Comment monitorer les clusters Kafka conteneurisés avec Elastic Observability
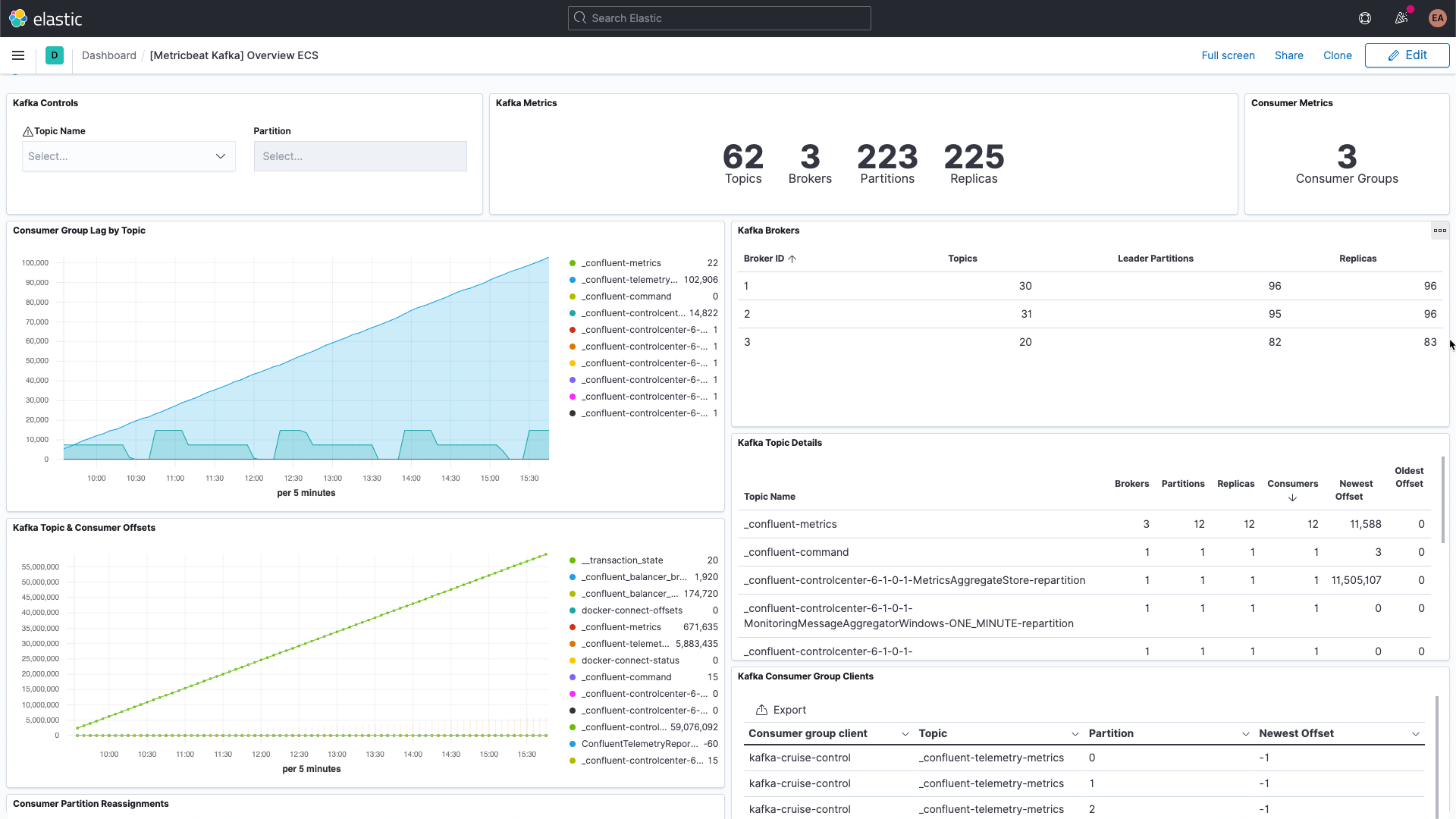
Kafka est une plateforme de diffusion des événements distribuée hautement disponible qui peut être exécutée sur un serveur physique, de manière virtualisée ou conteneurisée ou encore en tant que service géré. Elle repose sur un système de publication et d'abonnement, qui comprend un broker assurant la distribution des événements. Les éditeurs publient des événements sur des sujets spécifiques auxquels s'abonnent les consommateurs. Lorsqu'un nouvel événement est ajouté à un sujet, les consommateurs abonnés à ce dernier reçoivent une notification. Ainsi, de nombreux clients sont informés de l'activité sans que l'éditeur soit obligé de suivre la consommation des événements qu'il publie. Par exemple, lorsqu'une nouvelle commande est passée, une boutique en ligne est susceptible de publier un événement affichant les informations de la commande, qui peuvent être récupérées soit par les consommateurs du service de traitement des commandes afin de les informer de la nouveauté, soit par les consommateurs du service de livraison afin d'imprimer une étiquette, soit par toute autre partie intéressée. Selon la manière dont vous configurez les partitions et les groupes de consommateurs, vous pouvez contrôler lesquels, parmi ces derniers, reçoivent les nouveaux messages.
En règle générale, Kafka se déploie avec ZooKeeper, qui permet de stocker des informations sur la confirmation, comme les sujets, les partitions mais aussi les données sur les répliques et les redondances. Lors du monitoring des clusters Kafka, il est tout aussi important de monitorer les instances ZooKeeper associées en parallèle. En effet, les éventuels problèmes rencontrés par ZooKeeper affecteront également le cluster Kafka.
Il existe plusieurs manières d'utiliser Kafka en parallèle de la Suite Elastic. Vous pouvez configurer Metricbeat ou Filebeat pour envoyer des données sur les sujets Kafka, vous pouvez transférer des informations de Kafka vers Logstash ou de Logstash vers Kafka ou encore vous pouvez utiliser Elastic Observability pour monitorer Kafka et ZooKeeper, afin de surveiller de près votre cluster. Il s'agit d'ailleurs du sujet de cet article. Dans le paragraphe précédent, nous avons mentionné des événements affichant les informations de la commande passée. À l'aide du plug-in d'entrée de Kafka, Logstash peut également s'abonner à ces événements et transférer les données obtenues dans votre cluster Elasticsearch. Ainsi, vous améliorez l'observabilité de vos systèmes grâce à ces activités supplémentaires (ou à toute autre donnée requise pour vous permettre de comprendre précisément ce qu'il se passe au sein de votre environnement).
Éléments à rechercher lors du monitoring de Kafka
Kafka comprend plusieurs éléments disparates : le service en lui-même est souvent composé de divers brokers et instances ZooKeeper, mais aussi des clients qui utilisent Kafka, des éditeurs et des consommateurs. Kafka fournit plusieurs types d'indicateurs, certains via les brokers directement, d'autres via JMX. Le broker fournit des indicateurs pour les partitions et les groupes de consommateurs. Les partitions vous permettent de répartir les messages sur plusieurs brokers, c'est-à-dire d'exécuter le processus en parallèle. Les consommateurs reçoivent les messages provenant d'une partition à sujet unique. Ils peuvent être regroupés afin d'exploiter tous les messages d'un même sujet. Grâce à ces groupes de consommateurs, vous pouvez répartir la charge entre plusieurs personnes.
Chaque message Kafka est doté d'un offset. Il s'agit tout simplement d'un identifiant indiquant l'emplacement du message dans la séquence générale. Quand les éditeurs ajoutent des messages aux sujets, chacun obtient un nouvel offset. Le dernier offset d'une partition affiche l'identifiant le plus récent. Les consommateurs reçoivent des messages des sujets. La différence entre le dernier offset et l'offset reçu par le consommateur s'appelle le décalage consommateur. Immanquablement, les consommateurs seront un peu en retard par rapport aux éditeurs. Par conséquent, il faut surveiller le moment où le décalage consommateur augmente de manière récurrente. Une telle tendance indique que vous avez probablement besoin de davantage de consommateurs pour traiter la charge.
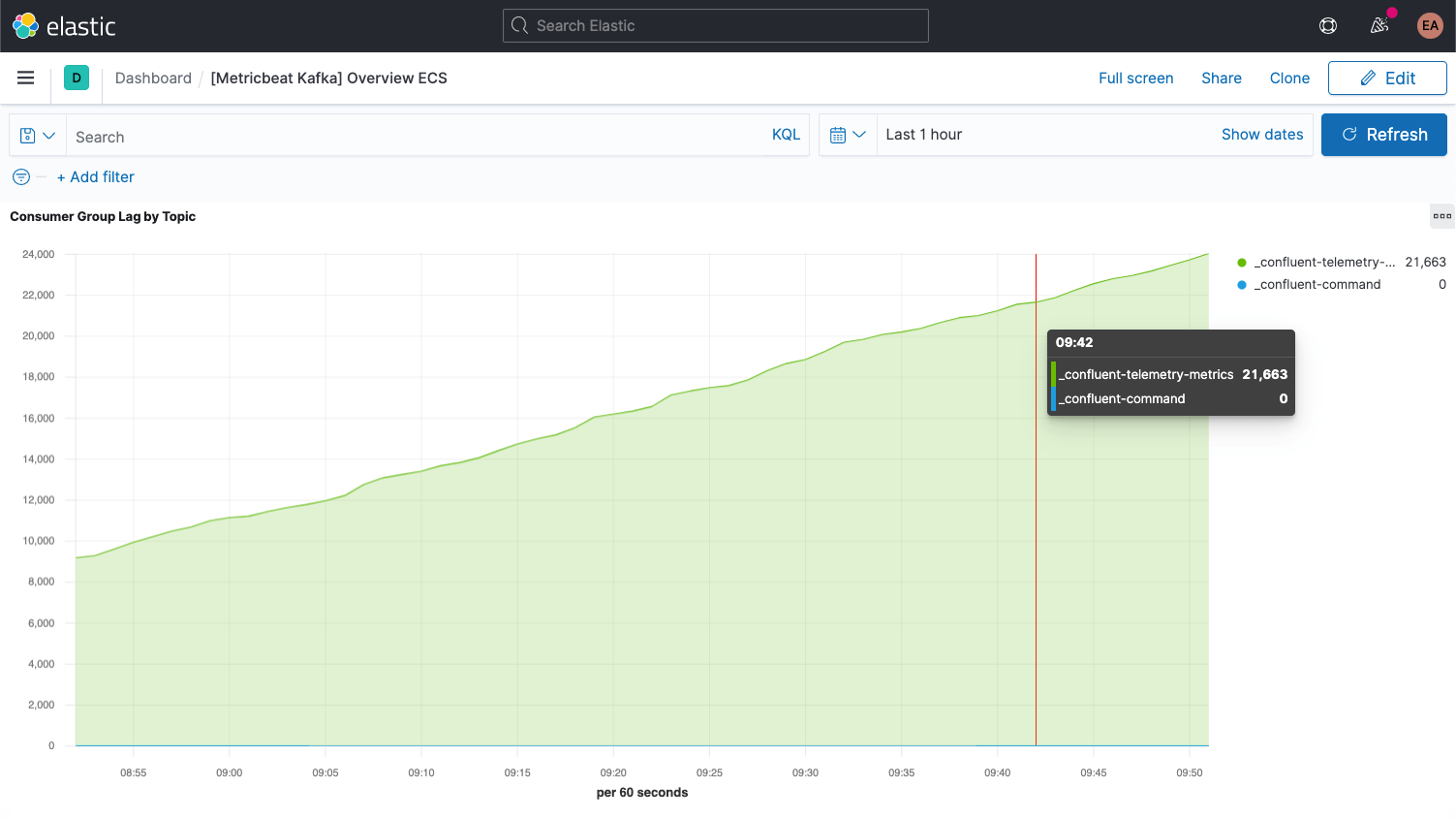
Lorsque vous étudiez les indicateurs des sujets eux-mêmes, il est important d'identifier tout sujet n'ayant aucun consommateur. Il peut s'agir d'un indice d'un défaut d'exécution.
Une fois la configuration terminée, nous vous présentons certains indicateurs fondamentaux supplémentaires des brokers.
Configuration de Kafka et de Zookeeper
Dans le cadre de l'exemple donné ici, nous exécutons un cluster Kafka conteneurisé fondé sur la plateforme Confluent, dans lequel trois brokers Kafka ont été développés (images cp-server), aux côtés d'une seule instance ZooKeeper. En pratique, vous souhaiterez probablement utiliser une configuration plus solide et hautement disponible pour ZooKeeper en parallèle.
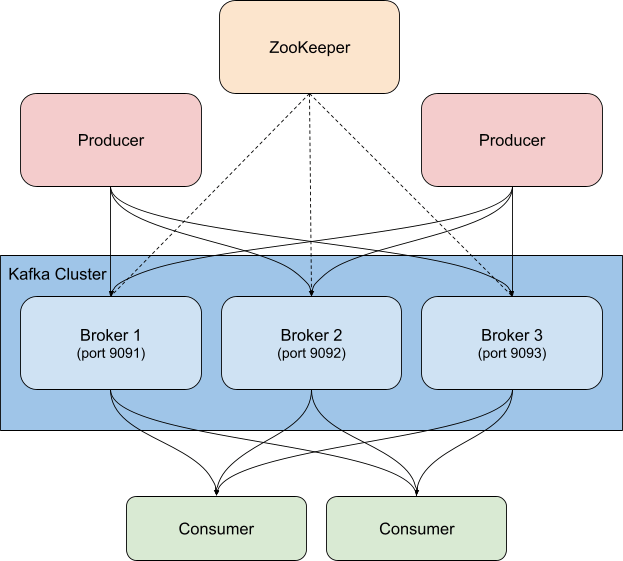
Nous avons cloné cette configuration et utilisé à la place le répertoire cp-all-in-one suivant.
git clone https://github.com/confluentinc/cp-all-in-one.git cd cp-all-in-one
Toutes les autres opérations mentionnées dans cet article sont effectuées à partir de ce répertoire cp-all-in-one.
Dans notre configuration, nous avons modifié les ports afin d'identifier plus facilement le port associé à chaque broker. (Plusieurs ports sont requis, car chacun est exposé à l'hôte.) Par exemple, broker3 se trouve sur le port 9093. En outre, à des fins de cohérence, nous avons remplacé le nom du premier broker par broker1. Le fichier complet, avant instrumentation, est disponible dans mon fork GitHub du répertoire officiel.
La configuration pour broker1 une fois les ports réalignés ressemble à ce qui suit.
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker1:29092,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
Comme vous pouvez le constater, j'ai remplacé les occurrences du nom d'hôte (hostname) de broker par broker1. Bien entendu, tout autre bloc de configuration du fichier docker-compose.yml où broker est mentionné sera également modifié afin de refléter les trois nœuds de nos clusters, par exemple. En outre, le centre de contrôle Confluent dépend maintenant des trois brokers.
control-center:
image: confluentinc/cp-enterprise-control-center:6.1.0
hostname: control-center
container_name: control-center
depends_on:
- broker1
- broker2
- broker3
- schema-registry
- connect
- ksqldb-server
(...)
Collecte des logs et des indicateurs
Nos services Kafka et ZooKeeper exécutent des conteneurs dotés à l'origine de trois brokers. Si nous voulons scaler vers le haut ou le bas, ou encore décider de renforcer l'instance ZooKeeper, nous n'avons pas envie de tout reconfigurer et recommencer le monitoring. Le processus doit être dynamique. Pour ce faire, nous exécutons également le monitoring dans des conteneurs Docker, en parallèle du cluster Kafka, et utilisons la fonction Autodiscover basée sur les indices d'Elastic Beats.
Fonction Autodiscover basée sur les indices
Pour le monitoring, nous recueillons les logs et les indicateurs de nos brokers Kafka et de l'instance ZooKeeper. Nous utilisons Metricbeat pour les indicateurs et Filebeat pour les logs, tous exécutés dans des conteneurs. Afin de lancer ce processus pour chaque indicateur et log, nous devons télécharger les fichiers de configuration pour la variante de Docker, à savoir les fichiers metricbeat.docker.yml et filebeat.docker.yml. Nous envoyons ces données de monitoring à notre déploiement Elastic Observability dans Elasticsearch Service sur Elastic Cloud. (Pour suivre cette partie, vous pouvez commencer un essai gratuit.) Si vous préférez gérer votre cluster vous-même, vous pouvez télécharger la Suite Elastic gratuitement et l'exécuter en local. Nous fournissons des instructions pour les deux scénarios.
Que vous utilisiez un déploiement sur Elastic Cloud ou exécutiez un cluster autogéré, vous devez préciser la méthode pour trouver le cluster, à savoir les URL de Kibana et d'Elasticsearch, mais aussi les identifiants qui vous permettent de vous connecter au cluster. Le point de terminaison Kibana vous permet de charger les informations par défaut relatives à la configuration et aux tableaux de bord. Beats envoie les données dans Elasticsearch. Avec Elastic Cloud, Cloud ID rassemble toutes les informations sur le point de terminaison.
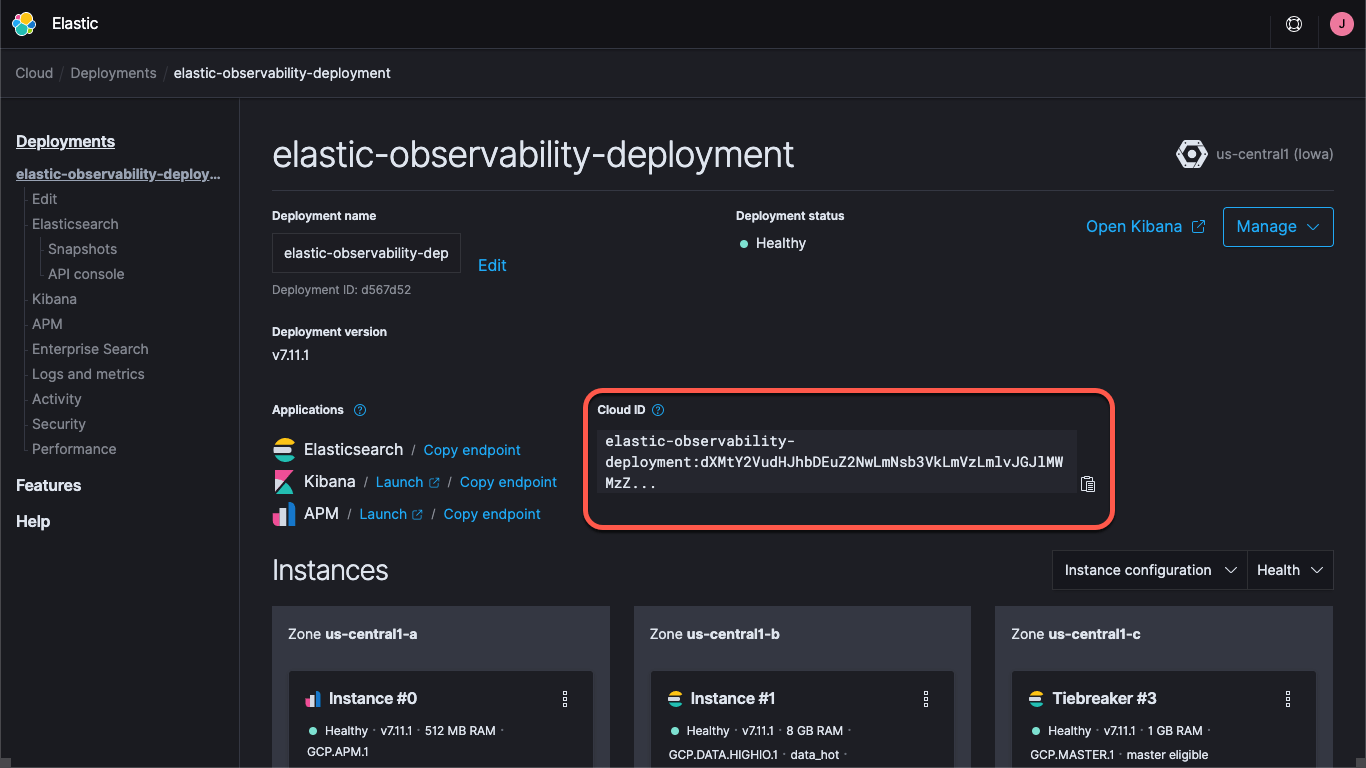
Quand vous créez un déploiement sur Elastic Cloud, vous obtenez un mot de passe pour l'utilisateur elastic. Dans cet article, nous utilisons ces identifiants par souci de simplicité. Cependant, la bonne pratique consiste à créer des clés API ou les utilisateurs et les rôles bénéficiant des privilèges minimums requis pour la tâche concernée.
Maintenant, chargeons les tableaux de bord par défaut pour Metricbeat et Filebeat. Il suffit de le faire une seule fois. La procédure est la même pour chaque instance Beat. Pour charger le support Metricbeat, exécutez la commande suivante.
docker run --rm \
--name=metricbeat-setup \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false \
setup
Cette commande crée un conteneur Metricbeat (appelé metricbeat-setup), charge le fichier metricbeat.docker.yml que nous avons téléchargé, se connecte à l'instance Kibana (provenant du champ cloud.id) et exécute la commande setup qui charge les tableaux de bord. Si vous n'utilisez pas Elastic Cloud, vous avez fourni les URL de Kibana et d'Elasticsearch via les champs setup.kibana.host et output.elasticsearch.hosts avec les champs d'identifiants individuels, qui devraient ressembler à ce qui suit.
docker run --rm \
--name=metricbeat-setup \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E setup.kibana.host=localhost:5601 \
-E setup.kibana.username=elastic \
-E setup.kibana.password=your-password \
-E output.elasticsearch.hosts=localhost:9200 \
-E output.elasticsearch.username=elastic \
-E output.elasticsearch.password=your-password \
-e -strict.perms=false \
setup
La commande -e -strict.perms=false permet d'atténuer un inévitable problème d'autorisation et de propriété du fichier Docker.
De même, pour configurer le support des logs, vous exécutez une commande similaire pour Filebeat.
docker run --rm \
--name=filebeat-setup \
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
docker.elastic.co/beats/filebeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false \
setup
Par défaut, ces fichiers de configuration sont configurés pour monitorer des conteneurs génériques en en rassemblant les indicateurs et les logs. Dans une certaine mesure, cela est utile, car nous voulons nous assurer qu'ils capturent également les indicateurs et les logs spécifiques aux services. Dans ce but, nous configurons nos conteneurs Metricbeat et Filebeat afin d'utiliser la fonction Autodiscover, comme expliqué précédemment. Pour ce faire, plusieurs méthodes existent. Nous pouvons faire en sorte que les configurations Beats recherchent des noms ou des images spécifiques. Cependant, nous devons disposer de nombreuses connaissances en amont. Nous allons donc utiliser la fonction Autodiscover basée sur les indices et laisser les conteneurs instruire directement Beats sur la méthode de monitoring à privilégier.
Grâce à la fonction Autodiscover basée sur les indices, nous ajoutons des étiquettes aux conteneurs Docker. Quand d'autres conteneurs se lancent, les conteneurs metricbeat et filebeat (que nous n'avons pas encore lancé) reçoivent une notification les autorisant à commencer le monitoring. Nous voulons configurer les conteneurs de broker pour que les modules Metricbeat et Filebeat de Kafka les monitorent. Nous voulons également que Metricbeat utilise le module ZooKeeper pour les indicateurs. Filebeat rassemble les logs ZooKeeper sans effectuer d'analyse spéciale.
La configuration de ZooKeeper est plus simple à réaliser que celle de Kafka. Nous allons donc commencer par là. La configuration initiale dans notre fichier docker-compose.yml pour ZooKeeper ressemble à ce qui suit.
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
Nous voulons ajouter un bloc labels au fichier YAML afin d'indiquer le module, les informations de connexion et les ensembles d'indicateurs. Il ressemble à ce qui suit.
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server
Ces étiquettes indiquent au conteneur metricbeat qu'il doit utiliser le module zookeeper pour le monitorer et qu'il peut y accéder via l'hôte ou le port zookeeper:2181. Il s'agit du port sur lequel ZooKeeper est configuré pour recevoir des données. Les étiquettes indiquent également au conteneur d'utiliser les ensembles d'indicateurs mntr et server depuis le module ZooKeeper. Par ailleurs, les versions récentes de ZooKeeper verrouillent certains "mots à quatre lettres", selon leur appellation. Nous devons donc ajouter les commandes srvr et mntr à la liste approuvée dans notre déploiement via KAFKA_OPTS. Alors, la configuration de ZooKeeper dans le fichier compose ressemble à ce qui suit.
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
KAFKA_OPTS: "-Dzookeeper.4lw.commands.whitelist=srvr,mntr"
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server
Il est plutôt facile de capturer les logs des brokers. Nous ajoutons simplement une étiquette à chacun pour le module de logging co.elastic.logs/module=kafka. Pour les indicateurs des brokers, la situation est un peu plus compliquée. Il existe cinq ensembles d'indicateurs dans le module Kafka de Metricbeat :
- les indicateurs des groupes de consommateurs ;
- les indicateurs des partitions ;
- les indicateurs de brokers ;
- les indicateurs des consommateurs ;
- les indicateurs des éditeurs.
Les deux premiers ensembles d'indicateurs proviennent des brokers eux-mêmes, et les trois derniers de JMX. Les deux derniers, consumer et producer, s'appliquent uniquement aux consommateurs et aux éditeurs basés sur Java (c'est-à-dire les clients du cluster Kafka), respectivement. Nous n'en parlons pas ici. (Toutefois, sachez qu'ils suivent les mêmes modèles que nous présentons dans cet article.) Commençons par les deux premiers ensembles d'indicateurs, car ils sont configurés de la même manière. La configuration initiale de Kafka dans notre fichier compose pour broker1 ressemble à ce qui suit.
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker1:29091,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: broker1
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29091
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
Comme dans le cas de la configuration pour ZooKeeper, nous devons ajouter des étiquettes pour indiquer à Metricbeat la méthode de collecte des indicateurs de Kafka.
labels:
- co.elastic.logs/module=kafka
- co.elastic.metrics/module=kafka
- co.elastic.metrics/metricsets=partition,consumergroup
- co.elastic.metrics/hosts='$${data.container.name}:9091'
Ainsi, les modules kafka de Metricbeat et Filebeat sont configurés pour rassembler les logs Kafka, mais aussi les indicateurs partition et consumergroup depuis le conteneur broker1 sur le port 9091. Nous précisons que nous avons utilisé une variable, data.container.name (précédé du symbole du dollar en tant que caractère d'échappement), au lieu du nom d'hôte. Vous pouvez utiliser le modèle que vous préférez. Nous devons recommencer l'opération pour chaque broker en réglant le port 9091 à chaque fois. (Voilà pourquoi nous les avons alignés au début. Nous allons utiliser 9092 et 9093 pour les brokers 2 et 3, respectivement.)
Nous pouvons lancer le cluster Confluent en exécutant docker-compose up --detach. Nous pouvons également lancer Metricbeat et Filebeat. Ils vont commencer à rassembler les indicateurs et les logs de Kafka.
Une fois le cluster cp-all-in-one de Kafka en place, il crée et exécute son propre réseau virtuel appelé cp-all-in-one_default. Étant donné que nous utilisons des noms d'hôte et de service dans nos étiquettes, Metricbeat doit s'exécuter sur le même réseau pour pouvoir traiter les noms et se connecter de manière appropriée. Pour lancer Metricbeat, nous ajoutons le nom du réseau à la commande d'exécution.
docker run -d \
--name=metricbeat \
--user=root \
--network cp-all-in-one_default \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
La commande d'exécution de Filebeat est similaire, mais n'a pas besoin du réseau. Elle ne se connecte pas aux autres conteneurs, mais directement depuis l'hôte Docker.
docker run -d \
--name=filebeat \
--user=root \
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
--volume="/mnt/data/docker/containers:/var/lib/docker/containers:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/filebeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
Dans chaque scénario, nous chargeons les fichiers YAML de configuration, mappons le fichier docker.sock depuis l'hôte jusqu'au conteneur et ajoutons les informations relatives à la connectivité. (Si vous exécutez un cluster autogéré, utilisez les mêmes identifiants que lors du chargement du support.) Il est à noter que si vous exécutez depuis Docker Desktop sur un Mac, vous n'avez pas accès aux logs, car ils sont stockés dans la machine virtuelle.
Visualisation de l'historique et des performances de Kafka et de ZooKeeper
Désormais, nous capturons les logs spécifiques aux services depuis nos brokers Kafka, mais aussi les logs et les indicateurs depuis Kafka et ZooKeeper. Si vous parcourez les tableaux de bord dans Kibana et utilisez les filtres, vous devriez voir les tableaux de bord pour Kafka.
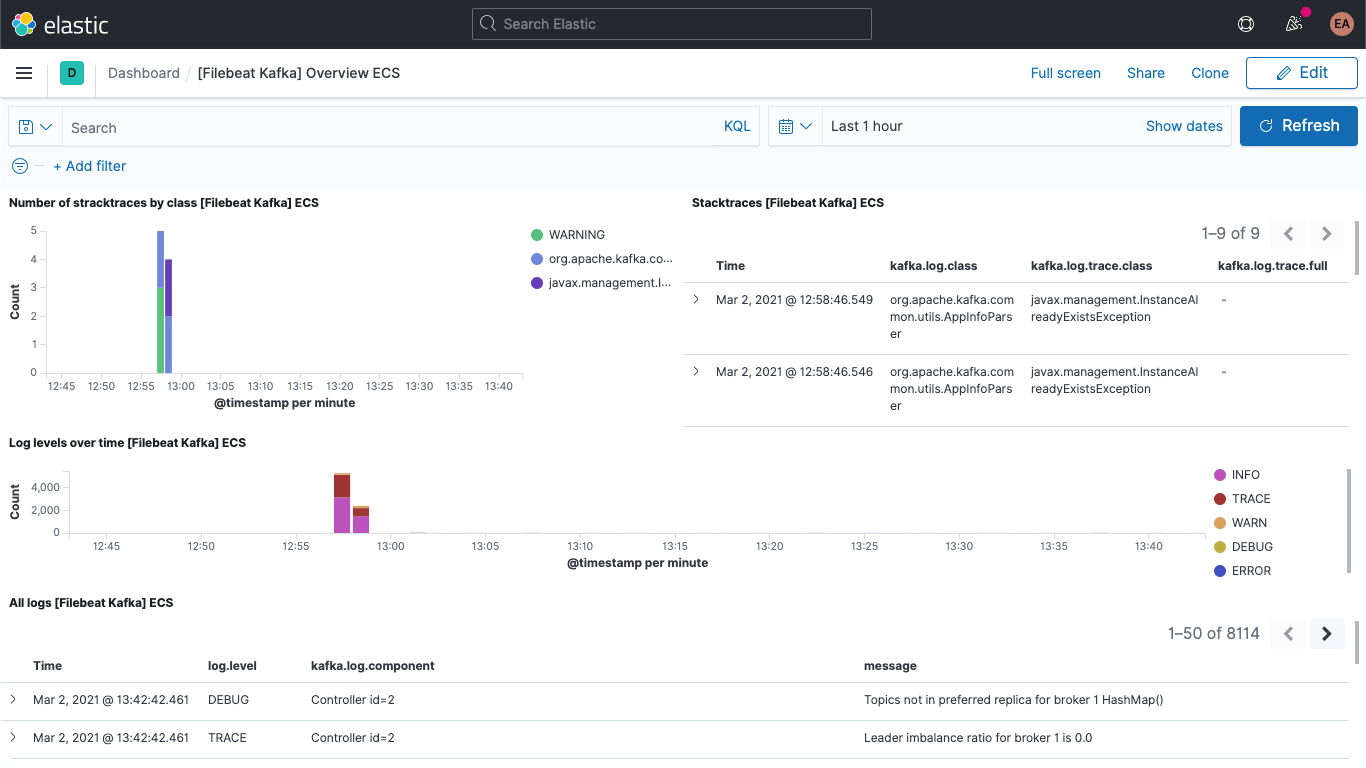
Le tableau de bord des logs de Kafka doit être inclus.
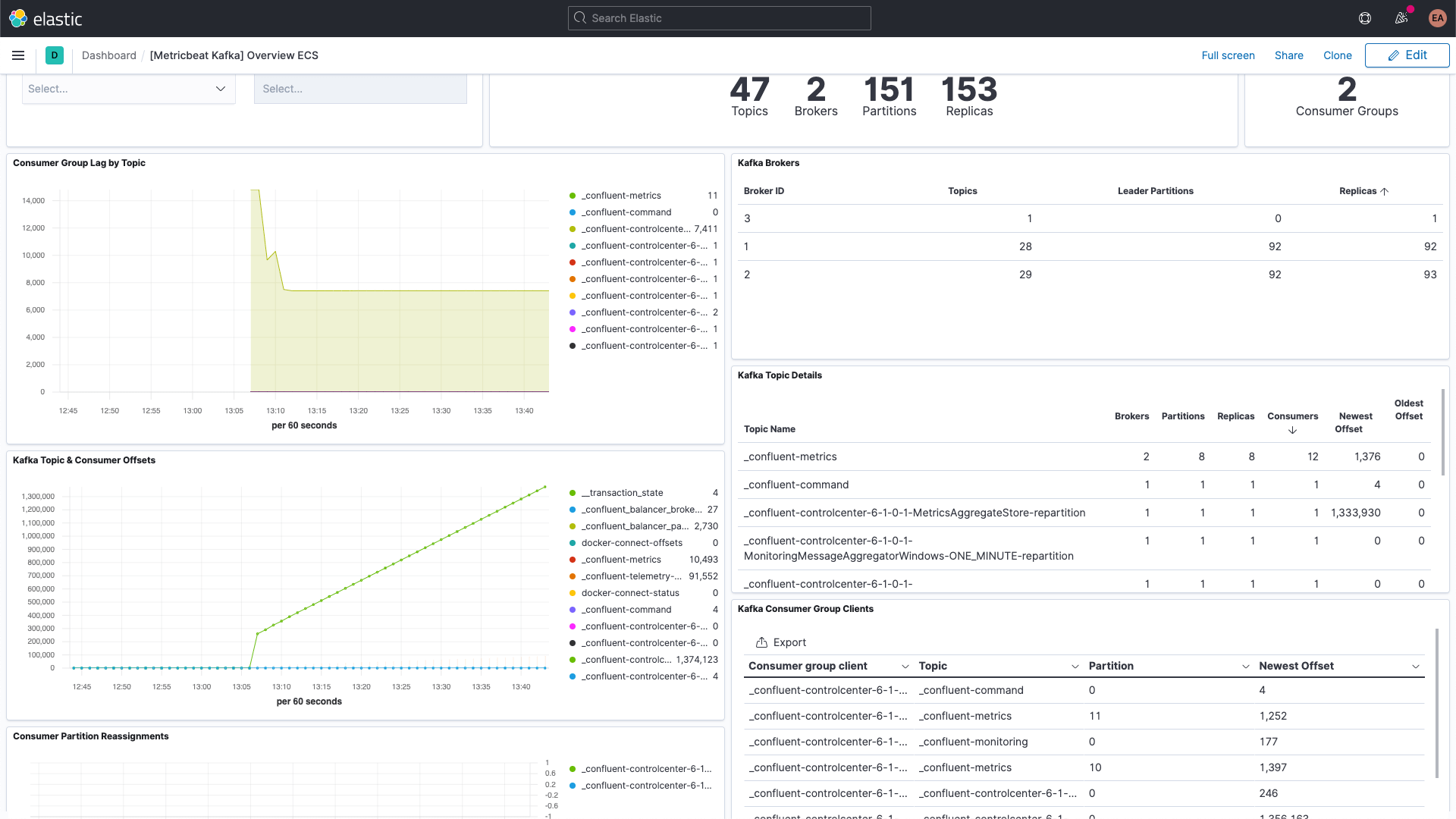
Tout comme le tableau de bord des indicateurs de Kafka.
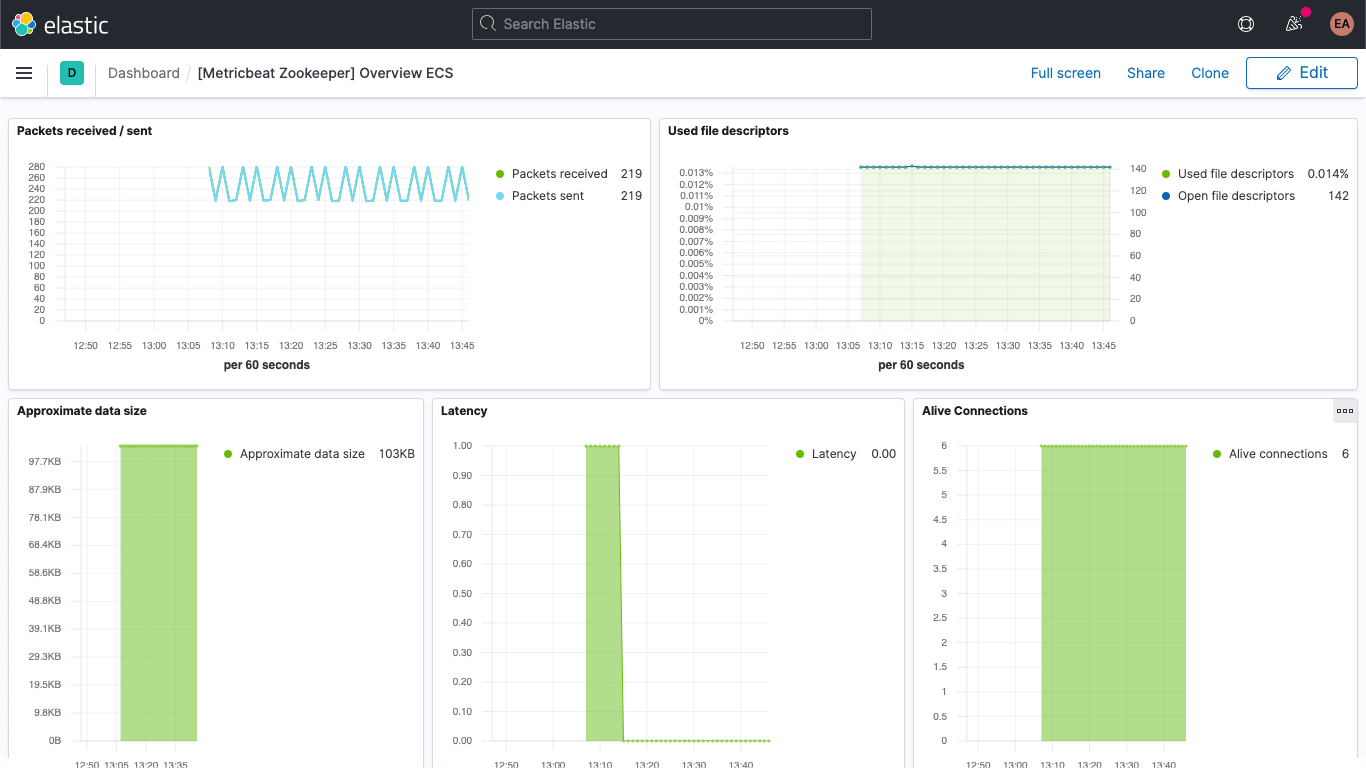
Un tableau de bord vous montre également les indicateurs de ZooKeeper.
En outre, vos logs Kafka et ZooKeeper sont disponibles dans l'application Logs de Kibana. Ainsi vous pouvez appliquer des filtres, mener des recherches et les décomposer.
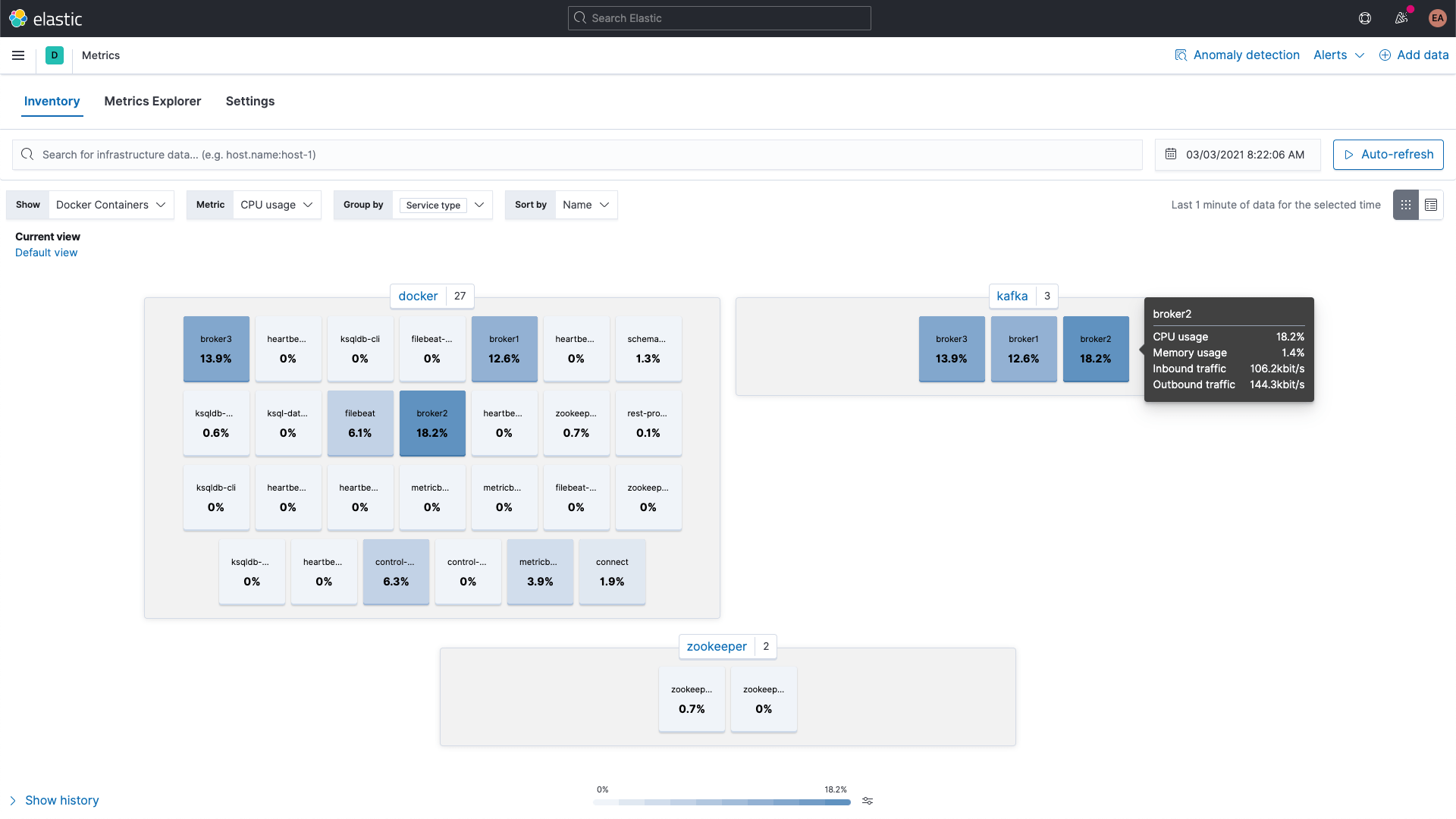
Par ailleurs, vous pouvez parcourir les indicateurs des conteneurs Kafka et ZooKeeper grâce à l'application Metrics dans Kibana. Voici une vue des données regroupées par type de service.
Indicateurs de brokers
Revenons un peu en arrière et rassemblons également les indicateurs de l'ensemble broker dans le module kafka. Nous vous avons expliqué plus haut que ces indicateurs étaient récupérés de JMX. Les ensembles d'indicateurs de brokers, d'éditeurs et de consommateurs exploitent discrètement Jolokia, un pont de JMX vers HTTP. L'ensemble d'indicateurs broker fait également partie du module kafka. Or, comme il utilise JMX, il doit passer par un port différent de celui des ensembles consumergroup et partition. Par conséquent, nous avons besoin d'un nouveau bloc dans les labels pour nos brokers, à l'instar de la configuration des annotations pour les divers ensembles d'indices.
En outre, nous devons inclure le fichier jar pour Jolokia. Nous l'ajoutons aux conteneurs de broker via un volume et le configurons. Comme expliqué sur la page de téléchargement, la version actuelle de l'agent JVM de Jolokia est 1.6.2. Nous nous servons donc de celle-ci. (-OL indique à cURL d'enregistrer le fichier en tant que nom distant et de suivre les redirections.)
curl -OL https://search.maven.org/remotecontent?filepath=org/jolokia/jolokia-jvm/1.6.2/jolokia-jvm-1.6.2-agent.jar
Nous ajoutons une section à la configuration de chaque broker afin de joindre le fichier JAR aux conteneurs.
volumes:
- ./jolokia-jvm-1.6.2-agent.jar:/home/appuser/jolokia.jar
Nous ajoutons aussi KAFKA_JVM_OPTS pour joindre le fichier JAR en tant qu'agent Java. (Remarque : les ports sont configurés par broker. Par conséquent, les ports 8771-8773 sont destinés aux brokers 1, 2 et 3.)
KAFKA_JMX_OPTS: '-javaagent:/home/appuser/jolokia.jar=port=8771,host=broker1 -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false'
Nous n'utilisons aucune forme d'authentification. Par conséquent, nous devons ajouter quelques signaux au moment du lancement. Il est à noter que le chemin du fichier jolokia.jar dans KAFKA_JMX_OPTS correspond à celui du volume.
Nous devons apporter quelques ajustements mineurs. Étant donné que nous utilisons Jolokia, nous n'avons plus besoin d'exposer KAFKA_JMX_PORT dans la section ports. Au contraire, nous exposons le port sur lequel Jolokia reçoit des données, c'est-à-dire le port 8771. En outre, nous supprimons les valeurs KAFKA_JMX_* dans la configuration.
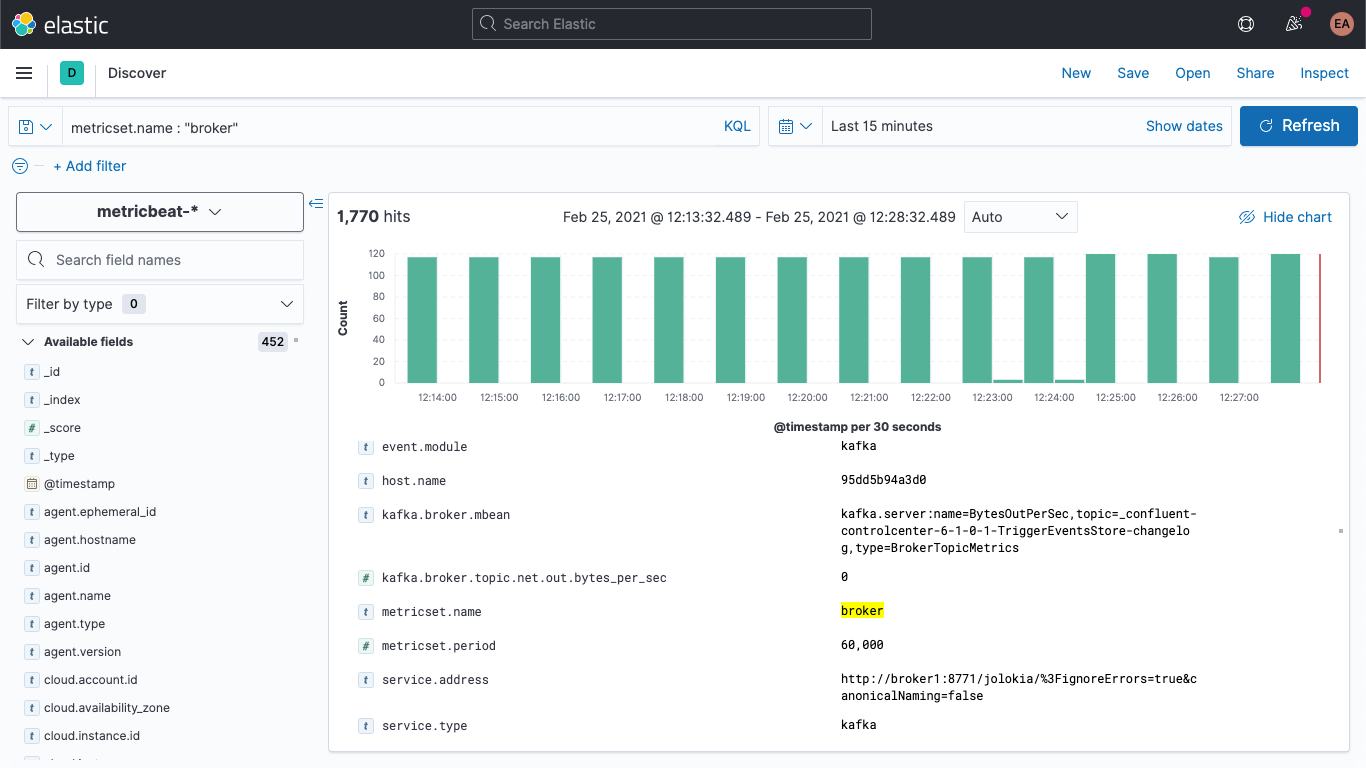
Si nous relançons notre cluster Kafka (docker-compose up --detach), les indicateurs de broker vont commencer à apparaître dans notre déploiement Elasticsearch. Si nous passons à l'onglet discover, sélectionnons le modèle d'indexation metricbeat-* et recherchons metricset.name : "broker", nous obtenons effectivement des données.
La structure des indicateurs de broker ressemble à ce qui suit.
kafka
└─ broker
├── address
├── id
├── log
│ └── flush_rate
├── mbean
├── messages_in
├── net
│ ├── in
│ │ └── bytes_per_sec
│ ├── out
│ │ └── bytes_per_sec
│ └── rejected
│ └── bytes_per_sec
├── replication
│ ├── leader_elections
│ └── unclean_leader_elections
└── request
├── channel
│ ├── fetch
│ │ ├── failed
│ │ └── failed_per_second
│ ├── produce
│ │ ├── failed
│ │ └── failed_per_second
│ └── queue
│ └── size
├── session
│ └── zookeeper
│ ├── disconnect
│ ├── expire
│ ├── readonly
│ └── sync
└── topic
├── messages_in
└── net
├── in
│ └── bytes_per_sec
├── out
│ └── bytes_per_sec
└── rejected
└── bytes_per_sec
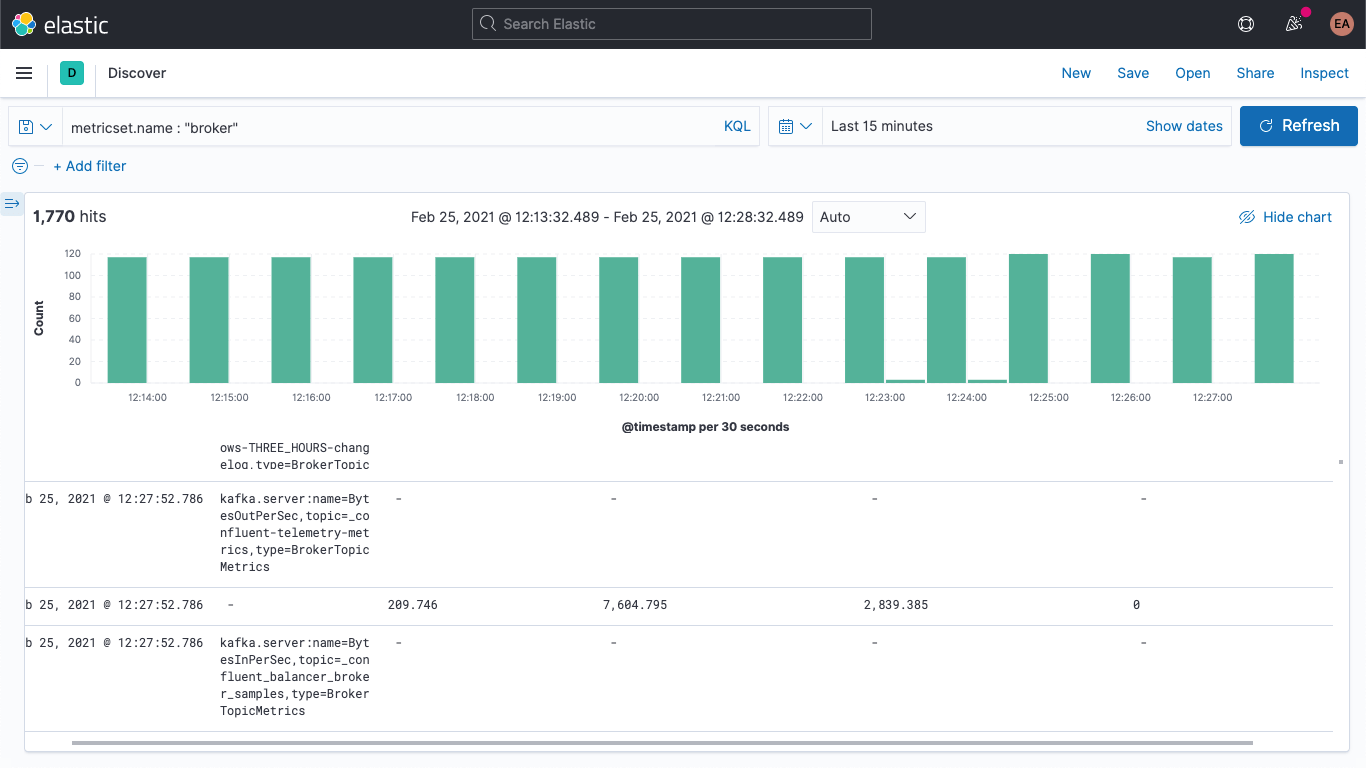
Comme l'indique le champ kafka.broker.mbean, les données s'affichent principalement sous forme de paires associant des noms et des valeurs. Observons le champ kafka.broker.mbean en prenant un indicateur comme exemple.
kafka.server:name=BytesOutPerSec,topic=_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog,type=BrokerTopicMetrics
La commande ci-dessus comprend le nom de l'indicateur (BytesOutPerSec), le sujet Kafka auquel il se réfère (_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog) et le type d'indicateur (BrokerTopicMetrics). Selon le nom et le type de l'indicateur, différents champs sont configurés. Dans cet exemple, seul kafka.broker.topic.net.out.bytes_per_sec est renseigné. (Sa valeur est 0.) Si ces données sont représentées en colonnes, il est évident que les informations obtenues sont très sommaires.
Il est possible de réduire la vue en ajoutant un pipeline d'ingestion afin de décomposer le champ mbean en champs individuels, ce qui nous permet de visualiser plus facilement les données. Répartissons les données en trois champs :
- KAFKA_BROKER_METRIC (qui correspond à beBytesOutPerSec dans l'exemple ci-dessus) ;
- KAFKA_BROKER_TOPIC (qui correspond à _confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog dans l'exemple ci-dessus) ;
- KAFKA_BROKER_TYPE (qui correspond à BrokerTopicMetrics dans l'exemple ci-dessus).
Dans Kibana, allez dans la section "Dev Tools" (Outils de développement).
Collez la commande suivante afin de définir un pipeline d'ingestion appelé kafka-broker-fields.
PUT _ingest/pipeline/kafka-broker-fields
{
"processors": [
{
"grok": {
"if": "ctx.kafka?.broker?.mbean != null",
"field": "kafka.broker.mbean",
"patterns": ["kafka.server:name=%{GREEDYDATA:kafka_broker_metric},topic=%{GREEDYDATA:kafka_broker_topic},type=%{GREEDYDATA:kafka_broker_type}"
]
}
}
]
}
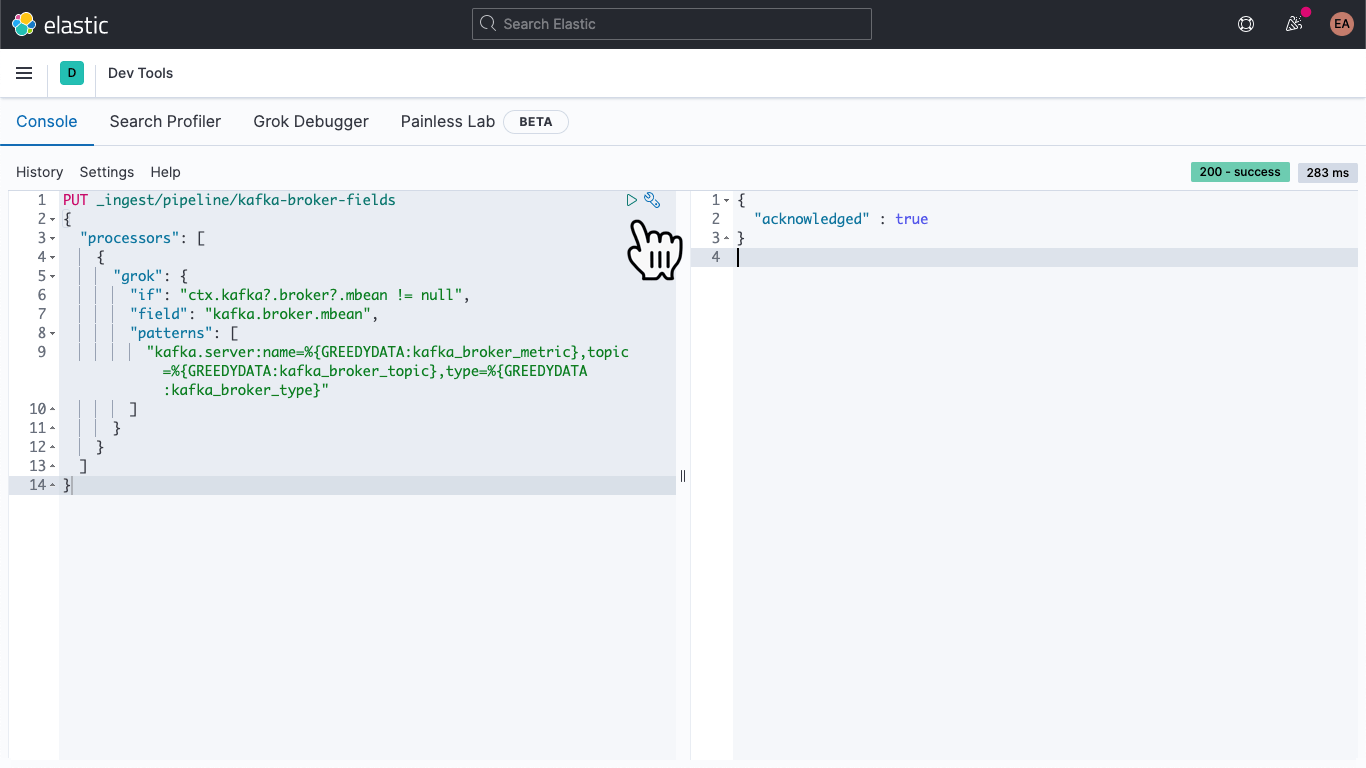
Puis, cliquez sur l'icône de lecture. Vous devriez obtenir le résultat illustré ci-dessus.
Notre pipeline d'ingestion est opérationnel, mais nous ne l'avons pas encore exploité. Nos anciennes données sont toujours sommaires et difficiles d'accès, tandis que de nouvelles informations continuent d'être recueillies de la même manière. Commençons par résoudre ce dernier problème.
Ouvrez le fichier metricbeat.docker.yml dans votre éditeur de texte de prédilection et ajoutez une ligne au bloc output.elasticsearch. (Vous pouvez supprimer les configurations d'hôtes, de nom d'utilisateur et de mot de passe si vous ne les utilisez pas.) Ensuite, indiquez notre pipeline de la manière suivante.
output.elasticsearch: pipeline: kafka-broker-fields
Ainsi, Elasticsearch sait que chaque nouveau document reçu doit passer par ce pipeline afin de vérifier notre champ mbean. Redémarrez Metricbeat.
docker rm --force metricbeat
docker run -d \
--name=metricbeat \
--user=root \
--network cp-all-in-one_default \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
Nous pouvons vérifier dans Discover que les nouveaux documents contiennent bien les nouveaux champs.
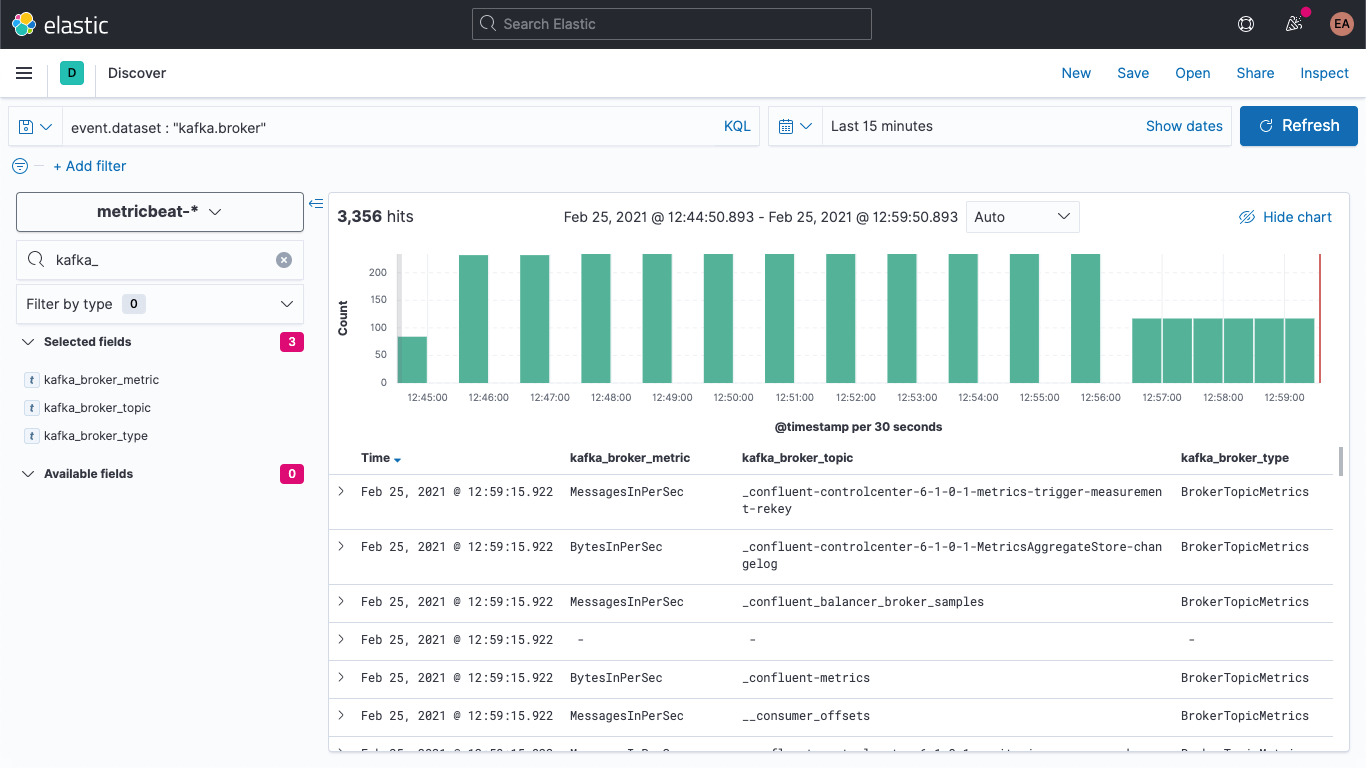
Nous pouvons également mettre à jour les anciens documents afin que ces champs soient tout de même renseignés. Revenez à la section DevTools et exécutez la commande suivante.
POST metricbeat-*/_update_by_query?pipeline=kafka-broker-fields
Elle affichera probablement un message indiquant qu'elle a expiré. Toutefois, elle s'exécute en arrière-plan et se terminera de manière asynchrone.
Visualisation des indicateurs de brokers
Passez à l'application Metrics et sélectionnez l'onglet "Metrics Explorer" pour tester nos nouveaux champs. Collez kafka.broker.topic.net.in.bytes_per_sec et kafka.broker.topic.net.out.bytes_per_sec pour les voir s'afficher ensemble.
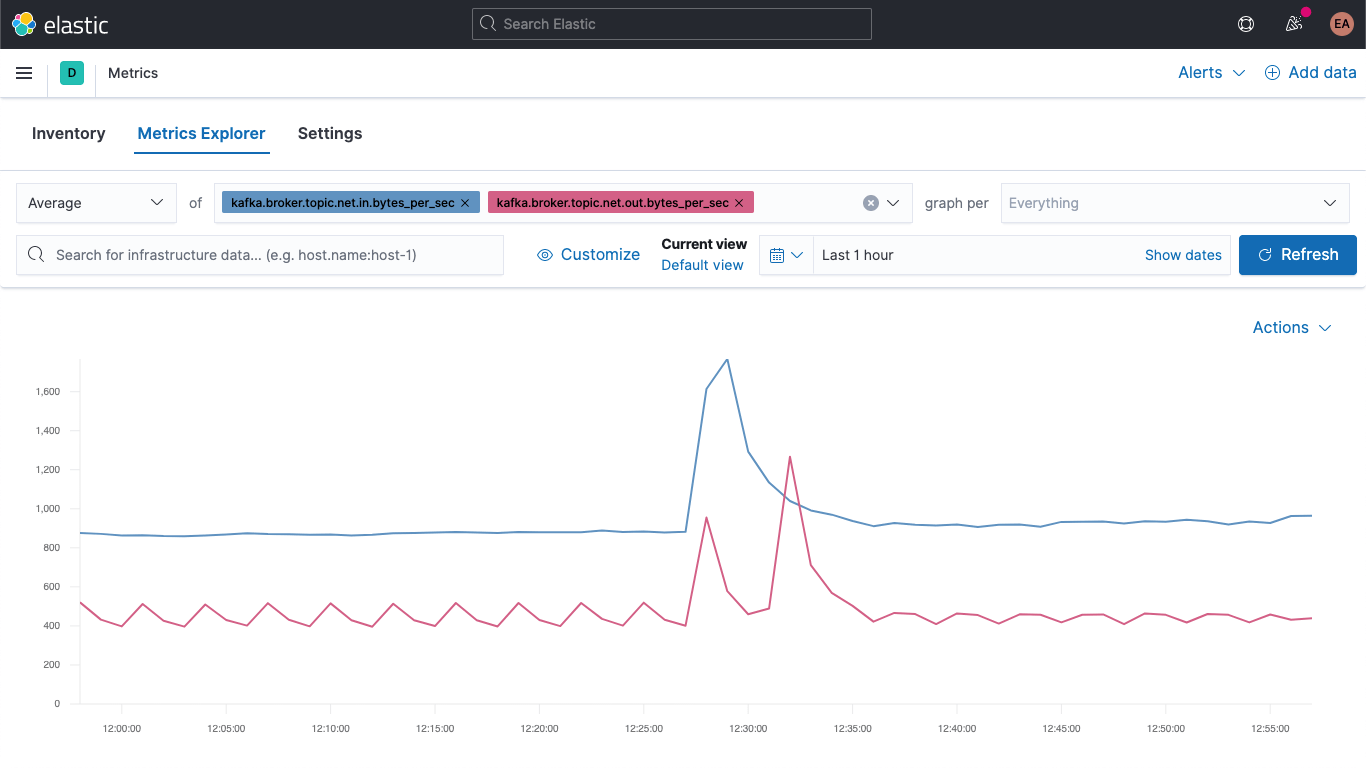
Puis, en exploitant l'un de nos nouveaux champs, ouvrez la liste déroulante "graph per" et sélectionnez kafka_broker_topic.
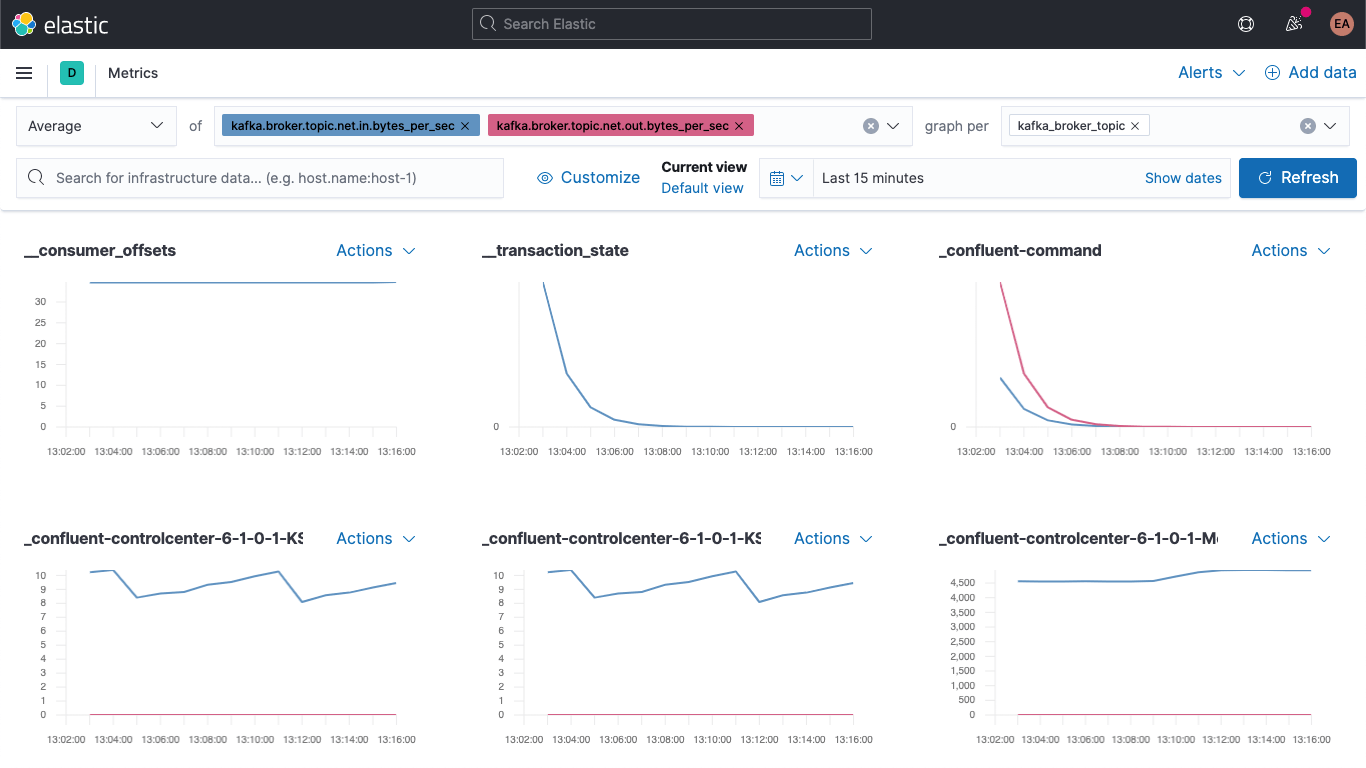
Certains champs affichent une valeur nulle. (Le cluster n'est pas encore très actif.) Toutefois, il est beaucoup plus facile d'afficher les indicateurs de brokers et de les décomposer par sujet à ce stade. Vous pouvez exporter n'importe lequel de ces graphes en tant que visualisations et les charger dans votre tableau de bord d'indicateurs Kafka ou créer vos propres visualisations à l'aide des différents graphes et graphiques disponibles dans Kibana. Si vous préférez créer des visualisations par glisser-déposé, essayez Lens.
Pour partir du bon pied avec les visualisations des indicateurs de brokers, nous vous conseillons de vous pencher sur les défaillances des blocs de récupération et de production.
kafka
└─ broker
└── request
└── channel
├── fetch
│ ├── failed
│ └── failed_per_second
├── produce
│ ├── failed
│ └── failed_per_second
└── queue
└── size
La gravité des défaillances indiquées ci-dessus dépend du cas d'utilisation. Si elles surviennent dans un écosystème où nous obtenons des mises à jour par intermittence (par exemple, le prix d'actions ou des courbes de température qui sont fournis de manière régulière), la présence de quelques défaillances n'est pas forcément une mauvaise chose. Toutefois, si quelques messages sont oubliés dans un système de commande, les conséquences peuvent s'avérer catastrophiques. En effet, cela signifie qu'un client ne reçoit pas la livraison qu'il attend.
Conclusion
Vous pouvez désormais monitorer ZooKeeper et les brokers Kafka à l'aide d'Elastic Observability. Vous savez également comment exploiter les indices vous permettant de monitorer automatiquement de nouvelles instances de services conteneurisés. Enfin, vous avez appris comment un pipeline d'ingestion peut faciliter la visualisation de vos données. Testez tout cela par vous-même en vous inscrivant à un essai gratuit d'Elasticsearch Service sur Elastic Cloud ou en téléchargeant la Suite Elastic et en l'exécutant en local.
Si vous exécutez un cluster Kafka en tant que service géré ou sur un serveur physique et pas conteneurisé, ne vous inquiétez pas. Très prochainement, cet article sera suivi par d'autres publications consacrées aux sujets suivants :
- Comment monitorer un cluster Kafka autonome avec Metricbeat et Filebeat
- Comment monitorer un cluster Kafka autonome avec Elastic Agent