Introducción práctica a Logstash
El Elastic Stack trata de facilitar lo más posible la ingesta de datos hacia Elasticsearch. Filebeat es una excelente herramienta para ver las últimas líneas de archivos y viene con un grupo de módulos que permiten ingerir una gran variedad de formatos comunes de registro con mínima configuración. Si los datos que deseas ingerir no están cubiertos por estos módulos, los nodos de ingesta de de Elasticsearch y Logstash proporcionan un medio poderoso y flexible para analizar y procesar la mayoría de los tipos de datos basados en texto.
En este blog, brindaremos una introducción breve a Logstash y mostraremos cómo trabajar con este motor al desarrollar una configuración para analizar algunos registros de acceso de caché de Squid de muestra e ingerirlos en Elasticsearch.
Un breve resumen de Logstash
Logstash es un motor de procesamiento y recopilación de datos basado en plugins. Incluye una gran variedad de plugins que permiten configurarlo fácilmente para recopilar, procesar y reenviar datos en muchas arquitecturas diferentes.
El procesamiento se organiza en uno o más pipelines. En cada pipeline, uno o más plugins de entrada reciben o recopilan datos que luego se colocan en una cola interna. De manera predeterminada, esta es pequeña y se almacena en la memoria, pero puede configurarse para ser más amplia y permanecer en el disco para mejorar la confiabilidad y la persistencia.
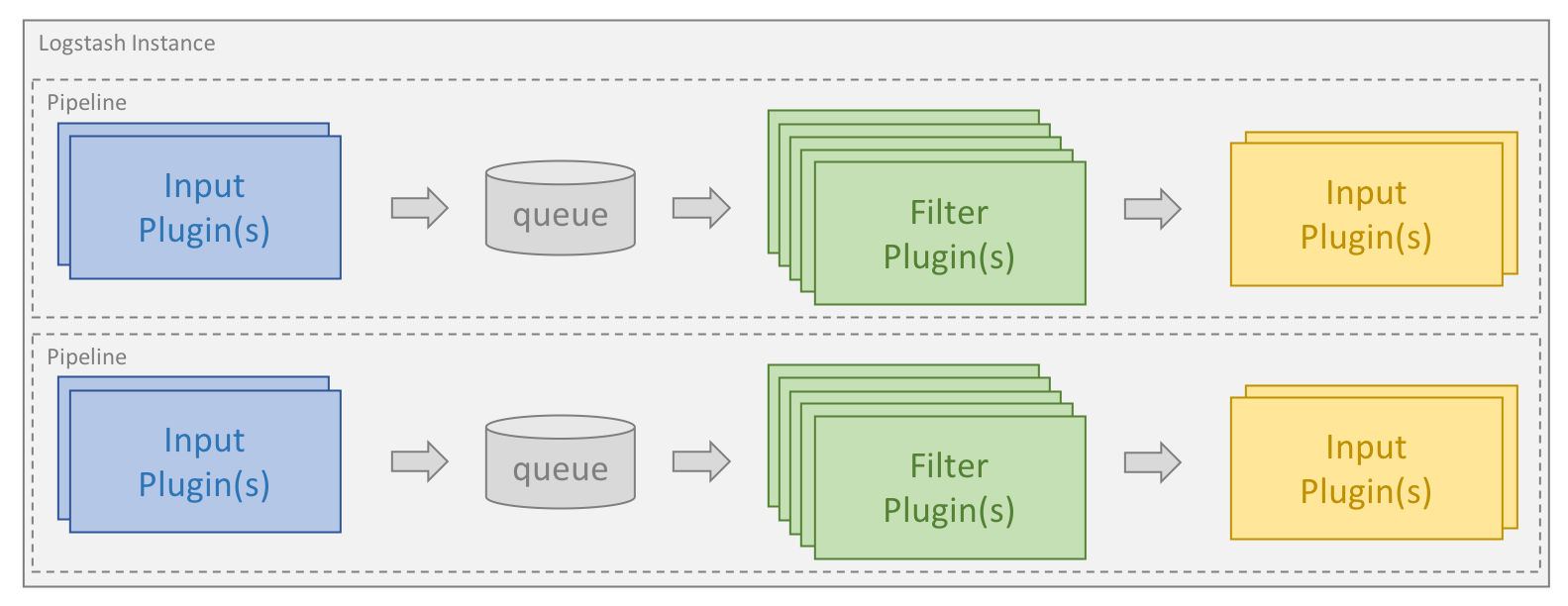
Los hilos de procesamiento leen datos de la cola y los procesan a través de cualquier plugin de filtro configurado en secuencia. Logstash viene de fábrica con una gran cantidad de plugins destinados a tipos específicos de procesamiento, y así es como se analizan, procesan y enriquecen los datos.
Una vez que se procesan los datos, los hilos de procesamiento envían los datos a los plugins de salida correspondientes, que son los responsables de formatear y enviar los datos hacia adelante, por. ej., a Elasticsearch.
Los plugins de entrada y salida también pueden tener un plugin de códec configurado. Esto permite formatear datos antes de colocarlos en la cola interna o antes de enviarlos a un plugin de salida.
Instalación de Logstash y Elasticsearch
Para ejecutar los ejemplos en este blog, primero debes instalar Logstash y Elasticsearch. Sigue los vínculos para obtener instrucciones sobre cómo instalarlos en tu sistema operativo. Usaremos la versión 6.2.4 de Elastic Stack.
Cómo especificar los pipelines
Los pipelines de Logstash se crean sobre la base de uno o más archivos de configuración. Antes de empezar, te explicaremos rápidamente las diferentes opciones disponibles. Los directorios que se describen en esta sección pueden variar según el modo de instalación y el sistema operativo, y se definen en la documentación.
Pipeline único usando un solo archivo de configuración
La manera más fácil de arrancar Logstash, y la manera que usaremos en este blog, es hacer que Logstash cree un solo pipeline basado en un solo archivo de configuración que especificamos a través del parámetro de línea de comandos -f.
Pipeline único mediante varios archivos de configuración
Logstash también puede configurarse para usar todos los archivos en un directorio específico como archivos de configuración. Esto puede establecerse a través del archivo logstash.yml o transmitiendo una ruta de directorio a través de la línea de comandos usando el parámetro de línea de comandos -f. Esta es la opción predeterminada si instalas Logstash como servicio.
Cuando se proporciona un directorio, todos los archivos en dicho directorio estarán concatenados en orden lexicográfico y luego se analizarán como un solo archivo de configuración. Por lo tanto, los datos de todas las entradas se procesarán a través de todos los filtros y se enviarán a todas las salidas a menos que controles el flujo a través de condicionales.
Uso de varios pipelines
Para usar varios pipelines dentro de Logstash, debes editar los archivos pipelines.yml que vienen con Logstash. Encontrarás estos archivos en el directorio de configuración, que contiene archivos de configuración y parámetros de configuración para todos los pipelines que admite esa instancia de Logstash.
El uso de varios pipelines te permite separar diferentes flujos lógicos, lo cual puede reducir significativamente la complejidad y la cantidad de condicionales usados. Esto facilita el ajuste y el mantenimiento de la configuración. A medida que los datos que circulan a través de un pipeline al mismo tiempo se vuelven más homogéneos, esto también puede generar importantes beneficios de rendimiento dado que los plugins de salida pueden usarse de manera más eficiente.
Cómo crear una primera configuración
Cualquier configuración de Logstash debe contener al menos un plugin de entrada y un plugin de salida. Los filtros son opcionales. Como primer ejemplo de cómo puede ser un archivo de configuración simple, empezaremos con uno que lee una serie de datos de prueba de un archivo y lo envía como salida a la consola en una forma estructurada. Esta es una configuración muy útil al desarrollar una configuración, ya que te permite iterar rápidamente y construir la configuración. En este blog, supondremos que nuestro archivo de configuración se llama test.conf y que está guardado en el directorio “/home/logstash” junto con el archivo que contiene nuestros datos de prueba:
input {
file {
path => ["/home/logstash/testdata.log"]
sincedb_path => "/dev/null"
start_position => "beginning"
}
}
filter {
}
output {
stdout {
codec => rubydebug
}
}
Aquí vemos los tres grupos de nivel principal que forman parte de toda configuración de Logstash: input (entrada), filter (filtro) y output (salida). En la sección de entrada, especificamos un file input plugin (plugin de entrada de archivo) e ingresamos la ruta de nuestro archivo de datos de prueba a través de la directiva path (ruta). Establecimos la directivastart_position (posición de inicio) en “beginning” (inicio) para ordenar al plugin que lea el archivo desde el principio cada vez que se descubra un nuevo archivo.
Para hacer un seguimiento de los datos dentro de cada archivo de entrada que se procesó, el plugin de entrada de archivo de Logstash usa un archivo llamado sincedb para registrar la posición actual. Ya que nuestra configuración se usa para el desarrollo, queremos que el archivo se relea varias veces, y por lo tanto, es conveniente deshabilitar el uso del archivo sincedb. Para esto, configuramos la directiva sincedb_path en “/dev/null” en los sistemas basados en Linux. En Windows, esto se establece en “nul”.
Si bien el plugin de entrada de archivo de Logstash es una excelente manera para comenzar a desarrollar configuraciones, Filebeat es el producto recomendado para la recopilación y el envío de registros desde servidores host. Filebeat puede enviar registros a Logstash y Logstash puede recibir y procesar estos registros con la entrada de Beats. La lógica de análisis descrita en este blog aún se aplica en cualquiera de las situaciones, pero Filebeat tiene un rendimiento más optimizado y requiere un menor uso de recursos, lo cual es ideal para ejecutar como agente.
El plugin de salida stdout escribe los datos en la consola y el códec rubydebug ayuda a mostrar la estructura, lo cual simplifica la depuración durante el desarrollo de la configuración.
Inicio de Logstash
Para verificar que Logstash y nuestro archivo de configuración funcionan, creamos un archivo llamado “testdata.log” en el directorio “/home/logstash”. Este contiene la cadena “Hello Logstash!” seguida por una nueva línea.
Suponiendo que tenemos el binario logstash en nuestra ruta, podemos arrancar Logstash con el siguiente comando:
logstash -r -f "/home/logstash/test.conf"
Además del parámetro de línea de comandos -f que analizamos antes, también usamos la marca-r. Esto le indica a Logstash que vuelva a cargar automáticamente la configuración cada vez que identifique que la configuración cambió. Esto es muy útil, especialmente durante el desarrollo. Dado que deshabilitamos el archivo sincedb, el archivo de entrada volverá a leerse cada vez que se vuelva a cargar la configuración, lo cual nos permite probar rápidamente la configuración mientras continuamos desarrollándola.
La salida por consola de Logstash muestra algunos registros relacionados con el inicio. Después de esto se procesará el archivo y verás algo como lo siguiente:
{
"message" => "Hello Logstash!",
"@version" => "1",
"path" => "/home/logstash/testdata.log",
"@timestamp" => 2018-04-24T12:40:09.105Z,
"host" => "localhost"
}
Este es el evento que procesó Logstash. Puedes ver que los datos se guardan en el campo de mensaje y que Logstash agregó algunos metadatos para el evento en forma de la marca de tiempo que se procesó y donde se originó.
Todo esto está muy bien y demuestra que la mecánica funciona. Ahora agregaremos algunos datos de prueba más reales y mostraremos cómo pueden analizarse.
¿Cómo analizo mis logs?
A veces hay un filtro perfecto que puede usarse para analizar los datos, p. ej., el filtro json en caso de que tus registros estén en formato JSON. Sin embargo, muchas veces necesitamos analizar registros en diferentes tipos de formatos de texto. El ejemplo que usaremos en este blog son algunas líneas de registros de acceso de caché de Squid como las siguientes:
1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 - 1524206424.145 106 207.96.0.0 TCP_HIT/200 68247 GET http://elastic.co/guide/en/logstash/current/images/logstash.gif - NONE/- image/gif
Cada línea contiene información acerca de una petición al caché de Squid y puede desglosarse en una serie de campos diferentes que necesitamos analizar.

Al analizar registros de texto, hay especialmente dos filtros que se utilizan con más frecuencia: dissect analiza registros de acuerdo con delimitadores, mientras que grok funciona de acuerdo con la coincidencia de expresiones regulares.
El filtro dissect funciona muy bien cuando la estructura de los datos está bien definida y puede ser muy rápido y eficiente. Además, por lo general es más fácil para arrancar, especialmente para usuarios que no conocen las expresiones regulares.
Grok es generalmente más potente y puede manejar una mayor variedad de datos. Sin embargo, la coincidencia de expresiones regulares puede usar más recursos y ser más lenta, en especial si no se optimiza en forma correcta.
Antes de continuar con el análisis, reemplazamos el contenido del archivo testdata.log por estas dos líneas de registro y nos aseguramos de que cada línea esté seguida por una nueva línea.
Análisis de registros con dissect
Al trabajar con el filtro dissect, especificas una secuencia de campos para extraer además de los delimitadores entre estos campos. El filtro realiza una sola pasada sobre los datos y busca coincidencias entre los delimitadores en el patrón. Al mismo tiempo, los datos entre los delimitadores se asignan a los campos especificados. El filtro no valida el formato de los datos extraídos.
Los separadores que se usan al analizar estos datos mediante el filtro dissect se resaltan en rosa a continuación.

El primer campo contiene la marca de tiempo y está seguido por uno o más espacios, según la longitud del siguiente campo de duración. Podemos especificar el campo de marca de tiempo como %{timestamp}, pero para que acepte un número variable de espacios como separador, debemos agregar un sufijo -> al campo. Todos los demás separadores en la entrada del registro consisten en solo un caracter. Por lo tanto, podemos comenzar a construir el patrón, lo que da como resultado la siguiente sección de filtro:
{
"@version" => "1",
"message" => "1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"@timestamp" => 2018-04-24T12:42:23.003Z,
"path" => "/home/logstash/testdata.log",
"host" => "localhost",
"duration" => "19395",
"timestamp" => "1524206424.034",
"rest" => "TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"client_ip" => "207.96.0.0"
}
Ahora podemos seguir construyendo el patrón paso a paso. Una vez que hemos analizado correctamente todos los campos, podemos eliminar el campo de mensaje para no mantener los mismos datos dos veces. Para esto, podemos usar la directiva remove_field, que solo se ejecuta si el análisis fue exitoso, lo que resulta en el siguiente bloque de filtro.
filter {
dissect {
mapping => {
"message" => "%{timestamp->} %{duration} %{client_address} %{cache_result}/%{status_code} %{bytes} %{request_method} %{url} %{user} %{hierarchy_code}/%{server} %{content_type}"
}
remove_field => ["message"]
}
}
Cuando se ejecuta con los datos de muestra, el primer registro es como el siguiente:
{
"user" => "-",
"content_type" => "-",
"host" => "localhost",
"cache_result" => "TCP_MISS",
"@timestamp" => 2018-04-24T12:43:07.406Z,
"duration" => "19395",
"request_method" => "GET",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"timestamp" => "1524206424.034",
"status_code" => "304",
"server" => "10.0.5.120",
"@version" => "1",
"client_address" => "207.96.0.0",
"bytes" => "15363",
"path" => "/home/logstash/testdata.log",
"hierarchy_code" => "DIRECT"
}
La documentación contiene algunos buenos ejemplos, y este de blog es un buen debate sobre el diseño y el propósito del filtro.
Eso fue muy fácil, ¿no? Procesaremos esto en profundidad un poco más adelante, pero primero veamos cómo podemos hacer lo mismo con grok.
¿Cuál es la mejor forma de trabajar con grok?
Grok usa patrones de expresiones regulares para hacer coincidir campos y delimitadores. La siguiente figura muestra los campos que deben capturarse en azul y los delimitadores en rojo.

Grok comenzará a buscar coincidencias entre los patrones configurados desde el principio y continuará hasta mapear todo el evento o hasta determinar que no se puede encontrar una coincidencia. Según el tipo de patrones utilizados, esto puede requerir que grok procese parte de los datos varias veces.
Grok viene con una gran variedad de patrones listos para usar. Algunos de los más genéricos pueden encontrarse aquí, pero este repositorio también contiene una gran cantidad de patrones muy especializados para tipos comunes de datos. En realidad hay uno para analizar registros de acceso de Squid, pero en lugar de simplemente usar esto en forma directa, en este tutorial mostraremos cómo construirlo de cero. Sin embargo, muestra que tal vez convenga consultar en este repositorio si ya existe algún patrón apropiado, antes de embarcarse en la creación de un patrón personalizado.
Al crear una configuración grok, hay una serie de patrones estándar que se usan comúnmente:
- WORD: (palabra) patrón que hace coincidir una sola palabra.
- NUMBER: (número) patrón que hace coincidir un entero positivo o negativo o un número de punto flotante.
- POSINT: patrón que hace coincidir un entero positivo.
- IP: patrón que hace coincidir una dirección IP IPv4 o IPv6.
- NOTSPACE: patrón que hace coincidir cualquier cosa que no sea un espacio.
- SPACE: patrón que hace coincidir cualquier cantidad de espacios consecutivos.
- DATA: patrón que hace coincidir una cantidad limitada de cualquier tipo de datos.
- GREEDYDATA: patrón que hace coincidir todos los datos restantes.
Estos son los patrones que usaremos al construir nuestra configuración del filtro grok. La manera de crear configuraciones de grok es, por lo general, empezar desde la izquierda y construir gradualmente el patrón, capturando el resto de los datos con un patrón GREEDYDATA. Podemos empezar usando el siguiente patrón y bloque de filtro:
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp}%{SPACE}%{GREEDYDATA:rest}"
}
}
}
Este patrón le indica a grok que busque un número al comienzo de la cadena y lo guarde en un campo llamado timestamp (marca de tiempo). Después de eso, hace coincidir una serie de espacios antes de guardar el resto de los datos en un campo llamado rest (descanso). Cuando cambiamos el bloque de filtro dissect para este, el primer registro sale de la siguiente manera:
{
"timestamp" => "1524206424.034",
"rest" => "19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"path" => "/home/logstash/testdata.log",
"message" => "1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"@timestamp" => 2018-04-24T12:45:11.026Z,
"@version" => "1",
"host" => "localhost"
}
Uso de Grok Debugger
Si bien podemos desarrollar todo el patrón de esta manera, hay una herramienta en Kibana que puede ayudar a simplificar la creación del patrón de grok: Grok Debugger. En el siguiente video, mostramos cómo podemos usar esta herramienta para construir los patrones para los registros de ejemplo que usamos en este blog.
Una vez realizada la configuración, podemos anular el campo de mensaje cuando el análisis se realiza correctamente, lo cual hará que el bloque de filtro se vea así:
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp}%{SPACE}%{NUMBER:duration}\s%{IP:client_address}\s%{WORD:cache_result}/%{POSINT:status_code}\s%{NUMBER:bytes}\s%{WORD:request_method}\s%{NOTSPACE:url}\s%{NOTSPACE:user}\s%{WORD:hierarchy_code}/%{NOTSPACE:server}\s%{NOTSPACE:content_type}"
}
remove_field => ["message"]
}
}
Esto es similar al patrón ready-made (listo para usar), pero no idéntico. Cuando se ejecuta con los datos de muestra, el primer registro se analiza de la misma manera que cuando usamos el filtro dissect:
{
"request_method" => "GET",
"cache_result" => "TCP_MISS",
"@timestamp" => 2018-04-24T12:48:15.123Z,
"timestamp" => "1524206424.034",
"user" => "-",
"bytes" => "15363",
"path" => "/home/logstash/testdata.log",
"hierarchy_code" => "DIRECT",
"duration" => "19395",
"client_address" => "207.96.0.0",
"@version" => "1",
"status_code" => "304",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"content_type" => "-",
"host" => "localhost",
"server" => "10.0.5.120"
}
Ajuste de rendimiento de grok
Grok es una herramienta muy potente y flexible para analizar datos, pero el uso ineficiente de los patrones puede generar un rendimiento más bajo de lo esperado. Por lo tanto, te recomendamos que leas este blog sobre el ajuste de rendimiento de grok antes de empezar a usar grok en serio.
Asegurar que los campos sean del tipo correcto
Como viste en los ejemplos anteriores, todos los campos se analizaron como campo de cadena. Antes de enviar esto a Elasticsearch en forma de documentos JSON, debemos cambiar los campos bytes, duration (duración) y status_code (código de estado) por enteros y timestamp (marca de tiempo) por un flotante.
Una manera de hacer esto sería usar un mutate filter (filtro mutate) y su opción convert (convertir).
mutate <span class="pun">{</span><span class="pln">
convert </span><span class="pun">=></span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"bytes"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"integer"</span><span class="pln">
</span><span class="str">"duration"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"integer"</span><span class="pln">
</span><span class="str">"status_code"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"integer"</span><span class="pln">
</span><span class="str">"timestamp"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"float"</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span>
También podemos hacer esto directamente en los filtros dissect y grok. En el filtro dissect, haremos esto a través de la directiva convert_datatype (convertir tipos de datos).
filter <span class="pun">{</span><span class="pln">
dissect </span><span class="pun">{</span><span class="pln">
mapping </span><span class="pun">=></span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"message"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"%{timestamp->} %{duration} %{client_address} %{cache_result}/%{status_code} %{bytes} %{request_method} %{url} %{user} %{hierarchy_code}/%{server} %{content_type}"</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
remove_field </span><span class="pun">=></span><span class="pln"> </span><span class="pun">[</span><span class="str">"message"</span><span class="pun">]</span><span class="pln">
convert_datatype </span><span class="pun">=></span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"bytes"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"int"</span><span class="pln">
</span><span class="str">"duration"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"int"</span><span class="pln">
</span><span class="str">"status_code"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"int"</span><span class="pln">
</span><span class="str">"timestamp"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"float"</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span>
Al usar grok, puedes especificar el tipo directamente después del nombre del campo en el patrón.
filter <span class="pun">{</span><span class="pln">
grok </span><span class="pun">{</span><span class="pln">
match </span><span class="pun">=></span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"message"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"%{NUMBER:timestamp:float}%{SPACE}%{NUMBER:duration:int}\s%{IP:client_address}\s%{WORD:cache_result}/%{POSINT:status_code:int}\s%{NUMBER:bytes:int}\s%{WORD:request_method}\s%{NOTSPACE:url}\s%{NOTSPACE:user}\s%{WORD:hierarchy_code}/%{NOTSPACE:server}\s%{NOTSPACE:content_type}"</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
remove_field </span><span class="pun">=></span><span class="pln"> </span><span class="pun">[</span><span class="str">"message"</span><span class="pun">]</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span>
Uso del filtro date
La marca de tiempo extraída del registro es en segundos y milisegundos desde epoch (época). Queremos tomar esto y convertirlo a un formato de marca de tiempo estándar que podamos guardar en el campo @timestamp. Para esto, usaremos el plugin de filtro de datos junto con el patrón UNIX, que coincide con los datos que tenemos.
date <span class="pun">{</span><span class="pln">
match </span><span class="pun">=></span><span class="pln"> </span><span class="pun">[</span><span class="pln"> </span><span class="str">"timestamp"</span><span class="pun">,</span><span class="pln"> </span><span class="str">"UNIX"</span><span class="pln"> </span><span class="pun">]</span><span class="pln">
</span><span class="pun">}</span>
Todas las marcas de tiempo estándar guardadas en Elasticsearch están en zona horaria UTC. Ya que esto también se aplica a nuestra marca de tiempo extraída, no necesitamos especificar ninguna zona horaria. Si tuvieras una marca de tiempo en otro formato, podrías especificar este formato en lugar del patrón predefinido UNIX.
Una vez que hemos agregado esto y las conversiones de tipo a nuestra configuración, el primer evento será de la siguiente manera:
<span class="pun">{</span><span class="pln">
</span><span class="str">"duration"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="lit">19395</span><span class="pun">,</span><span class="pln">
</span><span class="str">"host"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"localhost"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"@timestamp"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="lit">2018</span><span class="pun">-</span><span class="lit">04</span><span class="pun">-</span><span class="lit">20T06</span><span class="pun">:</span><span class="lit">40</span><span class="pun">:</span><span class="lit">24.034Z</span><span class="pun">,</span><span class="pln">
</span><span class="str">"bytes"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="lit">15363</span><span class="pun">,</span><span class="pln">
</span><span class="str">"user"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"-"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"path"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"/home/logstash/testdata.log"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"content_type"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"-"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"@version"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"1"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"url"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str"><img src="http://elastic.co/android-chrome-192x192.gif">
</span><span class="pun">,</span><span class="pln">
</span><span class="str">"server"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"10.0.5.120"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"client_address"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"207.96.0.0"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"timestamp"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="lit">1524206424.034</span><span class="pun">,</span><span class="pln">
</span><span class="str">"status_code"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="lit">304</span><span class="pun">,</span><span class="pln">
</span><span class="str">"cache_result"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"TCP_MISS"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"request_method"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"GET</span><span class="str">"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"hierarchy_code"</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"DIRECT"</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span>
Aparentemente, ahora tenemos el formato que queremos y estamos listos para empezar a enviar datos a Elasticsearch.
¿Cómo envío datos a Elasticsearch?
Antes de empezar a enviar datos a Elasticsearch usando el plugin de salida Elasticsearch, necesitamos revisar el rol de los mapeos y ver en qué se diferencian de los tipos que pueden convertirse en Logstash.
Elasticsearch tiene la capacidad para detectar automáticamente campos numéricos y de cadena, y el mapeo seleccionado estará basado en el primer documento que encuentres que tenga un campo nuevo. Según cómo se vean los datos, esto puede o no producir el mapeo correcto; p. ej., si tenemos un campo que normalmente es un flotante pero puede ser `0` para algunos registros. Es posible que esto pueda mapearse como un entero en lugar de flotante según cuál documento se haya procesado primero.
Elasticsearch también tiene la capacidad para detectar automáticamente campos de fecha, siempre que estén en el mismo formato estándar que produce el filtro date.
Otros tipos de campos, p. ej., geo_point e ip, no pueden detectarse automáticamente, y deben definirse en forma explícita a través de una plantilla de indexación. La plantilla de indexación puede administrarse directamente en Elasticsearch a través de una API, pero también es posible hacer que Logstash asegure que se haya cargado la plantilla correspondiente a través del plugin de salida Elasticsearch.
Para nuestros datos, generalmente los mapeos predeterminados son apropiados. El campo server (servidor) puede contener un guion o una dirección IP válida, por lo que no lo mapearemos como un campo IP. Un campo que requiere mapeo manual es el campo client_address (dirección del cliente), que queremos que sea del tipo IP. También tenemos algunos campos de cadena que queremos agregar por encima, pero no necesitamos hacer una búsqueda de texto libre. Los mapearemos explícitamente como campos keyword (palabra clave). Estos campos son: user (usuario), path (ruta), content_type (tipo de contenido), cache_result (resultado de caché), request_method (método de solicitud), server (servidor) y hierarchy_code (código jerárquico).
Queremos guardar nuestros datos en índices basados en tiempo que comiencen con el prefijo squid-. Supondremos que Elasticsearch se está ejecutando con la configuración predeterminada en el mismo host que Logstash para este ejemplo.
Luego, podemos crear la siguiente plantilla guardada en un archivo llamado squid_mapping.json:
{<span class="pln">
</span><span class="str">"index_patterns"</span><span class="pun">:</span><span class="pln"> </span><span class="pun">[</span><span class="str">"squid-*"</span><span class="pun">],</span><span class="pln">
</span><span class="str">"mappings"</span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"doc"</span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"properties"</span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"client_address"</span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln"> </span><span class="str">"type"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"ip"</span><span class="pln"> </span><span class="pun">},</span><span class="pln">
</span><span class="str">"user"</span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln"> </span><span class="str">"type"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln"> </span><span class="pun">},</span><span class="pln">
</span><span class="str">"path"</span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln"> </span><span class="str">"type"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln"> </span><span class="pun">},</span><span class="pln">
</span><span class="str">"content_type"</span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln"> </span><span class="str">"type"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln"> </span><span class="pun">},</span><span class="pln">
</span><span class="str">"cache_result"</span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln"> </span><span class="str">"type"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln"> </span><span class="pun">},</span><span class="pln">
</span><span class="str">"request_method"</span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln"> </span><span class="str">"type"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln"> </span><span class="pun">},</span><span class="pln">
</span><span class="str">"server"</span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln"> </span><span class="str">"type"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln"> </span><span class="pun">},</span><span class="pln">
</span><span class="str">"hierarchy_code"</span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln"> </span><span class="str">"type"</span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln"> </span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span>
Esta plantilla está configurada para aplicarse a todos los índices que coincidan con el patrón de indexación squid-*. Para el tipo de documento doc (predeterminado en Elasticsearch 6.x), especifica que el mapeo para el campo client_address (dirección del cliente) sea IP y que los demás campos especificados se mapeen como keyword (palabra clave).
Podemos cargar esto directamente a Elasticsearch, pero en su lugar mostraremos cómo configurar el plugin de salida Elasticsearch para que lo maneje. En la sección de salida de nuestra configuración de Logstash, agregaremos un bloque como este:
elasticsearch <span class="pun">{</span><span class="pln">
hosts </span><span class="pun">=></span><span class="pln"> </span><span class="pun">[</span><span class="str">"localhost:9200"</span><span class="pun">]</span><span class="pln">
index </span><span class="pun">=></span><span class="pln"> </span><span class="str">"squid-%{+YYYY.MM.dd}"</span><span class="pln">
manage_template </span><span class="pun">=></span><span class="pln"> </span><span class="kwd">true</span><span class="pln">
</span><span class="kwd">template</span><span class="pln"> </span><span class="pun">=></span><span class="pln"> </span><span class="str">"/home/logstash/squid_mapping.json"</span><span class="pln">
template_name </span><span class="pun">=></span><span class="pln"> </span><span class="str">"squid_template"</span><span class="pln">
</span><span class="pun">}</span>
Si ahora ejecutamos esta configuración e indexamos los documentos de muestra en Elasticsearch, obtendremos lo siguiente al recuperar los mapeos resultantes para el índice a través de la API obtener mapeo:
<span class="pun">{</span><span class="pln">
</span><span class="str">"squid-2018.04.20"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"mappings"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"doc"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"properties"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"@timestamp"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"date"</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"@version"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"text"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"fields"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"keyword"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"ignore_above"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="lit">256</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"bytes"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"long"</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"cache_result"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"client_address"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"ip"</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"content_type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"duration"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"long"</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"hierarchy_code"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"host</span><span class="str">"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"text"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"fields"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"keyword"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"ignore_above"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="lit">256</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"path"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"request_method"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"server"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"status_code"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"long"</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"timestamp"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"float"</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"url"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"text"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"fields"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"keyword"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pun">,</span><span class="pln">
</span><span class="str">"ignore_above"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="lit">256</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">},</span><span class="pln">
</span><span class="str">"user"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="pun">{</span><span class="pln">
</span><span class="str">"type"</span><span class="pln"> </span><span class="pun">:</span><span class="pln"> </span><span class="str">"keyword"</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span><span class="pun">}</span><span class="pln">
</span>
Podemos ver que se aplicó nuestra plantilla y que los campos que especificamos están mapeados de manera correcta. Dado que el enfoque principal de este blog es Logstash, solo analizamos superficialmente cómo funcionan los mapeos. Puedes leer más acerca de este tema esencial en la documentación.
Conclusiones
En este blog mostramos cómo trabajar mejor con Logstash al desarrollar una muestra de configuración personalizada y asegurar que está escrita correctamente en Elasticsearch. Pero esta es solo una muestra superficial de lo que se puede lograr con Logstash. Consulta los documentos y las entradas de blog que aparecen en los vínculos de este blog, pero también consulta la guía oficial de primeros pasos y observa todos los plugins de input (entrada), output (salida) y filter (filtro) disponibles. Una vez que tomes conocimiento de aquello que está disponible, Logstash se convertirá rápidamente en una multiherramienta indispensable en el procesamiento de datos.
Si tienes algún problema o alguna otra pregunta, siempre puedes comunicarte con nosotros en la categoría Logstash en nuestro Foro de debate. Si deseas ver otros ejemplos de configuración de datos y Logstash, ingresa a https://github.com/elastic/examples/ .
¡Feliz análisis!