Directly search S3 with the new frozen tier
We’re thrilled to announce the technical preview of the frozen tier in 7.12, enabling you to completely decouple compute from storage and directly search data in object stores such as AWS S3, Microsoft Azure Storage, and Google Cloud Storage. The next major milestone in our data tier journey, the frozen tier significantly expands your data reach by storing massive amounts of data for the long haul at much lower cost while keeping it fully active and searchable.
We've long supported multiple data tiers for data lifecycle management — hot for high speed and warm for lower cost and performance. Both leverage local hardware for storing your primary data and redundant copies. More recently, we’ve introduced the cold tier, which allows you to store up to twice the data on the same amount of hardware over the warm tier by eliminating the need to store your redundant copies locally. Although the primary data is still local for optimal performance, indices in the cold tier are backed by searchable snapshots stored in your object store for redundancy.

The frozen tier takes it a big step further by removing the need to store any data locally at all. Instead, it uses searchable snapshots to directly search data stored in the object store without any need to rehydrate it first. A local cache stores recently queried data for optimal performance on repeat searches. Storage costs go down significantly as a result — up to 90% over the hot or warm tiers, and up to 80% over the cold tier. The fully automated lifecycle of your data is now complete: from hot to warm to cold and then to frozen, all while ensuring you have the access and search performance you need at the lowest storage cost possible.
You never outgrow good data
Whether it’s for observability, security, or enterprise search, your IT data can keep growing at an exponential rate. It’s commonplace for organizations to ingest and search many terabytes a day. This data is critical not only for day-to-day success but also for historical reference. Unlimited lookback for security investigations, drilling into years of APM data for trend identification, or the occasional discovery for regulatory compliance are all key use cases for keeping your data around and accessible for longer periods of time. Satisfying these use cases, however, can quickly become very expensive if you don’t have the right tools or technology to store the data while ensuring it’s easily searchable.

That’s where the frozen tier comes in. It opens the door to all of these use cases, now making it cost effective to store years of data at a cost comparable to just archiving data in S3 or another object store. The key difference is that with the frozen tier the data remains fully searchable in Elasticsearch, and all your Kibana dashboards pulling data from the frozen tier will simply just work. Gone are the days of having to manually find and pull data out of the archive, restore it, and then make it available for search. The same is true for balancing trade-offs on which data to retain and which to delete. It all becomes easy and seamless now with the frozen tier.
How it works
The frozen tier leverages searchable snapshots to decouple compute from storage. As data migrates from warm or cold to frozen based on your index lifecycle management (ILM) policy, your indices on local nodes are migrated to S3 or your object store of choice. The cold tier migrates indices to the object store, but it still retains a single, full copy of the data on local nodes to ensure fast and consistent searches. The frozen tier, on the other hand, eliminates the local copy altogether and directly searches the data in the object store. It builds a local cache of recently queried data for faster repeat searches, but the size of the cache only needs to be a fraction of the full size of data stored in the frozen tier.
With a typical 10% local cache size, this means you only need a handful of local tier nodes to handle many hundreds of terabytes of frozen tier data. Here’s a simple comparison: if your typical warm tier node with 64 GB of RAM manages 10 TB, a cold tier node will be able to handle about twice as much at 20 TB, and a frozen tier node will jump up to 100 TB. This amounts to a 1:1500 RAM-to-storage ratio, and that’s just a conservative estimate.
Price vs performance
So what’s the tradeoff? Well, to no surprise, it’s performance. That’s why we offer these various data tiers, so that you have the flexibility to define the appropriate ILM policies for your organization to determine for how long and how much data should reside in the hot, warm, cold, and frozen tiers. Data stored in the frozen tier is meant to be occasionally searched, and it doesn’t need the faster performance of the other tiers.
We’ve also made great progress in optimizing for the best possible user experience with slower running searches. We’ve developed asynchronous search in Elasticsearch, which lets us provide a natural experience in Kibana by allowing you to render dashboards in the background and retrieve them later. We’ve also introduced a series of query efficiency improvements to speed up slow-running queries, including skipping indices that don’t match with prefiltering, exiting searches early where possible, using block-max WAND for text search, and so on.
Because all data is indexed by default in Elasticsearch, searching data in the frozen tier is especially efficient because we can leverage the concise index structures to return results over large datasets very quickly without having to scan the data itself. On top of that, one of the neatest things we’ve done with searchable snapshots is to use our deep expertise in Lucene to only pull down those subsets of the index that are really needed to answer a query.
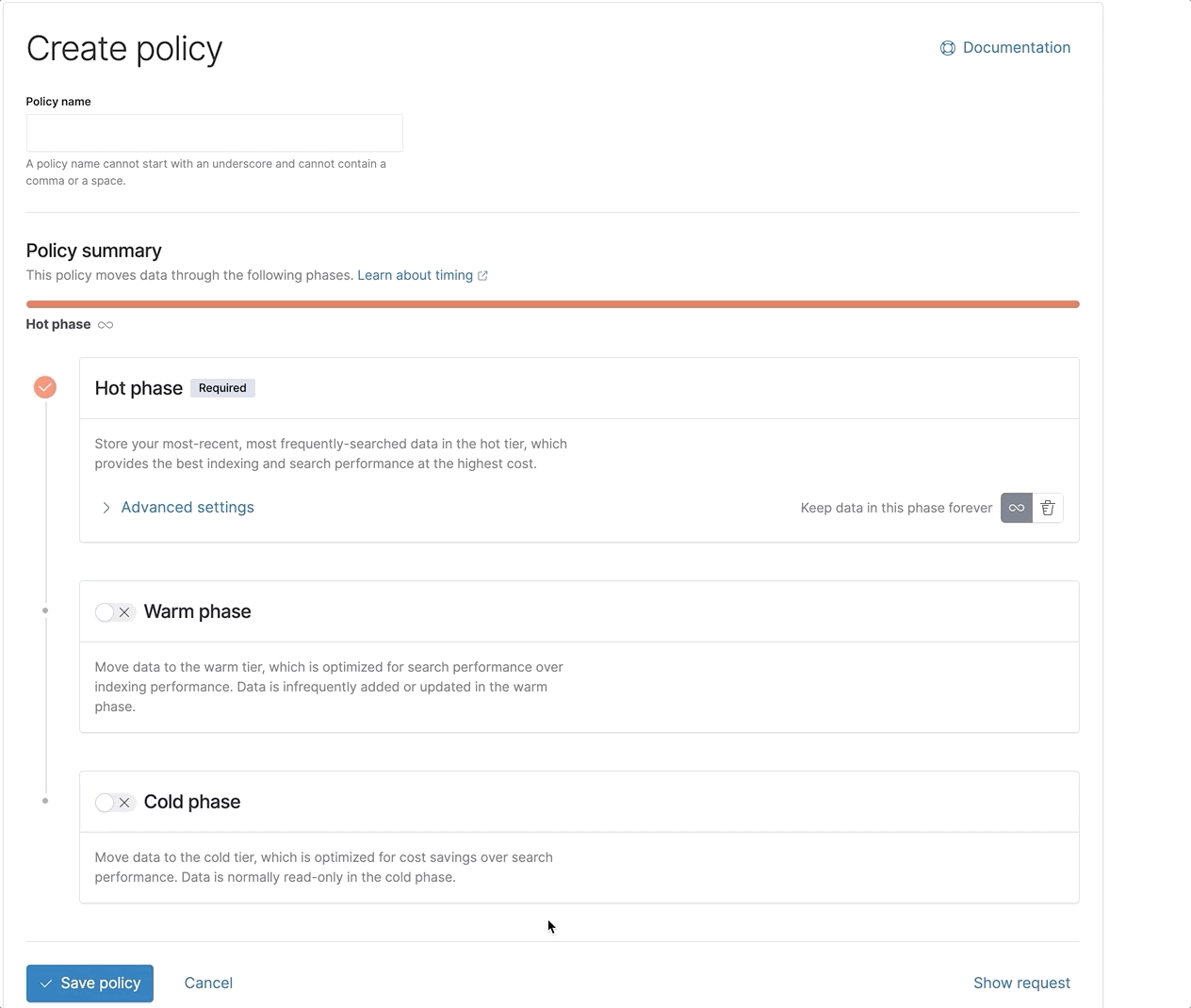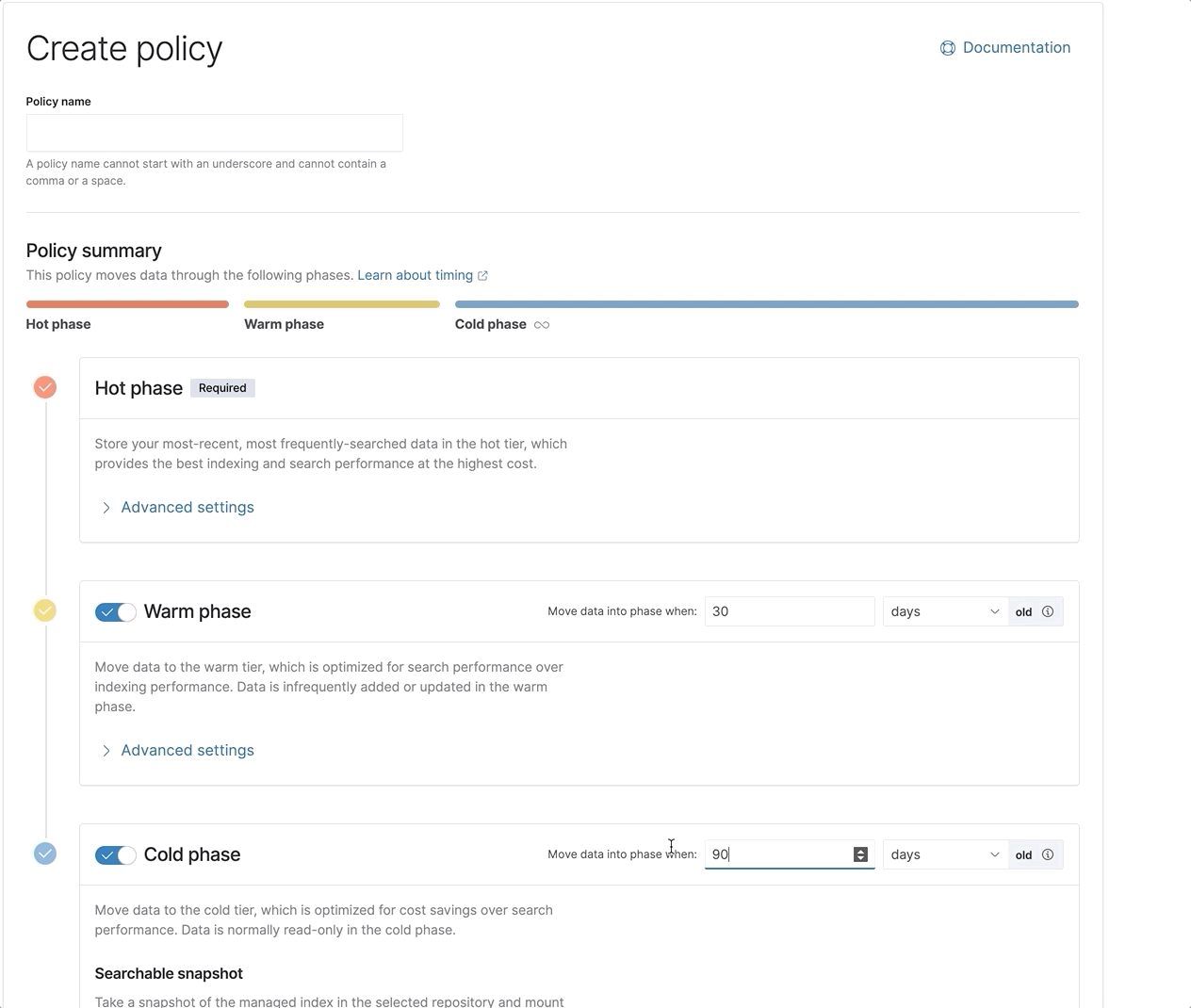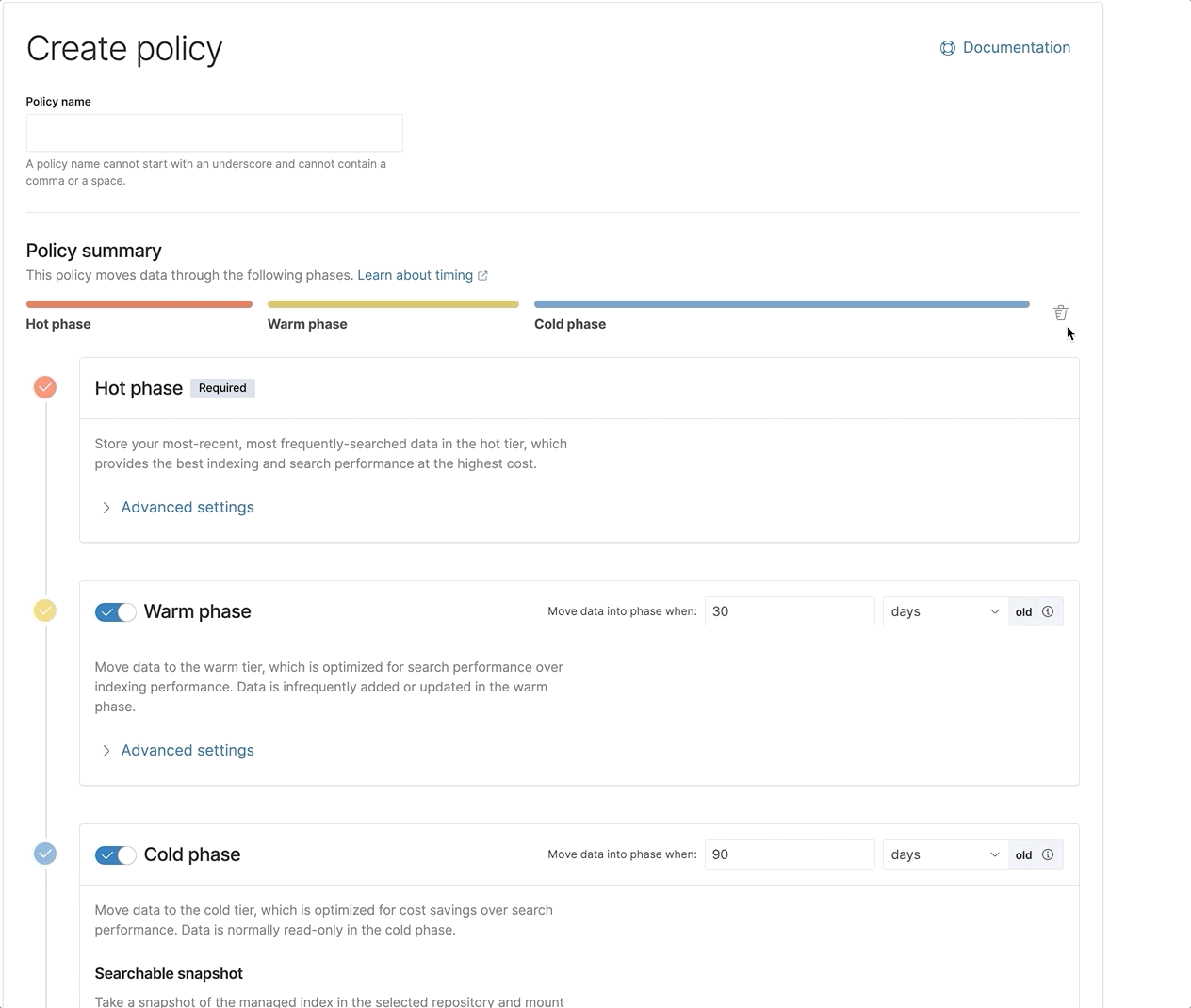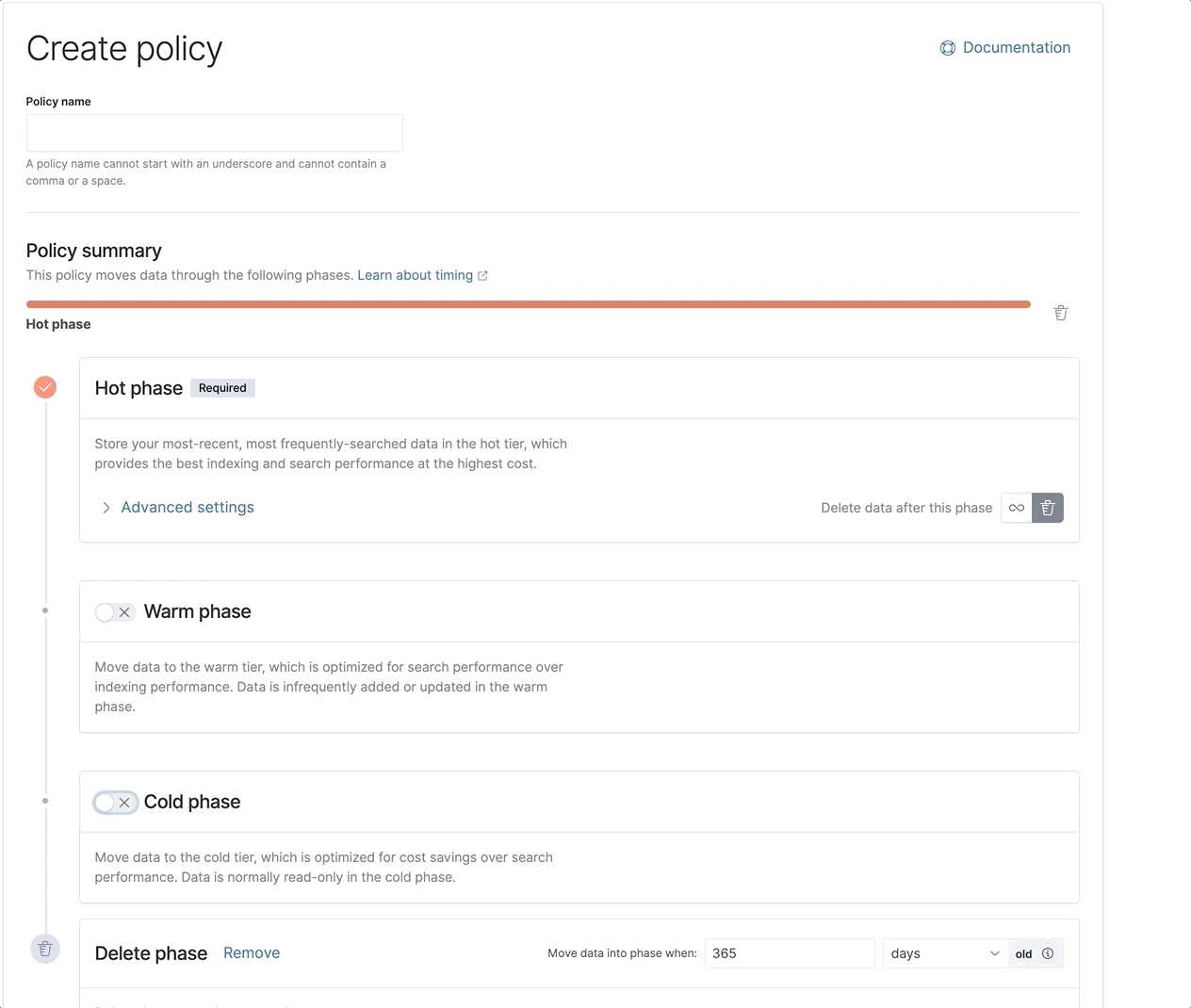
Together, all of these optimizations ensure the best and fastest experience possible when searching the frozen tier. Together with a newly redesigned ILM UI to make it far easier to set up and configure your ILM policies, you now have all the tools you need to get going quickly and effectively with the complete set of Elastic’s data tiers.
Public or private storage, your choice
Our approach at Elastic has always been to offer you the highest possible flexibility with the lowest amount of disruption. In addition to the official support we have for AWS S3, Azure Cloud Storage, Google Cloud Storage and MinIO, we are now releasing a repository test kit for testing and validating any S3-compatible object store to work with searchable snapshots, the cold tier, and the frozen tier.
Available as an easily consumable API, the test kit allows you to run a series of quick tests against your own S3-compatible object store. If they’re successful, you can use it to store and search your snapshots, and to enable it as the object store for the cold and frozen tiers. Because this is a validation test kit, it’s important to note that this doesn’t mean we’re officially supporting any S3 compatible storage that passes the validation. If an issue is found, the problem will need to be reproducible on supported S3 devices in order for us to fix the issue.
Timeline
The frozen tier is being introduced as a technical preview in Elastic 7.12. The hot, warm, and cold tiers are already generally available, as is the underlying searchable snapshots capability that supports the cold and frozen tiers. The frozen tier is also available in Elastic Cloud as of 7.12, with a simpler, out-of-the-box slider coming soon.
Get started today
To get started with the frozen tier, spin up a cluster on Elastic Cloud or install the latest version of the Elastic Stack. Already have Elasticsearch running? Just upgrade your clusters to 7.12 and give it a try. If you want to try it out on Elastic Cloud, details are available in the Elastic Cloud documentation. These steps will go away once the frozen slider becomes available. If you’d like to know more about the frozen tier, you can read the searchable snapshots blog, the searchable snapshots product documentation or the data tiers product documentation.
The release and timing of any features or functionality described in this document remain at Elastic’s sole discretion. Any features or functionality not currently available may not be delivered on time or at all.