Présentation de la recherche de similarités dans les images dans Elasticsearch


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Imaginez pouvoir imiter le look d'une célébrité avec l'aide d'une capture d'écran. Vous pourriez utiliser cette image pour trouver rapidement des vêtements du même style vendus en ligne. Mais une telle expérience de recherche n'existe pas aujourd'hui.
Les clients ont du mal à trouver ce dont ils ont besoin, ce qui les pousse à quitter la page qu'ils sont en train de consulter. Certains d'entre eux ne se souviennent pas du nom (mot clé) de l'objet de leur recherche, mais ont toutefois une idée de l'apparence ou de l'image réelle. Avec la recherche vectorielle, fonctionnalité intégrée disponible dans Elastic, les organisations peuvent implémenter la recherche de similarités dans les images. Elles peuvent ainsi créer une expérience de recherche plus intuitive afin que les clients puissent facilement trouver ce qu'ils recherchent en utilisant une simple image.
Pour implémenter cette fonctionnalité dans Elastic, vous n'avez pas besoin d'être un expert en Machine Learning pour vous lancer, car la recherche vectorielle est déjà intégrée à notre plateforme évolutive et hautement performante. Vous avez accès à des intégrations dans les frameworks d'application, ce qui facilite la création d'applications interactives.
Cette série d'articles de blog en plusieurs parties vous permettra de découvrir comment créer un prototype d'application de recherche de similarités dans Elastic en utilisant votre propre jeu d'images. La partie front-end de ce prototype d'application est implémentée à l'aide de Flask. Elle peut servir de point de départ pour votre propre application personnalisée.
- Première partie : 5 composants techniques de la recherche de similarités dans les images
- Deuxième partie : Implémentation de la recherche de similarités dans les images dans Elastic
Dans cet article de présentation, vous découvrirez l'architecture requise pour appliquer la recherche vectorielle aux données au format image avec Elastic. Si vous vous intéressez plus à la recherche sémantique sur du texte plutôt que sur des images, consultez la série d'articles de blog sur le traitement du langage naturel (NLP) qui aborde les incorporations de texte, la recherche vectorielle, la reconnaissance d'entités nommées (NER) et l'analyse des sentiments, et qui montre comment appliquer ces techniques dans Elastic. Avant tout, expliquons la façon dont la recherche de similarités et la recherche sémantique s'appuient sur la recherche vectorielle.
La recherche sémantique et la recherche de similarités reposent toutes deux sur la recherche vectorielle
La recherche vectorielle tire parti du Machine Learning (ML) pour capturer la signification et le contexte de données non structurées. La recherche vectorielle trouve des données similaires à l'aide d'algorithmes de recherche du plus proche voisin approximatif (ANN, Approximative Nearing Neighbor). En comparaison avec la recherche de texte traditionnelle (dans Elastic, sur la base de la notation BM25), la recherche vectorielle génère des résultats plus pertinents et s'exécute plus rapidement (sans avoir besoin d'optimisations extrêmes pour les moteurs de recherche).
Cette approche fonctionne avec les données textuelles, ainsi qu'avec les images et d'autres types de données non structurées pour lesquelles des modèles de plongement génériques sont disponibles. Pour les données textuelles, on parle couramment de recherche sémantique, alors que le terme recherche de similarités est fréquemment utilisé dans le contexte des images et de l'audio.
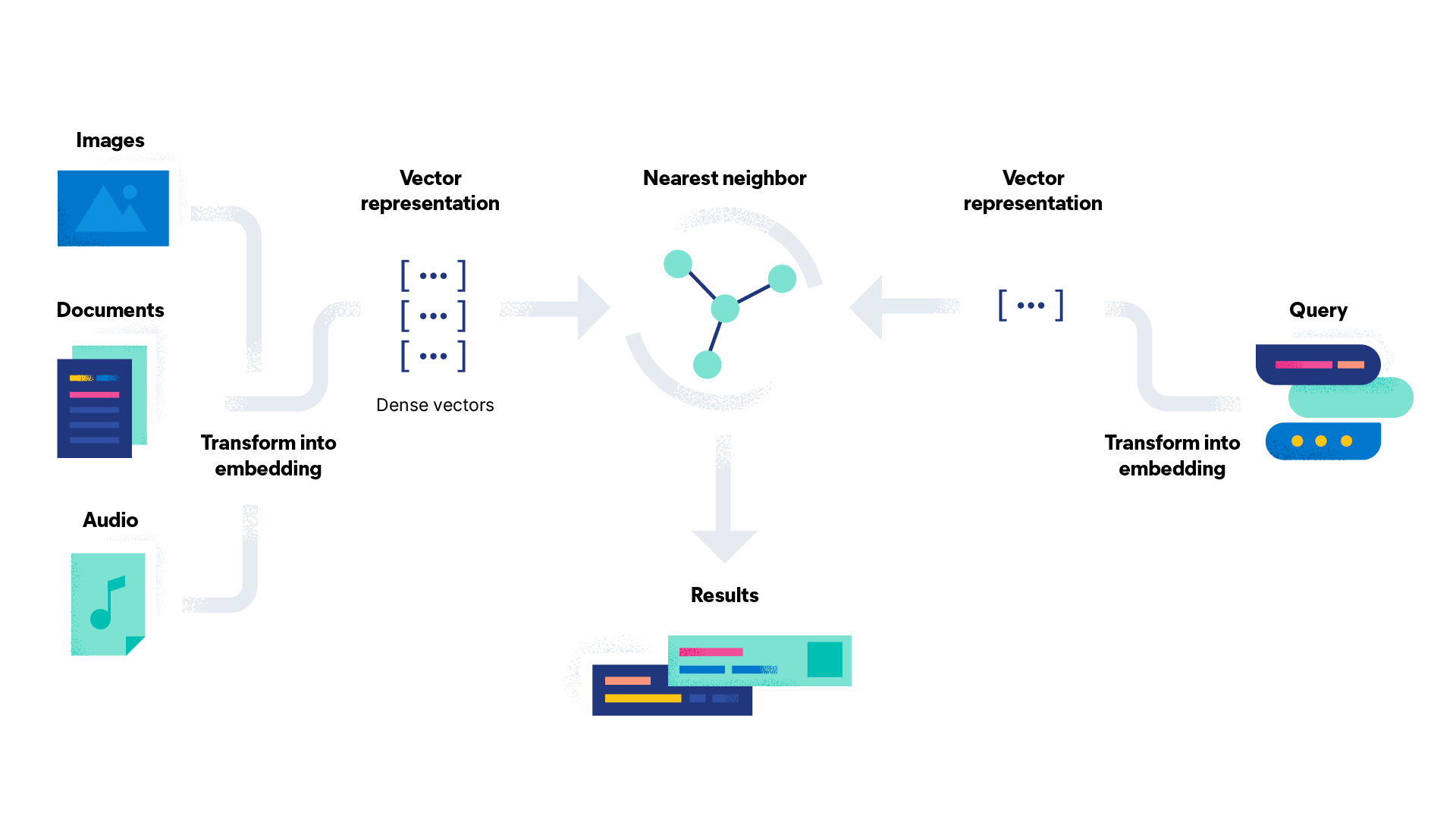
Comment générer des plongements vectoriels pour les images ?
Les plongements vectoriels sont la représentation numérique des données et du contexte associé, stockés dans des vecteurs de grande dimension (denses). Les modèles qui génèrent des plongements sont généralement entraînés sur des millions d'exemples pour fournir des résultats plus pertinents et plus précis.
Pour les données textuelles, les transformateurs de type BERT sont populaires pour générer des plongements qui fonctionnent avec de nombreux types de texte ; ils sont disponibles sur des référentiels publics tels que Hugging Face. Les modèles de plongement, qui fonctionnent bien sur tout type d'image, font en permanence l'objet de recherches. Le modèle CLIP (utilisé par nos équipes pour générer le prototype d'application de similarité d'images) est distribué par OpenAI et fournit un bon point de départ. Pour les cas d'utilisation spécialisés, et si vous êtes un utilisateur avancé, vous devrez peut-être entraîner un modèle de plongement personnalisé pour obtenir les performances souhaitées. Ensuite, vous devez être capable d'effectuer efficacement des recherches. Elastic prend en charge la recherche du plus proche voisin approximatif, largement adoptée, qui est basée sur HNSW.
La place de la recherche de similarités dans les applications innovantes
Quelle est la place de la recherche de similarités dans l'innovation ? Dans notre premier exemple, les utilisateurs peuvent prendre une capture d'écran et effectuer une recherche pour trouver la tenue de leur célébrité préférée.
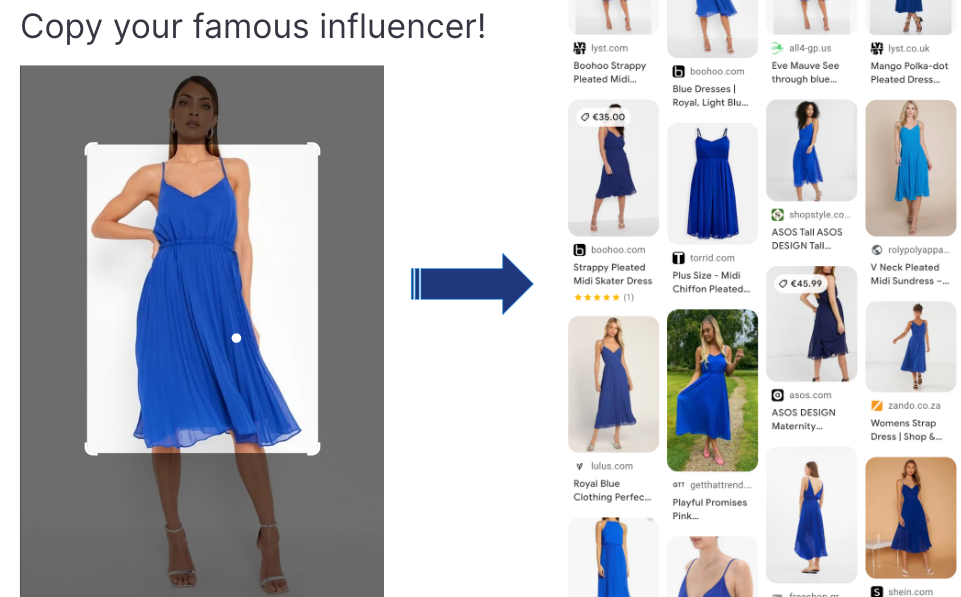
Vous pouvez également utiliser la recherche de similarités aux fins suivantes :
- Suggérer des produits similaires à ceux achetés par d'autres acheteurs.
- Trouver des designs associés ou des modèles pertinents à partir d'une bibliothèque d'éléments de design visuels.
- Trouver des morceaux que vous pourriez aimer via les services populaires de streaming de musique en vous basant sur vos écoutes récentes.
- Effectuer une recherche parmi d'énormes jeux de données d'images non structurées et non étiquetées en utilisant la description naturelle.
Découvrez ce qui alimente la recherche de similarités dans les images >>
Présentation de l'architecture de l'application de recherche de similarités dans les images
Créer ce genre d'application interactive peut vous paraître compliqué. C'est particulièrement vrai si vous envisagez une implémentation dans une architecture traditionnelle, comme présenté ci-dessous. Toutefois, dans le deuxième schéma, vous pouvez voir en quoi Elastic simplifie considérablement cette architecture…
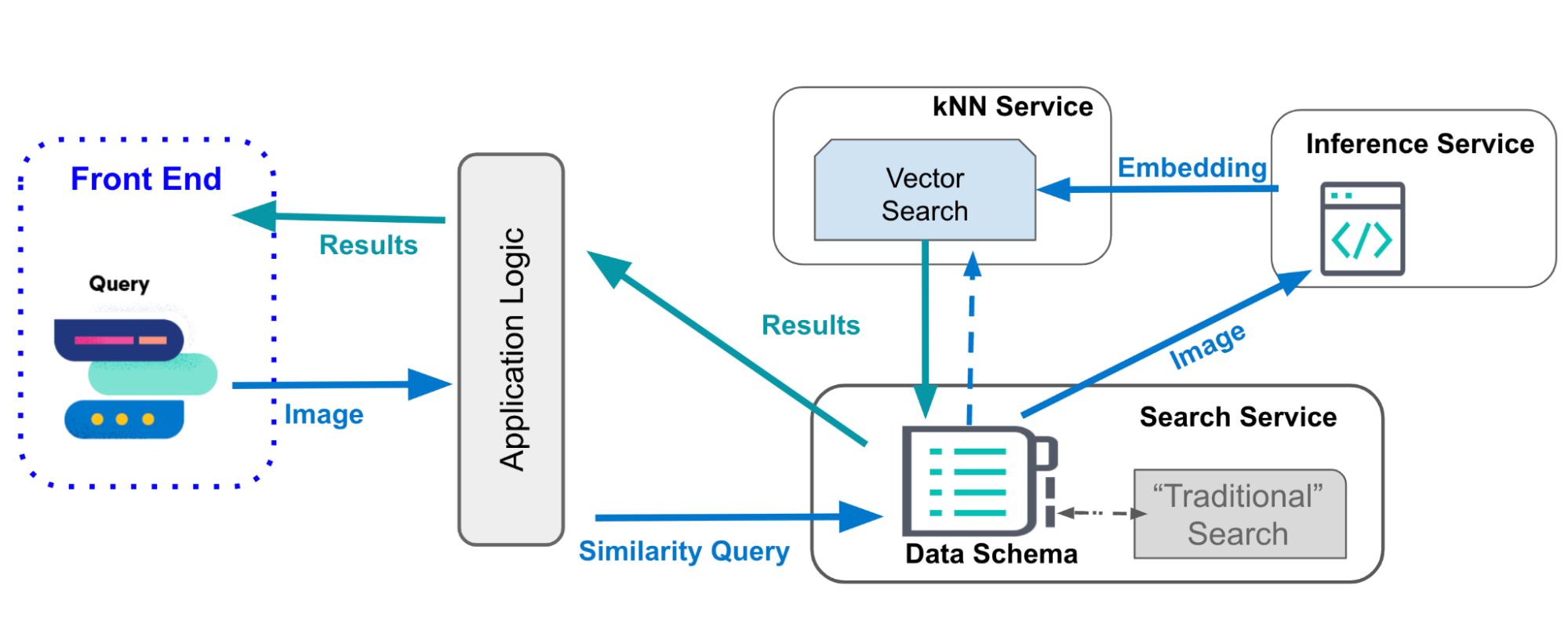
La plupart des frameworks d'application de recherche permettant d'effectuer une recherche dans vos données indexées ne prennent pas en charge nativement la recherche des k plus proches voisins nécessaire pour la recherche vectorielle (de similarités), ni l'inférence requise pour appliquer des modèles NLP. Par conséquent, l'application de recherche de similarités dans les images doit interagir avec plusieurs services, en dehors de la fonctionnalité de recherche principale, le service de recherche des k plus proches voisins. Si du traitement de texte est impliqué, ce service devra également interagir avec un service NLP, comme illustré à la Figure 1, ce qui peut s'avérer compliqué à établir et à maintenir.
En revanche, lors de l'implémentation de la recherche de similarités dans les images à l'aide de la plateforme Elastic, la recherche vectorielle et l'approche NLP sont intégrées de façon native. L'application peut communiquer de façon native avec tous les composants concernés. Le cluster Elasticsearch peut exécuter des recherches des k plus proches voisins et une inférence NLP, comme indiqué ci-dessous.
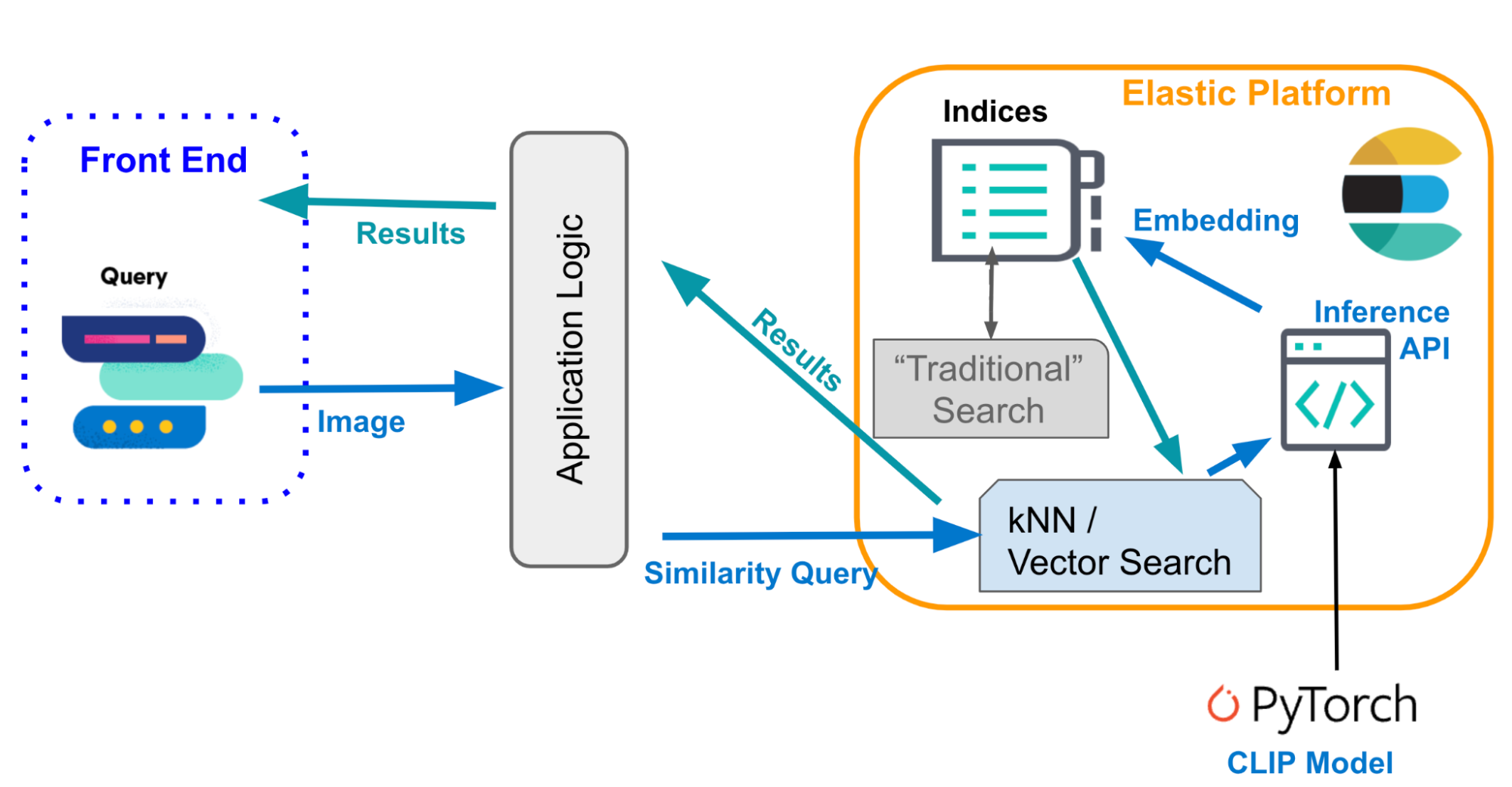
Pourquoi choisir Elastic pour la recherche de similarités dans les images ?
L'implémentation de la recherche de similarités dans les images dans Elastic vous offre des avantages certains. Avec Elastic, vous pouvez…
Réduire la complexité de l'application. Avec Elastic, vous n'avez pas besoin de services distincts pour exécuter la recherche des k plus proches voisins et vectoriser votre entrée de recherche. Les points de terminaison de la recherche vectorielle et de l'inférence NLP sont intégrés dans une plateforme de recherche scalable. Dans d'autres frameworks populaires, l'application de réseaux de neurones profonds et de modèles NLP se produit séparément du scaling des recherches sur de grands jeux de données. Cela signifie que vous devez embaucher des experts, ajouter du temps de développement à votre projet et réserver des ressources pour sa gestion au fil du temps.
Scaler rapidement. Dans Elastic, vous bénéficiez d'avantages à la fois en termes de scaling et de vitesse. Les modèles résident à côté des nœuds exécutant la recherche dans le même cluster, ce qui s'applique aux clusters sur site, et encore plus en cas de déploiement dans le cloud. Elastic Cloud vous permet d'adapter facilement la capacité, selon votre charge de travail actuelle en termes de recherche.
Réduire le nombre de services dont une application à besoin présente des avantages au-delà du scaling. Par exemple, vous pouvez bénéficier d'un monitoring simplifié des performances, d'une empreinte de maintenance réduite et de moins de vulnérabilités de sécurité. Les futures architectures sans serveur simplifieront plus que jamais les applications.
Et ensuite ?
Les parties 1 et 2 de cette série fourniront plus d'informations sur la façon d'implémenter la recherche de similarités dans les images dans Elastic. Elles incluront des considérations relatives à la conception technique pour chacun des composants de l'architecture de haut niveau ainsi que le code nécessaire pour implémenter l'architecture dans Elastic.
Pour vous entraîner à l'application de la recherche vectorielle dans Elastic, inscrivez-vous à notre atelier pratique sur la recherche vectorielle. Consultez notre hub d'événements virtuels pour trouver le prochain atelier et vous y inscrire. En attendant, si vous avez des questions sur l'un des concepts abordés dans cette série, contactez notre communauté dans ce forum de discussion.
Date de publication d'origine : 14 décembre 2022 ; date de mise à jour : 28 février 2023.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer