5 composants techniques de la recherche de similarités dans les images


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Dans la première partie de cette série d'articles, nous avons présenté la recherche de similarités dans les images et l'architecture de haut niveau capable de réduire la complexité et de simplifier l'implémentation. Cet article explique les concepts sous-jacents et les considérations techniques pour chaque composant nécessaire à l'implémentation d'une application de recherche de similarités dans les images. Ainsi, vous en apprendrez plus sur :
- les modèles de plongement, c'est-à-dire les modèles de Machine Learning qui génèrent la représentation numérique de vos données requise pour appliquer la recherche vectorielle ;
- le point de terminaison d'inférence, c'est-à-dire l'API qui applique les modèles de plongement à vos données dans Elastic ;
- la recherche vectorielle, c'est-à-dire la manière dont la recherche de similarités fonctionne avec la recherche du plus proche voisin ;
- la génération de plongements pour les images, c'est-à-dire le scaling de la génération de représentations numériques dans de grands ensembles de données ;
- la logique des applications, c'est-à-dire la manière dont la partie front-end interactive communique avec le moteur de recherche vectorielle au niveau du back-end.
Grâce à une meilleure connaissance de ces cinq composants, vous disposez d'une stratégie d'implémentation d'expériences de recherche plus intuitives en appliquant la recherche vectorielle dans Elastic.
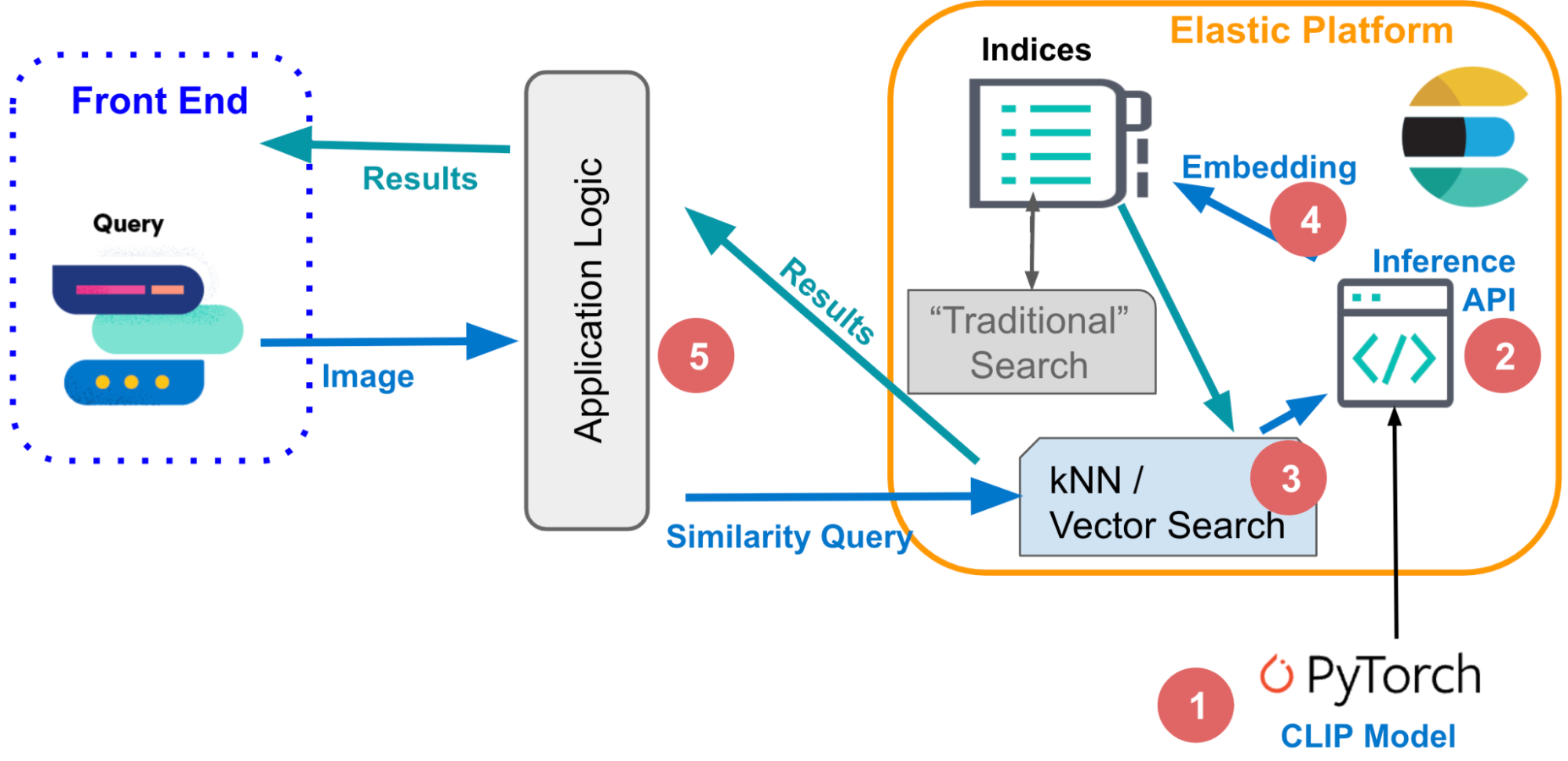
1. Modèles de plongement
Pour appliquer la recherche de similarités aux données au format image ou au langage naturel, vous devez disposer de modèles de Machine Learning capables de convertir vos informations en représentations numériques, également appelées plongements vectoriels. Dans l'exemple utilisé pour cet article :
- Le modèle de "transformation" du traitement du langage naturel (NLP) convertit le langage naturel en un vecteur.
- Le modèle CLIP ("Contrastive Language-Image Pre-training") d'OpenAI vectorise les images.
Les modèles de transformation sont des modèles de Machine Learning entraînés afin de traiter des données de langage naturel de différentes manières, notamment la traduction, la classification de textes ou la reconnaissance d'entités nommées (NER). Ils sont entraînés sur de très grands ensembles de données textuelles annotées afin d'apprendre les schémas et les structures du langage humain.
L'application de recherche de similarités trouve des images correspondant à des descriptions textuelles en langage naturel spécifiques. Pour implémenter ce type de recherche de similarités, vous devez disposer d'un modèle entraîné sur du texte et des images qui est capable de convertir une requête textuelle en vecteur. Il peut ensuite être utilisé pour trouver des images similaires.
Découvrez comment charger et utiliser le modèle NLP dans Elasticsearch. >>
CLIP est un modèle de langage à grande échelle développé par OpenAI qui est capable de traiter du texte et des images. Il est entraîné pour prédire la représentation textuelle d'une image à partir d'un court extrait de texte fourni en tant qu'entrée. Dans cette optique, il apprend à aligner les représentations visuelles et textuelles d'une image afin de pouvoir formuler des prédictions précises.
Autre aspect important, CLIP est un modèle "zero-shot" : il est en mesure de réaliser des tâches pour lesquelles il n'a pas été particulièrement entraîné. Par exemple, il peut traduire du texte dans des langues sur lesquelles il n'a pas été entraîné ou classer des images en catégories complètement inconnues. Ainsi, CLIP est un modèle très flexible et polyvalent.
Vous utiliserez le modèle CLIP pour vectoriser vos images, à l'aide du point de terminaison d'inférence dans Elastic présenté ci-dessous, puis exécuterez l'inférence sur un grand ensemble de données, comme expliqué à la section 3 ci-dessous.
2. Point de terminaison d'inférence
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
{
"docs" : [
{"text_field": "A mountain covered in snow"}
]
}3. Recherche (de similarités) vectorielle
Après avoir indexé les requêtes et les documents à l'aide des plongements vectoriels, les documents similaires sont les plus proches voisins de votre requête dans l'espace de plongement. Pour obtenir ce résultat, un algorithme populaire est la recherche des k plus proches voisins qui trouve les k vecteurs les plus proches d'un vecteur de requête. Cependant, au sein des grands ensembles de données que vous traitez habituellement dans les applications de recherche d'image, la recherche des k plus proches voisins requiert de très importantes ressources de calcul et peut engendrer des temps d'exécution excessifs. Une solution consiste à avoir recours à la recherche du plus proche voisin approximatif qui renonce à la précision parfaite en échange d'une exécution efficace et à grande échelle dans des espaces de plongement hautement dimensionnels.
Dans Elastic, le point de terminaison _search prend en charge les recherches du plus proche voisin approximatif et exact. Utilisez le code ci-dessous pour la recherche des k plus proches voisins. Il est supposé que les plongements pour l'ensemble des images dans l'index your-image-index sont disponibles dans le champ image_embedding. Dans la section suivante, découvrez comment vous pouvez créer des plongements.
# Run kNN search against <query-embedding> obtained above
POST <your-image-index>/_search
{
"fields": [...],
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": <query-embedding>
}
}Pour en savoir plus sur la recherche des k plus proches voisins dans Elastic, consultez notre documentation dédiée à l'adresse https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html.
4. Génération de plongements pour les images
Les plongements pour les images susmentionnés sont essentiels pour garantir la bonne performance de votre recherche de similarités dans les images. Ils doivent être stockés dans un index distinct dédié, qui est appelé your-image-index dans le code illustré ci-dessus. Cet index comprend un document par image associé à des champs contextuels et l'interprétation (plongement pour les images) des vecteurs denses des images. Les plongements représentent une image dans un espace de moindre dimension. Des images similaires sont mappées aux points qui se trouvent à proximité dans cet espace. La largeur de l'image brute peut être de plusieurs mégaoctets, en fonction de sa résolution.
Les spécificités de la génération de ces plongements peuvent varier. En règle générale, ce processus consiste à extraire les fonctionnalités des images, puis à les mapper dans un espace de moindre dimension à l'aide d'une fonction mathématique. Cette dernière est souvent entraînée sur un grand ensemble de données d'images pour apprendre la meilleure méthode de représentation des fonctionnalités dans l'espace de moindre dimension. La génération des plongements est une tâche unique.
Dans cet article, nous utilisons le modèle CLIP pour la réaliser. Il est distribué par OpenAI et constitue un bon point de départ. Pour obtenir les performances recherchées, vous devrez peut-être entraîner un modèle de plongement personnalisé qui est adapté aux cas d'utilisation spécialisés, selon la qualité de la représentation des types d'images que vous voulez classer dans les données publiques utilisées pour entraîner le modèle CLIP.
La génération de plongements dans Elastic doit avoir lieu au moment de l'ingestion et, par conséquent, dans le cadre d'un processus externe à la recherche composé des étapes suivantes :
- Chargez le modèle CLIP.
- Pour chaque image :
- Chargez l'image.
- Évaluez l'image à l'aide du modèle.
- Enregistrez les plongements générés dans un document.
- Enregistrez le document dans le datastore/Elasticsearch.
Grâce au pseudocode, ces étapes sont plus concrètes. Le code complet est accessible dans le référentiel fourni à titre d'exemple.
...
img_model = SentenceTransformer('clip-ViT-B-32')
...
for filename in glob.glob(PATH_TO_IMAGES, recursive=True):
doc = {}
image = Image.open(filename)
embedding = img_model.encode(image)
doc['image_name'] = os.path.basename(filename)
doc['image_embedding'] = embedding.tolist()
lst.append(doc)
...Vous pouvez également vous reporter au schéma ci-dessous qui vous fournit une illustration.
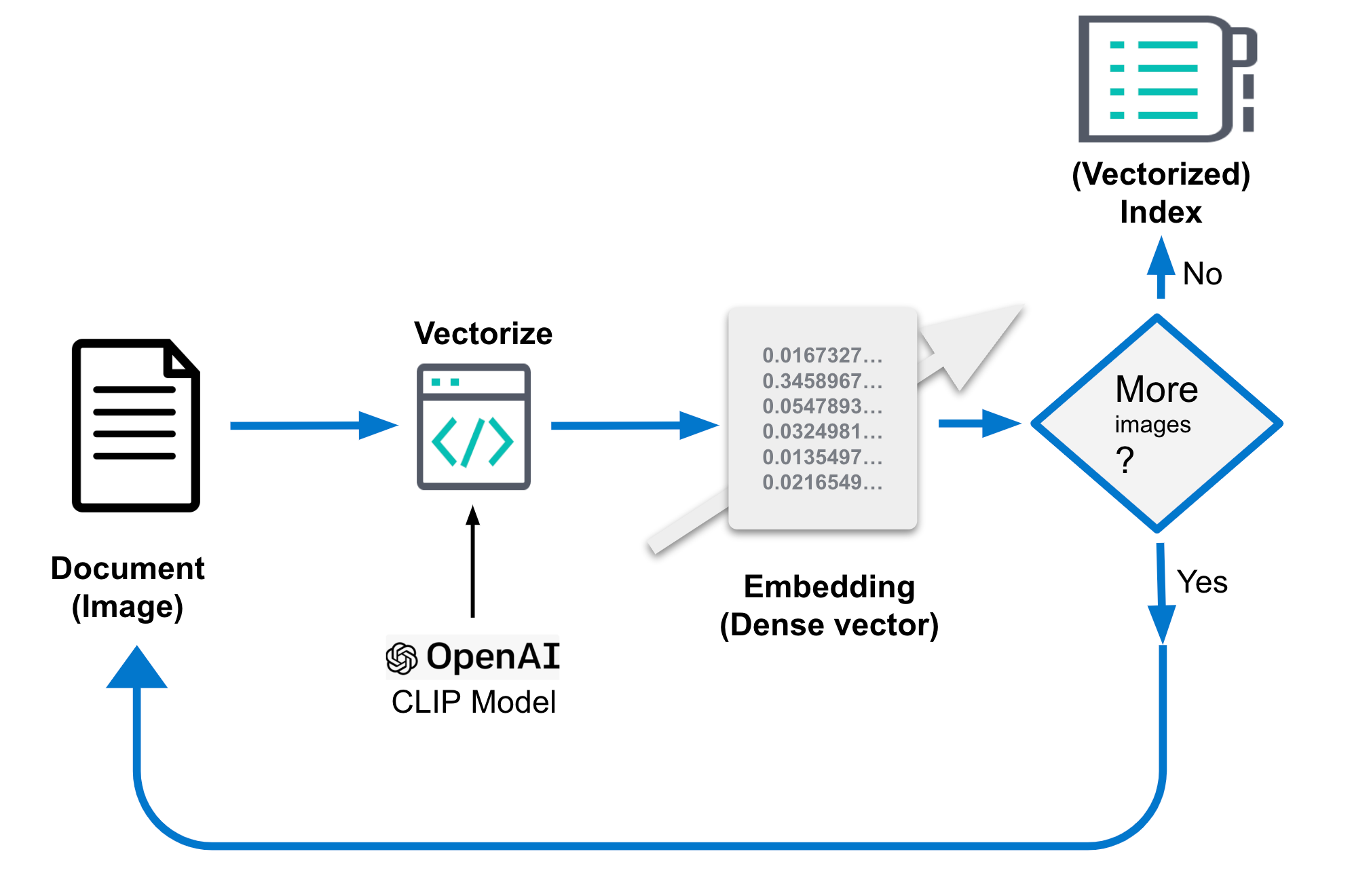
Une fois traité, le document devrait ressembler à ce qui suit. L'étape fondamentale est le champ image_embedding où est stockée la représentation des vecteurs denses.
{
"_index": "my-image-embeddings",
"_id": "_g9ACIUBMEjlQge4tztV",
"_score": 6.703597,
"_source": {
"image_id": "IMG_4032",
"image_name": "IMG_4032.jpeg",
"image_embedding": [
-0.3415695130825043,
0.1906963288784027,
.....
-0.10289803147315979,
-0.15871885418891907
],
"relative_path": "phone/IMG_4032.jpeg"
}
}5. La logique des applications
Grâce à ces composants basiques, vous pouvez enfin associer tous les éléments requis et suivre la logique afin d'implémenter une recherche interactive de similarités dans les images. Commençons sur le plan conceptuel par les étapes à suivre pour récupérer de manière interactive les images correspondant à une description donnée.
Pour les requêtes textuelles, l'entrée peut être aussi simple qu'un seul mot (roses, par exemple) ou une description plus longue, comme "une montagne couverte de neige". Vous pouvez également fournir une image et formuler une requête pour obtenir des images similaires.
Même si vous utilisez des modalités différentes pour formuler votre requête, elles sont toutes exécutées à l'aide de la même séquence d'étapes lors de la recherche vectorielle sous-jacente, à savoir une requête (recherche des k plus proches voisins) concernant les documents représentés par leurs plongements (en tant que vecteurs "denses"). Dans les sections ci-dessus, nous avons décrit les mécanismes permettant à Elasticsearch d'exécuter une recherche vectorielle très rapide et scalable qui est nécessaire dans les grands ensembles de données au format image. Consultez cette documentation pour savoir comment adapter la recherche des k plus proches voisins dans Elastic afin de gagner en efficacité.
- Comment pouvez-vous implémenter la logique décrite ci-dessus ? L'organigramme ci-dessous illustre les flux d'informations. La requête utilisateur sous forme de texte ou d'image est vectorisée par le modèle de plongement, selon le type d'entrée, soit un modèle NLP pour les descriptions textuelles, soit un modèle CLIP pour les images.
- Ces deux modèles convertissent la requête d'entrée en représentation numérique et en stockent le résultat dans un type de vecteur dense dans Elasticsearch ([numéro, numéro, numéro...]).
- La représentation vectorielle est ensuite utilisée dans le cadre d'une recherche des k plus proches voisins afin de trouver des vecteurs similaires (images) qui sont récupérés en tant que résultats.
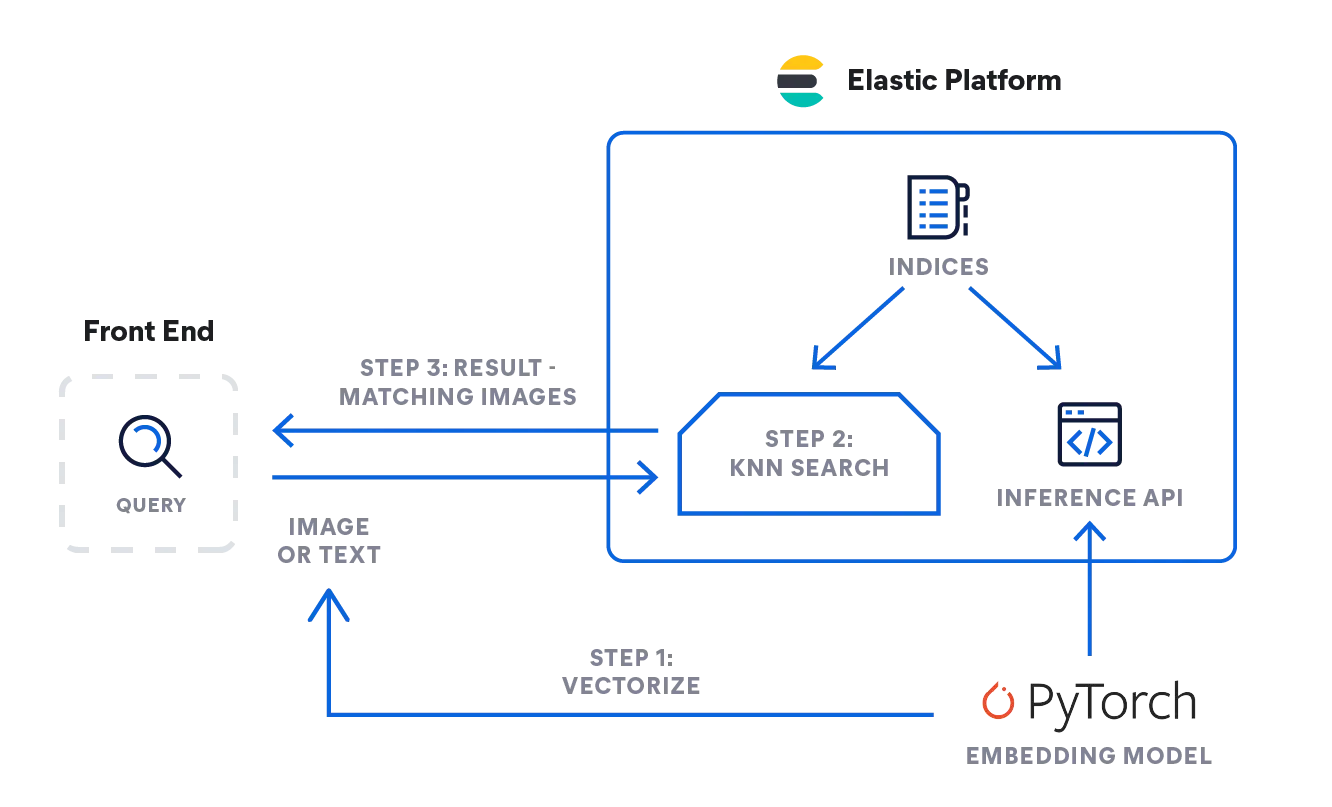
Inférence : vectorisation des requêtes des utilisateurs
L'application en arrière-plan enverra une requête à l'API d'inférence dans Elasticsearch. Pour les entrées textuelles, elle ressemble à ce qui suit :
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
{
"docs" : [
{"text_field": "A mountain covered in snow"}
]
}Pour les images, vous pouvez utiliser le code simplifié ci-dessous afin de traiter une seule image à l'aide du modèle CLIP, que vous avez dû charger dans votre nœud de Machine Learning Elastic au préalable :
model = SentenceTransformer('clip-ViT-B-32')
image = Image.open(file_path)
embedding = model.encode(image)Vous obtenez un éventail de valeurs Float32 de 512, similaires à ce qui suit.
{
"predicted_value" : [
-0.26385045051574707,
0.14752596616744995,
0.4033305048942566,
0.22902603447437286,
-0.15598160028457642,
...
]
}La recherche : pour des images similaires
La recherche fonctionne de la même manière pour les deux types d'entrées. Envoyez la requête avec une définition de recherche des k plus proches voisins (kNN) par rapport à l'index contenant des plongements pour les images intitulé my-image-embeddings. Intégrez le vecteur dense de la requête précédente ("query_vector" : [ ... ]) et exécutez la recherche.
GET my-image-embeddings/_search
{
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": [
-0.19898493587970734,
0.1074572503566742,
-0.05087625980377197,
...
0.08200495690107346,
-0.07852292060852051
]
},
"fields": [
"image_id", "image_name", "relative_path"
],
"_source": false
}La réponse d'Elasticsearch vous donnera les meilleures images correspondantes selon notre requête de recherche des k plus proches voisins, qui sont stockées dans Elastic en tant que documents.
Le diagramme de flux ci-dessous récapitule les étapes par lesquelles passe votre application interactive lors du traitement d'une requête utilisateur :
- Chargez l'application interactive, sa partie front-end.
- L'utilisateur sélectionne une image de son choix.
- Votre application vectorise l'image en appliquant le modèle CLIP qui stocke le plongement obtenu en tant que vecteur dense.
- L'application lance une recherche des k plus proches voisins dans Elasticsearch, qui se concentre sur le plongement et en récupère les plus proches voisins.
- Votre application traite le résultat obtenu et fournit une (ou plusieurs) images correspondantes.
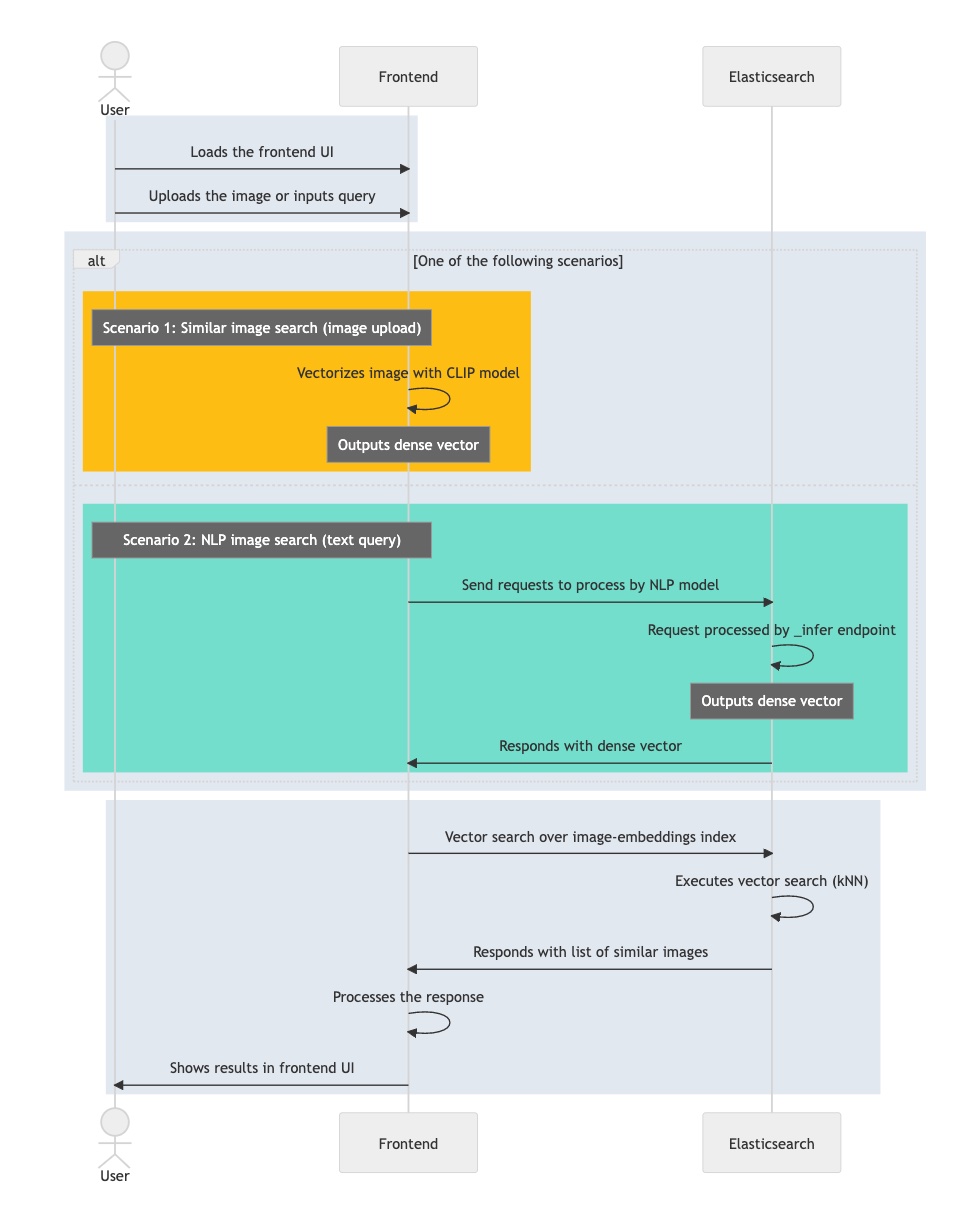
Maintenant que vous connaissez les principaux composants et flux d'informations requis pour implémenter une recherche interactive de similarités dans les images, vous pouvez passer à la partie finale de cette section qui vous apprendra comment faire concrètement. Vous obtiendrez un mode d'emploi détaillé vous expliquant comment configurer l'environnement de l'application, importer le modèle NLP et terminer la génération de plongements pour les images. Ensuite, vous serez en mesure de mener des recherches dans les images à l'aide du langage naturel. Aucun mot-clé n'est nécessaire.
Commencez à configurer la recherche de similarités dans les images. >>
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer