Downsampling a time series data stream
editDownsampling a time series data stream
editDownsampling provides a method to reduce the footprint of your time series data by storing it at reduced granularity.
Metrics solutions collect large amounts of time series data that grow over time.
As that data ages, it becomes less relevant to the current state of the system.
The downsampling process rolls up documents within a fixed time interval into a
single summary document. Each summary document includes statistical
representations of the original data: the min, max, sum and value_count
for each metric. Data stream time series dimensions
are stored unchanged.
Downsampling, in effect, lets you to trade data resolution and precision for storage size. You can include it in an index lifecycle management (ILM) policy to automatically manage the volume and associated cost of your metrics data at it ages.
Check the following sections to learn more:
How it works
editA time series is a sequence of observations taken over time for a specific entity. The observed samples can be represented as a continuous function, where the time series dimensions remain constant and the time series metrics change over time.
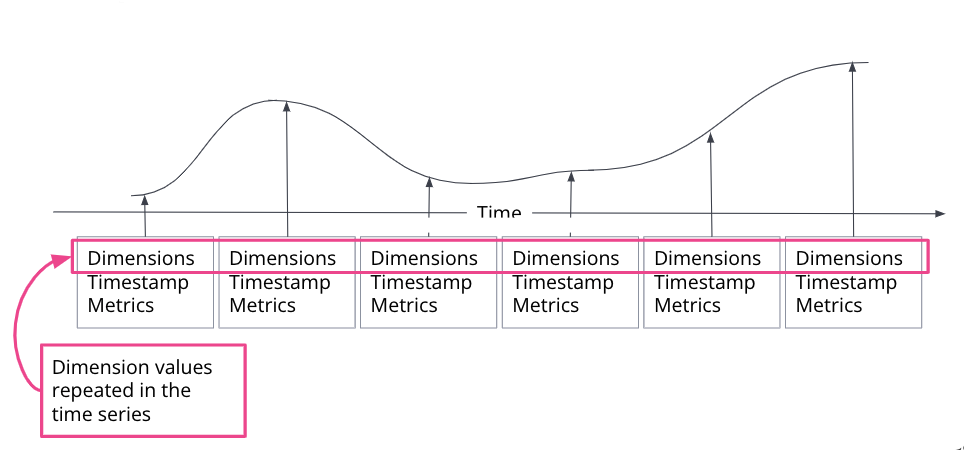
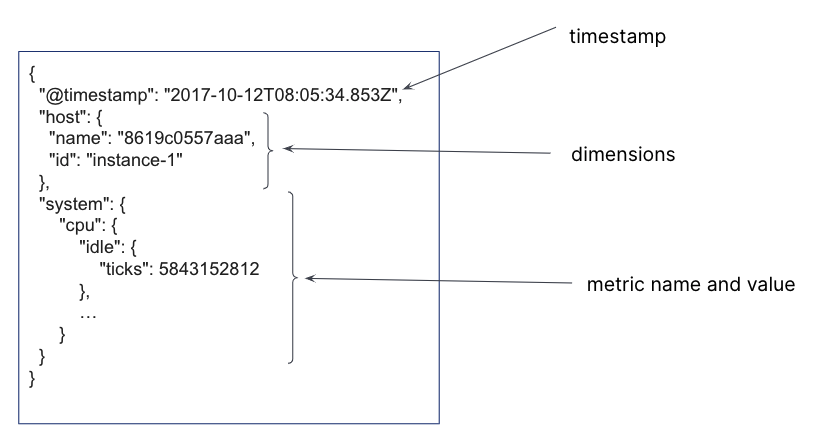
In an Elasticsearch index, a single document is created for each timestamp, containing the immutable time series dimensions, together with the metrics names and the changing metrics values. For a single timestamp, several time series dimensions and metrics may be stored.
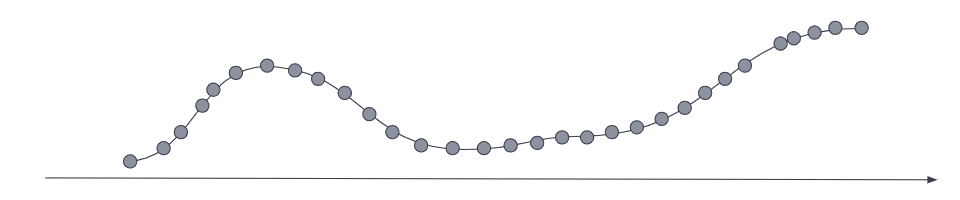
For your most current and relevant data, the metrics series typically has a low sampling time interval, so it’s optimized for queries that require a high data resolution.
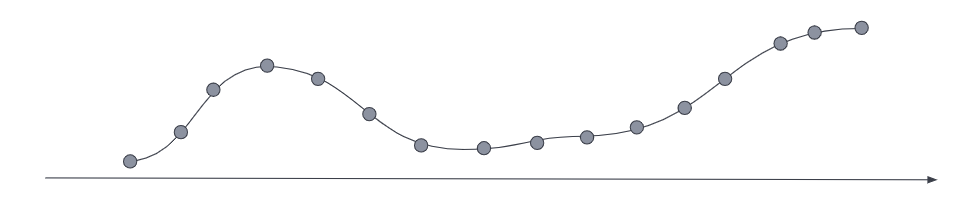
Downsampling works on older, less frequently accessed data by replacing the
original time series with both a data stream of a higher sampling interval and
statistical representations of that data. Where the original metrics samples may
have been taken, for example, every ten seconds, as the data ages you may choose
to reduce the sample granularity to hourly or daily. You may choose to reduce
the granularity of cold archival data to monthly or less.
Running downsampling on time series data
editTo downsample a time series index, use the
Downsample API and set fixed_interval to
the level of granularity that you’d like:
response = client.indices.downsample(
index: 'my-time-series-index',
target_index: 'my-downsampled-time-series-index',
body: {
fixed_interval: '1d'
}
)
puts response
POST /my-time-series-index/_downsample/my-downsampled-time-series-index
{
"fixed_interval": "1d"
}
To downsample time series data as part of ILM, include a
Downsample action in your ILM policy and set fixed_interval
to the level of granularity that you’d like:
response = client.ilm.put_lifecycle(
policy: 'my_policy',
body: {
policy: {
phases: {
warm: {
actions: {
downsample: {
fixed_interval: '1h'
}
}
}
}
}
}
)
puts response
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"warm": {
"actions": {
"downsample" : {
"fixed_interval": "1h"
}
}
}
}
}
}
Querying downsampled indices
editYou can use the _search and _async_search
endpoints to query a downsampled index. Multiple raw data and downsampled
indices can be queried in a single request, and a single request can include
downsampled indices at different granularities (different bucket timespan). That
is, you can query data streams that contain downsampled indices with multiple
downsampling intervals (for example, 15m, 1h, 1d).
The result of a time based histogram aggregation is in a uniform bucket size and
each downsampled index returns data ignoring the downsampling time interval. For
example, if you run a date_histogram aggregation with "fixed_interval": "1m"
on a downsampled index that has been downsampled at an hourly resolution
("fixed_interval": "1h"), the query returns one bucket with all of the data at
minute 0, then 59 empty buckets, and then a bucket with data again for the next
hour.
Notes on downsample queries
editThere are a few things to note about querying downsampled indices:
- When you run queries in Kibana and through Elastic solutions, a normal response is returned without notification that some of the queried indices are downsampled.
-
For
date histogram aggregations,
only
fixed_intervals(and not calendar-aware intervals) are supported. -
Timezone support comes with caveats:
-
Date histograms at intervals that are multiples of an hour are based on
values generated at UTC. This works well for timezones that are on the hour, e.g.
+5:00 or -3:00, but requires offsetting the reported time buckets, e.g.
2020-01-01T10:30:00.000instead of2020-03-07T10:00:00.000for timezone +5:30 (India), if downsampling aggregates values per hour. In this case, the results include the fielddownsampled_results_offset: true, to indicate that the time buckets are shifted. This can be avoided if a downsampling interval of 15 minutes is used, as it allows properly calculating hourly values for the shifted buckets. -
Date histograms at intervals that are multiples of a day are similarly
affected, in case downsampling aggregates values per day. In this case, the
beginning of each day is always calculated at UTC when generated the downsampled
values, so the time buckets need to be shifted, e.g. reported as
2020-03-07T19:00:00.000instead of2020-03-07T00:00:00.000for timezoneAmerica/New_York. The fielddownsampled_results_offset: trueis added in this case too. - Daylight savings and similar peculiarities around timezones affect reported results, as documented for date histogram aggregation. Besides, downsampling at daily interval hinders tracking any information related to daylight savings changes.
-
Date histograms at intervals that are multiples of an hour are based on
values generated at UTC. This works well for timezones that are on the hour, e.g.
+5:00 or -3:00, but requires offsetting the reported time buckets, e.g.
Restrictions and limitations
editThe following restrictions and limitations apply for downsampling:
- Only indices in a time series data stream are supported.
- Data is downsampled based on the time dimension only. All other dimensions are copied to the new index without any modification.
- Within a data stream, a downsampled index replaces the original index and the original index is deleted. Only one index can exist for a given time period.
- A source index must be in read-only mode for the downsampling process to succeed. Check the Run downsampling manually example for details.
- Downsampling data for the same period many times (downsampling of a downsampled index) is supported. The downsampling interval must be a multiple of the interval of the downsampled index.
- Downsampling is provided as an ILM action. See Downsample.
- The new, downsampled index is created on the data tier of the original index and it inherits its settings (for example, the number of shards and replicas).
-
The numeric
gaugeandcountermetric types are supported. -
The downsampling configuration is extracted from the time series data stream
index mapping. The only additional
required setting is the downsampling
fixed_interval.
Try it out
editTo take downsampling for a test run, try our example of running downsampling manually.
Downsampling can easily be added to your ILM policy. To learn how, try our Run downsampling with ILM example.