Interagissez différemment avec vos données grâce aux interfaces utilisateur Infrastructure et Logs
Dans la version 6.5 de la Suite Elastic, nous avons mis en place deux nouveaux outils permettant d’interagir avec vos données : les interfaces utilisateur Infrastructure et Logs. Ces deux interfaces sont encore en version bêta dans la version 6.5, mais nous y reviendrons ultérieurement car nous comptons sur vous pour nous faire part de vos commentaires. Ce que j’aimerais faire auparavant, c’est vous expliquer les motivations qui ont conduit à la mise en place de ces interfaces, décrire l’expérience utilisateur qu’elles proposent et aborder leur configuration. Commençons avec l’interface utilisateur Logs.
Interface utilisateur Logs
Motivation
J’entends régulièrement dire : “Donne-moi juste les logs, je n’ai pas besoin de quelque chose de sophistiqué. Tout ce que je dois savoir se trouve dans les logs. Je veux juste les lire“. Nous en avons pris bonne note et c’est à vous que revient le choix. Que préférez-vous ?
Une commande tail -f améliorée surveillant les derniers ajouts de lignes dans un fichier ? Une expérience visuelle avec des tableaux, des graphiques, des nuages de mots-clés, etc. ? Une vue tabulaire ? Vous devez pouvoir travailler de la manière qui vous convient. Or, avec la flexibilité de la Suite Elastic, c’est possible.
 |  |  |
Expérience utilisateur
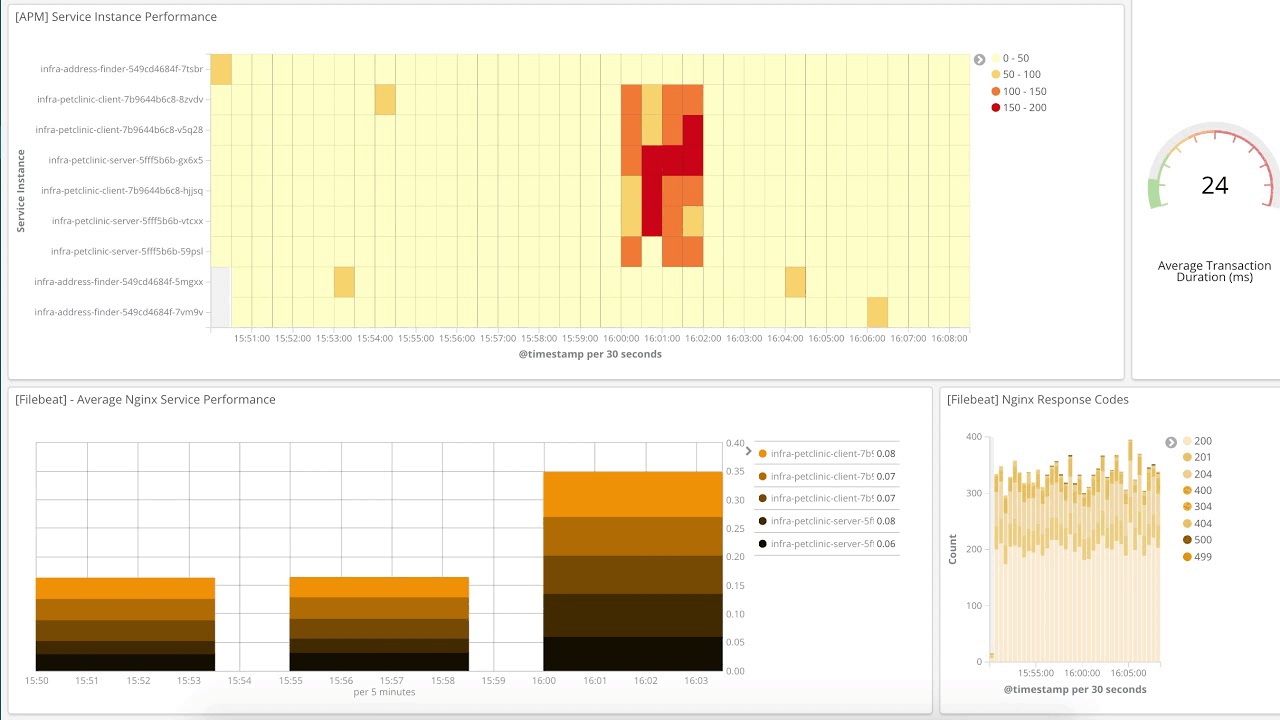
L’utilisation de l’IU Logs est similaire à l’utilisation d’une commande tail, sauf que dans le cas présent, ce sont tous les logs de tous vos systèmes qui sont surveillés dans une console. Au fur et à mesure que les logs sont générés, la partie inférieure de la vue affiche l’enregistrement le plus récent, comme si une commande tail -f était exécutée. Par défaut, l’IU Logs affiche l’ensemble des enregistrements de tous les logs répondant aux critères de configuration (que nous verrons plus en détail dans la prochaine section). Si vous travaillez sur un problème et que vous n’avez pas besoin de tous les logs de tous les services (qui apparaissent trop vite pour que vous puissiez tous les lire), servez-vous de la barre de recherche située en haut pour afficher ceux qui vous intéressent. Par exemple, si je veux voir uniquement les erreurs 404 des pods httpd d’Apache avec le niveau de balise Kubernetes = “frontend”, je vais l’indiquer dans la barre de recherche et laisser la saisie semi-automatique m’aider à trouver les logs appropriés :
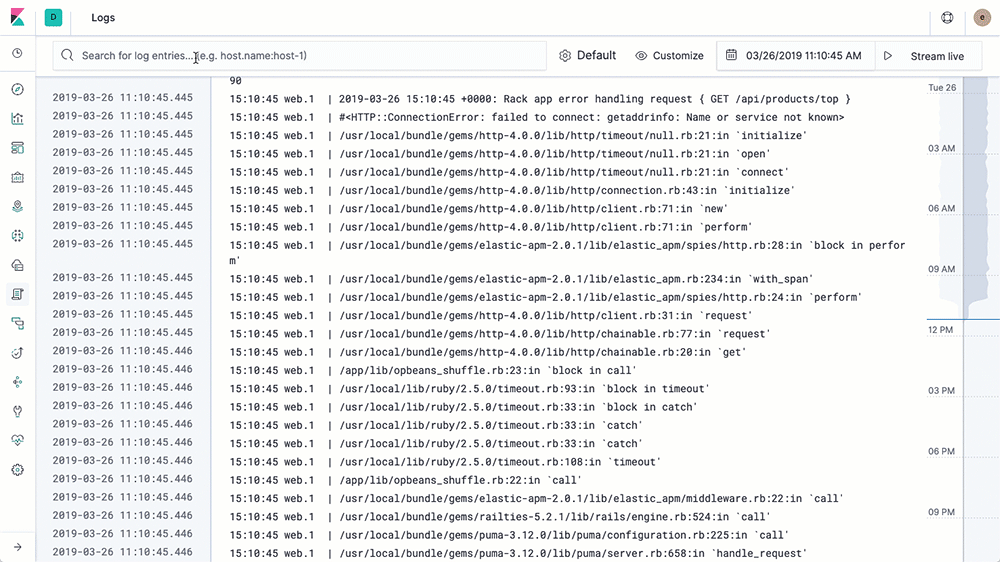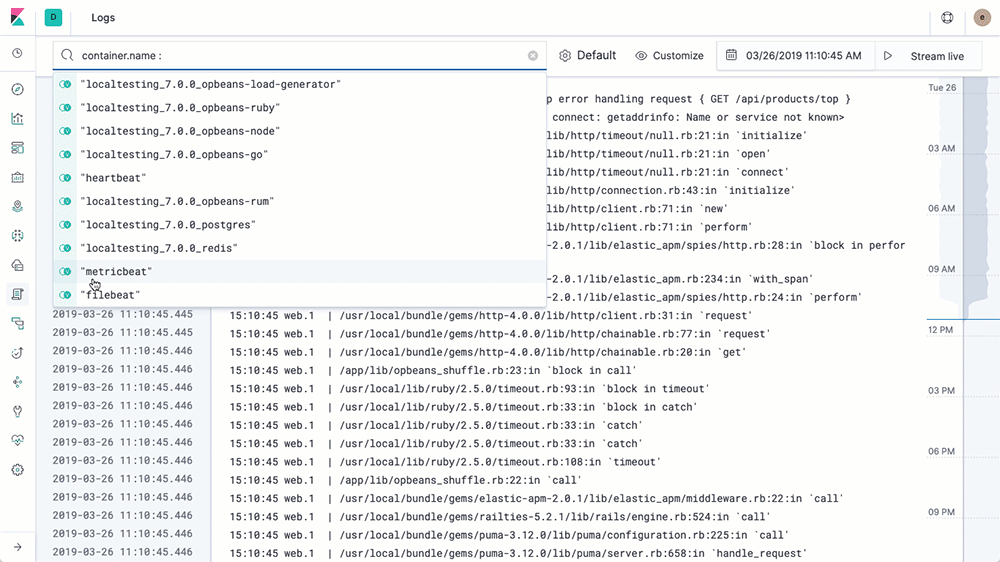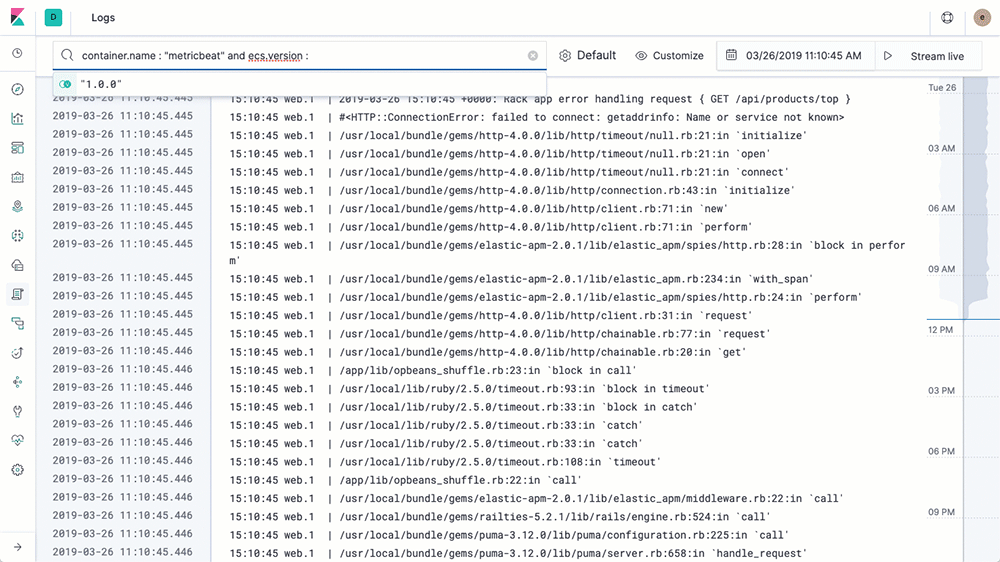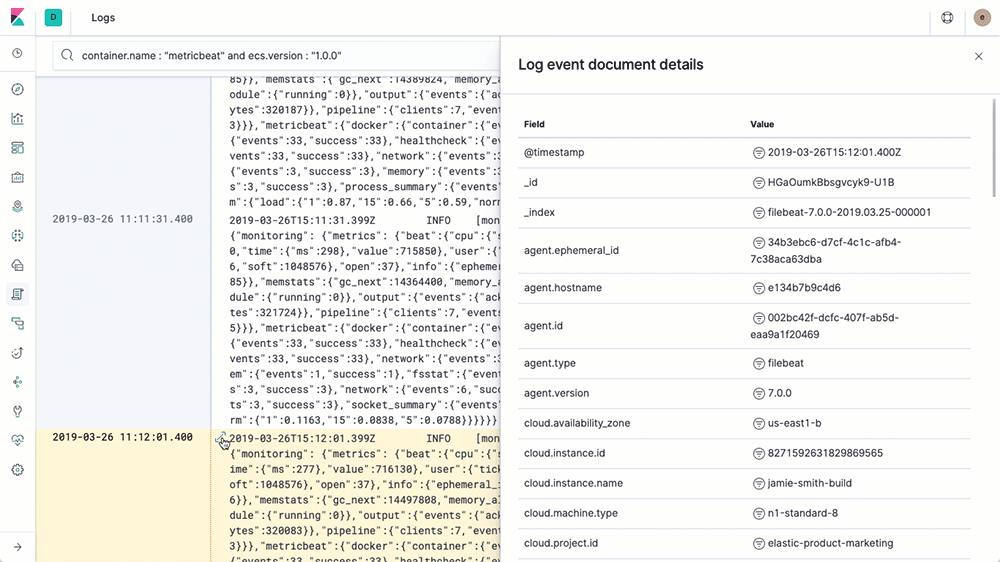
Cela revient à ouvrir un terminal, vous authentifier avec votre fournisseur k8s, déterminer les pods dont vous avez besoin et exécuter kubectl logs -f … | grep 404 (ou, dans une approche sans conteneurs, déterminer les noms d’hôte, se connecter avec SSH, surveiller les dernières lignes des logs, etc.). Notre but est de vous faciliter la vie et de mettre à votre disposition les données dont vous avez besoin selon la méthode que vous souhaitez.
Configuration
La documentation sur l’interface utilisateur Logs se trouve à l’emplacement habituel. Toutefois, je voudrais attirer votre attention sur certaines options de configuration ici. Voici la configuration par défaut que vous pouvez coller dans config/kibana.yml, à laquelle vous pouvez apporter des modifications :
xpack.infra.sources.default.logAlias: "filebeat-*"
xpack.infra.sources.default.fields.timestamp: "@timestamp"
xpack.infra.sources.default.fields.message: ['message', '@message']
La configuration est assez simple et directement prête à l’emploi. Les lignes affichées dans l’interface utilisateur Logs représentent le champ message de chaque index correspondant à l’alias filebeat-*. Que faire si vous souhaitez ajouter tous vos index Logstash ? Modifiez tout simplement xpack.infra.sources.default.logAlias en entrée config/kibana.yml comme ci-dessous et redémarrez Kibana :
#xpack.infra.sources.default.logAlias: "filebeat-*"
xpack.infra.sources.default.logAlias: "filebeat-*,logstash-*"
N’oubliez pas de redémarrer Kibana ! Ouvrez à nouveau l’interface utilisateur Logs et cliquez sur Stream Live (Streaming en direct). Vous devriez y voir tous vos logs Logstash et Filebeat s’afficher.
Remarque : Si vous préférez utiliser les alias Elasticsearch, définissez tout simplement xpack.infra.sources.default.logAlias sur le nom de l’alias, puis mettez l’alias à jour selon vos besoins. Voici la procédure équivalente utilisant un alias de logs.
Créez l’alias :
curl -X POST "localhost:9200/_aliases" -H 'Content-Type: application/json' -d'
{
"actions" : [
{ "add" : { "indices" : ["logstash-*", "filebeat-*"], "alias" : "logs" } }
]
}
'
Mettez à jour config/kibana.yml :
#xpack.infra.sources.default.logAlias: "filebeat-*"
xpack.infra.sources.default.logAlias: "logs"
Interface utilisateur Infrastructure
Motivation
En matière de gestion de l’infrastructure, je considère qu’il existe trois niveaux de maturité de base :
- Déterminer que quelque chose ne fonctionne plus, puis ouvrir un système de monitoring pour approfondir l’analyse.
- Représenter les indicateurs clés de tous les systèmes dans un grand tableau de bord, les observer, puis examiner les problèmes.
- Automatiser les opérations à l’aide du Machine Learning qui apprend ce qu’est un comportement normal, détecte les problèmes émergents et alerte l’équipe opérationnelle.
L’interface utilisateur Infrastructure a pour but d’aider l’équipe opérationnelle à “représenter les indicateurs clés dans un grand tableau de bord“. Je ne prendrai pas beaucoup de risques en disant que nous avons tous besoin de passer à l’étape “Automatisation avec le Machine Learning“. Pour en savoir plus, consultez cet article sur le Machine Learning Elastic. Si vous regardez la vidéo qui se trouve à la fin de l’article, vous verrez un workflow qui démarre par une alerte émise par une tâche de Machine Learning, puis qui évolue via l’APM et le traçage distribué, l’IU Infrastructure et l’IU Logs. Avec Elasticsearch, qui réunit les logs, les indicateurs, APM et le traçage distribué, vous pouvez tirer parti de tous les outils d’analyse et de visualisation sur l’ensemble de vos données.
Découvrons à présent l’IU Infrastructure. Dans cette vue, nous nous intéressons aux pods Kubernetes, qui sont regroupés par espace de nom. J’observe le trafic réseau entrant. En faisant un clic droit sur un pod, je peux accéder aux logs de ce pod ou à un tableau de bord d’indicateurs ayant subi une curation.
Expérience utilisateur
Aujourd’hui, trois types de dispositifs sont pris en charge : les hôtes, les pods Kubernetes (k8s) et les conteneurs Docker. Ce qui fait la puissance de l’IU Infrastructure, c’est que vous pouvez y voir l’état des indicateurs clés pour un grand nombre de dispositifs. Au niveau général, des carrés de couleur sont affichés sans texte, jusqu’à ce que vous décidiez d’explorer un sous-ensemble intéressant à l’aide de la barre de recherche ou en cliquant sur un groupe. Vous pouvez également examiner les logs d’un dispositif ou afficher un tableau de bord d’indicateurs.
Pour revenir aux “indicateurs clés“, en voici la liste. Ils proviennent tous de Metricbeat :
Hôtes : processeur, mémoire, charge, trafic entrant, trafic sortant et taux de logging
Kubernetes : processeur, mémoire, trafic entrant, trafic sortant
Docker : processeur, mémoire, trafic entrant, trafic sortant
Le regroupement vous permet de zoomer sur la liste des dispositifs. Si vous prenez en charge une application spécifique déployée avec Kubernetes, effectuez un regroupement par espace de nom. C’est la solution qui vous conviendra le mieux. Si vous pensez qu’un problème est lié à la surcharge d’un nœud donné, vous pouvez effectuer un regroupement à la fois par espace de nom et par nœud. Voici une liste des regroupements actuels (vous pouvez en utiliser jusqu’à deux par type de dispositif) :
Hôtes : zone de disponibilité, type de machine, ID de projet, fournisseur cloud
Kubernetes : espace de nom, nœud
Docker : hôte, zone de disponibilité, type de machine, ID de projet, fournisseur
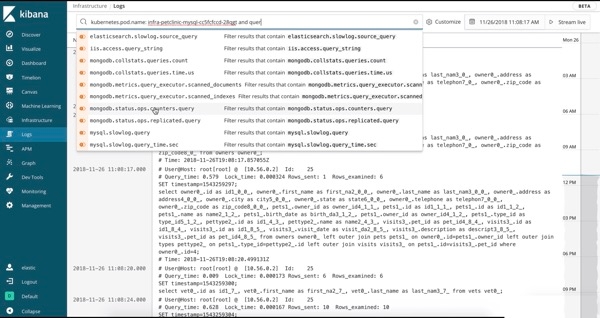
Si aucun des regroupements ci-dessous ne vous permet d’interagir de la façon que vous souhaitez avec vos données, utilisez dans ce cas la barre de recherche. Commencez tout simplement à taper, et la fonctionnalité de saisie semi-automatique Kibana Query Language vous guidera. J’ai fourni un exemple plus haut avec le GIF de l’IU Logs : quand j’ai commencé à taper kubernetes, Kibana m’a proposé labels (balises) et tier (niveau), puis m’a offert différents choix d’après les éléments indexés dans Elasticsearch.
Une fois les ressources regroupées, vous pouvez démarrer l’exploration d’un groupe en cliquant dessus. Vous verrez alors plus de détails sur ce groupe. Si un hôte, un pod ou un conteneur particulier vous intéresse, consultez alors les logs ou les indicateurs qui y sont associés. Voici une vue partielle des indicateurs d’un hôte :
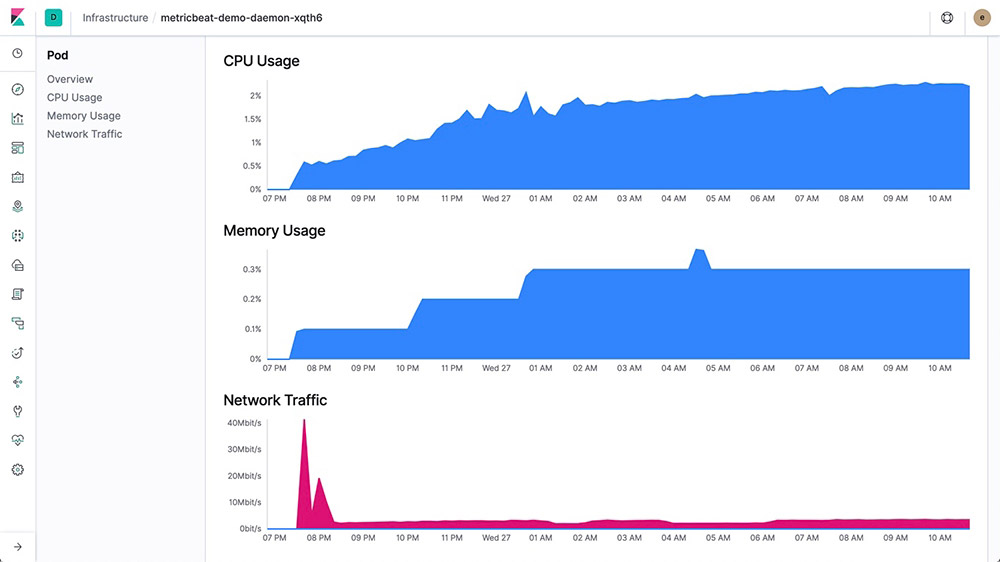
Configuration
L’IU Infrastructure nécessite très peu de configuration. Déployez simplement Metricbeat et activez le module System. Si vous exécutez des conteneurs, activez également les modules Kubernetes et Docker.
À moins que vous ayez modifié le modèle d'indexation par défaut (metricbeat-*), c’est fini ! Si vous avez besoin de personnaliser certains éléments, la documentation relative à l’IU Infrastructure vous donnera des explications. De mon côté, je vous fournis les principales options ci-dessous :
xpack.infra.sources.default.metricAlias: "metricbeat-*"
xpack.infra.sources.default.fields.host: "beat.hostname"
xpack.infra.sources.default.fields.container: "docker.container.name"
xpack.infra.sources.default.fields.pod: "kubernetes.pod.name"
Vous aussi, vous avez votre mot à dire !
Ces deux interfaces sont encore en version bêta. Qu’en pensez-vous ? Faites-nous part de vos réflexions (même lorsque ces interfaces auront été lancées de façon générale). Dites-nous de quelle façon vous préférez interagir avec vos données. Les regroupements proposés dans la version bêta de l’IU Infrastructure sont-ils suffisants pour répondre aux besoins de votre équipe ? Quels seraient ceux qui conviendraient ? Les indicateurs déterminant les couleurs sont-ils appropriés ? Souhaitez-vous une méthode différente pour filtrer les logs dans l’IU Logs ? Lorsque vous consultez la vue des indicateurs à partir de l’IU Infrastructure, visualisez-vous les indicateurs qui vous intéressent ?
Rendez-vous sur le forum de discussion de Kibana et dites-nous ce que vous aimez, ce que vous n’aimez pas, ce dont vous avez besoin etc. Les développeurs lisent vos commentaires et y répondent, car il est important pour eux d’avoir votre avis. Vous pouvez également signaler un problème, soumettre une requête d’extraction, ou garder un œil sur l’un et l’autre dans GitHub.
À vous d’essayer !
Notre système de démo en direct contient des logs et des indicateurs que vous pouvez consulter, sur lesquels vous pouvez faire des recherches et avec lesquels vous pouvez interagir. Maintenant, c’est à vous de jouer. Cliquez sur la mosaïque Infrastructure pour lancer l’IU Infrastructure :

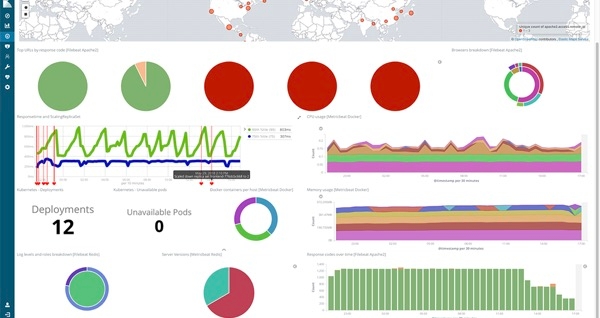
Vous pouvez basculer vers la vue Kubernetes ou Docker, faire des groupes d’objets à l’aide de l’IU, ou affiner la vue en vous servant de la barre de recherche. Cliquez avec le bouton gauche sur un hôte, un pod ou un conteneur, et lancez l’IU Logs pour cet objet. Et tant que vous êtes sur demo.elastic.co, jetez un œil aux tableaux de bord et visualisations proposés. À partir de la page d’accueil, vous pouvez accéder à différentes zones.
Démo
Voici une vidéo qui présente le workflow de ces deux interfaces (ainsi que le Machine Learning et APM avec le traçage distribué). Merci encore de votre intérêt et merci d’avance pour vos commentaires !