Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
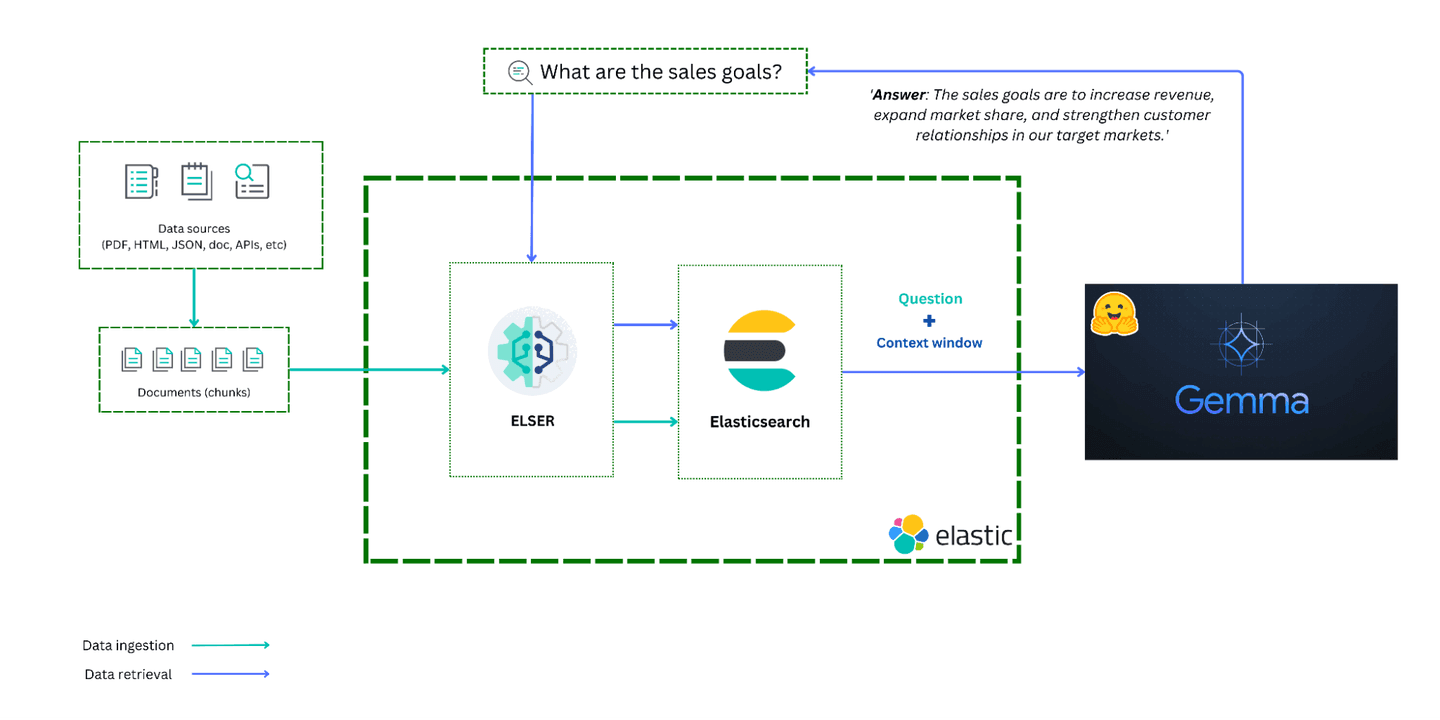
This blog will show you how to build a RAG system using Elasticsearch and Python to perform a semantic search and create a question-answering service that runs on your private data set. You will fetch the most relevant documents as a context window and send them to the Gemma model along with a question to be answered.

Background
Google has recently launched the state-of-the-art open model Gemma. It is built on the same research and technology which Gemini developed. You have the option to customize(fine-tune) the Gemma using your private data according to your requirement, ask questions for summarization or utilize it for RAG (Retrieval Augmented Generation) by specifying a context window. It can fulfill different kinds of use cases. Gemma has been released in two sizes - Gemma2B & Gemma7B. Both have pre-trained and instruction-tuned variants. You can pick any of them gemma-2b, gemma-2b-it, gemma-7b, gemma-7b-it. These are text-to-text and decoder-only models that work only with the English language.
How to a RAG system with Gemma, Hugging Face & Elasticsearch
Prerequisites
- Elastic credentials - Create an Elastic Cloud deployment to get all Elastic credentials (
ELASTIC_CLOUD_ID,ELASTIC_API_KEY). - ELSER v2 - Make sure the Elastic ELSERv2 model is downloaded and deployed in your Elastic instance.
- Hugging Face token - To get started with the Gemma model, it is necessary to agree to the terms on Hugging Face and create the access token with a
writerole. - Gemma model - We're going to use gemma-2b-it, though Google has also released gemma-2b, gemma-7b, gemma-7b-it models.
- Python 3.10 or higher
Overview
We will proceed step by step to construct the RAG. We’re going to use LangChain to build a complete flow. LangChain gives the framework to develop LLM-powered apps easily though you can write your own flow to develop a RAG.
- Prepare documents to store in Elasticsearch by passing through the ELSERv2 model.
- Run the Gemma model locally by using Hugging Face.
- Perform semantic search and fetch the most relevant document set.
- Ask questions to locally running Gemma models by passing prompts including context windows.
We are going to build a complete flow in Python.
1. Import packages & credentials
Install required packages
Import all dependencies
We’re going to use different modules of LangChain for different purposes.
Get credentials
This will accept ELASTIC_API_KEY and ELASTIC_CLOUD_ID from the user input. All data will be stored in the gemma-rag index.
2. Preparing documents
Download the sample dataset and deserialize the document
JSON contains workplace data like vacation policy, work-from-home policy, explaining how compensation works, onboarding steps, etc. Consider this is our private data set to which Gemma is not trained or has any access. At the end, our system will find the answer from this JSON data only.
Document chunking
Document chunking in RAG refers to breaking down large documents into smaller segments for more efficient processing and retrieval during question-answering tasks.
Why is document chunking needed?
Context window limit
The context window in RAG (Retrieval Augmented Generation) refers to the portion of text or documents from which the model retrieves relevant information to generate an answer. It helps provide the necessary context for generating accurate and meaningful responses to questions. The size of the context window can vary depending on the specific implementation or LLM limitations.
LLMs have limits on the context window. As mentioned in the technical report, Gemma models have a context length of 8192 tokens. So there is no use in providing a context window of more than 8192 tokens. Chunking helps to maintain your context window limitation.
Note: Tokens are the basic units of data processed by LLMs. In the context of text, a token can be a word, part of a word (subword), or even a character — depending on the tokenization process.
Balancing context size
When utilizing Large Language Models (LLMs), it's crucial to consider the size of the context we feed into the model.
LLMs have a limit on the number of tokens they can handle at once. For instance, GPT-3.5-turbo has a token limit of 4096.
Moreover, as the context size increases, the quality of generated responses may decrease, leading to potential inaccuracies or hallucinations.
Handling larger contexts also translates to longer processing times and higher costs associated with LLM usage.
This underscores the importance of mastering the art of retrieval. Achieving the right balance between context chunking and embedding accuracy is key.
Hallucination
For example, in your JSON data, there is one document that contains data about 3 policies i.e. leave, work-from-home & pet policy. Now if you’re searching for “pet policy” or “work from home”, it is going to return the same document. Even, It will be the same for the “leave policy”. This practice may contain extra irrelevant information and with such context window, LLMs can hallucinate the result or the answer won’t be that accurate. Whereas if you split this one document into three documents (three different policies), It will pick an accurate chunk and use it as a context window.
How to chunk data?
There are different strategies for chunking the data-
- Fixed length chunking- Splitting a document into fixed size frames such as several characters, words, etc.
- Context-aware chunking- Logically and semantically splitting documents.
- NLP-driven chunking- Use NLP (Natural language Processing) to chunk the data more effectively. Breaking large bodies of text into manageable chunks allows us to summarize each section separately, resulting in a more precise overall summary.
You can come up with your own logic to chunk the data according to your requirements. In this example, we’re going to use Fixed length chunking. For this, we will be using LangChain’s CharacterTextSplitter(). This process will divide your data according to characters such as new line (\n), dot (.), comma (,), etc., and measure chunk length by a number of characters assigned to the chunk_size.
Here we are going to create the chunks for the content field.
3. Index documents
Assuming you have downloaded and deployed the ELSERv2 model. ELSER (Elastic Learned Sparse EncodeR) is a retrieval model developed by Elastic. It empowers users to conduct semantic search and enhance the search result relevance by considering contextual meaning and user intent instead of solely relying on exact keyword matches.
We'll utilize the ElasticsearchStore library for document indexing, which is an integral component of langChain's vector store functionality.
Let’s verify if the documents were inserted properly. Log in to Kibana and go to the menu ☰ > Management > Dev Tools. Hit the below query on the gemma-rag index.
Response
text- This field holds the chunked data.vectors.tokens- Contains all tokens generated by the ELSER model. A semantic search will be performed on this field.
4. Load Gemma model locally using Hugging Face
Why Hugging Face?
Hugging Face is the collaboration platform where we can host and collaborate on unlimited free and open models. You can find different kinds of open models, datasets and demo apps. All are publicly available and open source. You can run all the models locally on your machine using Hugging Face.
Gemma is a state-of-the-art and open model which is hosted on Hugging Face. You can simply run this on your local machine.
Hugging Face login
To get started with Gemma, you need to pass the Hugging Face access token while executing notebook_login().

Enter the Hugging Face access token and click on the Login button.
Initialize the tokenizer with the model (google/gemma-2b-it)
AutoTokenizer is used to convert user input into a stream of tokens which can be processed by the Gemma models.
Usage
- GPU usage: To run the model on GPU, pass the
device_map="auto"parameter in thefrom_pretrainedmethod.
- CPU Usage: The model will run on the CPU by simply removing the parameter
device_map.
You can explore more usage and optimization methods and use them according to your requirements.
Create a
Here we’re going to use the transformer’s pipeline. It is the abstraction layer of all other pipelines and provides an easy way to use models for inference.
text-generation: It will return TextGenerationPipeline. This pipeline predicts the words that will follow a specified text prompt.model&tokenizer: Pass the model & tokeninzer which we initialize in the previous step.max_new_tokens: The maximum number of tokens to generate, ignoring the number of tokens in the prompt.device="cuda": This will use CUDA to perform all computations on GPUs.
5. Create a chain using a prompt template
Now we are going to perform a semantic search using retrievers. It is going to use the ELSERv2 model to perform the search.
Here "k": 5 shows the maximum number of documents should be returned. All the documents will pass to the format_docs method to concat as a single context window.
We’re going to use a static template where context and question will be the placeholder. Both will get replaced on-the-fly based on the question we’re asking. You can use your own prompts or template.
6. Ask a question

Conclusion
In this blog, we've explored how to integrate Gemma into a RAG system using Elasticsearch for semantic search and document retrieval. Gemma models come with more tuning options. Because of their relatively small size, it is possible to deploy them in any environment like laptops, desktops, private servers etc. By following the outlined steps and utilizing the LangChain framework with Python, developers can seamlessly integrate Gemma into their projects and unlock its full potential for generation tasks. Alternatively, you can write the entire flow (RAG) without relying on LangChain by choosing another language. The complete Python notebook showcasing all the above implementations can be found on the elasticsearch-labs repository.
Related Content

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

July 6, 2026
Who grades the grader? LLM-as-a-Judge inside Elasticsearch Workflows
Find out if your RAG agent is ready to ship. Score it on correctness, faithfulness and retrieval quality using only Elasticsearch Workflows and two Claude models.

June 15, 2026
Your search index is already an agent memory system: Persistent agent memory for Claude Code with Elasticsearch
Give your AI agent persistent cross-session memory using Elasticsearch: Hybrid recall, a knowledge graph, and cross-device handoffs. Three commands to install.

June 15, 2026
Your FAQ bot doesn't need a PhD: LLM query routing with Elastic Workflows
Route LLM queries by complexity using Elasticsearch search metadata: Mistral Small for FAQ questions, Claude Sonnet for multi-source synthesis.