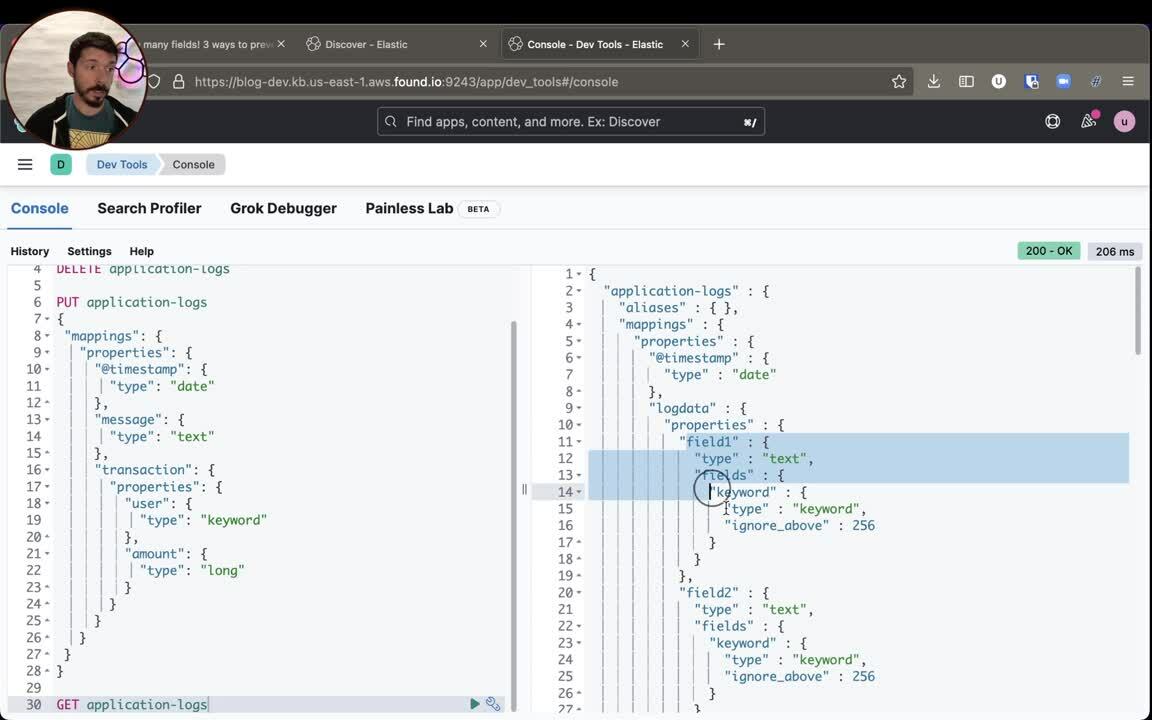
GET dynamic-mapping-test/_mappingを実行すると、結果として得られたインデックスの新しいマッピングを確認できます。新たに、transaction.field3がtextおよびkeywordとして追加されています。実際には、新しいフィールドが2つ追加されます。
{
"dynamic-mapping-test" : {
"mappings" : {
"properties" : {
"transaction" : {
"properties" : {
"user" : {
"type" : "keyword"
},
"amount" : {
"type" : "long"
},
"field3" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"message" : {
"type" : "text"
}
}
}
}
}
よろしいですね。ただ、これにより新たな問題が生じます。Elasticsearchに送られるデータを管理できない場合、マッピング爆発と呼ばれる問題が起きやすくなるのです。サブフィールド、さらにサブサブフィールドは無制限に作成できます。サブフィールドも同じ2つのタイプ、つまりtextとkeywordを持つため、次のようになります。
POST dynamic-mapping-test/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field",
"field4": {
"sub_user": "a sub field",
"sub_amount": "another sub field",
"sub_field3": "yet another subfield",
"sub_field4": "yet another subfield",
"sub_field5": "yet another subfield",
"sub_field6": "yet another subfield",
"sub_field7": "yet another subfield",
"sub_field8": "yet another subfield",
"sub_field9": "yet another subfield"
}
}
}データ構造は、データの検索可能性と集約可能性を維持できるように作成されるため、このようなフィールドを格納するためにRAMとディスク容量が浪費されることになります。このようなフィールドは、今後まったく使用されない可能性もあります。検索のために必要になる場合に備えて「念のために」作成されるだけなのです。
コンサルティングでインデックスの最適化を依頼された場合、最初のステップで、インデックス内のすべてのフィールドの使用状況を調査して、本当に検索されているフィールドと、リソースの無駄にしかならないフィールドを特定します。
戦略#1:厳密さを求める
Elasticsearchに格納されるログの構造とログの格納方法を完全に管理する必要がある場合には、明確なマッピング定義を定めておき、その定義から逸脱した情報が格納されないようにします。
トップレベルフィールドまたは一部のサブフィールドでdynamic: strictを使用することで、mappings定義の内容と一致しないドキュメントを却下し、事前に定義されたマッピングに従うことを送信者に強制します。
PUT dynamic-mapping-test
{
"mappings": {
"dynamic": "strict",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}その後、次のようにフィールドを追加してドキュメントをインデックスすると、
POST dynamic-mapping-test/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field"
}
}
}次の結果が返されます。
{
"error" : {
"root_cause" : [
{
"type" : "strict_dynamic_mapping_exception",
"reason" : "mapping set to strict, dynamic introduction of [field3] within [transaction] is not allowed"
}
],
"type" : "strict_dynamic_mapping_exception",
"reason" : "mapping set to strict, dynamic introduction of [field3] within [transaction] is not allowed"
},
"status" : 400
}マッピングに含まれるものだけを格納することが絶対的な方針である場合、この戦略によって、事前に定義されたマッピングに従うことを送信者に強制します。
戦略#2:厳密すぎないようにする
"dynamic": "false"を使用することで、処理の柔軟性をやや高めて、ドキュメントが期待される形式に厳密に一致していなくてもドキュメントを合格させることができます。
PUT dynamic-mapping-disabled
{
"mappings": {
"dynamic": "false",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}この戦略では、到着したドキュメントをすべて承認しますが、マッピングで指定されたフィールドのみをインデックスします。追加フィールドは検索できなくなるだけです。つまり、新しいフィールドによってRAMが浪費されなくなりますが、ディスク容量は消費されます。依然として、このフィールドは検索のhitsで見ることができ、これにはtop_hits集約が含まれます。しかし、このフィールドの検索や集約はできません。そのコンテンツを格納するデータ構造体が作られていないためです。
この戦略を全体に適用する必要はありません。ルートをstrictとし、サブフィールドで新しいフィールドをインデックスすることなく受け入れることもできます。詳細については、「内部オブジェクトのdynamicの設定(Setting dynamic on inner objects)」を参照してください。
PUT dynamic-mapping-disabled
{
"mappings": {
"dynamic": "strict",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"dynamic": "false",
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}戦略#3:ランタイムフィールド
Elasticsearchはschema on readとschema on writeの両方をサポートしますが、それぞれ注意点があります。dynamic:runtimeを使用する場合、新しいフィールドはランタイムフィールドとしてマッピングに追加されます。マッピングで指定されているフィールドがインデックスされ、追加フィールドはクエリ時間にのみ検索可能/集約可能となります。つまり、新しいフィールドで事前にRAMが浪費されることはありませんが、データ構造体がランタイムで作成されるため、クエリ応答が遅くなるというデメリットが生じます。
PUT dynamic-mapping-runtime
{
"mappings": {
"dynamic": "runtime",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}大きなドキュメントをインデックスしてみましょう。
POST dynamic-mapping-runtime/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field",
"field4": {
"sub_user": "a sub field",
"sub_amount": "another sub field",
"sub_field3": "yet another subfield",
"sub_field4": "yet another subfield",
"sub_field5": "yet another subfield",
"sub_field6": "yet another subfield",
"sub_field7": "yet another subfield",
"sub_field8": "yet another subfield",
"sub_field9": "yet another subfield"
}
}
}GET dynamic-mapping-runtime/_mappingを実行すると、大きなドキュメントをインデックスする際にマッピングが変更されることが示されます。
{
"dynamic-mapping-runtime" : {
"mappings" : {
"dynamic" : "runtime",
"runtime" : {
"transaction.field3" : {
"type" : "keyword"
},
"transaction.field4.sub_amount" : {
"type" : "keyword"
},
"transaction.field4.sub_field3" : {
"type" : "keyword"
},
"transaction.field4.sub_field4" : {
"type" : "keyword"
},
"transaction.field4.sub_field5" : {
"type" : "keyword"
},
"transaction.field4.sub_field6" : {
"type" : "keyword"
},
"transaction.field4.sub_field7" : {
"type" : "keyword"
},
"transaction.field4.sub_field8" : {
"type" : "keyword"
},
"transaction.field4.sub_field9" : {
"type" : "keyword"
}
},
"properties" : {
"transaction" : {
"properties" : {
"user" : {
"type" : "keyword"
},
"amount" : {
"type" : "long"
}
}
},
"message" : {
"type" : "text"
}
}
}
}
}新しいフィールドは、通常のキーワードフィールドと同様に検索可能になりました。最初のドキュメントをインデックスする際にデータタイプが推定されますが、動的なテンプレートを使用してこれを制御することもできます。
GET dynamic-mapping-runtime/_search
{
"query": {
"wildcard": {
"transaction.field4.sub_field6": "yet*"
}
}
}次の結果が得られます。
{
…
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"hits" : [
{
"_source" : {
"message" : "hello",
"transaction" : {
"user" : "hey",
"amount" : 3.14,
"field3" : "hey there, new field",
"field4" : {
"sub_user" : "a sub field",
"sub_amount" : "another sub field",
"sub_field3" : "yet another subfield",
"sub_field4" : "yet another subfield",
"sub_field5" : "yet another subfield",
"sub_field6" : "yet another subfield",
"sub_field7" : "yet another subfield",
"sub_field8" : "yet another subfield",
"sub_field9" : "yet another subfield"
}
}
}
}
]
}
}このように、取り込むドキュメントのタイプがわからない場合、この戦略が有効であることは明らかです。ランタイムフィールドは、パフォーマンスとマッピングの複雑さの絶妙なバランスを実現できる、手堅いアプローチであると言えます。
Kibanaとランタイムフィールドの使用に関する注意事項
Kibanaで検索バーを使って検索を実行するときに、フィールドを指定しない場合(たとえば、「message: hello」ではなく「hello」とだけ入力する)、すべてのフィールドがマッチし、宣言済みのすべてのランタイムフィールドが含まれます。おそらくこのような挙動が望まれることはないので、インデックスでは動的な設定index.query.default_fieldを使用する必要があります。マッピングされたフィールドのすべて、または一部にこれを設定し、ランタイムフィールドは明示的にクエリされるままにします(例:"transaction.field3: hey")。
最終的に完成したマッピングは、次のようになります。
PUT dynamic-mapping-runtime
{
"mappings": {
"dynamic": "runtime",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
},
"settings": {
"index": {
"query": {
"default_field": [
"message",
"transaction.user"
]
}
}
}
}最適な戦略の選択
戦略にはそれぞれメリットとデメリットがあるため、最適な戦略はユースケースに応じて決めることになります。以下に、ニーズに合わせて最適な戦略を選ぶためのまとめをご紹介します。
|
戦略 |
メリット |
デメリット |
|
#1 - strict |
格納されたドキュメントは、マッピングに準拠していることが保証される |
マッピングで宣言されていないフィールドがドキュメントに含まれている場合、そのドキュメントは却下される |
|
#2 - dynamic: false |
格納されたドキュメントには任意の数のフィールドを含めることができるが、リソースを利用できるのはマッピングされたフィールドのみ |
マッピングされていないフィールドを検索や集約に使用することはできない |
|
#3 - ランタイムフィールド |
#2のすべてのメリット ラインタイムフィールドは、Kibanaでも他のフィールドと同様に使用できる |
ラインタイムフィールドにクエリを実行する場合、検索の応答が比較的遅くなる |
Elastic Stackが本当に得意とするのは、オブザーバビリティです。数年分の金融取引情報を安全に格納しつつ、影響を受けたシステムを追跡することや、毎日発生する数テラバイトのネットワークメトリックを取り込むことが必要でも、10倍の速度でオブザーバビリティを実施でき、コストも数分の一に抑えることができます。
Elasticオブザーバビリティを導入してみませんか?最良のソリューションはクラウドにあります。今すぐ、Elastic Cloudの無料トライアルを始めましょう。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷