Acceso a modelos de machine learning en Elastic


 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
Elastic brinda soporte a los modelos de machine learning que necesitas
Elastic® te permite aplicar el machine learning (ML) adecuado para tu caso de uso y nivel de experiencia con ML. Tienes varias opciones:
- Aprovecha los modelos que vienen integrados. Además de modelos dirigidos a amenazas de seguridad específicas y tipos de problemas de sistemas en nuestra solución de observabilidad y seguridad, puedes usar nuestro modelo de Elastic Learned Sparse Encoder propio listo para usar y también una identificación de idioma, útil si trabajas con datos de texto en un idioma distinto al inglés.
- Accede a modelos de PyTorch de terceros desde cualquier lugar, incluido el centro de modelos HuggingFace.
- Carga un modelo que hayas entrenado tú mismo; principalmente transformadores de NLP en este punto.
Usar modelos integrados te brinda valor desde el inicio: sin necesidad de contar con experiencia en ML, obtienes la flexibilidad de probar diferentes modelos y determinar cuál tiene mejor rendimiento con tus datos.
Diseñamos nuestra gestión de modelos para que sea escalable en varios nodos de un cluster y para asegurar un buen rendimiento de inferencia para cargas de trabajo de alto rendimiento y de baja latencia. Eso se logra, en parte, potenciando los pipelines de ingesta para ejecutar la inferencia y usando nodos dedicados para la inferencia de modelos con alta demanda informática; durante la fase de ingesta, la búsqueda y el análisis de datos.
Continúa leyendo para obtener más información sobre la biblioteca Eland que te permite cargar modelos en Elastic y el rol que esto cumple para los varios tipos de machine learning que puedes usar en Elasticsearch®; desde los modelos más recientes de transformadores y procesamiento de lenguaje natural (NLP) hasta modelos de árbol mejorados para regresión.
Eland te permite cargar modelos de ML en Elastic
Nuestra biblioteca Eland brinda una interfaz sencilla para cargar modelos de ML en Elasticsearch; siempre y cuando se hayan entrenado con PyTorch. Al usar la biblioteca nativa libtorch y esperar modelos que se exportaron o guardaron como una representación de TorchScript, Elasticsearch evita ejecutar un intérprete de Python mientras realiza la inferencia de modelos.
Al integrarse a uno de los formatos más populares para crear modelos NLP en PyTorch, Elasticsearch puede proporcionar una plataforma que funcione con una gran variedad de casos de uso y tareas de NLP. Veremos eso más en detalle en la sección sobre transformadores a continuación.
Tienes tres opciones para usar Eland para cargar un modelo: línea de comandos, Docker y desde adentro de tu propio código de Python. Docker es menos complejo porque no requiere una instalación local de Eland y todas sus dependencias. Una vez que tengas acceso a Eland, la muestra de código siguiente enseña cómo cargar un modelo de NER DistilBERT, como ejemplo:

Más abajo, haremos un recorrido por cada argumento de eland_import_hub_model. Y puedes emitir el mismo comando desde un contenedor Docker.
Una vez cargado, la interfaz de usuario de ML Model Management (Gestión de modelos de ML) de Kibana te permite gestionar los modelos en un cluster de Elasticsearch, incluidas cada vez más asignaciones para rendimiento adicional y modelos de detención/reanudación mientras se (re)configura el sistema.
¿Qué modelos tienen soporte?
Elastic brinda soporte a una variedad de modelos de transformadores, además de las bibliotecas de aprendizaje supervisadas más populares:
- Modelos de incrustación y NLP: todos los transformadores que se ajustan a la interfaz del modelo de BERT estándar y usan el algoritmo de tokenización WordPiece. Ve una lista completa de las arquitecturas de modelo con soporte.
- Aprendizaje supervisado: modelos entrenados de bibliotecas de scikit-learn, XGBoost y LightGBM para serializar y usar como modelo de interfaz en Elasticsearch. Nuestra documentación proporciona un ejemplo para entrenar un XGBoost para clasificar según los datos en Elastic. También puedes exportar e importar modelos supervisados entrenados en Elastic con nuestras analíticas de marco de datos.
- AI generativa: puedes usar la API proporcionada para el LLM para hacer búsquedas (potencialmente enriquecidas con contexto recuperado de Elastic) y procesar los resultados devueltos. Para ver más instrucciones, consulta este blog, que lleva a un repositorio de GitHub con código de ejemplo para comunicarse a través de la API de ChatGPT.
A continuación, proporcionamos más información para el tipo de modelo que más probablemente uses en el contexto de aplicaciones de búsqueda: transformadores de NLP.
Cómo aplicar transformadores y NLP en Elastic, con facilidad
Permítenos hacerte un recorrido por los pasos para cargar y usar un modelo de NLP, por ejemplo un modelo de NER popular de Hugging Face, y repasar los argumentos identificados en el fragmento de código siguiente.

- Especifica el identificador de Elastic Cloud. Como alternativa, usa --url.
- Proporciona detalles de autenticación para acceder a tu cluster. Puedes buscar métodos de autenticación disponibles.
- Especifica el identificador para el modelo en el centro de modelos de Hugging Face.
- Especifica el tipo de tarea de NLP. Los valores compatibles son fill_mask, ner, text_classification, text_embedding y zero_shot_classification.
Una vez que hayas cargado el modelo, luego tendrás que desplegarlo. Logras esto desde la pantalla Model Management (Gestión de modelos) de la pestaña Machine Learning en Kibana. Luego, por lo general, probarías el modelo para asegurarte de que funcione de manera adecuada.
Ahora estás listo para usar el modelo desplegado para inferencia. Por ejemplo, para extraer entidades con nombre, llamas al endpoint _infer en el modelo de NER cargado:
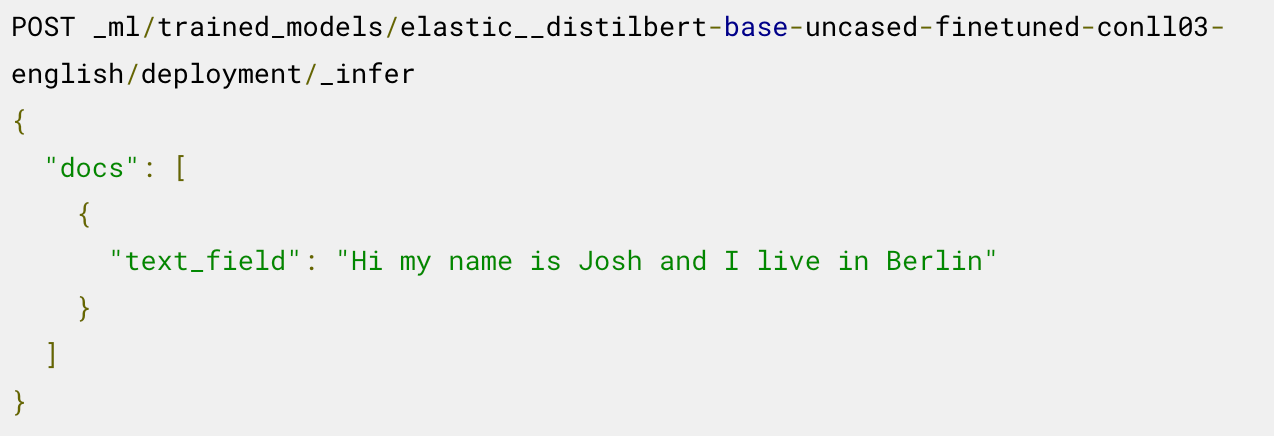
El modelo identifica dos entidades: la persona "Josh" y el lugar "Berlin".

Para ver pasos adicionales, como usar este modelo en un pipeline de inferencia y ajustar el despliegue, lee el blog que describe este ejemplo.
¿Quieres ver cómo aplicar la búsqueda semántica, por ejemplo, cómo crear incrustaciones para texto y luego aplicar la búsqueda de vectores para encontrar documentos relacionados? En este blog se explica eso paso a paso, incluso la validación del rendimiento del modelo.
¿Sabes qué tipo de tarea corresponde a qué modelo? Esta tabla te ayudará a empezar.
Modelo de Hugging Face | task-type |
|---|---|
ner | |
text_embedding | |
text_classification | |
zero_shot_classification | |
| Responder preguntas | question_answering |
Elastic también ofrece soporte para comparar la similitud de dos textos entre sí con el tipo de tarea text_similarity; esto es útil para clasificar el texto de los documentos al compararlo con otra entrada de texto proporcionada, y a veces se lo llama codificación cruzada.
Echa un vistazo a estos recursos para más detalles
- Soporte para transformadores de PyTorch, incluidas consideraciones de diseño para Eland
- Pasos para cargar transformadores en Elastic y usarlos en inferencia
- Blog en el que se describe cómo buscar en tus datos privados con ChatGPT
- Adaptar un transformador previamente entrenado a una tarea de clasificación de texto y cargar el modelo personalizado en Elastic
- Identificación de idioma integrada que te permite identificar texto en un idioma distinto al inglés antes de pasarlo a modelos que solo admiten inglés
Elastic, Elasticsearch y las marcas asociadas son marcas comerciales, logotipos o marcas comerciales registradas de Elasticsearch N.V. en los Estados Unidos y otros países. Todos los demás nombres de empresas y productos son marcas comerciales, logotipos o marcas comerciales registradas de sus respectivos propietarios.
El lanzamiento y la sincronización de cualquier característica o funcionalidad descrita en este blog quedan a la entera discreción de Elastic. Cualquier característica o funcionalidad que no esté disponible actualmente puede no entregarse a tiempo o no entregarse en absoluto.
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime

