¿Qué es la recuperación de información?
Definición de recuperación de información
La recuperación de información (Information Retrieval, IR) es un proceso que facilita la recuperación efectiva y eficiente de información relevante de grandes colecciones de datos no estructurados o semiestructurados. Los sistemas de IR ayudan a buscar, localizar y presentar información que coincida con la búsqueda o la necesidad de información de un usuario.
Como forma dominante de acceso a la información, miles de millones de personas que utilizan motores de búsqueda confían en la recuperación de información todos los días. Mediante el despliegue de diversos modelos, algoritmos y técnicas cada vez más avanzadas (por ejemplo: búsqueda de vectores), los sistemas de recuperación de información permiten el acceso de búsqueda a una amplia y creciente gama de fuentes, incluidos documentos, elementos dentro de documentos, metadatos y bases de datos de textos, imágenes, videos y sonidos.
Breve historia de la recuperación de información
Las raíces de la recuperación de información se remontan a la antigüedad, cuando se crearon bibliotecas y archivos para organizar y almacenar información, incluida la indexación y alfabetización del trabajo académico. En la década de 1800, las tarjetas perforadas se utilizaban para procesar información y, en 1931, Emanuel Goldberg recibió una patente para el primer dispositivo electromecánico de recuperación de documentos exitoso, conocido como "Máquina estadística", diseñado para buscar datos codificados en películas.
La recuperación de información comenzó a formalizarse en lo que se convertiría en una disciplina científica a mediados del siglo XX, junto con el desarrollo de las computadoras modernas. Gerard Salton y Hans Peter Luhn fueron pioneros en los primeros modelos de recuperación automatizada de documentos. Salton y sus colegas de Cornell crearon el Sistema de Recuperación de Información SMART en la década de 1960, un hito en el campo al que se le atribuye haber sentado las bases para las técnicas modernas de IR y conceptos clave, incluida la matriz de términos-documentos, el modelo de espacio vectorial, la retroalimentación de relevancia y la clasificación de Rocchio.
En la década de 1970, con la aparición de técnicas de recuperación más avanzadas, modelos probabilísticos y marcos de trabajo de procesamiento de vectores totalmente articulados, el campo había avanzado significativamente. Con la llegada de los motores de búsqueda a finales de la década de 1990, los sistemas y modelos de IR que antes pertenecían principalmente al ámbito académico, las instituciones y las bibliotecas se pusieron al servicio de todos.
Tipos de modelos de recuperación de información
Se diseñan diferentes tipos de modelos de recuperación de información para abordar desafíos específicos y establecer procesos para recuperar información relevante. Hay modelos clásicos que forman las bases del campo, modelos no clásicos que intentan abordar las limitaciones de los enfoques tradicionales y modelos de IR alternativos que van aún más allá, a menudo integrando tecnologías avanzadas como Machine Learning y los modelos de lenguaje. A nivel general, los tipos de modelos de recuperación de información más comunes incluyen:
Modelo booleano
El modelo booleano, uno de los modelos de recuperación de información más simples y antiguos, se basa en la lógica booleana, que utiliza operadores que incluyen Y, O y NO para combinar términos de búsqueda. Los documentos se representan como conjuntos de términos y se procesa una búsqueda para identificar los documentos que coinciden con las condiciones especificadas. Aunque es eficaz para coincidencias de búsquedas precisas, el modelo booleano no puede clasificar documentos con base en su relevancia ni ofrecer coincidencias parciales.
Modelo de espacio vectorial
En este modelo, los documentos y las consultas se representan como vectores en un espacio multidimensional. Cada dimensión corresponde a un término único y el valor de cada dimensión representa la importancia y frecuencia del término en el documento o búsqueda. Se calcula la similitud del coseno entre el vector de búsqueda y los vectores de documentos para determinar la relevancia de los documentos para la búsqueda. Desarrollado en parte para abordar las desventajas del modelo booleano, el modelo de espacio vectorial puede proporcionar resultados clasificados con base en puntuaciones de relevancia y se utiliza ampliamente en la recuperación de texto.
Modelo probabilístico
Este modelo estima la probabilidad de que un documento sea relevante para una búsqueda determinada. Considera factores como la frecuencia de los plazos y la extensión de los documentos para calcular las probabilidades de relevancia. Es particularmente útil para tratar con grandes cantidades de datos. Debido a que funciona con estadísticas ponderadas, el modelo es ideal para proporcionar resultados clasificados.
Indexación semántica latente (LSI)
La indexación semántica latente (Latent Semantic Indexing, LSI) utiliza descomposición de valores singulares (Singular Value Decomposition, SVD) para capturar las relaciones semánticas entre términos y documentos. Al igual que la búsqueda semántica, la indexación semántica utiliza la intención y el contexto para identificar documentos relacionados conceptualmente, incluso si no comparten términos exactos. Esta capacidad clave hace que la LSI sea útil para extraer el significado contextual de las palabras en un cuerpo de texto.
Okapi BM25
Una de las variantes más populares del modelo probabilístico, BM25, es una función de clasificación de relevancia de búsqueda. La utilizan los motores de búsqueda para estimar la relevancia de un documento para una búsqueda. Clasifica un conjunto de documentos con base en los términos de búsqueda que aparecen en cada documento, independientemente de la interrelación entre los términos dentro de un documento, y consta de muchas funciones de puntuación con diferentes componentes y parámetros. BM significa "mejor combinación" (best matching).
¿Por qué es importante la recuperación de información?
En la era de la información, los datos se generan cada segundo a una escala que antes era inimaginable. Sin un medio viable para acceder a la información, los datos son efectivamente inútiles. Los sistemas de IR garantizan que los usuarios puedan obtener la información relevante que necesitan en medio del creciente ruido de la sobrecarga de información.
La recuperación de información desempeña un papel vital en casi todas las industrias y dominios del mundo moderno, desde la academia y el comercio electrónico hasta la atención médica y la defensa. Es una interfaz hombre-máquina que ayuda en la toma de decisiones, la investigación y el descubrimiento de conocimientos, tanto a nivel empresarial como personal. Desde buscar en nuestros escritorios localizados hasta descubrir las noticias del mundo, o desde la investigación genómica hasta el filtrado de spam, la recuperación de información es fundamental para casi todas las facetas de nuestras vidas.
Los motores de búsqueda dependen de modelos de recuperación de información para ofrecer resultados de búsqueda precisos. Las plataformas de comercio electrónico utilizan modelos de recuperación para recomendar productos con base en las preferencias y el comportamiento del usuario. Las bibliotecas digitales dependen de la ciencia de recuperación de información para ayudar a los usuarios a realizar investigaciones. En el sector de la salud, los sistemas de IR ayudan a buscar en bases de datos registros de pacientes, investigaciones médicas y protocolos de tratamiento relevantes. Y los profesionales del derecho utilizan la recuperación de información para revisar grandes volúmenes de casos legales en busca de precedentes.
¿Cómo funciona un sistema de recuperación de información?
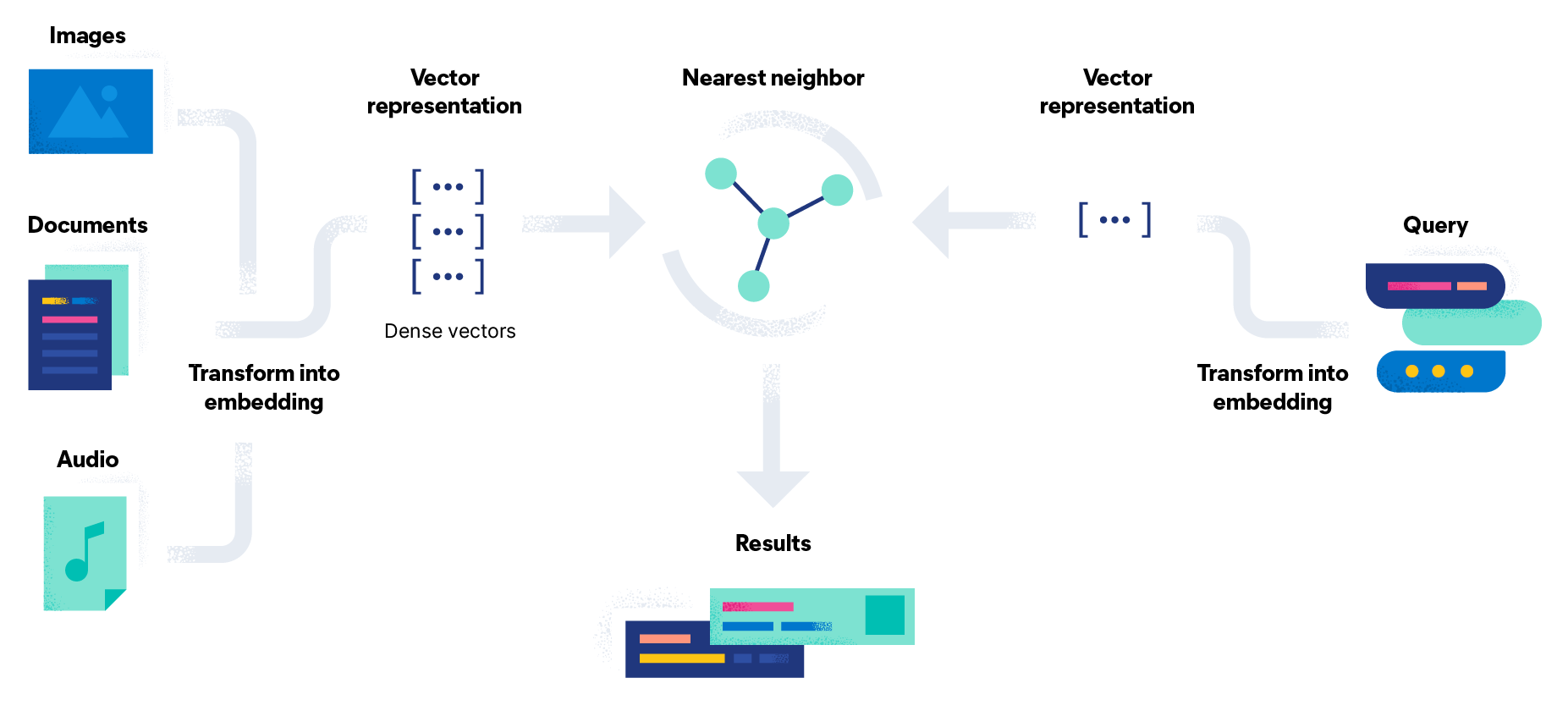
El proceso de recuperación de información generalmente se activa cuando un usuario ingresa una búsqueda formal en un sistema indicando sus necesidades de información. El sistema de IR crea un índice de documentos en una colección de contenido o base de datos de información. Los objetos de datos, incluidos los de documentos de texto, imágenes, audio y videos, se procesan para extraer términos relevantes y datos sustitutos, y se utilizan estructuras de datos para almacenar y recuperar esas entidades de manera eficiente.
Cuando un usuario envía una búsqueda, el sistema la procesa para identificar términos relevantes y determinar su importancia. Luego, el sistema clasifica los documentos con base en su relevancia para la búsqueda. En muchos casos, los modelos y algoritmos de IR se utilizan para calcular una puntuación numérica con base en lo bien que coincide cada objeto de la colección o base de datos con la búsqueda. Muchas consultas no coincidirán exactamente: los documentos más relevantes se presentan al usuario en una lista clasificada. Estos resultados clasificados representan una de las diferencias clave entre la búsqueda de recuperación de información y la búsqueda en bases de datos.
Componentes principales de un sistema de recuperación de información
Un sistema de recuperación de información consta de varios componentes clave:
Colección de documentos
El conjunto de documentos de los que el sistema puede recuperar información.
Componente de indexación
Los datos y documentos de origen se procesan para crear un índice mediante la asignación de términos y datos a los documentos que los contienen, a menudo en una estructura de datos dedicada y optimizada.
Procesador de búsquedas
El procesador de búsquedas analiza las consultas de los usuarios y las palabras clave y las prepara para compararlas con las entidades indexadas.
Algoritmo de clasificación
El algoritmo de clasificación determina la relevancia de los documentos para una búsqueda y les asigna puntuaciones. El más común es el algoritmo de clasificación BM25 (Best Match 25), que destaca por su enfoque modificado de la frecuencia de los términos que evita sobresaturar el documento con palabras clave y términos repetidos.
Interfaz de usuario
La interfaz de usuario (User Interface, UI) es la pantalla a través de la cual los usuarios interactúan con el sistema, envían consultas y se les presentan los resultados. Aquí, los resultados se pueden ajustar con base en lo bien que responden a la búsqueda del usuario. En algunos casos, los mecanismos podrían permitir a los usuarios proporcionar retroalimentación sobre la relevancia de los documentos recuperados, que pueden utilizarse para mejorar recuperaciones futuras.
Beneficios de la recuperación de información
Los beneficios importantes de los modelos de recuperación de información incluyen:
- Acceso eficiente a la información: por encima de todo, los sistemas de IR ahorran a las personas una cantidad incalculable de tiempo y esfuerzo. La recuperación de información permite a los usuarios acceder rápidamente a información relevante sin buscar manualmente en grandes cantidades de documentos y datos.
- Descubrimiento de conocimientos: la recuperación de información es una herramienta poderosa que nos permite dar sentido a los datos. Con la IR, los usuarios pueden identificar tendencias, patrones y relaciones dentro de los datos que podrían no ser evidentes inicialmente.
- Personalización: algunos sistemas de IR pueden adaptar los resultados de manera significativa a los usuarios individuales con base en sus preferencias y comportamientos.
- Soporte para decisiones: los profesionales están capacitados para tomar decisiones informadas con acceso a la información más pertinente cuando la necesitan.
Desafíos y limitaciones de la recuperación de información
A pesar de los importantes avances, la recuperación de información nunca ha sido perfecta. Persisten problemas, desafíos y limitaciones conocidos, que incluyen:
Ambigüedad. El lenguaje natural es inherentemente ambiguo, lo que dificulta la interpretación precisa de las consultas de los usuarios. Problemas similares de vaguedad e incertidumbre pueden afectar el proceso de indexación y evaluación, particularmente con objetos como imágenes y videos.
Relevancia. La determinación de la relevancia es subjetiva y puede variar con base en el contexto y la intención del usuario. Los criterios utilizados para determinar el valor y la importancia pueden estar regidos por un conjunto de estándares generales imperfectos que no reflejan las necesidades específicas del usuario individual.
Brechas semánticas. Los sistemas de recuperación pueden tener dificultades para capturar el significado más profundo del contenido debido a la brecha entre la representación textual y la comprensión humana. La falta de claridad en la información y la expresión de los usuarios representa un obstáculo importante para el éxito de la IR. El procesamiento del lenguaje natural avanzado impulsado por la AI busca cerrar esas brechas semánticas y de ambigüedad.
Escalabilidad. A medida que aumentan los volúmenes de datos, mantener una recuperación e indexación eficientes y efectivas se vuelve más complejo, y se requieren cada vez más recursos y potencia informática.
Tendencias futuras en la recuperación de información
Con avances recientes en AI generativa y Machine Learning, la recuperación de información tal como la conocemos puede estar al borde de un cambio transformador.
Las técnicas avanzadas de Machine Learning ya están mejorando la recuperación al aprender de las interacciones del usuario y adaptarse a contextos, ubicaciones y preferencias cambiantes. El procesamiento mejorado del lenguaje natural y el análisis semántico crean una mejor comprensión de las consultas de los usuarios y el contenido de los documentos. Los sistemas de recuperación también están evolucionando para manejar de manera más efectiva la avalancha cada vez mayor de contenido multimedia.
El impacto de la AI generativa en la recuperación de información tiene el potencial de ser revolucionario. En lugar de la lista clasificada de resultados a la que estamos acostumbrados, que requiere ordenar manualmente los enlaces y documentos existentes para encontrar lo que estamos buscando, recibiremos respuestas reales a nuestras preguntas. El contexto se trasladará de una pregunta a otra, lo que permitirá consultas complejas, conversacionales y de varios pasos, con las barreras del procesamiento del lenguaje humano y la intención prácticamente borradas. En lugar de reunir las respuestas nosotros mismos, los motores de búsqueda harán el trabajo por nosotros, sintetizando información en resultados específicos y personalizados en forma de contenido original que proporcione exactamente lo que necesitamos y nada que no necesitemos.
Profundiza en las tendencias de búsqueda técnica de 2024. Mira este webinar para conocer las mejores prácticas, las metodologías emergentes y cómo las principales tendencias influencian a los desarrolladores en 2024.
Recuperación de información con Elasticsearch
Elastic se dedica a mejorar constantemente las capacidades de recuperación de información disponibles en Elastic Stack. Nuestro modelo de recuperación más nuevo, Elastic Learned Sparse Encoder, aumenta la recuperación lista para utilizar de Elastic con un modelo de lenguaje previamente entrenado. Y para lograr una verdadera experiencia con un solo clic, la hemos integrado con el nuevo Elasticsearch Relevance Engine.
Elasticsearch también tiene excelentes capacidades de recuperación léxica y herramientas completas para combinar los resultados de diferentes consultas, un concepto conocido como recuperación híbrida. También estamos mejorando las capacidades del chatbot con NLP y búsqueda vectorial, lanzando modelos de procesamiento de lenguaje natural de terceros para incrustaciones de texto y evaluando nuestro rendimiento mediante un subconjunto de BEIR.
Explora más recursos de recuperación de información
- Mejora de la recuperación de información en Elastic Stack: Presentamos Elastic Learned Sparse Encoder, nuestro nuevo modelo de recuperación
- Mejora de la recuperación de información en Elastic Stack: Pasos para mejorar la relevancia de la búsqueda
- Mejora de la recuperación de información en Elastic Stack: Recuperación de pasajes de evaluación comparativa
- Mejora de la recuperación de información en Elastic Stack: Recuperación híbrida
- Explicación de los algoritmos de búsqueda de la AI
Lo que deberías hacer a continuación
Cuando estés listo… estas son cuatro formas en las que podemos ayudarte a aprovechar la información de los datos de tu empresa:
- Comienza una prueba gratuita y ve cómo Elastic puede ayudar a tu empresa.
- Haz un recorrido por nuestras soluciones para ver cómo funciona Elasticsearch Platform y cómo se ajustarán a tus necesidades.
- Descubre cómo brindar AI generativa en la empresa.
- Comparte este artículo con alguien que sepas que disfrutaría leerlo. Compártelo por email, LinkedIn, Twitter o Facebook.