RAG con contexto en el que puedes confiar
Las aplicaciones de IA deben ofrecer resultados precisos a escala para generar confianza en los usuarios. Fundamenta los modelos de lenguaje grandes (LLM) con la precisión de la recuperación híbrida de Elasticsearch y escala la Retrieval-Augmented Generation (RAG) con baja latencia y alta eficiencia.
RAG diseñado para una precisión sin igual y un escalado vectorial eficiente
Ofrece el contexto adecuado con el rendimiento vectorial, la eficiencia de costos y la seguridad que exige la producción.
Proporciona a tus aplicaciones RAG el contexto adecuado con búsqueda híbrida, reclasificación semántica e inferencia integrada usando modelos de Jina AI de terceros o nativos de primer nivel. Sustituye la recuperación vectorial ingenua por una única consulta que combine palabras clave, vectores y filtros.

Escala el contexto a través de miles de millones de documentos que abarcan datos estructurados, no estructurados y vectoriales sin sacrificar la calidad de recuperación ni el gasto. Los algoritmos de cuantización y optimización de disco como DiskBBQ reducen la memoria hasta en un 95 % mientras mantienen una alta calidad de clasificación con baja latencia.

Simplifica tu pipeline con una plataforma unificada que extrae contexto de documentos y registros no estructurados y estructurados en una sola consulta. Aplica controles de acceso a nivel de documento y basados en roles (RBAC) para que los LLM solo expongan los datos que un usuario debería ver.
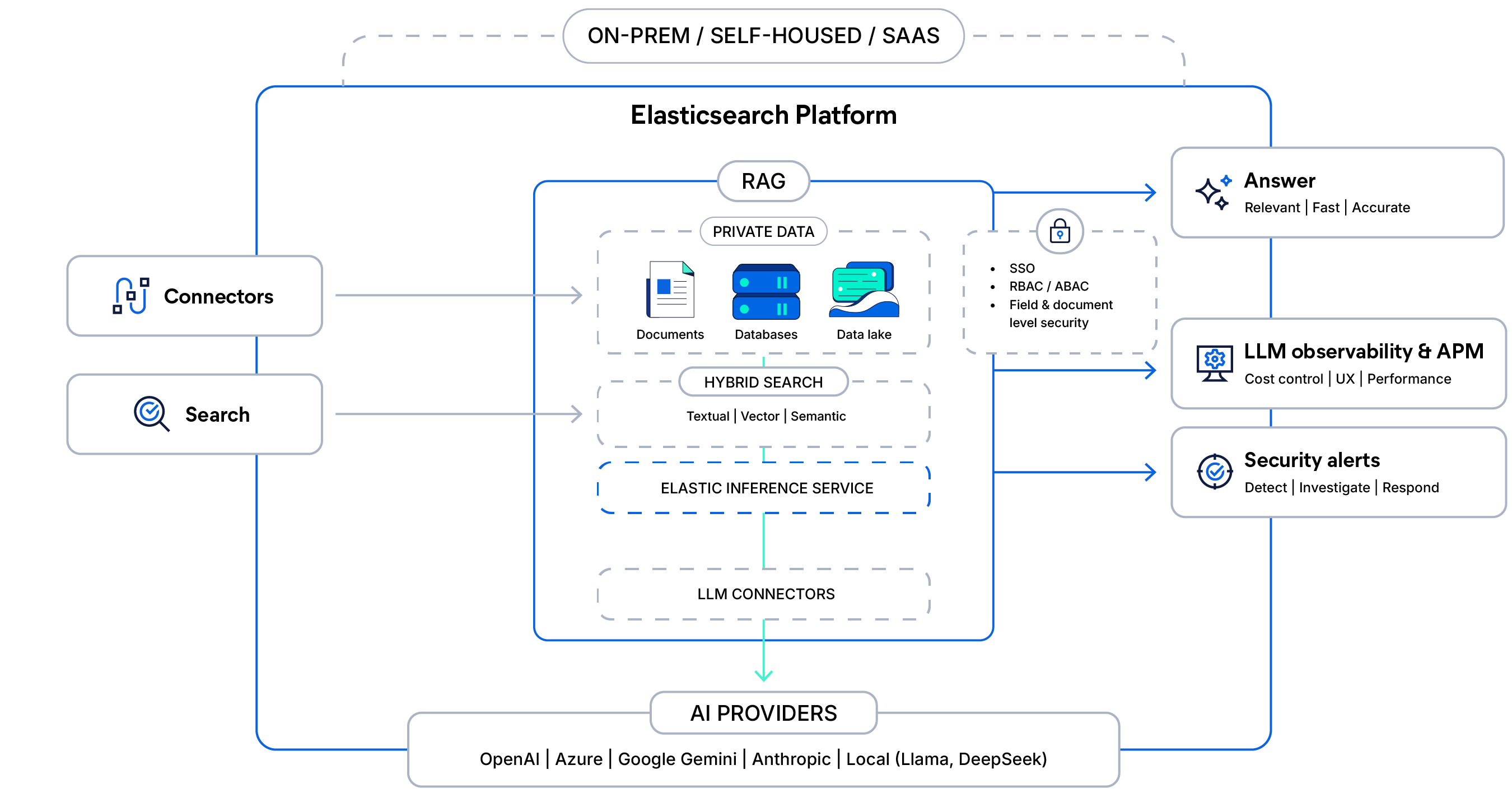
La arquitectura detrás del RAG consciente del contexto
Conecta tus datos privados con búsqueda híbrida segura e inferencia gestionada, fundamenta las respuestas de LLM con controles de acceso y ofrece respuestas rápidas, observables y listas para producción a gran escala.
¿Qué estás desarrollando?
Crea chats basados en tus datos y agentes guiados por el contexto. Explora nuestro catálogo completo de formación o sigue nuestros tutoriales en Elasticsearch Labs.

Preguntas y respuestas sobre tus datos. Crea un sistema RAG con Gemma, Hugging Face y Elasticsearch.

Construye apps de RAG con agentes más rápido gracias a LangGraph y Elasticsearch.

Elastic creó un asistente de soporte GenAI: conoce la arquitectura, las técnicas y las mejores prácticas para crear uno propio.
Preguntas frecuentes
¿Qué es RAG en IA?
¿Qué es RAG en IA?
Retrieval-Augmented Generation (comúnmente conocido como RAG) es un patrón de procesamiento del lenguaje natural que permite a las empresas buscar en fuentes de datos privados y proporcionar un contexto que sustente grandes modelos de lenguaje. Esto produce respuestas más precisas y en tiempo real en aplicaciones de AI generativa.
¿Cuáles son los beneficios de RAG?
¿Cuáles son los beneficios de RAG?
RAG, cuando se implementa de manera óptima, proporciona acceso seguro a datos privados relevantes y específicos del dominio en tiempo real. Puede reducir la incidencia de alucinaciones en aplicaciones de AI generativa y aumentar la precisión de las respuestas.
¿Cuáles son los beneficios de usar Elastic para flujos de trabajo de RAG?
¿Cuáles son los beneficios de usar Elastic para flujos de trabajo de RAG?
Elastic hace que RAG esté preparado para la producción, ya que resuelve las partes más difíciles de manera inmediata: la ingesta y el anclaje de datos de alta calidad, la recuperación precisa y eficiente a escala, la aplicación de seguridad a nivel de documento, y la preservación de la atribución de la fuente para respuestas confiables. Con recuperación vectorial, léxica e híbrida nativa; modelos de primera parte como ELSER e integraciones flexibles de modelos de terceros en todo el ecosistema de GenAI; y rendimiento probado a escala empresarial, Elastic ayuda a los equipos a construir sistemas RAG que son más rápidos de lanzar, más fáciles de ajustar y confiables en producción.
¿Cómo habilita Elasticsearch la ingeniería de contexto?
¿Cómo habilita Elasticsearch la ingeniería de contexto?
Elasticsearch está diseñado para la relevancia a escala, que es la base de la ingeniería de contexto. Reúne la búsqueda estructurada, de vectores y de palabras clave con analíticas, inferencia y observabilidad en una sola plataforma. Esto hace que sea más fácil para los desarrolladores almacenar, recuperar y clasificar datos empresariales estructurados y no estructurados con precisión, a fin de que los agentes siempre obtengan el contexto correcto.
Con Agent Builder, Elasticsearch lleva esto más allá al integrar chat, recuperación, creación de herramientas y orquestación directamente en la plataforma. Los desarrolladores pueden crear, probar y escalar agentes contextualizados en minutos al usar sus propios datos, modelos y herramientas, todo ello con el respaldo de la relevancia, la seguridad y el rendimiento de Elasticsearch.