Introducción al procesamiento de lenguaje natural con PyTorch en Elasticsearch

 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
Con el lanzamiento de la versión 8.0, Elastic se complace en presentar la capacidad de cargar modelos de machine learning de PyTorch en Elasticsearch para brindar procesamiento de lenguaje natural (NLP) moderno en el Elastic Stack. Ahora, los usuarios de Elasticsearch pueden integrar uno de los formatos más populares para crear modelos NLP e incorporarlos como parte de un pipeline de datos de NLP en Elasticsearch con nuestro procesador de inferencias. La capacidad de agregar modelos de PyTorch, junto con las API de búsqueda de ANN nuevas, agrega un nuevo vector a Elastic Enterprise Search.
¿Qué es NLP?
NLP se refiere a la forma en que podemos usar el software para manipular y comprender el texto oral o escrito, o lenguaje natural. En 2018, Google puso a disposición una nueva técnica open source para preentrenamiento en NLP llamada Bidirectional Encoder Representations from Transformers (representaciones de codificador bidireccional de transformadores) o BERT. BERT usa "aprendizaje por transferencia" mediante el entrenamiento a partir de sets de datos del tamaño de internet (por ejemplo, piensa en todo Wikipedia más los libros digitales) sin participación humana.
El aprendizaje por transferencia permite el preentrenamiento de un modelo BERT para que comprenda el lenguaje de uso general. Una vez que se preentrena un modelo una sola vez, luego puede volver a usarse y ajustarse para tareas más específicas a fin de comprender cómo se usa el lenguaje.
Para brindar soporte a modelos tipo BERT (modelos que usan el mismo tokenizador que BERT), Elasticsearch comenzará por dar soporte a la mayoría de las tareas de NLP más comunes con soporte para modelos de PyTorch. PyTorch es una de las bibliotecas de machine learning modernas más populares con una gran comunidad de usuarios activos, y es una biblioteca que brinda soporte a redes neuronales profundas, como la arquitectura Transformer que usa BERT.
Estos son algunos ejemplos de tareas de NLP:
- Análisis de sentimiento: clasificación binaria para identificar enunciados positivos vs. negativos
- Reconocimiento de entidades con nombre (NER): crear estructura a partir de texto no estructurado, intentar extraer detalles como nombre, ubicación u organización, por ejemplo
- Clasificación de texto: clasificación zero-shot (disparo cero) que te permite clasificar el texto según las clases que elijas sin preentrenamiento
- Incrustaciones de texto: se usa para búsqueda k vecino más cercano (kNN)

NLP en Elasticsearch
El propósito de integrar los modelos NLP en la plataforma de Elastic fue brindar una gran experiencia del usuario para cargar y gestionar modelos. Con el cliente de Eland para cargar modelos de PyTorch y la interfaz de usuario de ML > Model Management (Gestión de modelos) de Kibana para gestionar los modelos en un cluster de Elasticsearch, los usuarios pueden probar diferentes modelos y familiarizarse con el rendimiento con sus datos. También queríamos que fuera escalable en varios nodos disponibles en un cluster y proporcionar un buen rendimiento de los resultados de inferencia.
Para que todo esto fuera posible, necesitábamos una biblioteca de machine learning con la cual realizar la inferencia. Agregar soporte para PyTorch en Elasticsearch requirió del uso de la biblioteca nativa libtorch, que respalda PyTorch y solo brindará soporte a los modelos de PyTorch que se exportaron o guardaron como una representación de TorchScript. Esta es la representación de un modelo que libtorch necesita y permitirá que Elasticsearch evite ejecutar un intérprete de Python.
Al integrarse a uno de los formatos más populares para crear modelos NLP en modelos de PyTorch, Elasticsearch puede proporcionar una plataforma que funcione con una gran variedad de casos de uso y tareas de NLP. Hay disponible una variedad de bibliotecas excelentes para entrenar modelos NLP, por lo que dejaremos eso a otras herramientas por el momento. Ya sea que entrenes modelos con bibliotecas como PyTorch NLP, Hugging Face Transformers o fairseq de Facebook, podrás importar los modelos en Elasticsearch y realizar inferencia sobre esos modelos. La inferencia de Elasticsearch inicialmente será solo al momento de la ingesta, con la capacidad de expandirla en un futuro para introducir la inferencia también al momento de la búsqueda.
Hasta ahora ha habido métodos para integrar los modelos NLP a través de llamadas de API, plugins y otras opciones para transmitir datos hacia Elasticsearch y desde este. Pero con la integración de modelos NLP en tu pipeline de datos de Elasticsearch, obtendrás los siguientes beneficios:
- Crear una mejor infraestructura en torno a tus modelos NLP
- Escalar la inferencia de tu modelo de NLP
- Mantener la privacidad y seguridad de tus datos
Los modelos NLP pueden gestionarse de forma centralizada y coordinar, cargar y distribuir esos modelos.
Las llamadas de interferencia a los modelos de PyTorch pueden distribuirse alrededor del cluster y pueden permitir a los usuarios escalar conforme a la carga en el futuro. Se puede mejorar el rendimiento no moviendo los datos y optimizando las VM de Cloud para inferencia basada en CPU. Al incorporar modelos NLP en Elasticsearch, podemos mantener los datos en una red, en general, centralizada y segura que tiene en cuenta el cumplimiento y la privacidad de los datos. La infraestructura común, el rendimiento de búsqueda y la privacidad de los datos pueden mejorarse con la incorporación de modelos NLP en Elasticsearch.
Flujo de trabajo de implementación de un modelo de NLP de PyTorch
Existen algunos pasos sencillos para implementar un modelo de NLP con PyTorch. El primer paso es cargar los modelos en Elasticsearch. Un método para hacerlo es con las API REST que se pueden usar desde cualquier cliente de Elasticsearch, pero queríamos agregar herramientas incluso más sencillas que ayudaran en el proceso. En nuestro cliente de Eland, que es nuestra biblioteca de ciencia de datos de Python para el Elastic Stack, expondremos algunos métodos y scripts muy simples que te permiten cargar modelos desde el disco local o bajar modelos del centro de modelos Hugging Face, que es una de las formas más populares de compartir modelos entrenados. Para ambos enfoques, habrá herramientas que te ayudarán a convertir los modelos de PyTorch en sus representaciones de TorchScript y, por último, a cargar los modelos en un cluster.
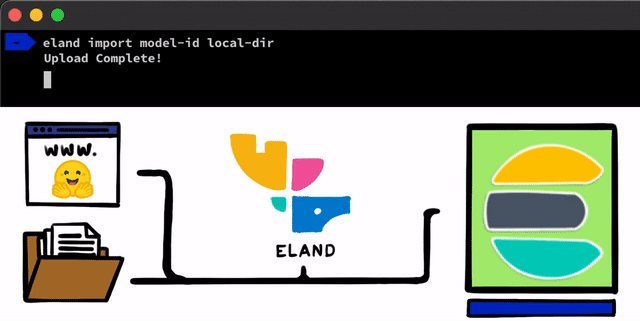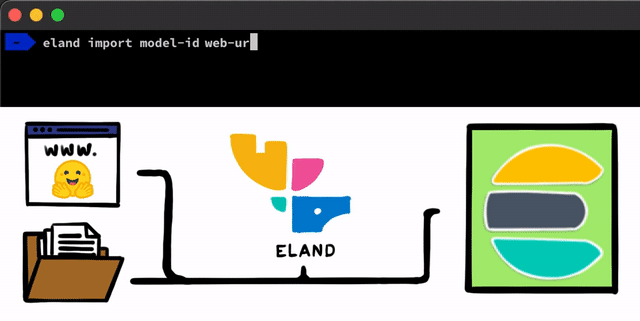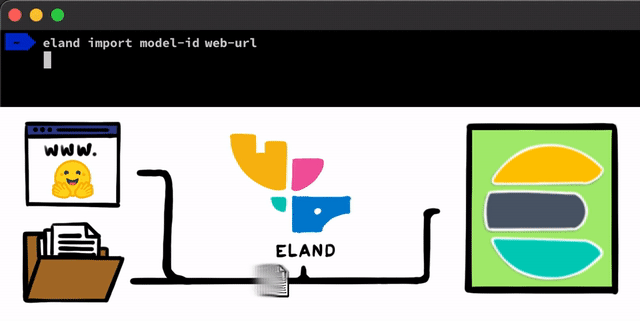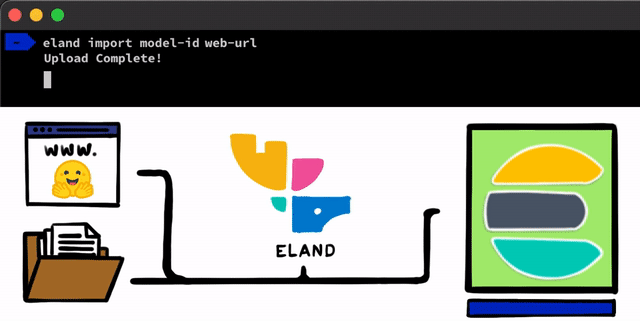
Una vez que los modelos de PyTorch estén cargados en el cluster, podrás asignar esos modelos a nodos de machine learning específicos. Este proceso los prepara para la inferencia cargando los modelos a la memoria e iniciando procesos libtorch nativos.
Por último, una vez finalizada la asignación de modelos, estaremos listos para la inferencia. Al momento de la ingesta habrá un procesador para inferencia, y puedes configurar cualquier tipo de pipeline de procesamiento de ingesta para preprocesar o posprocesar documentos antes o después de la inferencia. Por ejemplo, podemos tener una tarea de análisis de sentimiento en la que tomamos texto de un campo de un documento como entrada, devolvemos la etiqueta de clase positiva o negativa que se predijo para dicha entrada y agregamos esa predicción a un campo de salida en el documento. El documento nuevo resultante puede entonces seguir procesándose con otros procesadores de ingesta o indexarse como está.
Lo que se viene
Esperamos con ansias proporcionarte más ejemplos de modelos específicos y tareas de NLP en futuras actualizaciones del blog y próximos webinars. Si tienes un modelo que te gustaría probar en Elasticsearch, puedes comenzar hoy y comentarnos tu experiencia en nuestro foro de debate sobre machine learning o Slack de la comunidad. Para los casos de uso de producción, Elasticsearch requiere una licencia Platino o Enterprise para cargar modelos NLP y usar el procesador de inferencia, pero puedes probarlo hoy con una licencia de prueba gratuita. O puedes comenzar por crear un cluster de Elastic Cloud y usar nuestro cliente de Eland para cargar el modelo a tu cluster nuevo. Puedes comenzar una prueba gratuita de 14 días de Elastic Cloud ahora mismo.
Algo más… si te interesa saber más sobre los modelos NLP y cómo integrarlos en Elasticsearch, asiste a nuestro webinar Introducción a modelos NLP y búsqueda de vectores.
Enlaces relacionados adicionales:
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime