Cómo ingestar datos en Elasticsearch Service
Elasticsearch está siempre presente en la búsqueda de datos y las analíticas. Los desarrolladores y las comunidades aprovechan Elasticsearch para los casos de uso más diversos, desde búsqueda de aplicaciones y búsqueda de sitios web hasta logging, monitoreo de infraestructura, APM y Security Analytics. Si bien hoy en día existen soluciones disponibles de manera libre para estos casos de uso, los desarrolladores necesitan, en primer lugar, introducir sus datos en Elasticsearch.
Este artículo describe algunas de las formas más comunes de ingestar datos en Elasticsearch Service. Este puede ser un cluster hospedado en Elastic Cloud o en su variante en las dependencias, Elastic Cloud Enterprise. Mientras nos concentramos en estos servicios, la ingesta de datos en el cluster autogestionado de Elasticsearch se ve prácticamente igual. Lo único que cambia es cómo se aborda el cluster.
Antes de adentrarnos en detalles técnicos, si tienes alguna pregunta o problema mientras sigues este artículo, no dudes en dirigirte a discuss.elastic.co. Una comunidad animada podrá responder tus preguntas.
Ahora, preparémonos para adentrarnos en la ingesta de datos con los siguientes métodos:
- Elastic Beats
- Logstash
- Clientes de lenguaje
- Kibana Dev Tools
Ingesta de datos en Elasticsearch Service
Elasticsearch proporciona una API RESTful para la comunicación con las aplicaciones del cliente. Por lo tanto, las llamadas REST se usan para ingestar datos, realizar búsquedas y analíticas de datos, así como también administrar el cluster y sus índices. Internamente, todos los métodos descritos recurren a esta API para ingestar datos en Elasticsearch.
Para el resto de este artículo, suponemos que ya has creado tu cluster de Elasticsearch Service. Si aún no lo has hecho, regístrate en una prueba gratuita en Elastic Cloud. Una vez que hayas creado un cluster, recibirás una Cloud ID y una contraseña para la cuenta superusuario de elastic. La Cloud ID tiene el siguiente formato cluster_name:ZXVy...Q2Zg==. Codifica la URL de tu cluster y, como ya veremos, simplifica la ingesta de datos en él.
Elastic Beats
Elastic Beats es un conjunto de agentes de datos livianos que permite enviar datos de forma conveniente a Elasticsearch Service. Como son livianos, los Beats no generan sobrecarga de tiempo de ejecución y, por lo tanto, pueden ejecutarse y recopilar datos en dispositivos con recursos de hardware limitados, como dispositivos de IoT, dispositivos perimetrales o dispositivos integrados. Los Beats son la opción perfecta si necesitas recopilar datos y no cuentas con los recursos para ejecutar recolectores de datos que demanden gran cantidad de recursos. Este tipo de recolección de datos generalizada en todos nuestros dispositivos de la red te permitirá detectar rápidamente y reaccionar, por ejemplo, ante problemas que abarquen todo el sistema e incidentes relacionados con la seguridad.
Por supuesto que los Beats no se limitan a sistemas con poca cantidad de recursos. También pueden usarse en sistemas con más recursos de hardware disponibles.
El conjunto Beats: una visión general
Beats viene en diferentes sabores para recolectar diferentes tipos de datos:
- Filebeat te permite leer, procesar con anticipación y enviar datos desde fuentes que vienen en la forma de archivos. Aunque la mayoría de los usuarios usa Filebeat para leer archivos de log, soporta cualquier tipo de formato de archivo no binario. Además, Filebeat es compatible con una gran cantidad de fuentes de datos, incluyendo TCP/UDP, contenedores, Redis y Syslog. Una gran cantidad de módulos facilita la recolección y el análisis de los formatos de log para aplicaciones comunes, como Apache, MySQL y Kafka.
- Metricbeat recopila y preprocesa métricas de sistema y servicio. Las métricas del sistema incluyen información sobre la ejecución de procesos, así como también los números de uso del CPU, la memora, el disco y la red. Los módulos están disponibles para recopilar datos de diferentes servicios, incluyendo Kafka, Palo Alto Networks, Redis y muchos más.
- Packetbeat recopila y preprocesa datos de red en vivo. Esto habilita el monitoreo de la aplicación y las analíticas de rendimiento de seguridad y red. Packetbeat, entre otros, es compatible con los siguientes protocolos: DHCP, DNS, HTTP, MongoDB, NFS, y TLS.
- Winlogbeat captura logs de eventos desde los sistemas operativos de Windows, incluyendo eventos de aplicación, eventos de hardware y eventos de seguridad y sistema. La vasta información disponible a partir del log de eventos de Windows puede resultar de interés para muchos casos de uso.
- Auditbeat detecta cambios en archivos críticos y recopila eventos de Linux Audit Framework. Los diferentes módulos facilitan su implementación, que suelen usarse en los casos de uso de las analíticas de seguridad.
- Heartbeat usa el rastreo para controlar la disponibilidad de los sistemas y los servicios. Por lo tanto, Heartbeat es útil en una variedad de escenarios, como el monitoreo de infraestructura y las analíticas de seguridad. ICMP, TCP y HTTP son protocolos compatibles.
- Functionbeat recopila logs y métricas desde dentro de un ambiente sin servidor como AWS Lambda.
Una vez que has decidido cuál de los Beats usar en tu situación específica, comenzar es tan fácil como se describe en la próxima sección.
Primeros pasos con Beats
En esta sección, tomaremos Metricbeat como ejemplo de cómo comenzar con los Beats. Los pasos que debes seguir para otros Beats son muy similares. Consulta también la documentación y sigue los pasos para tu Beat específico y tu sistema operativo.
- Descarga e instala el Beat deseado. Existen diversas formas de instalar los Beats, pero la mayoría de los usuarios elige usar los repositorios provistos por Elastic para el administrador de paquetes del sistema operativo (DEB/RPM) o, simplemente, descargar y descomprimir el paquete tgz/zip.
- Configura el Beat y habilita los módulos deseados.
- Por ejemplo, para recolectar métricas sobre contenedores de Docker que se ejecuten en tu sistema, habilita el módulo Docker con
sudo metricbeat modules enable dockersi realizaste la instalación con el administrador de paquetes. Si, en cambio, descomprimiste el paquete tgz/zip, usa/metricbeat modules enable docker. - La Cloud ID es una forma conveniente de especificar el Elasticsearch Service al que se envían los datos recolectados. Agrega la Cloud ID y la información de autenticación al archivo de configuración de Metricbeat (metricbeat.yml):
cloud.id: cluster_name:ZXVy...Q2Zg==
cloud.auth: "elastic:YOUR_PASSWORD"
- Como se mencionó antes, se te proporcionó la
cloud.ida partir de la creación de tu cluster.cloud.authes una concatenación separada por comas de un nombre de usuario y una contraseña que poseen suficientes privilegios dentro del cluster de Elasticsearch. - Para comenzar rápidamente, usa el superusuario de Elastic y la contraseña que se te otorgó después de la creación del cluster. Puedes encontrar el archivo de configuración en el directorio
/etc/metricbeatsi instalaste con el administrador de paquetes, o en el directorio descomprimido si usaste el paquete tgz/zip.
- Carga en Kibana los dashboards incluidos. La mayoría de los Beats y sus módulos vienen con dashboards de Kibana predefinidos. Cárgalas en Kibana con
sudo metricbeat setupsi instalaste usando el administrador de paquetes, o con./metricbeat setupen el directorio descomprimido si usaste el paquete tgz/zip.
- Ejecuta el Beat. Usa
sudo systemctl start metricbeatsi instalaste usando el administrador de paquetes o un sistema de Linux basado en systemd, o usa./metricbeat -esi instalaste usando el paquete tgz/zip.
Si todo funciona como se espera, los datos comenzarán a moverse en tu Elasticsearch Service.
Explora estos dashboards incluidos
Dirígete a tu Kibana dentro de tu Elasticsearch Service para inspeccionar los datos:
- Dentro de Kibana Discover, selecciona el patrón de índice
metricbeat-*y podrás ver los documentos individuales que se han ingestado. - La pestaña Infraestructura de Kibana te permite inspeccionar tu sistema y las métricas de Docker de una forma más gráfica, con diferentes gráficos sobre el uso de recursos del sistema (CPU, memoria, red).
- Dentro de los dashboards de Kibana, selecciona cualquiera de los dashboards prefijados con [Metricbeat System] para explorar tus datos de una manera más interactiva.
Logstash
Logstash es una herramienta poderosa y flexible para leer, procesar y enviar datos de cualquier tipo. Logstash proporciona una variedad de capacidades que no están actualmente disponibles o son muy costosas para llevar a cabo con Beats, como enriquecer documentos con búsquedas comparadas con las fuentes de datos externas. Sin embargo, esta funcionalidad y flexibilidad de Logstash tiene un precio. Además, los requisitos de hardware para Logstash son significativamente mayores que para Beats. Como tal, Logstash no debería implementarse en dispositivos de bajos recursos. Logstash, por lo tanto, se usa como alternativa a Beats, si la funcionalidad de este último no fuese suficiente para un caso de uso específico.
Un patrón de arquitectura común consiste en combinar Beats y Logstash: usar Beats para recolectar datos y usar Logstash para realizar el procesamiento de los datos que Beats no pueda hacer.
Visión general de Logstash
Logstash funciona ejecutando pipelines de procesamiento de eventos, en donde cada pipeline consiste en, al menos, uno de cada uno de los siguientes:
- Las entradas (inputs) leen a partir de fuentes de datos. Muchas fuentes de datos son compatibles de manera oficial, incluso archivos, http, imap, jdbc, kafka, syslog, tcp y udp.
- Los filtros (filters) procesan y enriquecen los datos de diferentes maneras. En muchos casos, las líneas de log sin estructura necesitan, en primer lugar, ser parseadas en un formato más estructurado. Por lo tanto, Logstash proporciona, entre otras cosas, filtros para parsear CSV, JSON, pares de clave/valor, datos no estructurados delimitados y datos no estructurados complejos sobre la base de expresiones regulares (filtros grok). Además, Logstash proporciona filtros para enriquecer datos realizando búsquedas de DNS, agregando información geográfica sobre direcciones IP o realizando búsquedas comparadas con un diccionario personalizado o un índice de Elasticsearch. Los filtros adicionales permiten diversas transformaciones de los datos, por ejemplo, para renombrar, eliminar, copiar campos de datos y valores (filtro mutate).
- Las salidas (outputs) escriben los datos parseados y enriquecidos en la pila de datos, y son la etapa final de la pipeline de procesamiento de Logstash. Si bien existen muchos plugins de salida disponibles, aquí nos concentraremos en la ingesta en Elasticsearch Service usando la salida de elasticsearch.
Pipeline de muestra de Logstash
No hay dos casos de uso iguales. Por lo tanto, es probable que tengas que desarrollar las pipelines de Logstash que se adapten a tu entrada de datos y a tus requisitos específicos.
Presentamos una pipeline de Logstash de muestra que
- lee la fuente de RSS de los blogs de Elastic,
- realiza un procesamiento leve de los datos copiando o renombrando campos, y eliminando caracteres especiales y etiquetas HTML,
- ingesta los documentos en Elasticsearch.
Los pasos son los siguientes:
- Instala Logstash mediante tu administrador de paquetes o descargando y descomprimiendo el archivo tgz/zip.
- Instala el rss input plugin de Logstash, que permite leer las fuentes de datos RSS:
./bin/logstash-plugin install logstash-input-rss - Copia la siguiente definición de pipeline de Logstash en un nuevo archivo, como ~/elastic-rss.conf:
input {
rss {
url => "/blog/feed"
interval => 120
}
}
filter {
mutate {
rename => [ "message", "blog_html" ]
copy => { "blog_html" => "blog_text" }
copy => { "published" => "@timestamp" }
}
mutate {
gsub => [
"blog_text", "<.*?>", "",
"blog_text", "[\n\t]", " "
]
remove_field => [ "published", "author" ]
}
}
output {
stdout {
codec => dots
}
elasticsearch {
hosts => [ "https://<your-elsaticsearch-url>" ]
index => "elastic_blog"
user => "elastic"
password => "<your-elasticsearch-password>"
}
}
- Dentro del archivo anterior, modifica los hosts y la contraseña de los parámetros para que coincidan con el punto final de Elasticsearch Service y tu contraseña para el usuario elastic. En la Elastic Cloud, podrás obtener la URL del punto final de Elasticsearch en los detalles de tu página de despliegue (Copiar la URL del punto final).
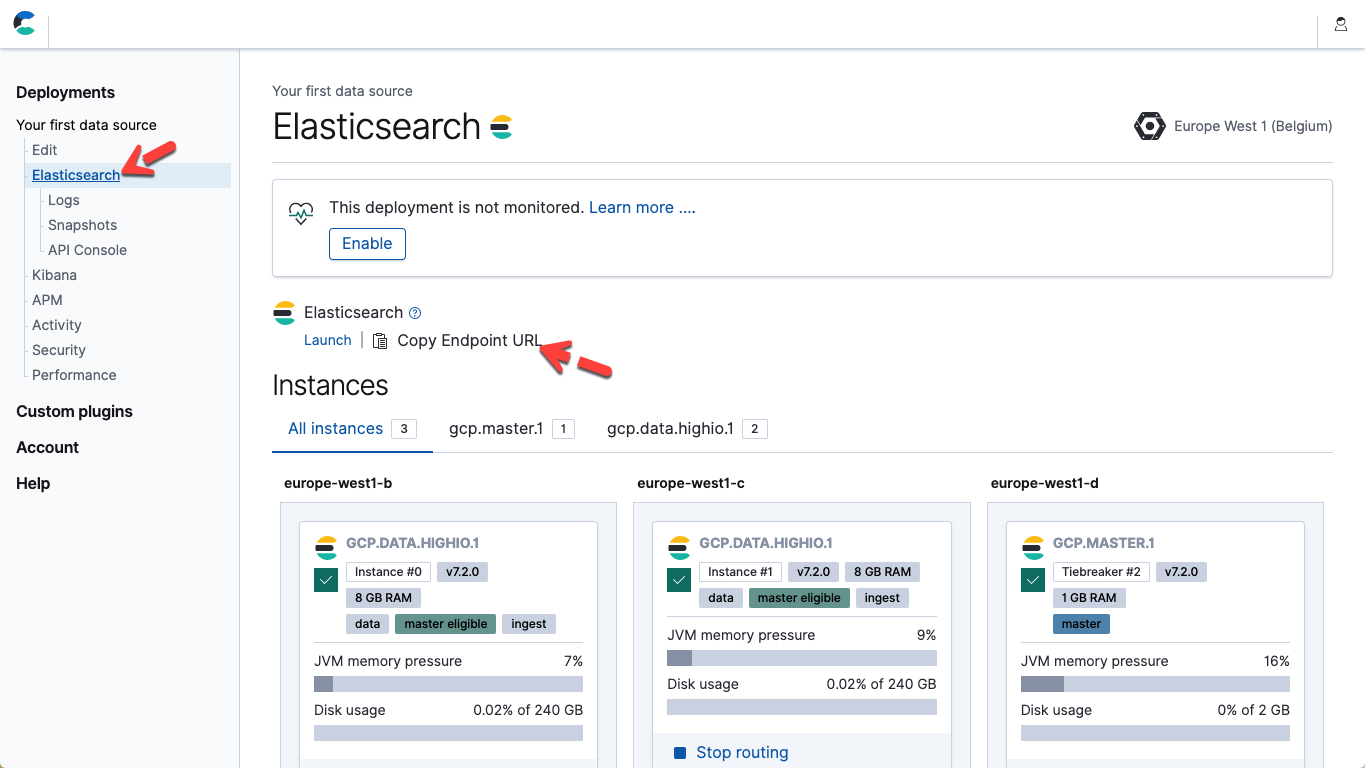
- Ejecuta la pipeline iniciando Logstash: ./bin/logstash -f ~/elastic-rss.conf
Iniciar Logstash tomará algunos segundos. Comenzarás a ver que se imprimen puntos (.....) en la consola. Cada punto representa un documento que se ha ingestado en Elasticsearch.
- Abre Kibana. Dentro de la Consola Kibana Dev Tools, ejecuta lo siguiente para confirmar que se han ingestado 20 documentos: POST elastic_blog/_search
Clientes de lenguaje
En algunas situaciones, es preferible integrar la ingesta de datos con tu código de aplicación personalizado. Para esto, recomendamos usar uno de los clientes Elasticsearch con soporte oficial. Estos clientes son librerías que generan abstracciones de detalles de bajo nivel de la ingesta de datos y te permiten concentrarte en el trabajo real específico para tu aplicación. Existen clientes oficiales para Java, JavaScript, Go, .NET, PHP, Perl, Python y Ruby. Consulta la documentación del lenguaje que elijas para conocer todos los detalles y los ejemplos de código. Si tu aplicación está escrita en un lenguaje que no se enumeró antes, es probable que exista un cliente de contribución de la comunidad.Kibana Dev Tools
Nuestra herramienta de elección recomendada para desarrollar y depurar las solicitudes de Elasticsearch es la Consola Kibana Dev Tools. Dev Tools expone todo el poder y la flexibilidad de la API REST de Elasticsearch genérica, al mismo tiempo que abstrae la parte técnica de las solicitudes HTTP subyacentes. No nos sorprende que puedas usar la Consola Dev Tools para ingresar en Elasticsearch documentos JSON sin procesar:PUT my_first_index/_doc/1
{
"title" : "How to Ingest Into Elasticsearch Service",
"date" : "2019-08-15T14:12:12",
"description" : "This is an overview article about the various ways to ingest into Elasticsearch Service"
}