Elasticsearch, Kibana, Elastic Cloud 8.1: Faster indexing, less disk storage, and smarter analytics capabilities


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Welcome aboard the 8.x journey as we continue to usher in a new era of speed, scale, relevance, and simplicity.
Pack your bags and climb aboard with 8.1, where indexing data is 20% faster and consumes 20% less disk space with doc-value-only fields. Then, map the world in a whole new way with Geohexgrid aggregation and new Elastic Maps features. Plus, discover new perspectives for your data via ad-hoc analytics while experiencing a faster, smaller Elastic Stack.
Ready to buckle up and get started? We have the links you need:
- Try out the new features on Elastic Cloud
- Download the latest versions of Elasticsearch, Kibana, Elastic Cloud on Kubernetes
- Dig deeper in the release notes: Elasticsearch, Kibana, Elastic Cloud, Elastic Cloud on Kubernetes
- See Elasticsearch breaking changes
A new age in speed, scale, relevance, and simplicity
With the unveiling of 8.0, we introduced exciting new features like kNN vector search, Lucene 9’s approximate nearest neighbor (ANN), and support for BERT-based ML models that combined to deliver an easy and fast way to use native natural language processing in the Elastic Stack. These new innovations have ushered Elastic into a new age of speed, scale, relevance and simplicity.
In 8.1, we are excited to continue the journey, pushing the boundaries of the Elastic Stack to make it the most performant, scalable, and secure search-powered platform, available everywhere..
Save space at a faster index pace
In 8.1 we are introducing doc-value-only fields that give you the flexibility to index faster and store more efficiently. By disabling inverted structures (like inverted index) and points (BKD trees) on fields, you can index data up to 20% faster while reducing disk storage by around 20%! With this change at the template level and at rollover, there is a tradeoff in search performance. With doc-value-only fields, you can choose between cost and performance based on your data type and use case. Fields that are rarely queried and where query performance is not as important would be perfect to take advantage of the faster indexing and smaller size on disk.
You can use the field usage and disk usage APIs to identify applicable fields and the potential storage savings. This is widely applicable, and should probably be used on all the data that you mostly run aggregations on, like metrics. If your organization ingests multiple terabytes of data in a day, this option will have a huge impact in your overall data management and could greatly lower your total cost of ownership.
Improved geo analytics with hex tiles in Elasticsearch
When working with and analyzing geospatial data, grid systems are critical to partitioning areas of interest and the shape of the grid system impacts the accuracy of your analysis. Hex tiles are more accurate and efficient for analysis when zooming or scrolling of objects within a grid or a map. When hex tiles are fitted together, it defines a measurable edge and the distances from each center of the hex tile is equal. And after all, hexagons are the bestagons.
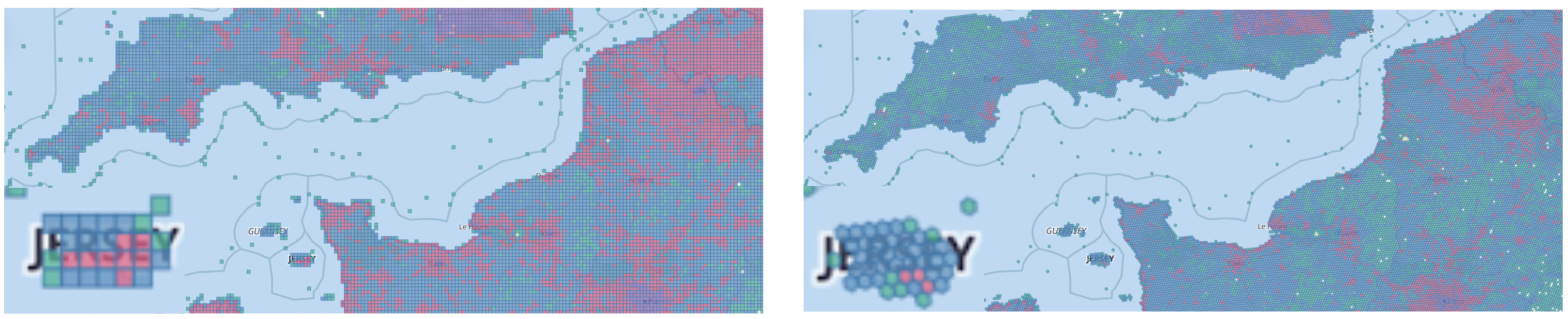
With the Geohexgrid, developed by Uber (H3), geospatial data is partitioned into hexagonally shaped tiles. This means that zooming in and out renders the map smoothly, because hexagons cover a greater part of the circle that bounds them, while still keeping high-fidelity to ensure an accurate and great map experience for your users. In the future, you will be able to experience Geohexgrid in Kibana with the Maps app.
Dive deeper into data exploration in Kibana to unearth insights
When you need to dive deeper into your data to answer complex questions — like exploring real user monitoring (RUM) data in the Observability solution — you can flexibly go from workflow to data discovery in Kibana Lens to gain more insights and investigate hunches. Kibana’s analytical capabilities empower you to start your data discovery from anywhere within the stack, with any data or use case — in whatever way you want to take your analysis, examine your data through a different lens (or ten).
Easily change your perspective on your data by swapping out different visualization types. In 8.1, you can try three new types: gauge, waffle, and mosaic (now in tech preview). Use gauges for metrics that you’re tracking for goals, add a waffle chart to see the composition of your data down to the smallest proportion, and employ a mosaic chart to better compare data with multiple variables. Learn more about visualizing proportions in this video.
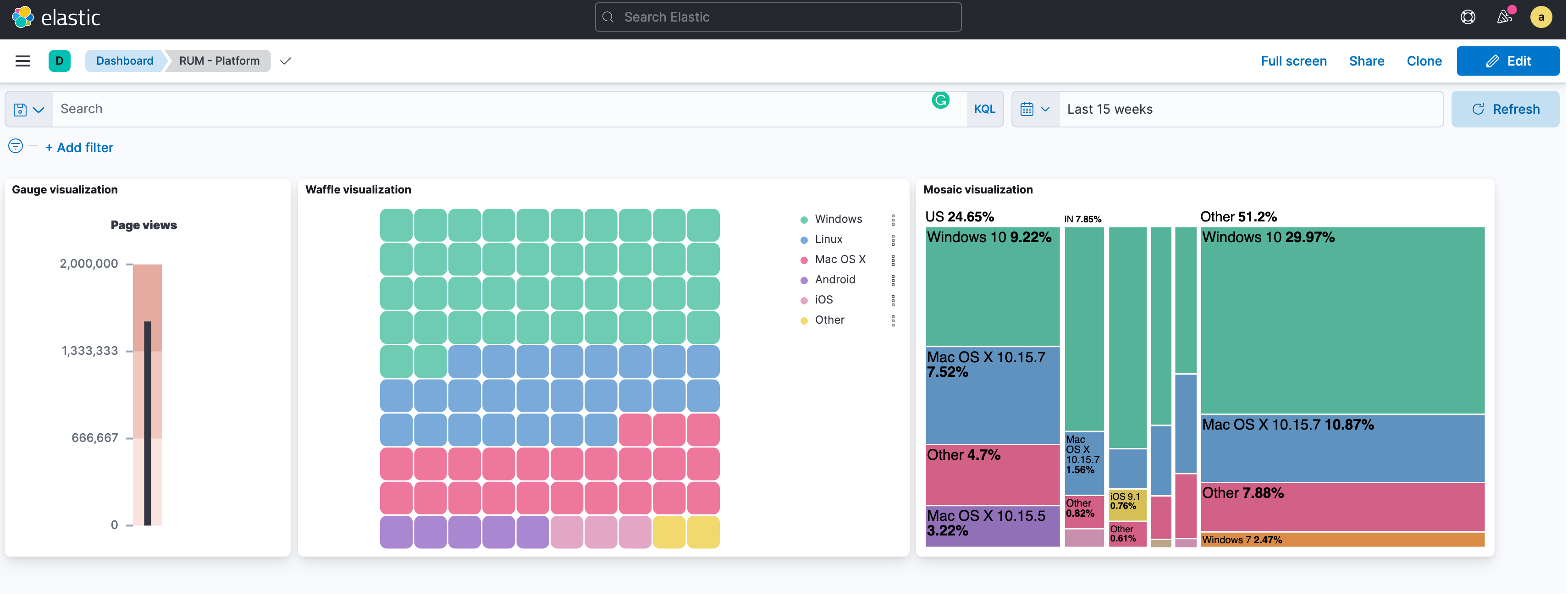
Enhance your data exploration with custom formulas, pivot tables, and multi-field top values — a new way to drag and drop multiple fields to compare combined top values and hone in on multi-dimensional data. With multi-field top values, combining values provides more on-the-go flexibility to your analysis — no need to update your index or add fields as this combination gets created at report time.
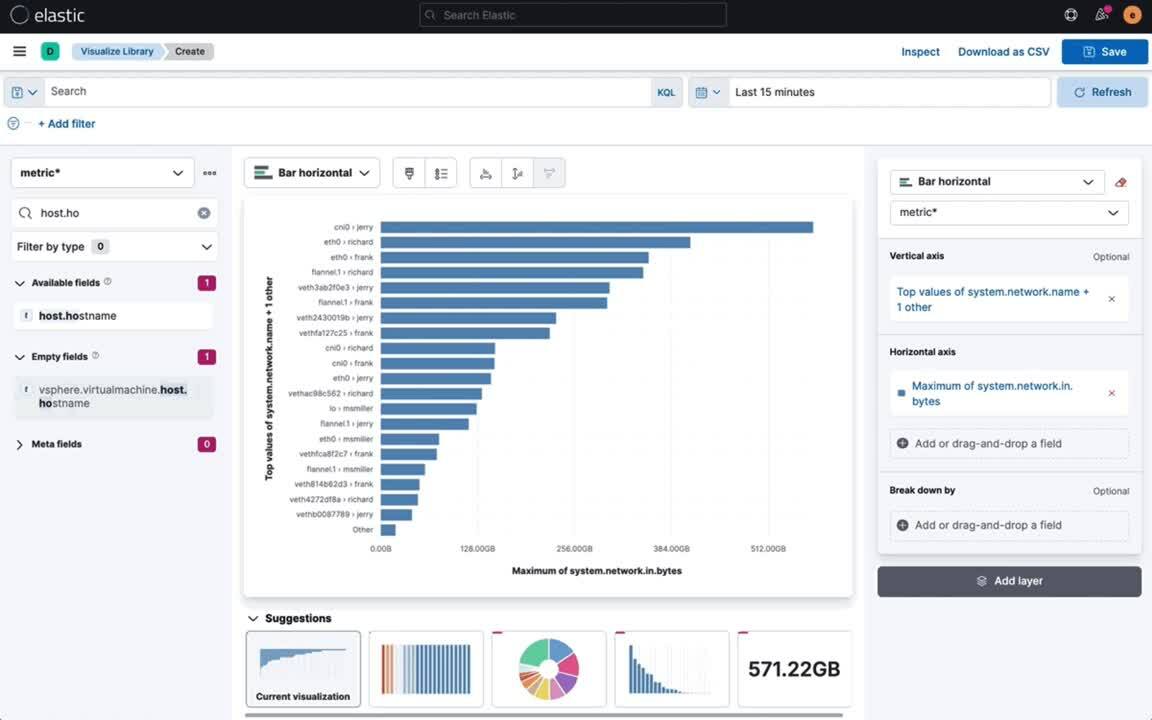
Bring your discoveries back to your team to make the unknowns “known.” Quickly take action by adding new charts and dashboards based on your lessons learned to resolve future incidents faster.
Zoom and pan across maps with speed and ease
The first step in every journey is getting your hands on the map. You can already upload your geo data to Elastic Maps via many different methods, and with 8.1, you’ll also have the ability to import shapefiles so you can get started analyzing your geo data even faster with this data format.
Once you have your geodata imported, enjoy the buttery-smooth zooming and panning with native support for Elasticsearch vector tiles in Elastic Maps. First introduced in 8.0, vector tiles are now the default for document layers in Elastic Maps so that everyone can enjoy faster performance and better interactivity.
Simplified syntax and field access in documents with the new field API
In 8.1, we are introducing easy access to fields in a document from Painless scripts. Rather than using the doc variable method, which requires logic to check that both fields and their values exist, you can use the new field API to access documents to handle missing values automatically.
The field API returns a field object that iterates over fields with multiple values, providing access to the underlying value through the get(<default_value>) method, as well as the type conversion and helper method. It also returns the default value that you specify, regardless of whether the field exists or has any values for the document. This means that the field API can handle missing values without requiring additional logic.
field(‘name’).get(<default_value>)To make scripts even more readable, you can also use the new $ shortcut. Make sure you include the $ symbol, field name, and a default value that you want to get in case the field doesn’t exist:
$(‘field’, <default_value>)With these enhanced capabilities and simplified syntax, you can write scripts that are shorter and easier to read. For example, the following script uses the outdated syntax:
Before
if (!doc.containsKey('myfield') || doc['myfield'].empty) { return "unavailable" } else { return doc['myfield'].value }Using the field API, you can now write this same script much more succinctly, without requiring additional logic to determine whether fields exist before operating on them:
After
$(‘myfield’, ‘unavailable’)This feature is in beta so some field types aren’t yet compatible with the new API, such as text or geo field and in the future it may allow abstract access to _source and doc_values too. We recommend using the existing doc variable to access field types that are not supported yet. More information is available in the official documentation page.
Other updates across the Elastic Stack and Elastic Cloud
Kibana
- Discover a whole new Document Explorer — New to Discover, you can try out the new Document Explorer, a whole new way to examine your data. Even faster and more robust, this new feature is available to try out via advanced settings. Got feedback? Feel free to drop us a note from Kibana or via this form.
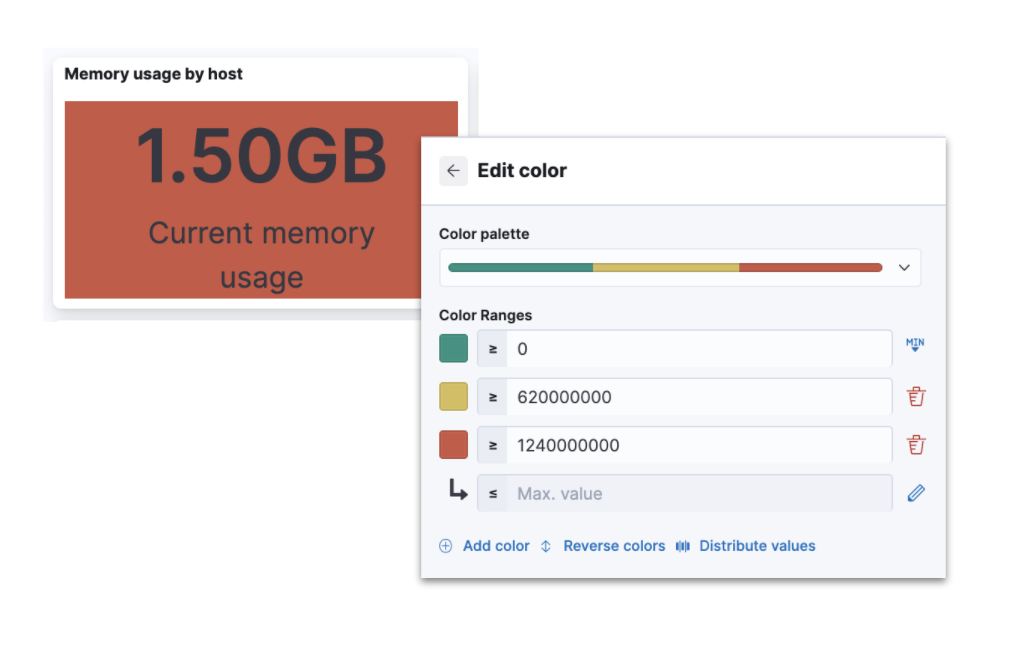
- Color outside the data lines — Add more customization to your visualizations with "color by value" for metrics in Kibana Lens. Use multiple color stops to show progress and goals.
- Find the needle in the text haystack — Rank your "Top values" by rarity to find uniquely occurring values in your data. With Elasticsearch backing your top values search in Kibana Lens, finding the anomalies in your data is quick and easy.
- Understand cases at a glance — Cases now include operational KPIs and a summary of the number of alerts, users, hosts, and actions to make it easier to understand individual cases at a glance.
- Gain better oversight over alerts — The Rules view includes percentile durations, so you can easily identify rules that produce long durations. Paired with the new configurable rule cancellation option, canceling long running rules can reduce any impact to cluster performance.
- Learn more about 8.1 features in the Kibana docs.
Try it out
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. If you’re new to Elastic Cloud, take a look at our Quick Start guides (bite-sized training videos to get you started quickly) or our free fundamentals training courses. You can always get started with a free 14-day trial of Elastic Cloud or download the self-managed version of the Elastic Stack for free.
Read about these capabilities and more in the 8.1 release notes (Elasticsearch, Kibana, Elastic Cloud, Elastic Cloud on Kubernetes), and other Elastic 8.1 highlights in the Elastic 8.1 announcement post.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print