Elastic Cloud : l'API Elasticsearch Service est désormais en disponibilité générale
Avec la console Elastic Cloud, vous pouvez créer et gérer vos déploiements, consulter des informations de facturation et vous tenir au courant des dernières nouveautés, le tout, en un seul endroit. La console propose une interface utilisateur simple et intuitive pour les tâches courantes de gestion et d'administration.
Même si une interface utilisateur de gestion représente certes un avantage, la plupart des entreprises veulent également une API pour automatiser les tâches et workflows courants, en particulier pour gérer leurs déploiements. Nous sommes donc très heureux d'annoncer la disponibilité générale de l'API Elasticsearch Service pour prendre en charge ces workflows.
Non seulement vous pouvez intégrer l'API directement, mais vous pouvez également utiliser Elastic Cloud Control (ecctl), l'interface de ligne de commande d'Elastic Cloud qui prend désormais en charge l'API Elasticsearch Service. Vous pouvez également utiliser la bibliothèque cloud-sdk-go ou générer un SDK dans un autre langage de programmation.
Avant de voir comment créer et scaler un déploiement avec l'API Elasticsearch Service, étudions tout d'abord quelques scénarios régulièrement rencontrés et les avantages que présente une API dans de tels cas :
Insertion dans des pipelines d'intégration et de livraison continues
Pour bon nombre de nos utilisateurs, la Suite Elastic joue un rôle essentiel dans la stack de production. Or, certains changements que vous introduisez dans votre application peuvent avoir une incidence sur Elasticsearch. C'est le cas si vous optimisez des requêtes ou si vous testez de nouvelles versions de la Suite Elastic.
Un pipeline d'intégration ou de livraison continue permettrait, par exemple, d'effectuer automatiquement un déploiement en respectant les spécifications que vous avez définies, tout en offrant la possibilité d'effectuer une restauration à partir d'un snapshot, afin d'utiliser facilement un ensemble de données de votre cluster de production. Lorsque vous apportez un changement de code spécifique à votre application dans un environnement de développement ou de test, vous en voyez immédiatement les conséquences avant que votre environnement de production soit mis à niveau.
Intégration de nouvelles équipes et de nouveaux cas d'utilisation
La Suite Elastic est une composante essentielle de la stack de production. Mais ce n'est pas tout ! Elle peut également servir pour l'observabilité de votre application et de votre infrastructure. Plutôt que d'avoir un déploiement unique servant différentes finalités, nous recommandons de faire la distinction entre les différents cas d'utilisation et les différentes équipes en utilisant un déploiement dédié dans la mesure du possible. Pourquoi ? Car cela permet de réduire les frictions dues aux éventuelles interférences entre équipes, par exemple lorsqu'un cas d'utilisation gourmand en ressources (ou un bug involontaire) d'une équipe a un impact sur les autres équipes.
Avec Elasticsearch Service, rien de plus simple que de gérer plusieurs déploiements, quel que soit leur nombre. De plus, vous pouvez facilement intégrer votre gestionnaire de configuration ou outil infrastructure-as-code favori, tel que Ansible, Chef, Puppet et Terraform (ou votre portail interne d'entreprise) à notre API. Lorsqu'une nouvelle équipe est intégrée et demande à créer une nouvelle stack de développement, vous pouvez créer un déploiement pour cette équipe à l'aide d'un modèle et d'un dimensionnement adaptés, et le configurer selon ses besoins. Le tout, sans intervention manuelle.
Scaling des déploiements
De nombreux utilisateurs ont besoin de pouvoir programmer le scaling de leur déploiement pour prendre en charge les augmentations ou les baisses d'utilisation, ce, afin d'optimiser les coûts lors des périodes d'inactivité. De tels événements peuvent être prévisibles : on peut escompter par exemple qu'il y aura une augmentation du trafic sur le site web d'une boutique en ligne lors d'un jour férié. Mais ils peuvent être également inattendus, par exemple si une vente de dernière minute non prévue a lieu, entraînant un changement au niveau de l'utilisation des ressources. Avec une API, les clients peuvent mettre en œuvre des workflows de scaling temporels ou basés sur l'utilisation.
Si, en revanche, vous souhaitez mettre en place un scaling basé sur des indicateurs, tels que l'espace disque, le processeur ou la RAM, certaines considérations sont à prendre en compte. Si vous avez diminué la capacité, vous devez par exemple vous assurer que l'espace disque disponible est suffisant pour prendre en charge l'utilisation en cours.
Prise en main de l'API Elasticsearch Service
Comme nous venons de le voir à travers quelques exemples, lorsque nous disposons d'une API, nous n'avons plus besoin de nous connecter à notre console utilisateur pour gérer un déploiement. Maintenant, étudions comment créer et scaler un déploiement avec ecctl, notre outil en ligne de commande, ou cURL directement dans l'API REST.
1. Créer une clé d'API
Pour vous authentifier, vous devez tout d'abord générer une clé d'API qui vous identifiera comme étant le propriétaire du compte. Pour générer cette clé, connectez-vous à la console utilisateur et accédez à la page de gestion des clés d'API sous la section Account (Compte).
Vous pouvez générer plusieurs clés d'API pour gérer plus facilement l'accès à partir de différentes applications. Vous pouvez aussi révoquer une clé sans que cela ait un impact sur les autres.
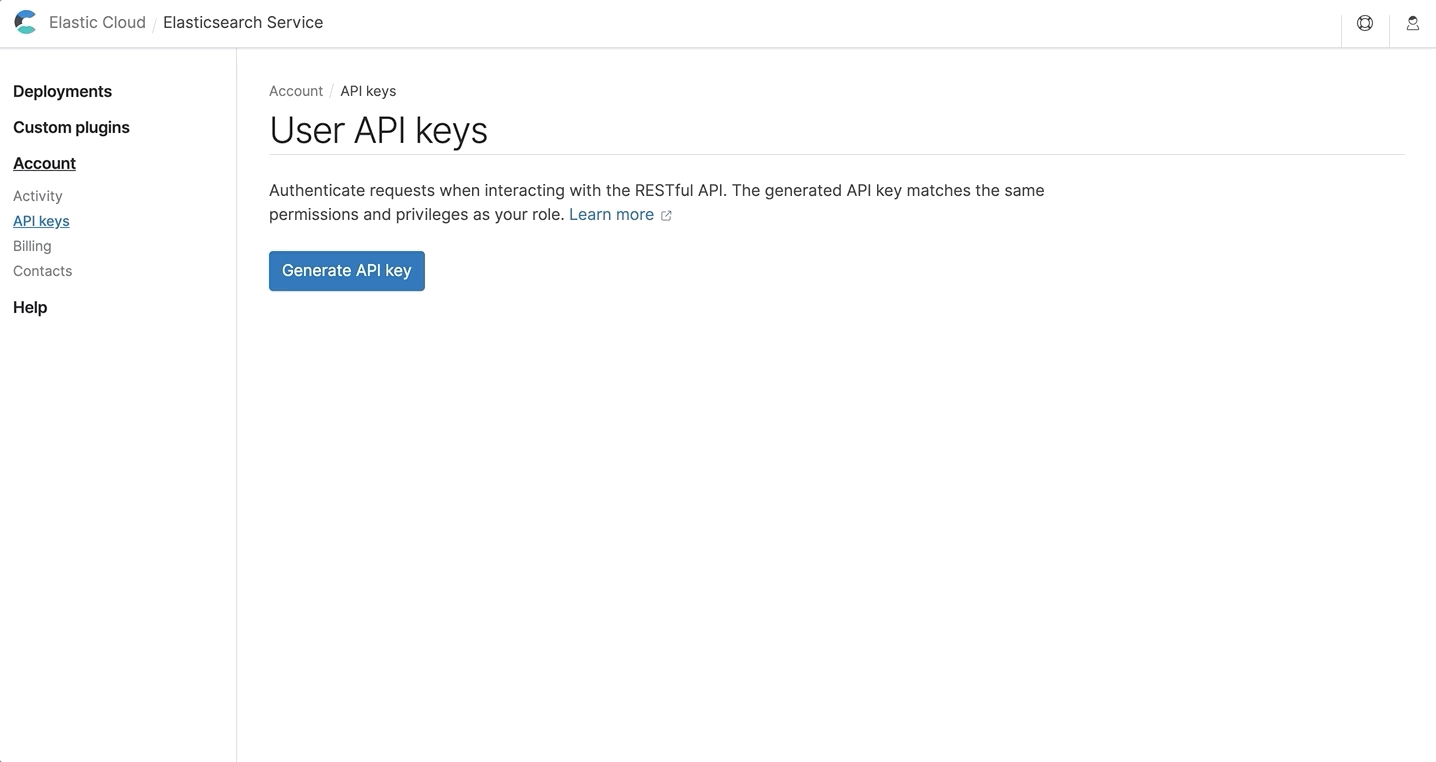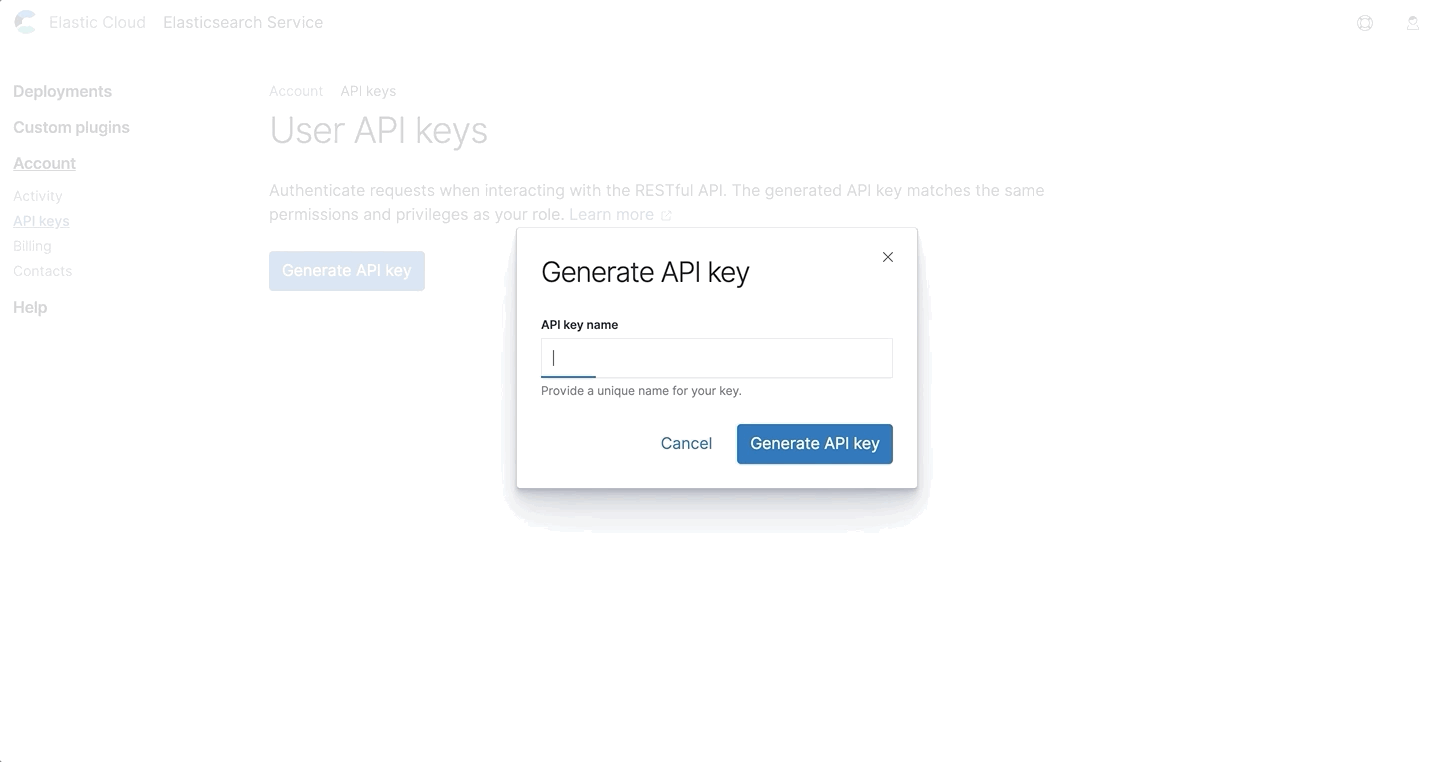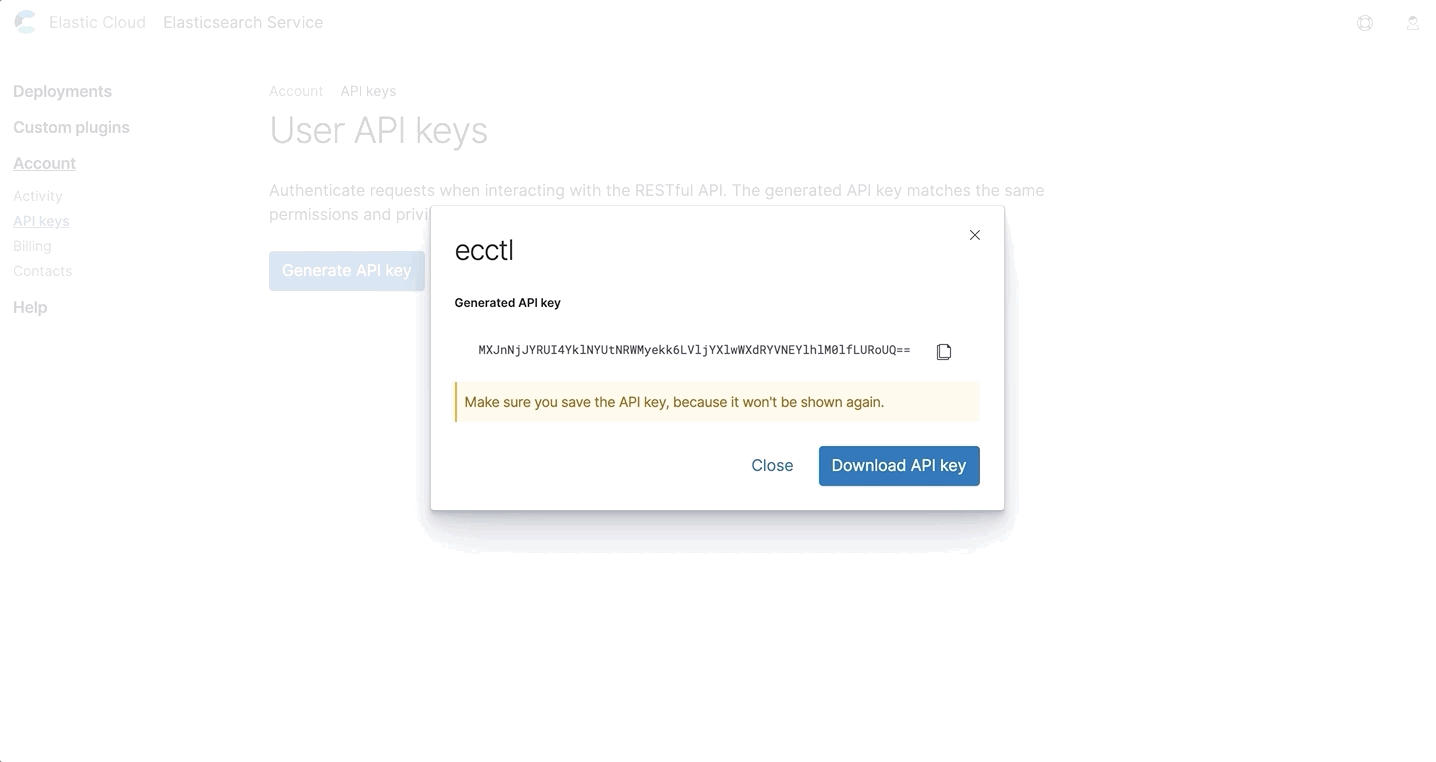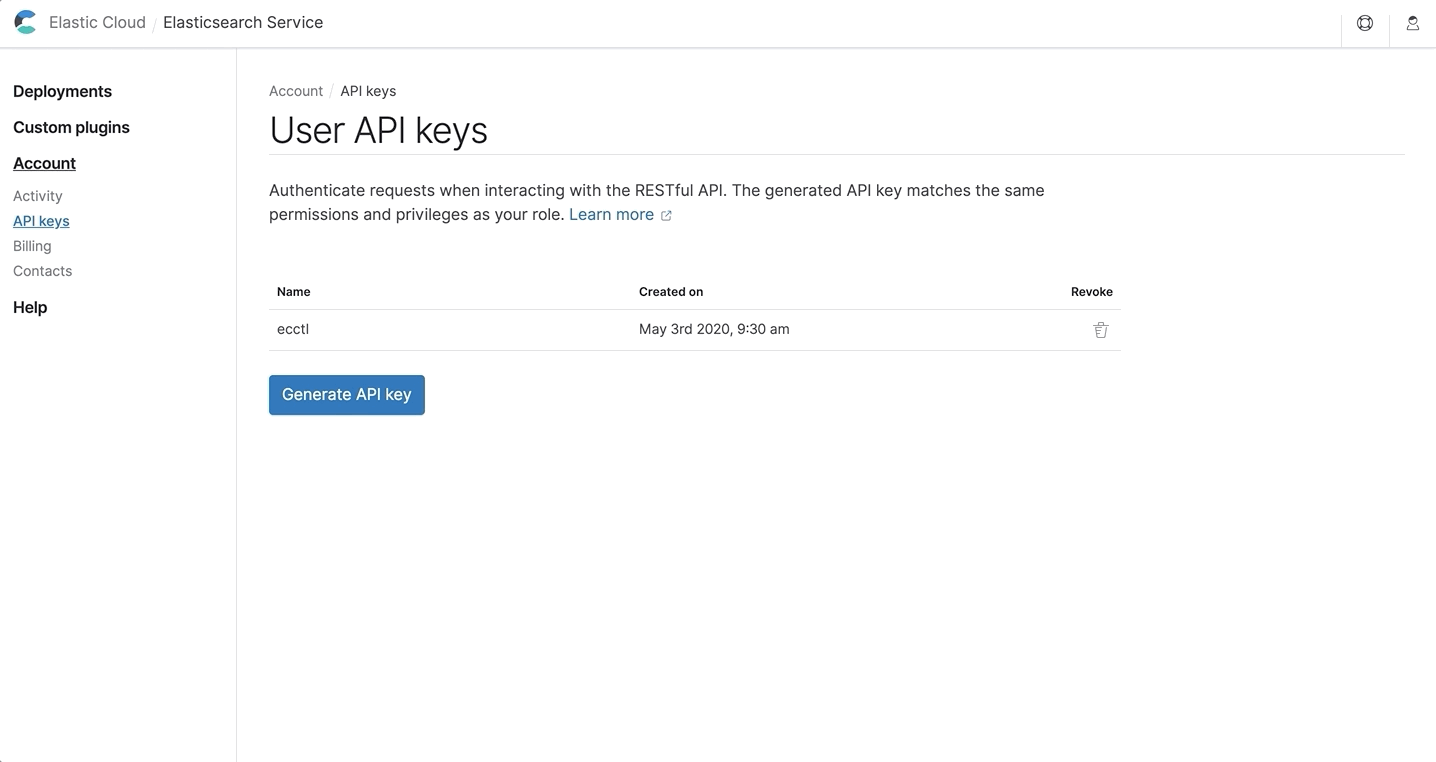
Lorsque vous créez une clé, vous serez invité à saisir de nouveau votre mot de passe, à donner un nom à la clé, puis à la copier ou à la télécharger. Attention : c'est le seul moment où vous verrez la clé. Aussi, assurez-vous de l'enregistrer à un endroit sûr.
2. Configurer ecctl
Si c'est la première fois que vous utilisez ecctl, vous devez l'installer sur votre machine locale. (Les instructions d'installation sont accessibles ici.) Si ecctl est déjà installé, assurez-vous d'utiliser la version 1.0.0-beta3 ou supérieure pour que toutes les commandes abordées dans ce blog soient prises en charge. Nous étudierons également des exemples avec cURL, mais nous recommandons néanmoins d'utiliser ecctl, car il permet d'interagir de façon plus conviviale avec notre API.
Une fois ecctl installé, exécutez la commande ecctl init et utilisez l’assistant de configuration. Lorsque vous êtes invité à choisir le produit, sélectionnez Elasticsearch Service. Choisissez ensuite le format texte ou JSON comme sortie par défaut, et la clé API comme mécanisme d'authentification. Entrez alors la clé API enregistrée lors de l'étape précédente.
Pour tester la configuration et vous assurer qu'elle est correcte, exécutez la commande ecctl deployment list : celle-ci renverra la liste des déploiements actifs.

3. Créer votre premier déploiement
Maintenant que nous disposons de tout ce dont nous avons besoin, créons notre premier déploiement. Elasticsearch Service prend en charge des modèles de déploiement, qui créent un déploiement disposant des composants et du matériel adaptés à votre cas d'utilisation.
Lorsque vous créez un déploiement avec notre API, vous devez préciser le modèle que vous souhaitez utiliser, et la charge utile devra se conformer à la charge utile prévue par le modèle. Vous trouverez une liste des modèles disponibles pour votre fournisseur cloud et votre région dans notre guide d'utilisateur.
Dans cet exemple, choisissons GCP Iowa (us-central1) et le modèle optimisé d'E/S (gcp-io-optimized). Copions le JSON ci-dessous et enregistrons-le en tant que fichier create-deployment.json :
{
"name": "created-via-api",
"resources": {
"elasticsearch": [
{
"region": "gcp-us-central1",
"ref_id": "main-elasticsearch",
"plan": {
"cluster_topology": [
{
"node_type": {
"master": true,
"data": true,
"ingest": true
},
"instance_configuration_id": "gcp.data.highio.1",
"zone_count": 2,
"size": {
"resource": "memory",
"value": 2048
}
}
],
"elasticsearch": {
"version": "7.6.2"
},
"deployment_template": {
"id": "gcp-io-optimized"
}
}
}
],
"kibana": [
{
"region": "gcp-us-central1",
"elasticsearch_cluster_ref_id": "main-elasticsearch",
"ref_id": "main-kibana",
"plan": {
"cluster_topology": [
{
"instance_configuration_id": "gcp.kibana.1",
"zone_count": 1,
"size": {
"resource": "memory",
"value": 1024
}
}
],
"kibana": {
"version": "7.6.2"
}
}
}
],
"apm": [
{
"region": "gcp-us-central1",
"elasticsearch_cluster_ref_id": "main-elasticsearch",
"ref_id": "main-apm",
"plan": {
"cluster_topology": [
{
"instance_configuration_id": "gcp.apm.1",
"zone_count": 1,
"size": {
"resource": "memory",
"value": 512
}
}
],
"apm": {
"version": "7.6.2"
}
}
}
]
}
}
Des options de configuration supplémentaires sont disponibles, comme le paramétrage d'un cluster de monitoring et la restauration à partir d'un snapshot. Toutefois, dans cet exemple, nous allons privilégier la simplicité en créant un déploiement avec un cluster Elasticsearch à haute disponibilité déployé sur deux zones de disponibilité, une seule instance de Kibana et un serveur APM unique. Ensuite, tout ce qu'il nous reste à faire, c'est d'exécuter la commande ecctl ci-dessous pour lancer la création du déploiement.
Pour vous familiariser avec l'API, utilisez la console utilisateur Elastic Cloud pour émettre une requête d'API équivalente à celle que vous avez configurée dans l'interface utilisateur.
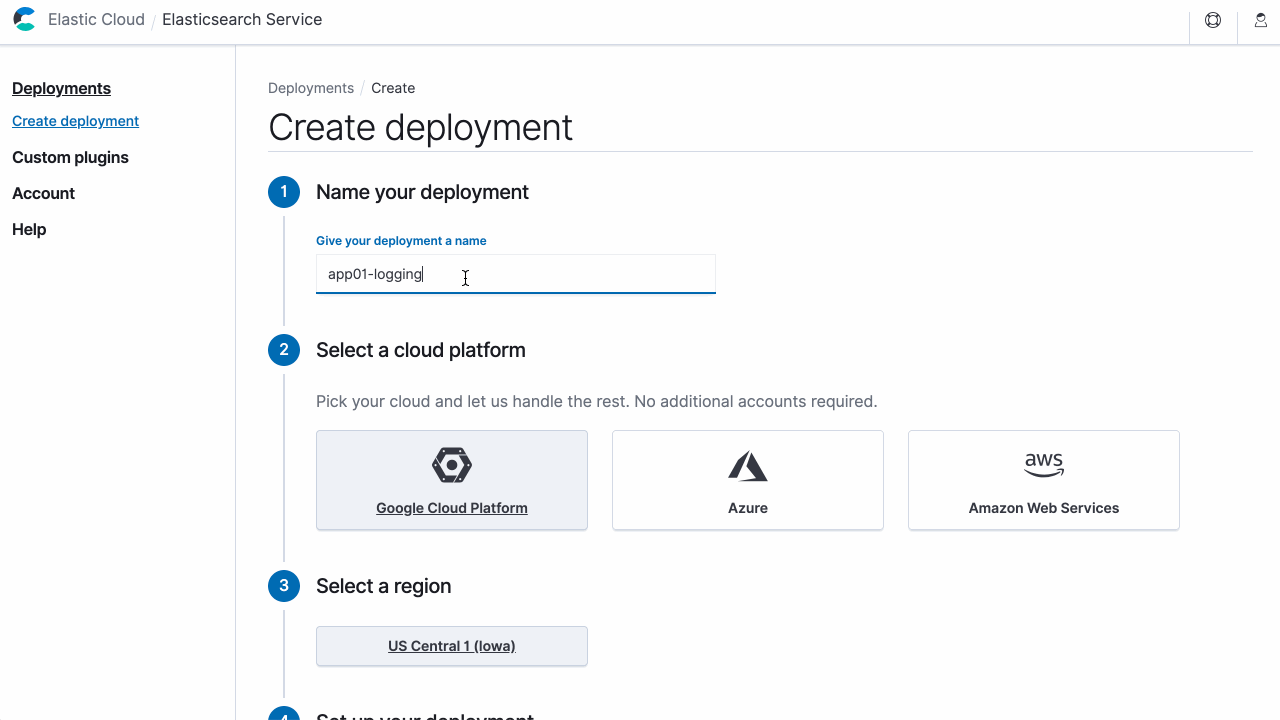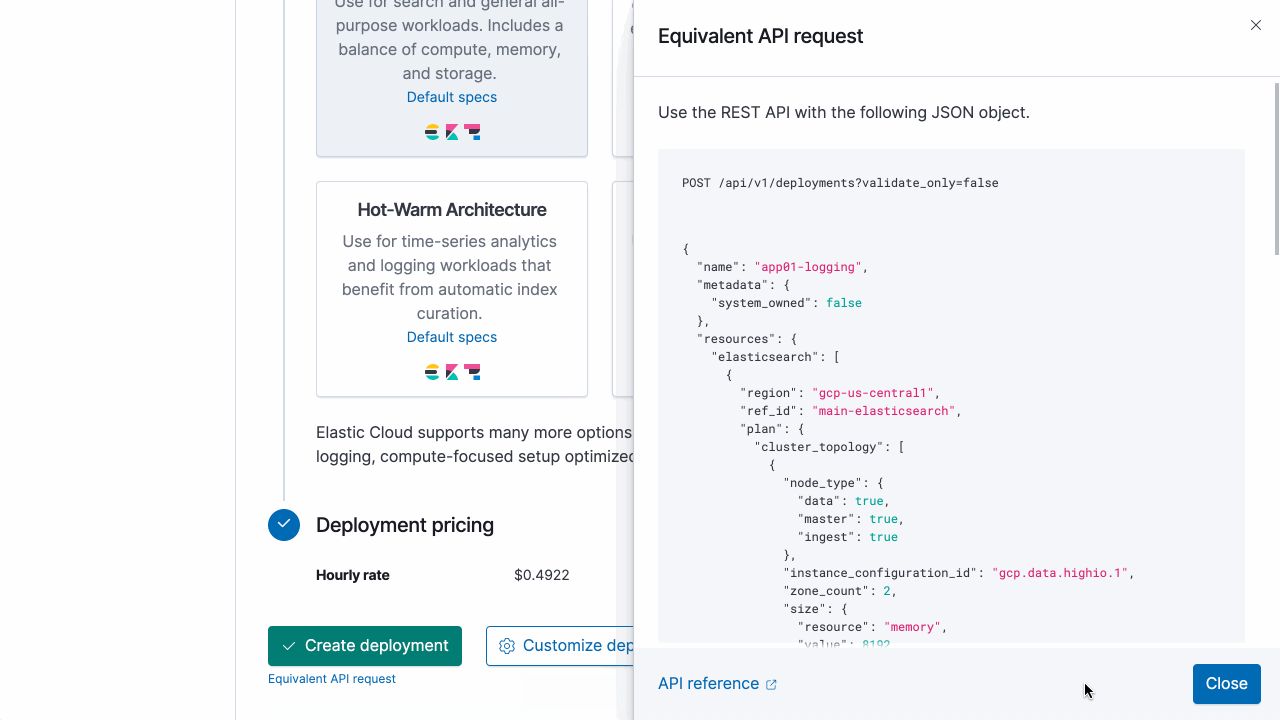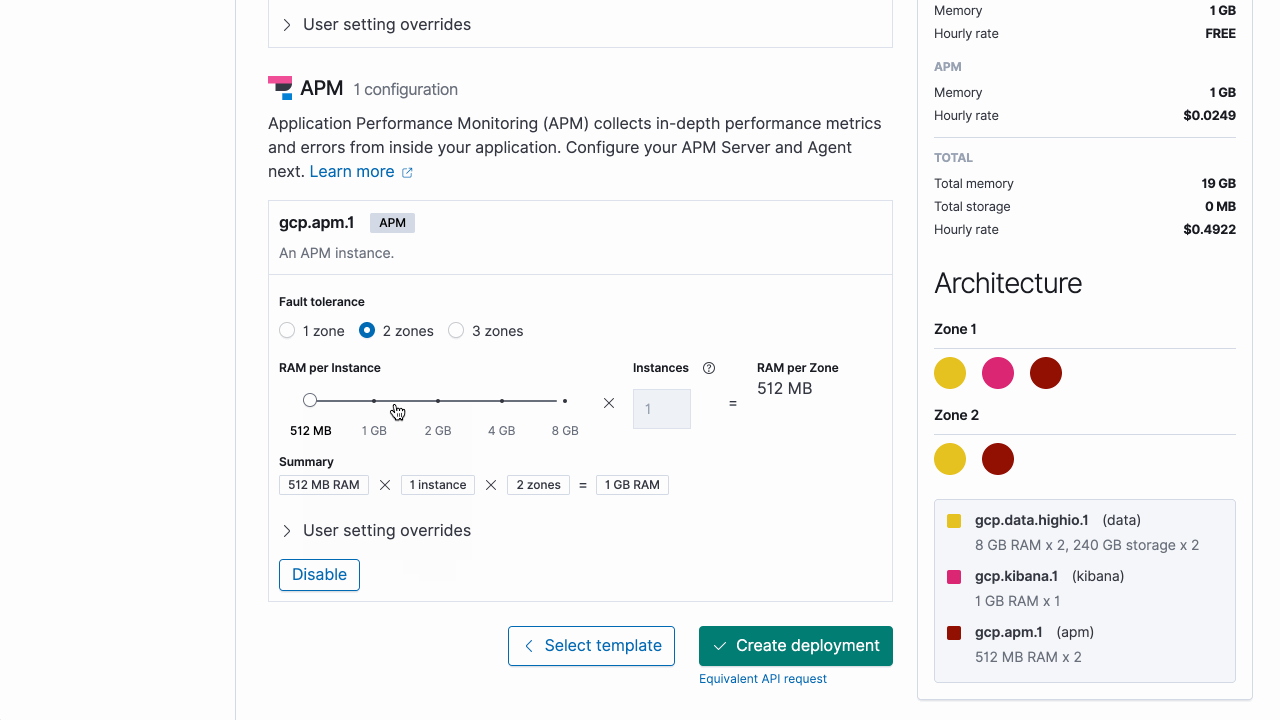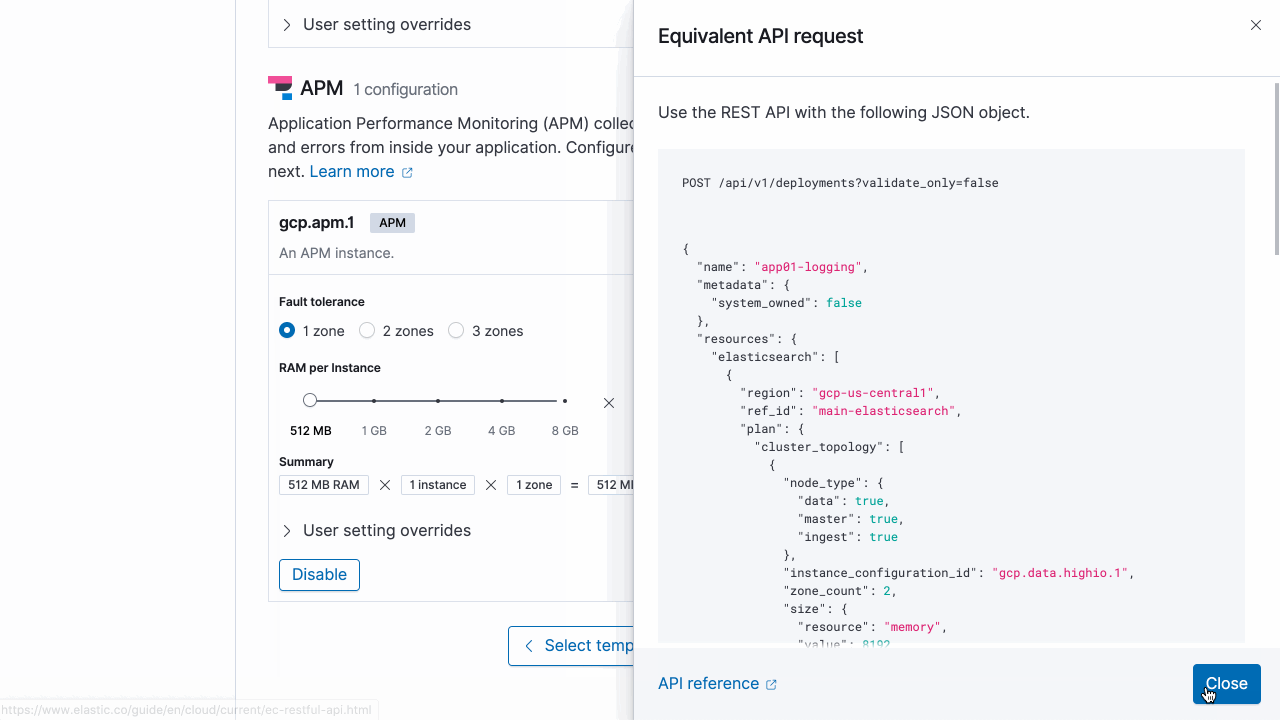
Exécution avec ecctl :
ecctl deployment create -f create-deployment.json
Pour monitorer la progression, utilisez l'indicateur --track, aussi bien dans cette commande que dans toutes les autres. En général, l'indicateur --help est très utile pour connaître les options disponibles.
Si vous utilisez cURL, la commande suivante donnera le même résultat :
curl -XPOST https://api.elastic-cloud.com/api/v1/deployments \ -H "Authorization: ApiKey <API_KEY>" \ -d @create-deployment.json
La réponse indiquera que la requête a été correctement soumise et renverra l'ID du déploiement. Copiez-le, car celui-ci vous sera nécessaire pour scaler votre cluster à la prochaine étape. La réponse inclura également le mot de passe généré aléatoirement pour l'utilisateur elastic, dont vous pourrez vous servir immédiatement pour vous connecter à Kibana ou pour utiliser l'API REST Elastic pour poursuivre la configuration de votre déploiement et commencer à l'utiliser.

4. Scaler votre déploiement
Maintenant que le déploiement est opérationnel, voyons comment faire pour le scaler. Dans cet exemple, nous allons augmenter la taille de nos nœuds de données de 4 096 Mo à 8 192 Mo. Attention : étant donné que vous allez apporter des changements uniquement à votre cluster Elasticsearch, vous devez définir le champ prune_orphans sur false pour indiquer que les autres composants faisant partie de votre déploiement (ici, Kibana et APM), ne doivent pas être supprimés.
Copiez le JSON ci-dessous et enregistrez-le en tant que fichier update-deployment.json :
{
"prune_orphans": false,
"resources": {
"elasticsearch": [
{
"region": "gcp-us-central1",
"ref_id": "main-elasticsearch",
"plan": {
"cluster_topology": [
{
"zone_count": 2,
"node_type": {
"master": true,
"data": true,
"ingest": true,
"ml": false
},
"instance_configuration_id": "gcp.data.highio.1",
"size": {
"resource": "memory",
"value": 4096
}
}
],
"elasticsearch": {
"version": "7.6.2"
},
"deployment_template": {
"id": "gcp-io-optimized"
}
}
}
]
}
}
Cette fois-ci, vous allez utiliser la commande "update" :
ecctl deployment update <ID_DÉPLOIEMENT> -f update-deployment.json
Si vous utilisez cURL, utilisez la méthode PUT pour soumettre le nouveau plan :
curl -XPUT https://api.elastic-cloud.com/api/v1/deployments/<ID_DÉPLOIEMENT> \ -H "Authorization: ApiKey <API_KEY>" \ -d @update-deployment.json
Dans certains cas, vous voudrez peut-être annuler un plan avant qu'il ne soit achevé. Vous pouvez utiliser ecctl pour annuler la commande du plan en indiquant "elasticsearch" en tant que type :
ecctl deployment plan cancel <ID_DÉPLOIEMENT> --kind elasticsearch
Ou, si vous utilisez cURL, envoyez une requête pour supprimer le plan en attente et l'ID de référence Elasticsearch, c.-à-d. "main-elasticsearch" :
curl -XDELETE https://api.elastic-cloud.com/api/v1/deployments/<ID_DÉPLOIEMENT>/elasticsearch/main-elasticsearch/plan/pending \ -H "Authorization: ApiKey <API_KEY>"
5. Nettoyage
Dans cette dernière étape, vous allez supprimer le déploiement créé à l'aide de la commande "shutdown" :
ecctl deployment shutdown <ID_DÉPLOIEMENT>
Lorsque vous soumettez une action de destruction, ecctl envoie un message de confirmation avant d'exécuter cette action. Vous pouvez employer l'indicateur global --force, qui peut être utile dans le cadre d'une automatisation.
Si vous utilisez cURL, vous pouvez soumettre la requête suivante :
curl -XPOST https://api.elastic-cloud.com/api/v1/deployments/<ID_DÉPLOIEMENT>/_shutdown \ -H "Authorization: ApiKey <API_KEY>"
Pour conclure
Nous avons étudié différents cas d'utilisation pour l'automatisation des déploiements. Le but : vous montrer comment créer, scaler et mettre fin à un déploiement. Notre API peut être utilisée de bien d'autres façons pour automatiser des procédures et réduire l'interaction humaine nécessaire pour gérer vos déploiements.
Pour consulter la liste complète des points de terminaison API disponibles, accédez aux exemples d'API dans la section API RESTful de notre guide d'utilisation.
Vous découvrez Elasticsearch Service ? Inscrivez-vous pour un essai gratuit de 14 jours.