Ministère des Armées : Déployer une solution en un temps record avec Elastic Cloud pour lutter contre COVID-19 et toute future pandémie
WaKED-CO (Watch of Knowledge on Emergent Diseases COVID-19) est une initiative lancée en un temps record par la Direction Centrale du service santé du Ministère des Armées. La mission derrière ce projet ? Faciliter le travail de recherche bibliographique autour de la crise.
L’objectif est ici double : pouvoir suivre l’évolution rapide de l’épidémie et des progrès scientifiques autour, mais aussi aider certaines parties prenantes, telles que les pouvoirs publics ou la communauté médicale, dans leur prise de décision. Pour ce projet, différentes équipes de data scientists au sein du gouvernement ont travaillé ensemble : le Secrétariat Général pour l’Administration (SGA), le Service de Santé des Armées (SSA), le Centre de Conduite Informatique de l’Armée de Terre (CCIAT) et l’Institut de Recherche Biomédicale des Armées (IRBA).
Dès le départ, ces équipes dressent un bilan de la situation et des défis sous-jacents :
- La dissémination des ressources et la disparité de leur qualité
- Le caractère complexe et chronophage de la recherche bibliographique
- L’absence d’une vision d’ensemble sur les recherches autour de COVID19
- Le manque d’exhaustivité des publications
- Le manque de temps
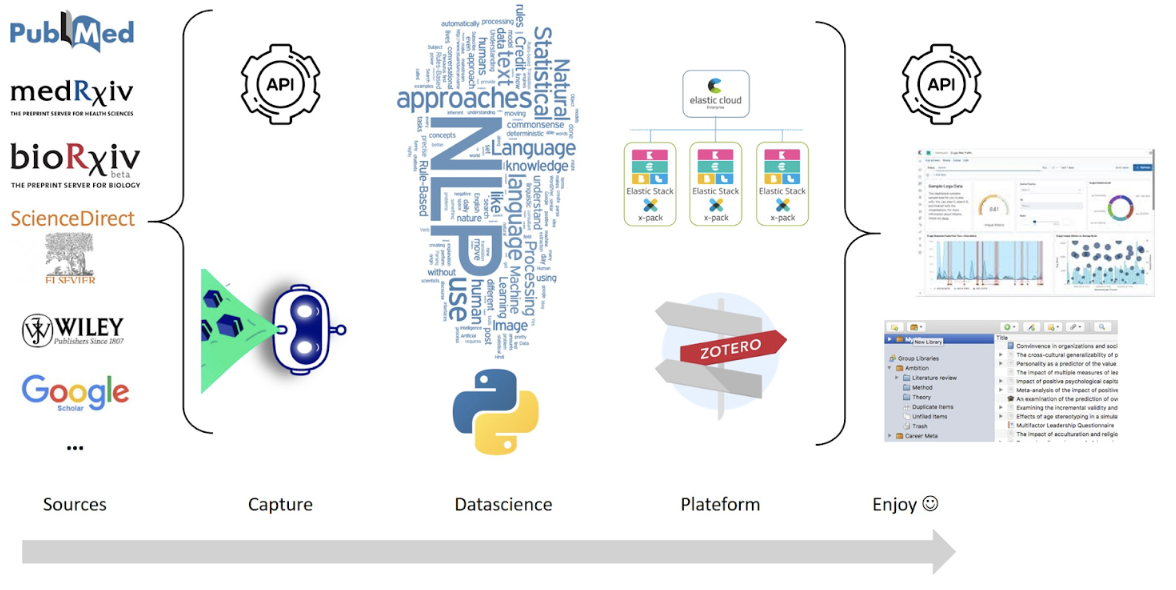
Pour relever ces défis, Elastic Cloud est d’emblée proposé. La Suite Elastic a déjà fait ses preuve au Ministère des Armées pour d’autres sujets comme la vision à 360° des données de chaque département pour accompagner la prise de décision. Les utilisateurs de la plateforme disposent ainsi d’un outil permettant d’agréger, croiser et analyser finement les données. En déployant Elastic Cloud, l’équipe WaKED-CO élimine les contraintes autour des tâches de maintenance et d’implémentation de la solution. Les efforts sont de fait concentrés sur les fonctionnalités de la Suite Elastic et de leur mise à profit :
La flexibilité de Kibana - le produit possède de nombreuses options de tableaux de bords (depuis un simple graphique, jusqu’à des séries temporelles, des nuages de mots ou des cartographies détaillées).
La capacité de recherche puissante d’Elasticsearch couplée à la data science - une combinaison faisant de l’offre un outil apte à répondre aux défis du projet.
Des recherches pertinentes grâce à Elastic
L’équipe WaKED-CO commence par dresser les objectifs fonctionnels pour WaKED-CO. Elle souhaite pouvoir recenser l’ensemble des publications scientifiques et des essais cliniques au sein de la plateforme et les enrichir grâce à l’ajout d’informations annexes. De cette façon, elle vise à faciliter, l’organisation, le tri et la collecte d’information ainsi que la recherche et la veille scientifique. Cette base de données doit aussi pouvoir être couplée avec de l’Intelligence Artificielle pour aider à la réalisation d’études sur COVID19. Enfin il est primordial que la plateforme assure une veille solide de la situation, en faisant remonter les informations pertinentes pour l’utilisateur et, en le guidant correctement dans sa recherche grâce à un système d’alerte.
Ingérer les données avec Elastic
La première étape du projet est de mettre à disposition de nombreuses sources de données hétérogènes et ainsi élargir le spectre d'analyse des chercheurs. Ces données proviennent de sources de publications diverses qui ont été validées par un comité scientifique, la majorité de ces sites sont spécialisés dans le domaine médical (ex: medworm.). Sont inclus à cela les sites contenant des articles scientifiques pré-publiés ainsi que les bases de données nationales et internationales (PubMed, ScienceDirect, Wiley). Pour ingérer ces données disparates, l’équipe met en place un ETL (Extract, Transform and Load) :
- Extract : Des modules d'ingestion développés pour ingérer les différentes sources de données sont développés en Python et utilisent soit des API, soit se comportent comme des robots d'indexation (scraping).
- Transform : Une fois l'extraction des données réalisée, un travail est porté sur la normalisation des différentes sources. Cette normalisation est essentielle car cela permet de rendre homogène l’interrogation des données.
- Load : Une fois la transformation réalisée, les données sont chargées dans une architecture distribuée en terme de calcul et de stockage et nous indexons les données afin de les rendre disponibles à travers un moteur de recherche.
Traitement des données avec Elastic
L’essentiel de ces données est textuelle, par conséquent l’équipe implémente un certain nombre de techniques de traitement du langage naturel (NLP - Natural Language Processing). Ci-dessous une liste non-exhaustive des différents enrichissements réalisés ou prévus :
- Détection du pays d'appartenance de l'auteur
- Détection et extraction d'entités nommées (Pathologies, Molécules, Médicaments, Dosages) présentes dans les publications
- Extraction de mots-clés s’ils n'ont pas été renseignés par les auteurs
- Système d’alerte basé sur l'apparition de nouvelles entités ou sur leurs évolutions
- Traduction des publications dans différentes langues afin de faciliter l'accès à la connaissance
- Réalisation d'un agent conversationnel à partir des connaissances extraites dans les publications
Enfin, une fois ces données traitées, l’équipe a mis au point son outil de visualisation reposant sur Kibana, l’offre est aujourd’hui dynamique et permet de faire un état des lieux en temps quasi réel et aide les acteurs de cette crise sanitaire dans leur prise de décision :
Voici un aperçu de ce qui peut aujourd’hui être réalisé sur la plateforme :
Venir en soutien au Service Public avec Elastic
Bien qu’elle soit encore à l’état de prototype, la plateforme permet aujourd’hui aux acteurs-clés de cette crise sanitaire d’effectuer une veille journalière et d’être alertés sur les tendances autour de la crise ou sur des thématiques spécifiques qu’ils souhaitent suivre de près. WaKED-CO est accessible depuis le 15 avril sur le site public Platefome COVID-19 du gouvernement français, section veille scientifique, la plateforme est utilisée par l’IRBA et la cellule de crise du ministère des Solidarités et de la Santé. La plateforme comptait au 14 mai en moyenne 280 connexions par jour et plus de 500 000 publications y étaient référencées, elle compte aussi les résultats de près de 388 essais cliniques réalisés avec plus de 16 millions de patients. Depuis, l’ingestion de données se poursuit quotidiennement et ne cesse de croître (voir le communiqué de presse).
L’équipe compte aujourd’hui poursuivre le développement de cette plateforme avec toujours cet objectif de simplifier la tâche des chercheurs et des acteurs de la crise sanitaire. Par exemple, l’équipe envisage d’utiliser Canvas pour mettre en avant des chiffres clés sur les avancées scientifiques (nombre de recherches, essais cliniques etc.). Au-delà de la crise COVID19, l’équipe souhaite aussi faire de cette plateforme un outil d’aide à la gestion de crise pour mieux équiper les acteurs majeurs si une situation similaire devait se reproduire.

Guillaume VIMONT chargé du pôle Data Science et Big Data au sein du LABO BI & BIG DATA du Ministère des Armées.