¿Qué es RAG (generación aumentada de recuperación)?
Definición de generación aumentada de recuperación (RAG)
La generación aumentada de recuperación (RAG) es una técnica que complementa la generación de texto con información de fuentes de datos privadas o propietarias. Combina un modelo de recuperación, que está diseñado para buscar grandes sets de datos o bases de conocimiento, con un modelo de generación como un modelo de lenguaje grande (LLM), que toma esa información y genera una respuesta de texto legible.
La generación aumentada de recuperación puede mejorar la relevancia de una experiencia de búsqueda, al agregar contexto de fuentes de datos adicionales y complementar la base de conocimientos original del entrenamiento de un LLM. Esto mejora el resultado del modelo de lenguaje grande, sin tener que volver a entrenarlo. Las fuentes de información adicionales pueden variar desde información nueva en Internet en la que el LLM no recibió capacitación hasta contexto comercial propietario o documentos internos confidenciales que pertenecen a empresas.
La RAG es valiosa para tareas tales como la respuesta a preguntas y la generación de contenido, ya que permite que los sistemas de AI generativa utilicen fuentes de información externas para producir respuestas más precisas y coherentes con el contexto. Implementa métodos de recuperación de búsqueda —normalmente, búsqueda semántica o búsqueda híbrida— para responder a la intención del usuario y ofrecer resultados más relevantes.
Profundiza en la generación aumentada de recuperación (RAG) y cómo este enfoque puede vincular tus datos confidenciales y en tiempo real a modelos de AI generativa para mejores experiencias de usuario final y precisión.
Entonces, ¿qué es la recuperación de información?
La recuperación de información (IR) se refiere al proceso de buscar y extraer información relevante de una fuente de conocimiento o un set de datos. Es muy parecido a utilizar un motor de búsqueda para buscar información en Internet. Ingresas una búsqueda y el sistema recupera los documentos o páginas web que probablemente contengan la información que estás buscando y te los presenta.
La recuperación de información implica técnicas para indexar y buscar de manera eficiente en grandes sets de datos; esto facilita a las personas el acceso a la información específica que necesitan a partir de un conjunto masivo de datos disponibles. Además de los motores de búsqueda web, los sistemas de IR (recuperación de información) suelen usarse en bibliotecas digitales, sistemas de gestión de documentos y diversas aplicaciones de acceso a la información.
La evolución de los modelos de lenguaje de AI
Los modelos de lenguaje de AI han evolucionado significativamente a lo largo de los años:
- En las décadas de 1950 y 1960, el campo estaba en pañales, con sistemas básicos basados en reglas que tenían una comprensión lingüística limitada.
- En las décadas de 1970 y 1980, se introdujeron los sistemas expertos: estos codificaban el conocimiento humano para resolver problemas, pero tenían capacidades lingüísticas muy limitadas.
- La década de 1990 vio el surgimiento de los métodos estadísticos, que usaban enfoques basados en datos para tareas lingüísticas.
- En la década de 2000, habían surgido técnicas de machine learning como las máquinas de vectores de soporte (que categorizaban diferentes tipos de datos de texto en un espacio de alta dimensión), aunque el aprendizaje profundo todavía estaba en sus primeras etapas.
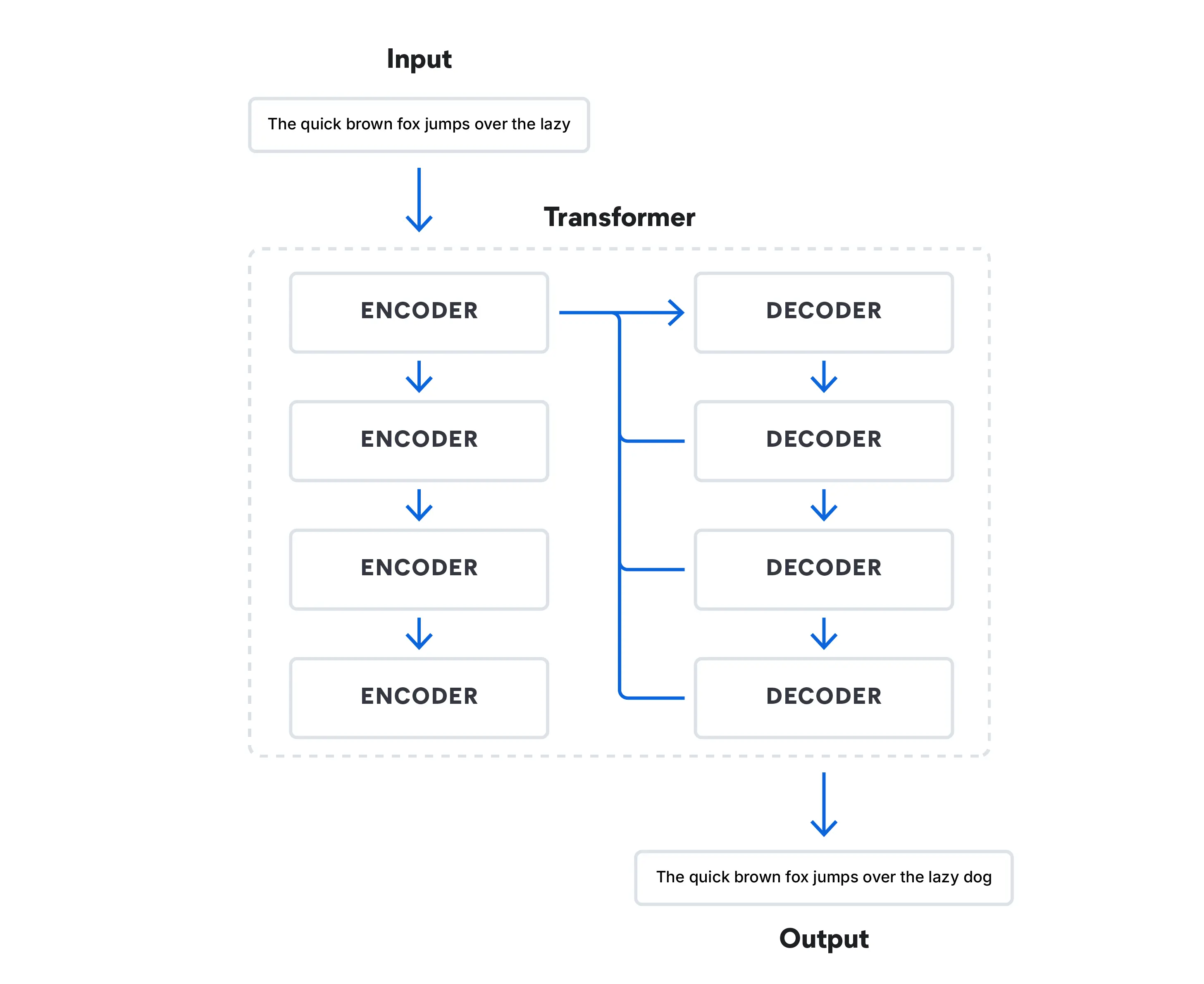
- La década de 2010 marcó un cambio importante en el aprendizaje profundo. La arquitectura de transformadores cambió el procesamiento del lenguaje natural con el uso de mecanismos de atención, lo que permitió que el modelo se enfocara en diferentes partes de una secuencia de entrada al procesarla.
Hoy en día, los modelos de transformadores procesan datos de manera que pueden simular el habla humana al predecir qué palabra viene a continuación en una secuencia de palabras. Estos modelos han revolucionado el campo y han llevado al surgimiento de los LLM como BERT (Representaciones de codificador bidireccional a partir de transformadores) de Google.
Estamos viendo una combinación de modelos masivos preentrenados y modelos especializados diseñados para tareas específicas. Los modelos como RAG continúan ganando terreno, ya que amplían el alcance de los modelos de lenguaje de AI generativa más allá de los límites del entrenamiento estándar. En 2022, OpenAI presentó ChatGPT, que es, posiblemente, el LLM más conocido basado en arquitectura de transformadores. Su competencia incluye modelos básicos basados en chat como Google Bard y Bing Chat de Microsoft. LLaMa de Meta2, que no es un chatbot para consumidores, sino un LLM open source, está disponible gratuitamente para los investigadores que estén familiarizados con el funcionamiento de los LLM.
Relacionado: Cómo elegir un LLM: La guía de primeros pasos con los LLM open source de 2024
¿Cómo funciona RAG?
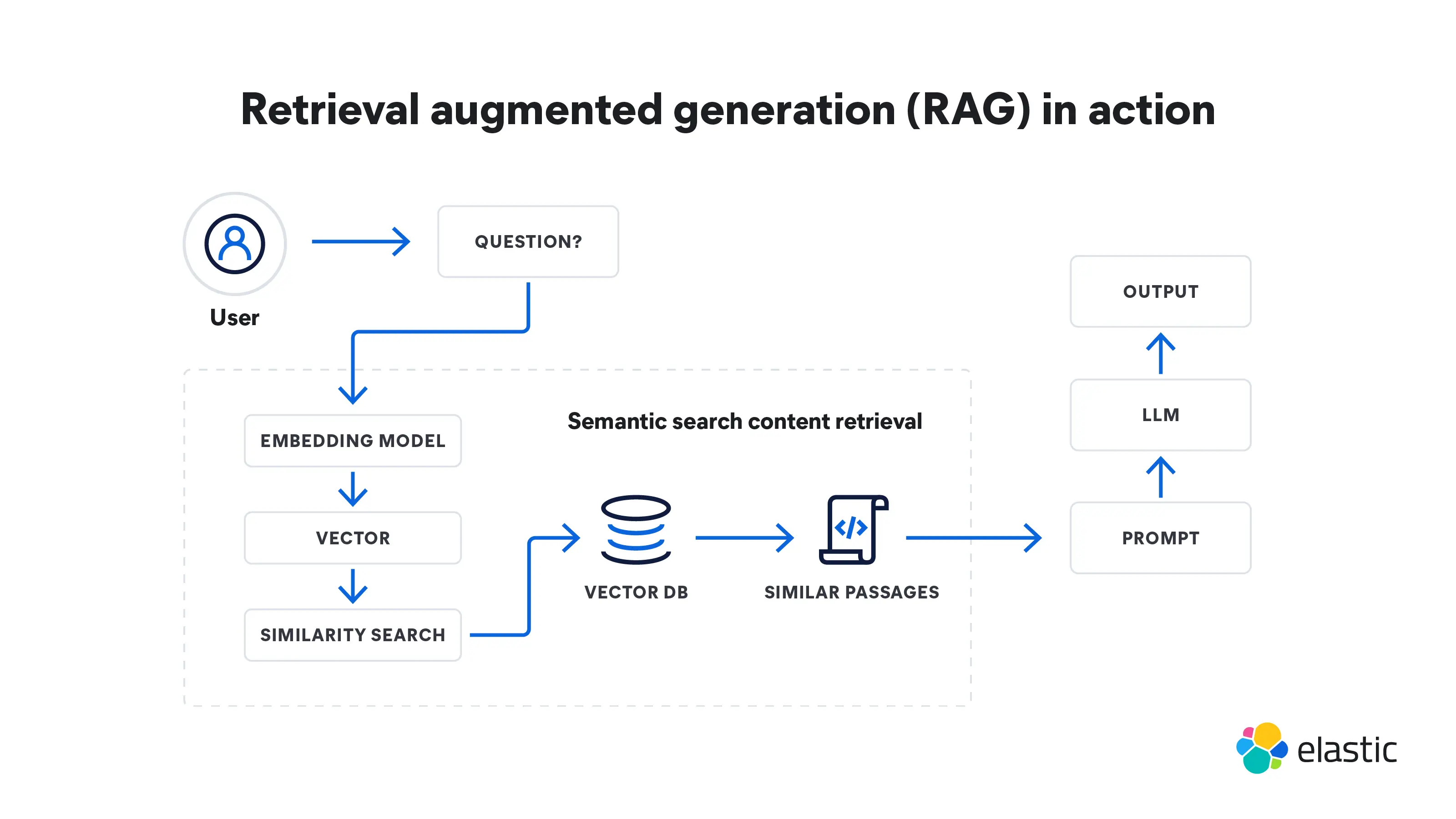
La generación aumentada de recuperación es un proceso de varios pasos que comienza con la recuperación y luego conduce a la generación. Así es como funciona:
Recuperación
- La RAG comienza con una búsqueda de entrada. Podría ser la pregunta de un usuario o cualquier fragmento de texto que requiera una respuesta detallada.
- Un modelo de recuperación toma información pertinente de las bases de conocimiento, bases de datos o fuentes externas, o de varias fuentes a la vez. El lugar donde busca el modelo depende de lo que pide la búsqueda de entrada. Esta información recuperada ahora sirve como fuente de referencia para cualquier hecho y contexto que necesite el modelo.
- La información recuperada se convierte en vectores en un espacio de alta dimensión. Estos vectores de conocimiento se almacenan en una base de datos de vectores.
- El modelo de recuperación clasifica la información recuperada según su relevancia para la búsqueda de entrada. Los documentos o pasajes con las puntuaciones más altas se seleccionan para su posterior procesamiento.
Generación
- A continuación, un modelo de generación, como un LLM, utiliza la información recuperada para generar respuestas de texto.
- El texto generado puede pasar por pasos de posprocesamiento adicionales para garantizar que sea gramaticalmente correcto y coherente.
- Estas respuestas son, en general, más precisas y tienen más sentido en contexto porque han sido moldeadas por la información complementaria que ha proporcionado el modelo de recuperación. Esta capacidad es especialmente importante en dominios especializados donde los datos públicos de Internet son insuficientes.
Beneficios de RAG
La generación aumentada de recuperación tiene varios beneficios sobre los modelos de lenguaje que funcionan de forma aislada. Aquí hay algunas formas en que ha mejorado la generación de texto y las respuestas:
- La RAG se asegura de que tu modelo pueda acceder a los datos más recientes y actualizados y a la información relevante, ya que puede actualizar periódicamente sus referencias externas. Esto garantiza que las respuestas que genera incorporen la información más reciente que podría ser relevante para el usuario que realiza la búsqueda. También puedes implementar seguridad a nivel de documento para controlar el acceso a los datos dentro de un flujo de datos y restringir los permisos de seguridad a documentos particulares.
- La RAG es una opción más rentable ya que requiere menos cómputo y almacenamiento, lo que significa que no es necesario tener tu propio LLM ni gastar tiempo y dinero para ajustar tu modelo.
- Una cosa es afirmar que es exacta y otra es demostrarlo. La RAG puede citar sus fuentes externas y proporcionárselas al usuario para respaldar sus respuestas. Si así lo desea, el usuario puede evaluar las fuentes para confirmar que la respuesta que recibió es precisa.
- Si bien los chatbots basados en LLM pueden crear respuestas más personalizadas que las respuestas escritas anteriormente, la RAG puede adaptar sus respuestas aún más. Esto se debe a que tiene la capacidad de utilizar métodos de recuperación de búsqueda (generalmente, búsqueda semántica) para hacer referencia a una variedad de puntos informados por el contexto al sintetizar su respuesta midiendo la intención.
- Cuando un LLM se enfrenta a una búsqueda compleja para la que no ha sido capacitado, a veces puede "alucinar" y proporcionar una respuesta inexacta. Al basar sus respuestas en referencias adicionales de fuentes de datos relevantes, la RAG puede responder con mayor precisión a consultas ambiguas.
- Los modelos de RAG son versátiles y se pueden aplicar a una amplia gama de tareas de procesamiento del lenguaje natural, incluidos sistemas de diálogo, generación de contenido y recuperación de información.
- El sesgo puede ser un problema en cualquier AI creada por el hombre. Al confiar en fuentes externas verificadas, la RAG puede ayudar a reducir el sesgo en sus respuestas.
Generación aumentada de recuperación frente al ajuste
La generación aumentada de recuperación y el ajuste son dos enfoques diferentes para entrenar modelos de lenguaje de AI. Mientras que la RAG combina la recuperación de una amplia gama de conocimientos externos con la generación de texto, el ajuste se centra en una gama limitada de datos para distintos propósitos.
En el ajuste, un modelo preentrenado se entrena aún más con datos especializados para adaptarlo a un subconjunto de tareas. Implica modificar los pesos y parámetros del modelo en función del nuevo set de datos, lo que le permite aprender patrones específicos de tareas mientras conserva el conocimiento de su entrenamiento previo inicial.
El ajuste se puede utilizar para todo tipo de AI. Un ejemplo básico es aprender a reconocer gatitos en el contexto de la identificación de fotografías de gatos en Internet. En los modelos basados en lenguaje, el ajuste puede ayudar con aspectos como la clasificación de texto, el análisis de opiniones y el reconocimiento de entidades con nombre, además de la generación de texto. Sin embargo, este proceso puede llevar mucho tiempo y ser costoso. La RAG acelera el proceso y consolida estos costos con menos necesidades de computación y almacenamiento.
Debido a que tiene acceso a recursos externos, la RAG es particularmente útil cuando una tarea exige incorporar información dinámica o en tiempo real de la web o bases de conocimiento empresariales para generar respuestas fundamentadas. El ajuste tiene diferentes fortalezas: si la tarea en cuestión está bien definida y el objetivo es optimizar el rendimiento únicamente en esa tarea, el ajuste puede ser muy eficiente. Ambas técnicas tienen la ventaja de no tener que entrenar un LLM desde cero para cada tarea.
Desafíos y limitaciones de la generación aumentada de recuperación
Si bien la RAG ofrece importantes ventajas, también enfrenta varios desafíos y limitaciones:
- La RAG se basa en conocimientos externos. Puede producir resultados inexactos si la información recuperada es incorrecta.
- El componente de recuperación de la RAG implica buscar en grandes bases de conocimiento o en la web, lo que puede ser costoso y lento desde el punto de vista informático, aunque aún más rápido y menos costoso que el ajuste.
- La integración perfecta de los componentes de recuperación y generación requiere un diseño y una optimización cuidadosos, lo que puede generar dificultades potenciales en la capacitación y la implementación.
- Recuperar información de fuentes externas podría generar preocupaciones sobre la privacidad cuando se trata de datos confidenciales. Cumplir con los requisitos de privacidad y cumplimiento también puede limitar a qué fuentes puede acceder la RAG. Sin embargo, esto se puede resolver mediante el acceso a nivel de documento, en el que puede otorgar acceso y permisos de seguridad a roles específicos.
- La RAG se basa en la exactitud de los hechos. Puede tener dificultades para generar contenido imaginativo o ficticio, lo que limita su uso en la generación de contenido creativo.
Tendencias futuras de la generación aumentada de recuperación
Las tendencias futuras de la generación aumentada de recuperación se centran en hacer que la tecnología de RAG sea más eficiente y adaptable en distintas aplicaciones. Aquí hay algunas tendencias para tener en cuenta:
Personalización
Los modelos RAG seguirán incorporando conocimientos específicos del usuario. Esto les permitirá brindar respuestas aún más personalizadas, particularmente en aplicaciones de recomendaciones de contenido y asistentes virtuales.
Comportamiento personalizable
Además de la personalización, los mismos usuarios también pueden tener más control sobre cómo se comportan y responden los modelos de RAG para ayudarlos a obtener los resultados que buscan.
Escalabilidad
Los modelos de RAG podrán manejar volúmenes de datos e interacciones de usuarios aún mayores que los que pueden manejar actualmente.
Modelos híbridos
Integración de RAG con otras técnicas de AI (por ejemplo, el aprendizaje por refuerzo) permitirá contar con sistemas aún más versátiles y sensibles al contexto, que puedan manejar distintos tipos de datos y tareas simultáneamente.
Despliegue en tiempo real y de baja latencia
A medida que los modelos de RAG avanzan en su velocidad de recuperación y tiempo de respuesta, se usarán más en aplicaciones que requieren respuestas rápidas (como chatbots y asistentes virtuales).
Profundiza sobre las tendencias de búsqueda técnica de 2024. Mira este webinar para conocer las mejores prácticas, las metodologías emergentes y cómo las principales tendencias influyen en los desarrolladores en 2024.
Generación aumentada de recuperación con Elasticsearch
Con Elasticsearch, puedes crear búsquedas habilitadas para RAG para tu app de AI generativa, sitio web, experiencias de clientes o de empleados. Elasticsearch proporciona un conjunto de herramientas completo que te permite hacer lo siguiente:
- Almacenar y buscar datos propietarios y otras bases de conocimiento externas para extraer contexto
- Generar resultados de búsqueda altamente relevantes a partir de tus datos mediante distintos métodos: búsqueda textual, vectorial, híbrida o semántica
- Crear respuestas más precisas y experiencias atractivas para tus usuarios
Descubre cómo Elasticsearch puede mejorar la AI generativa para tu negocio
Explora más recursos de RAG
- Explora el Playground de IA
- Ve más allá de los conceptos básicos de RAG
- Elasticsearch - el motor de búsqueda más relevante para RAG
- Elegir un LLM: La guía de primeros pasos con los LLM open source de 2024
- Explicación de los algoritmos de búsqueda de AI
- Cómo hacer un chatbot: qué deben hacer y qué no deben hacer los desarrolladores en un mundo impulsado por la AI
- Tendencias técnicas de 2024: cómo están evolucionando las tecnologías de búsqueda e IA generativa
- Crea prototipos e intégrate con los LLM con más rapidez
- La base de datos vectorial más descargada del mundo: Elasticsearch
- Desmitificar ChatGPT: Diferentes métodos para crear búsquedas de AI
- Recuperación versus veneno: Lucha contra los ataques de AI a la cadena de suministro