Demystifying ChatGPT: Different methods for building AI search



Partager sur Twitter


Partager sur LinkedIn


Partager sur Facebook


Partage par e-mail


Imprimer
What is ChatGPT?
First things first, ChatGPT is awesome! It can help you work more efficiently — from summarizing a 10,000-word document to providing a list of differentiations between competing products, as well as many other tasks.
ChatGPT is the best known large language model (LLM) based on the transformer architecture. But there are other LLMs that you may have heard of, including BERT (Bidirectional Encoder Representation from Transformer), Bard (Language Model for Dialogue Applications), or LLaMA (LLM Meta AI). LLMs have multiple layers of neural networks that work together to analyze text and predict outputs. They’re trained with a left-to-right or bidirectional transformer that maximizes the probability of following and preceding words in context to figure out what might come next in a sentence. LLMs also have an attention mechanism that allows them to focus selectively on parts of text in order to identify the most relevant sections. For example, Rex is adorable and he is a cat. “He”, in this sentence, refers to “Cat” and “Rex.”
More is more
Large Language Models are generally compared by the number of parameters — and bigger is better. The number of parameters is a measure of the size and the complexity of the model. The more parameters a model has, the more data it can process, learn from, and generate. However, having more parameters also means having more computational and memory resource demands. Parameters are learned or updated during the training process by using an optimization algorithm that tries to minimize the error or the loss between the predicted outputs and the actual outputs. By adjusting the parameters, the model can improve its performance and accuracy on a given task or domain.
LLMs are expensive to train
Modern LLMs have billions of parameters that are trained on trillions of tokens and cost millions of dollars. Training an LLM includes identifying a data set, making sure the data set is large enough for it to perform functions like a human, determining the network layer configurations, using supervised learning to learn the information in the data set, and finally, fine-tuning. Needless to say, retraining LLMs on domain specific data is also very expensive.
How does a GPT model work?
A Generative pre-trained transformer (GPT) model is a type of neural network that uses the transformer architecture to learn from large amounts of text data. The model has two main components: an encoder and a decoder. The encoder processes the input text and converts it into a sequence of vectors called embeddings that represent the meaning and context of each word/subword in numerics. However, the decoder generates the output text by predicting the next word in the sequence based on the embeddings and the previous words.
The GPT model uses a technique called “attention” to focus on the most relevant parts of the input and output texts and to capture long-range dependencies and relationships between words. The model is trained by using a large corpus of texts as both the input and the output and by minimizing the difference between the predicted words and the actual words. It can then be fine-tuned or adapted to specific tasks or domains by using smaller and more specialized data sets.
Tokens
Tokens are the basic units of text or code that an LLM uses to process and generate language. Tokens can be characters, words, subwords, or other segments of text or code, depending on the chosen tokenization method or scheme. They are assigned numerical values or identifiers and are arranged in sequences or vectors, then are fed into or outputted from the model.
For example, the sentence “A quick brown fox jumps over a lazy dog” can be tokenized into the following tokens: “a,” “quick,” “brown,” “fox,” “jumps,” “over,” “a,” “lazy,” and “dog.”
Embedding
Embeddings are vectors or arrays of numbers that represent the meaning and the context of the tokens that the model processes and generates. They are derived from the parameters of the model and are used to encode and decode the input and output texts. Embeddings help the model to understand the semantic and syntactic relationships between the tokens and to generate more relevant and coherent texts. They are essential components of the transformer architecture that GPT-based models use. They can also vary in size and dimension, depending on the model and the task.
At a minimum, pre-trained LLMs contain embedding for tens of thousands of words, tokens, and terms. For example, ChatGPT-3 has a vocabulary of 14,735,746 words and a dimension of 1,536. The following is from a small model called distilbert-based-uncased. Despite the fact that this is a small model, it is still 100s mb in size.
Transformer
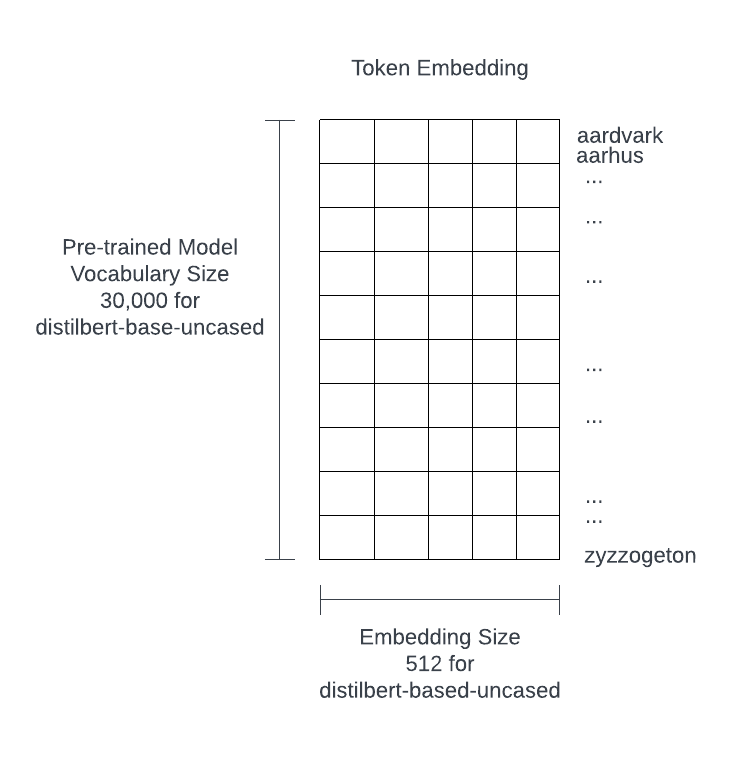
A transformer model is a neural network that learns context or meaning by tracking relationships in sequential data like the words in this sentence. In its simplest form, a transformer will take an input and predict an output. Within the transformer, there is an encoder stack and a decoder stack.
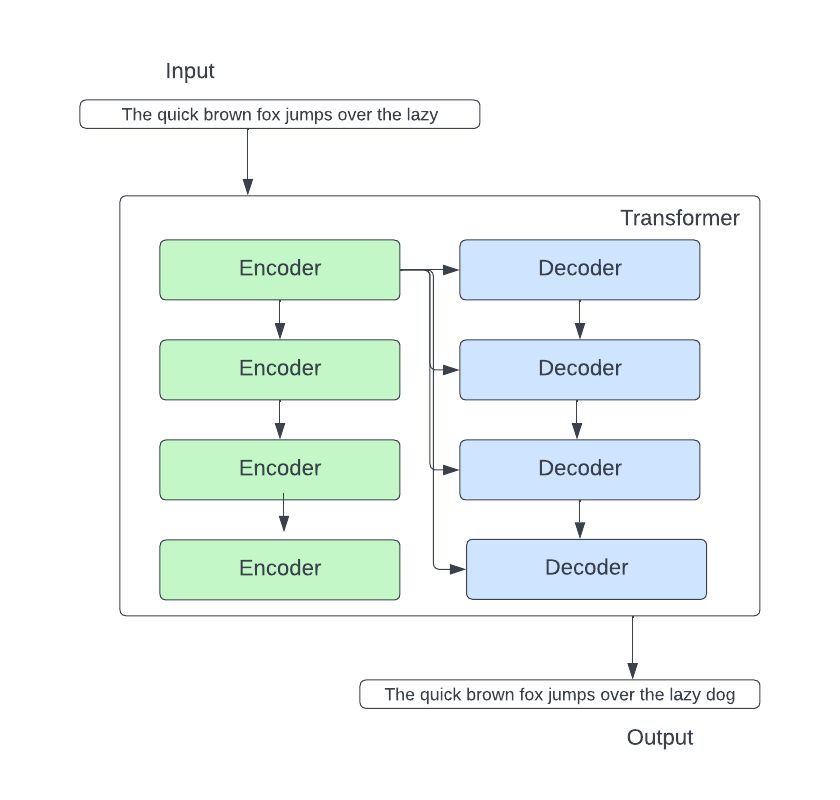
Let’s dig into the encoder block and the decoder block. In the encoder block, there are two important components: the self-attention neural network and the feed-forward neural network.
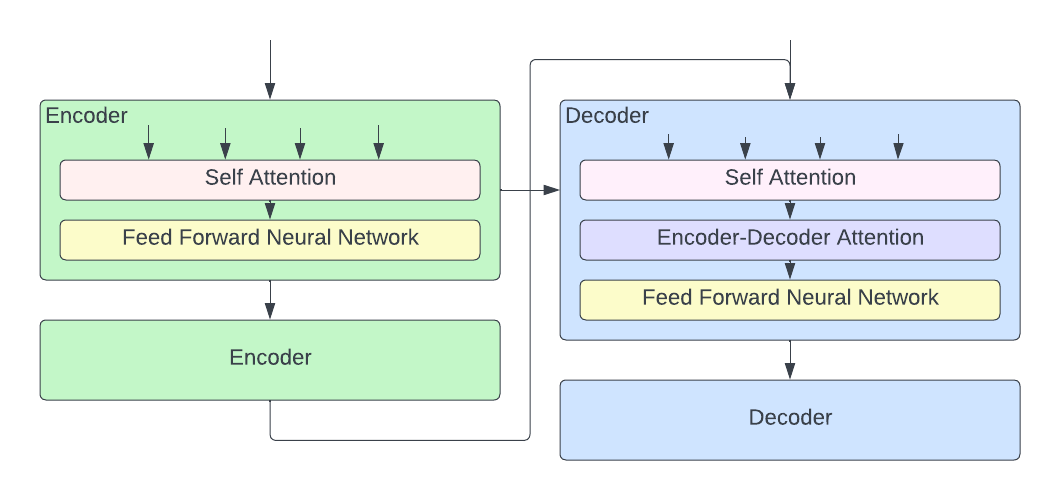
The self-attention layer is crucial as it builds in the “understanding” of the current token from the previous words that are relevant to the current one. For example, “it” refers to the chicken in “the chicken crossed the road because it wants to know what the jokes are all about.”
The other important layer in an encoder is the feed-forward neural network (FFNN). FFNN predicts what word comes after the current token.
Moving on to the decoder side, the encoder-decoder attention layer stands out. The encoder-decoder layer focuses on relevant parts of the input sentence, taking into account the layer below it and the output of the encoder stack.
Putting it all together:
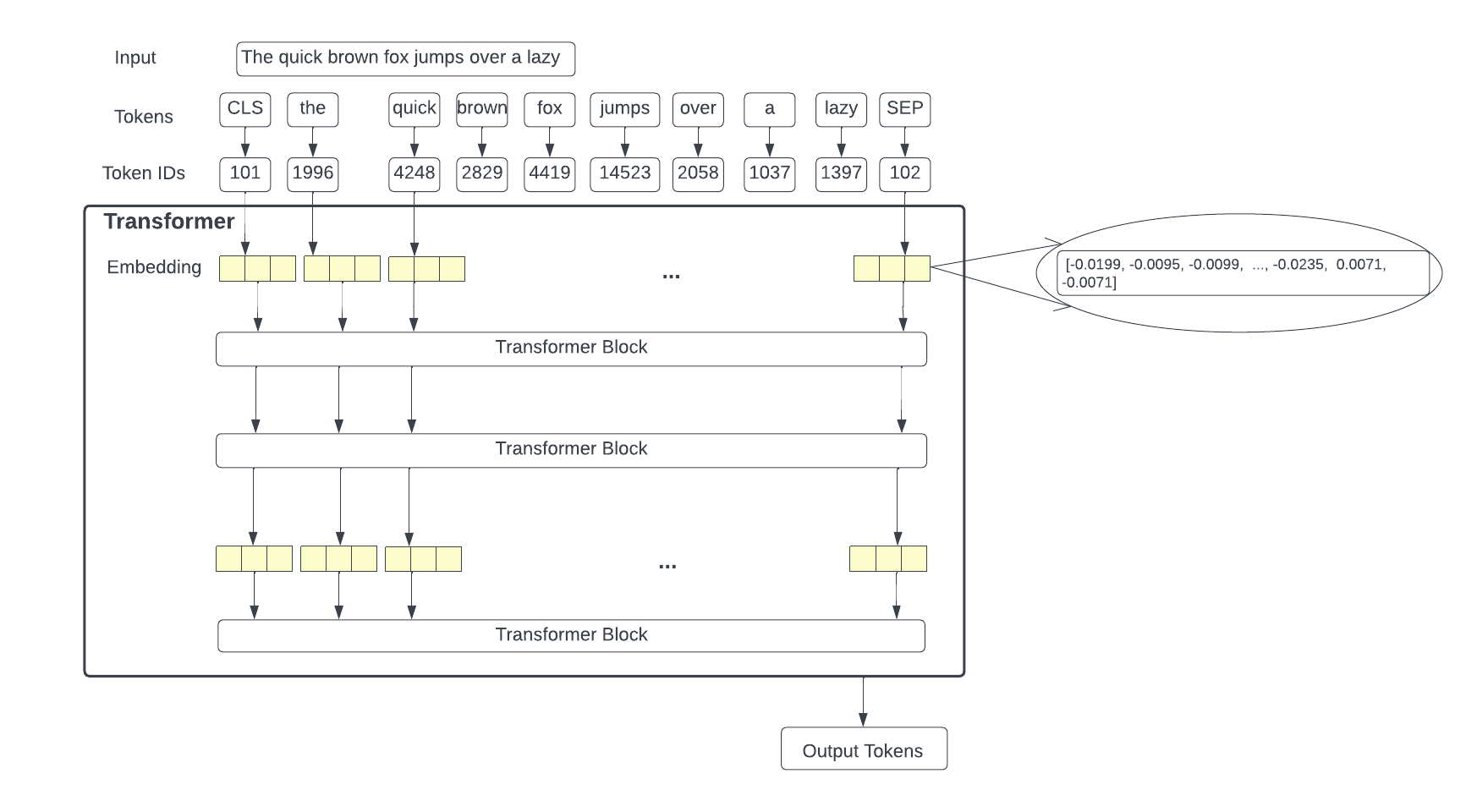
We will take an input, tokenize the input, and obtain token IDs of the tokens before converting them into embeddings for each token. From there, we will pass the embeddings into a transformer block. At the end of the process, the transformer will predict a series of output tokens. The following image provides a detailed look at the transformer model.
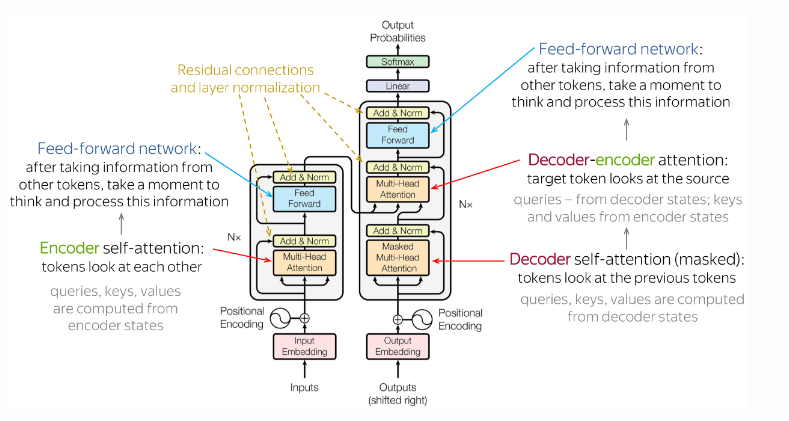
The decoder stack outputs a vector of floats. The linear layer projects the vector of floats produced by the stack of decoders into a larger vector called a logits vector. If the model has a 10,000-word vocabulary, then the linear layer maps the decoder output onto a 10,000 cell vector. The softmax layer turns those scores from the logit vector into probabilities — all positive — and adding up to 100%. The cell with the highest probability is chosen, and the word associated with it is produced as the output for this step.
The challenges with ChatGPT and LLMs
- They are trained on data that has no domain knowledge and could be out of date. For example, hallucinations are incorrect answers given as if they are correct and are common with LLMs.
- The models on their own do not have a natural ability to apply or extract filters from the input. Examples include time, date, and geographical filters.
- There is no access control on what document users can see.
- There are serious privacy and sensitive data control concerns.
- It is slow and very expensive to train on your own data and keep it up to date.
- Response from ChatGPT or other LLMs can be slow. Usually, Elasticsearch® would have millisecond query responses. With LLMs, it can take up to seconds to get a response. But this is expected as LLMs are performing complex tasks. Also, ChatGPT charges by the number of token processed. If you have a high velocity workload like Black Friday merchandise search for an ecommerce site, it can get very expensive very quickly. Not to mention, it probably won’t meet <10ms query SLA.
- It is difficult, if not impossible, to interpret how ChatGPT or other LLMs arrived at query results. Besides hallucinations, ChatGPT and otherLLMs may produce irrelevant responses that are difficult to determine how the model produced the erroneous answer.
Where does Elasticsearch fit?
Elasticsearch supports a bag of words and BM25 information retrieval approach, in addition to vector search through kNN and aNN natively (kNN is the exact nearest neighbor distance of all documents and aNN is the approximation). For aNN, Elasticsearch uses the HNSW (hierarchical navigable small world) algorithm for calculating approximate nearest neighbor distance. Elastic can mitigate many of the problems with LLMs while letting our users take advantage of all the good things ChatGPT and other LLMs can provide.
Elasticsearch can be used as a vector database, and to perform hybrid retrieval across text and vector data. There are three patterns where Elasticsearch can provide clear benefits when used with LLMs:
Provide context to your data and integrate with ChatGPT or other LLMs
Enable you to bring your own model (any 3rd party model)
Use the built-in Elastic Learned Sparse Encoder model
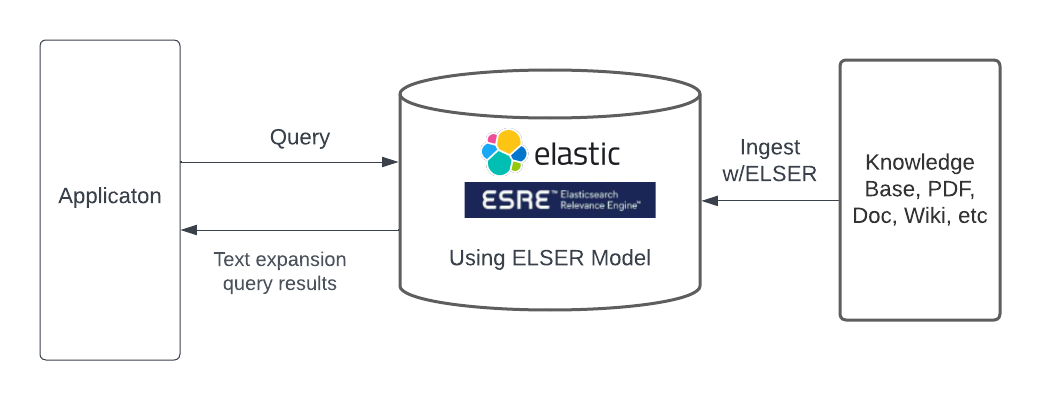
Method 1: Provide context to your data and integrate with ChatGPT or other LLMs
The following depicts how to separate LLMs from your data while integrating with generative AI.
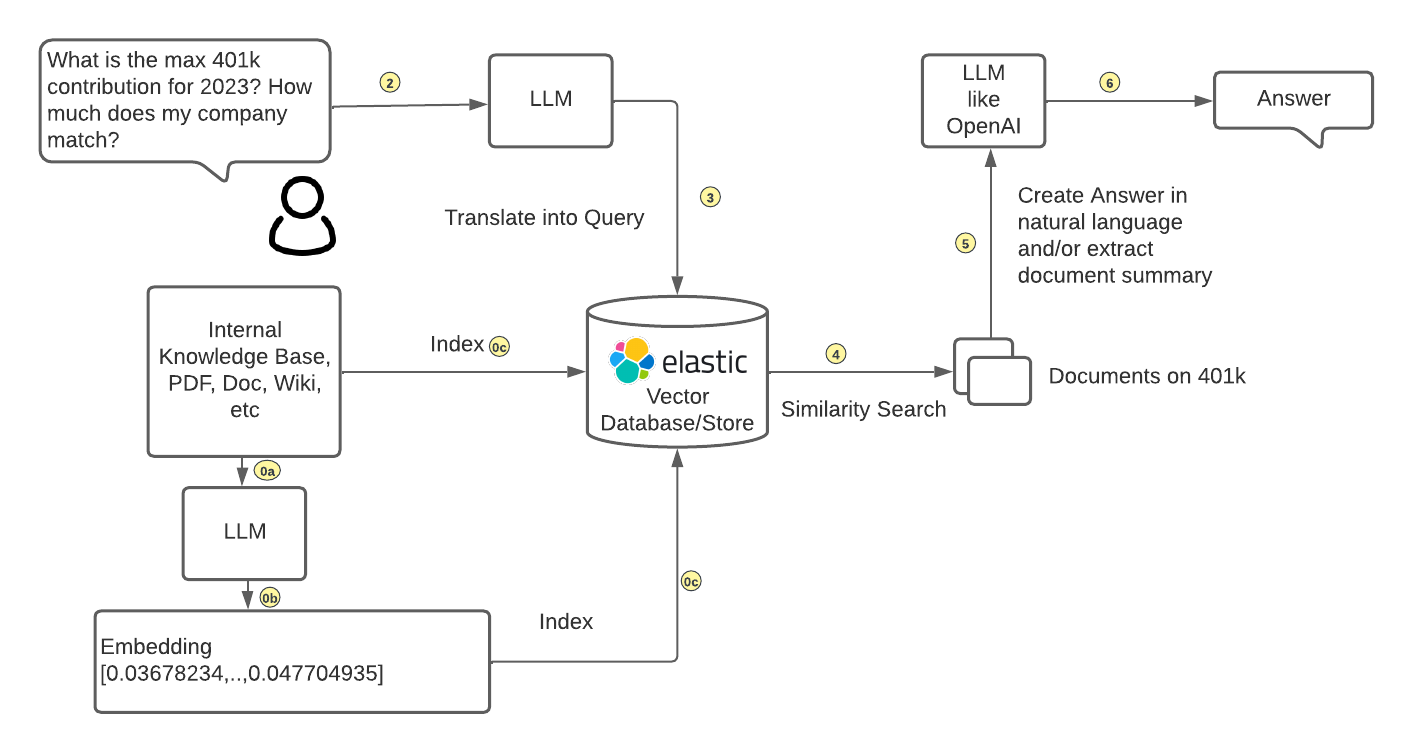
A customer can bring their own embedding generated by a LLM and ingest their data along with the embedding into Elasticsearch. Then, the customer can take the similarity search results from their own data stored in Elasticsearch (context to the user’s question) to ChatGPT or another LLM to construct natural-language based answers to their users.
Also, the newly released reciprocal rank fusion (RRF) allows users to perform hybrid search, which can combine and rank search results. For instance, the BM25 method can filter for the relevant documents along with vector search to provide the best documents. With RRF, customers can achieve best search results natively through Elasticsearch instead of through their own applications, which greatly reduces complexity and maintenance of their applications.
Method 2: Bring your own model
The recently announced Elasticsearch Relevance EngineTM (ESRETM) provides the capability to bring your own LLMs. This capability has been available for a while through machine learning. The Elasticsearch machine learning team has been scaffolding infrastructure for integrating transformer-based models. Starting with the 8.8 release, you can ingest and query just like you would normally do in Elasticsearch through the search APIs. On top of that, you can use the hybrid search method with RRF, which provides even better relevance. As the models are managed and integrated into Elasticsearch, it reduces operation complexity while achieving the most relevant search results.
This approach would require the users to know what model would work well for their use case and a commercial relationship with Elastic.
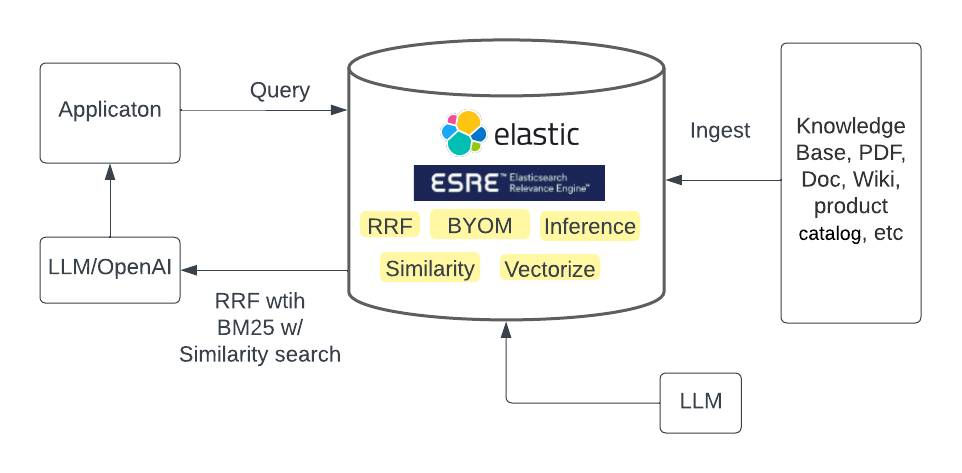
Method 3: Use the built-in sparse encoder model
Elastic Learned Sparse Encoder is the Elastic out-of-the-box language model that outperforms SPLADE (SParse Lexical AnD Expansion Model), which itself is a state-of-the-art model. Elastic Learned Sparse Encoder solves the vocabulary mismatch problem where a document may be relevant to a query but does not contain any terms that appear in the query. An example of the mismatch may be if we ask “how have American corporations have assisted with Covid-19 efforts”, then manufacturers of ventilators may not appear in the query results.
Elastic Learned Sparse Encoder is accessible just like other search endpoints via the text_expansion query. Elastic Learned Sparse Encoder enables our user to begin the state-of-the-art generative AI search with a click and yield immediate results. Elastic Learned Sparse Encoder is also an Elastic commercial feature.
Here are some benchmark results using the BEIR benchmark. We used several standardized data sets (horizontal axis) and applied different retrieval metaphors (vertical axis). As you can see, a combination of BM25 and our Learned Sparse Encoder using RRF, returns the best relevance scores. These scores with RRF beat the SPLADE model and our Learned Sparse Encoder model when considered by itself. We published more details on our blog here.
.png)
Terms and definitions
Neural Network (NN)
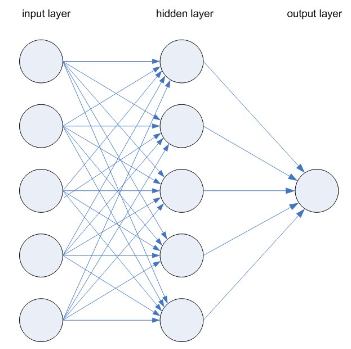
Each node is a neuron. Think of each individual node as its own linear regression model, composed of input data, weights, a bias (or threshold), and an output. The math representation may look like:
∑wixi + bias = w1x1 + w2x2 + w3x3 + bias
output = f(x) = 1 if ∑w1x1 + b>= 0; 0 if ∑w1x1 + b < 0
Once an input layer is determined, weights (w) are assigned. These weights help determine the importance of any given variable with larger ones contributing more significantly to the output compared to other inputs. All inputs are then multiplied by their respective weights and then summed. Afterward, the output is passed through an activation function, which determines the output. If that output exceeds a given threshold, it activates the node and passes data to the next layer in the network. This results in the output of one node becoming the input of the next node. This process of passing data from one layer to the next layer is a feed-forward network. This is just one type of NNs.
LLM parameters
Weights are numerical values that define the strength of connections between neurons across different layers in the model. Biases are additional numerical values that are added to the weighted sum of inputs before being passed through an activation function.
SPLADE
SPLADE is a late interaction model. The idea behind SPLADE models is that using a pre-trained language model like BERT can identify connections between words and use the knowledge to enhance sparse vector embedding. You would use this when you have a document that covers a wide range of topics, such as a Wikipedia article about a WWII movie — it contains the plot, the actors, the history, and the studio that released the film.
With embedding retrieval techniques alone, the relevance of the document to queries becomes an issue because the document can be projected onto a large number of dimensions and render it close to none of the queries. SPLADE solves the problem by combining all token-level probability distributions into a single distribution that tells us the relevance of every token in the vocabulary to our input sentence, similar to the BM25 method. Elastic Learned Sparse Encoder is the Elastic version of the SPLADE model.
RRF
RRF is a hybrid search query that normalizes and combines multiple search result sets with different relevant indicators into a single result set. Based on our own testing, combining RRF (BM25 + Elastic Learned Sparse Encoder) produces the best search relevance.
Wrap up
By combining the creative capabilities of technologies, such as ChatGPT, and the business context of proprietary data, we can truly transform how customers, employees, and organizations search.
Retrieval augmented generation (RAG) bridges the gap between large language models that power generative AI and private data sources. Well-known limitations of large language models can be addressed with context-based retrieval, enabling you to build deeply engaging search.
Unlock the power of ChatGPT and other generative search technologies with Elasticsearch:
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Partager
Partager sur Twitter
Partager sur LinkedIn
Partager sur Facebook
Partage par e-mail
Imprimer

