Acelerar las experiencias de AI generativa
Herramientas para desarrolladores y AI impulsada por la búsqueda creadas para la velocidad y la escala


 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
Los descubrimientos diarios en modelos de lenguaje grandes (LLM) y AI generativa han puesto a los desarrolladores al frente del movimiento, lo cual influye en su dirección y posibilidades. En este blog, compartiremos cómo los clientes de Elastic usan la plataforma abierta y la base de datos de vectores de Elastic para la AI impulsada por búsqueda y herramientas de desarrolladores a fin de acelerar y escalar las experiencias de AI generativa, lo que les brinda nuevas vías de crecimiento.
Los resultados de una encuesta reciente a desarrolladores realizada por Dimensional Research y con el soporte de Elastic indican que el 87 % de los desarrolladores ya tiene un caso de uso para AI generativa; ya sea análisis de datos, soporte al cliente, búsqueda en el lugar de trabajo o chatbots. Pero solo el 11 % implementó con éxito estos casos de uso en entornos de producción.
Varios factores se interponen en su camino:
Despliegue y gestión del modelo: elegir el modelo indicado requiere de experimentación e iteración rápida. Desplegar LLM para aplicaciones de AI generativa es una tarea compleja que demanda mucho tiempo y tiene una curva de aprendizaje pronunciada para muchas organizaciones.
Problemas legales y de cumplimiento: estos problemas son especialmente importantes cuando se trata con datos confidenciales y pueden ser un obstáculo para la adopción del modelo.
- Escalado: los datos específicos del dominio son esenciales para que los LLM comprendan el contexto y generen salidas precisas. Recuperar eso a medida que los datos escalan requiere un soporte que sea escalable en la misma medida para las cargas de trabajo que generan incrustaciones de vectores, lo cual aumenta la demanda de los recursos de memoria y procesamiento con rapidez. Con grandes conjuntos de datos, las ventanas de contexto resultan grandes y costosas para pasar a un LLM; y más contexto no necesariamente significa más relevancia. Solo una plataforma robusta de herramientas puede dar forma al contexto y equilibrar las compensaciones entre relevancia y escala a fin de lograr una arquitectura de innovación viable preparada para el futuro.
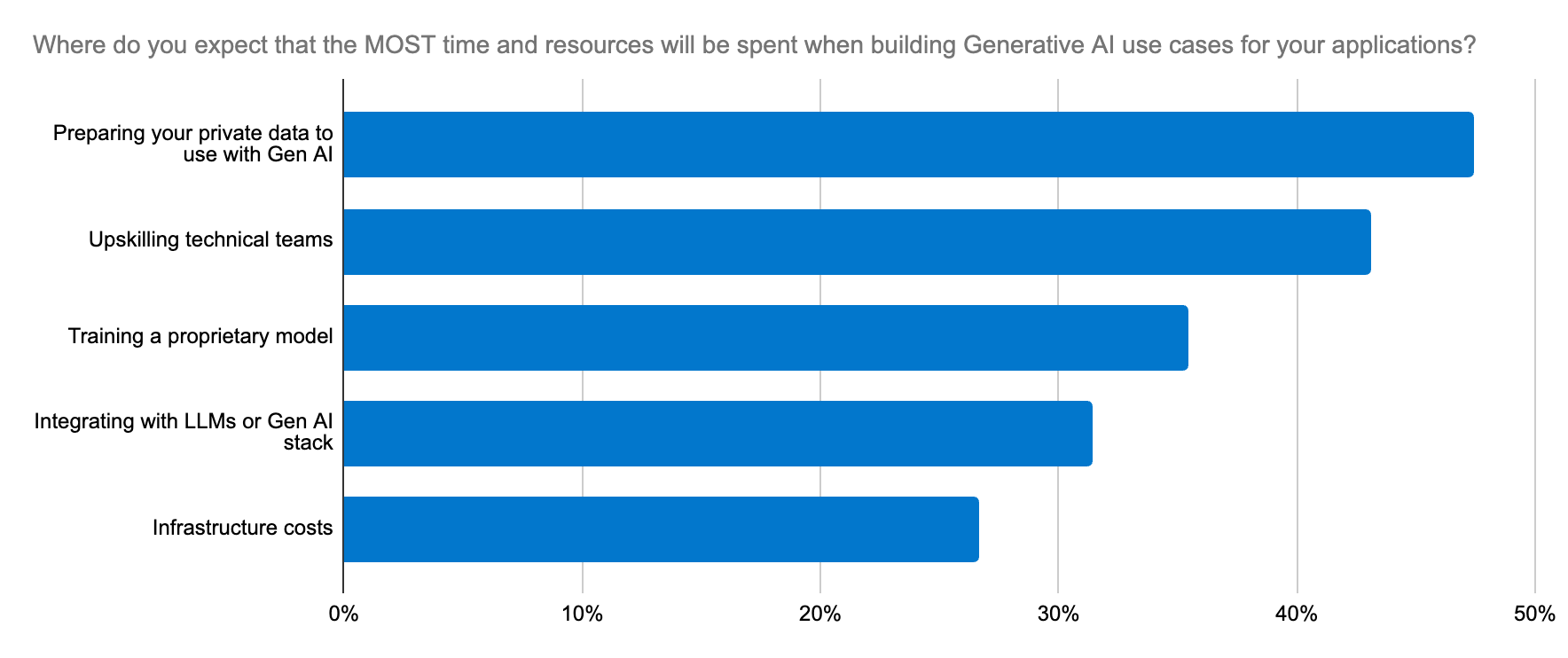
Los desarrolladores buscan una forma confiable, escalable y rentable de crear aplicaciones de AI generativa y una plataforma que simplifique la implementación y el proceso de selección de LLM.
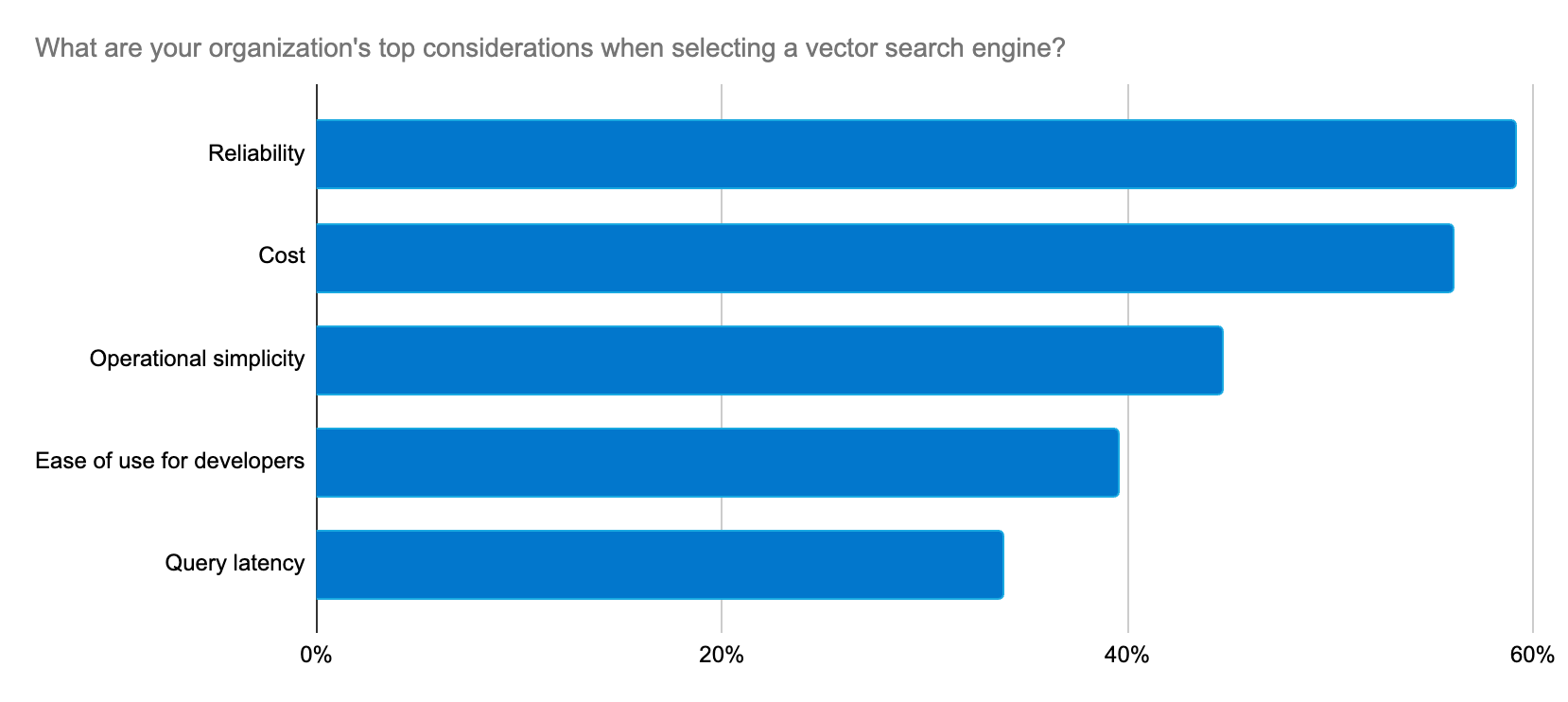
Elastic proporciona de forma constante soluciones a estos problemas para los desarrolladores gracias a un ritmo rápido de innovación con el objetivo de brindar soporte a los casos de uso de AI generativa.
Lanzar experiencias de AI generativas de forma rápida y a escala
Elasticsearch es la base de datos de vectores más descargada en el mercado, y la asociación profunda de Elastic con la comunidad de Lucene nos ha permitido diseñar innovaciones de búsqueda y proporcionarlas a nuestros clientes más rápido. Elasticsearch ahora está impulsado por Lucene 9.10, lo que ayuda a los clientes a lograr velocidad y escala con la AI generativa. Con la versión 9.10, entre otros estímulos de velocidad, los usuarios ven importantes mejoras en la latencia de búsqueda en índices multisegmento. Y eso es solo el comienzo, hay más velocidad por delante.
Usamos Elastic como una base de datos de vectores dada su flexibilidad, escalabilidad y confiabilidad inherentes. Elastic eleva continuamente el juego brindando con rapidez nuevas características que dan soporte al machine learning y la AI generativa.
Peter O'Connor, gerente de ingeniería de ingeniería de plataforma, Stack Overflow
Para implementar y escalar con rapidez cargas de trabajo de RAG, Elastic Learned Sparse EncodeR (ELSER), disponible para el público en general, es un modelo de machine learning (ML) fácil de desplegar, optimizado y de interacción tardía para la búsqueda semántica. ELSER proporciona resultados de búsqueda contextualmente relevantes sin requerir ajustes y ofrece a los desarrolladores una solución integrada de confianza, lo cual ahorra tiempo y complejidad en la selección, el despliegue y la gestión del modelo.
ELSER eleva la relevancia de búsqueda sin resentir la velocidad; cuando Consensus actualizó su plataforma de investigación académica impulsada por Elastic, usando ELSER, redujo la latencia de búsqueda en un 75 % con precisión mejorada.
Al emparejar ELSER con el modelo de incrustación E5, puedes aplicar con facilidad la búsqueda de vectores multilingüe. Nuestro artefacto optimizado de E5 está personalizado específicamente para los despliegues de Elasticsearch. La búsqueda multilingüe también está disponible a través de la carga de modelos multilingües o la integración a la API de inferencia de Elastic (por ejemplo, las incrustaciones del modelo multilingüe de Cohere). Estos avances aceleran más la generación aumentada de recuperación (RAG), lo cual hace que Elastic sea una infraestructura fundamental para escalar las experiencias de AI generativa innovadoras que creas.
Elastic también está enfocado en escalar estas experiencias de manera eficiente. La cuantificación escalar, que se incluye en nuestra versión 8.12, cambia el juego para el almacenamiento de vectores. Las grandes expansiones de vectores pueden llevar a búsquedas más lentas. Pero esta técnica de compresión reduce drásticamente los requisitos de memoria cuatro veces, ayuda a incluir más vectores y, a escalas más altas, tiene un impacto insignificante en la recuperación. Duplica las velocidades de búsquedas de vectores usadas en RAG sin sacrificar la precisión. ¿El resultado? Un sistema más austero y rápido que recorta costos de infraestructura a escala.
Al combinar la precisión y velocidad de Elastic con el poder de Google Cloud, puedes crear una plataforma de búsqueda muy estable y rentable que también brinde una buena experiencia para el usuario.
Sujith Joseph, arquitecto de cloud y búsqueda empresarial principal, Cisco Systems
El motor de búsqueda más relevante para RAG
La relevancia es clave para las mejores experiencias de AI generativa. Usar ELSER para la búsqueda semántica y BM25 para la búsqueda textual son excelentes primeros pasos para recuperar documentos relevantes comocontexto para los LLM. Las ventanas de contexto grandes pueden refinarse aún más con herramientas de reclasificación que ahora son parte del Elastic Stack. Los reclasificadores aplican modelos de ML para ajustar tus resultados de búsqueda y colocan los resultados más relevantes en la parte superior según las señales y preferencias del usuario. Learning to Rank (LTR) ahora también es nativo de Elasticsearch Platform. Es poderoso para los casos de uso de RAG, que dependen de la alimentación de los resultados más relevantes a un LLM como contexto.
La implementación se simplifica aún más mediante la API de inferencia y proveedores externos, como Cohere. Actualiza a nuestra versión más reciente para probar el impacto que pueden tener los reclasificadores en la relevancia.
Estos enfoques no solo mejoran la precisión de búsqueda (en un 30 %, en el caso de Consensus), sino que también te ayudan a lograr resultados rápidos, refinando la relevancia para RAG y gestionando los flujos de trabajo de ML de manera eficiente.
Simplificando la selección y el cambio de modelos
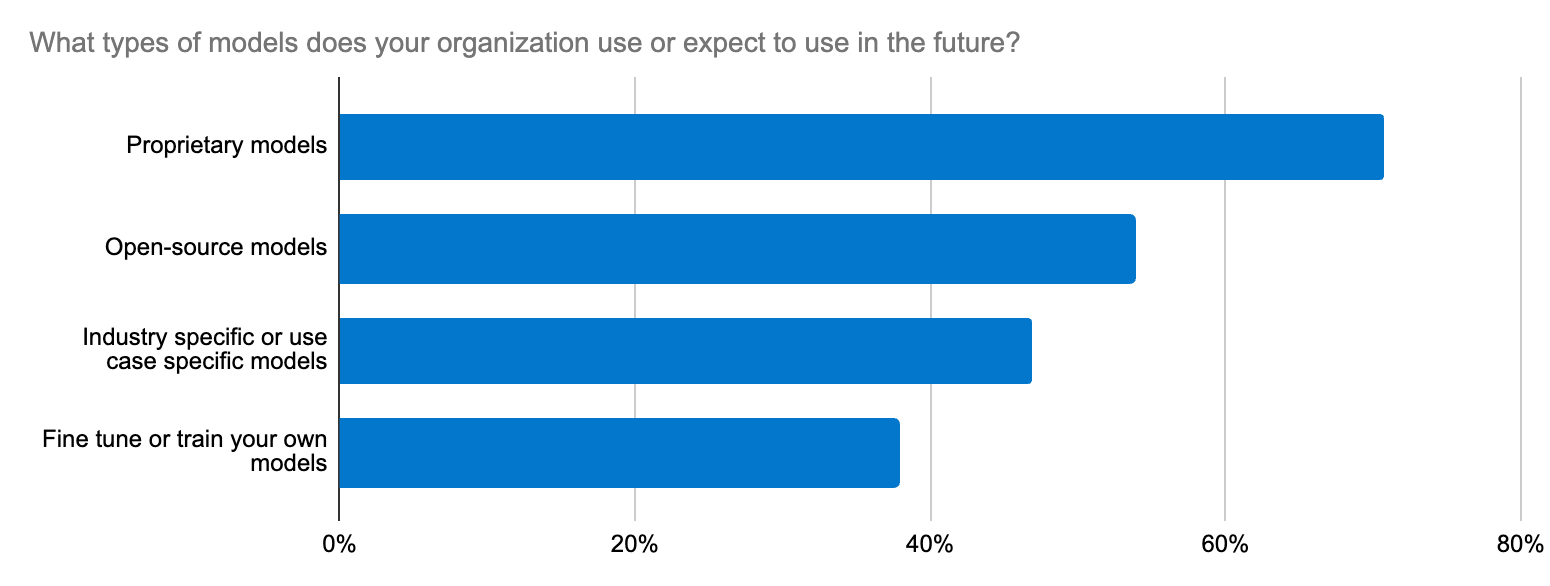
La selección del modelo puede sentirse como la búsqueda de una aguja en un pajar. De hecho, nuestra encuesta a desarrolladores resaltó que uno de los principales cinco esfuerzos de AI generativa en las organizaciones es la integración en LLM. Este dilema va más allá de elegir LLM de open source o closed source para un caso de uso; se extiende a la precisión, la seguridad de los datos, la especificidad para el dominio y la adaptación rápida al ecosistema cambiante de LLM. Los desarrolladores necesitan un flujo de trabajo directo para probar modelos nuevos y cambiar entre uno y otro.
Elastic ofrece soporte para modelos de transformadores y fundacionales a través de su plataforma abierta, base de datos de vectores y motor de búsqueda. Elastic Learned Sparse EncodeR (ELSER) es un punto de partida confiable para acelerar las implementaciones de RAG.
Además, la API de inferencia de Elastic optimiza el código y la gestión de inferencias multicloud para los desarrolladores. Ya sea que uses ELSER o incrustaciones de OpenAI (el modelo más evaluado y usado por los desarrolladores), Hugging Face, Cohere o demás para cargas de trabajo de RAG, una llamada de API garantiza un código limpio para gestionar el despliegue de inferencias híbrido. Con la API de inferencia, es fácil acceder a una amplia gama de modelos, para que puedas encontrar el indicado. La integración sencilla con modelos de AI generativa y procesamiento de lenguaje natural (NLP) específicos del dominio optimiza la gestión de modelos, lo cual libera tiempo para que puedas enfocarte en la innovación de AI.
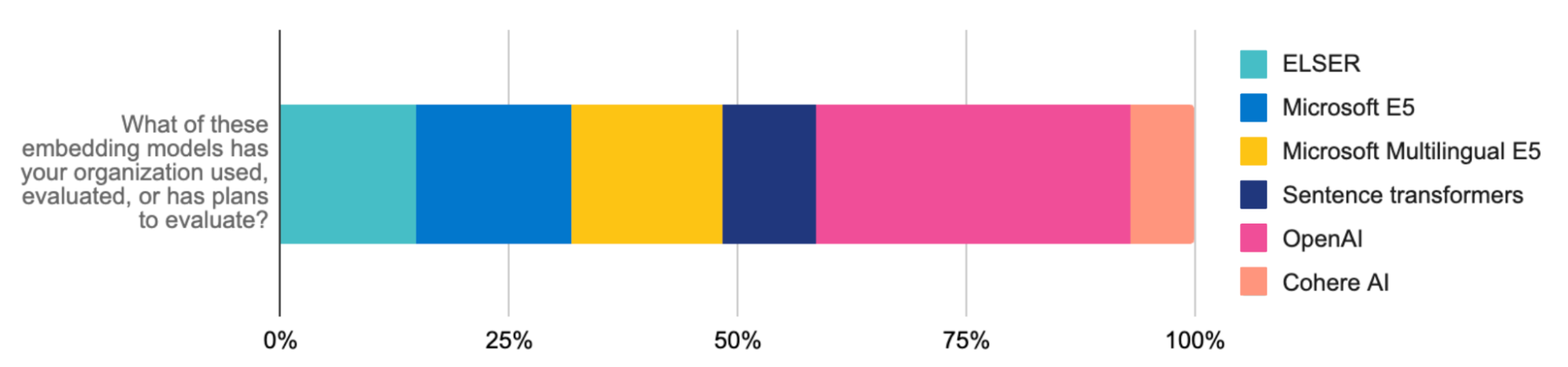
Más fuertes juntos: Una excelente experiencia con las integraciones
Los desarrolladores también pueden hospedar varios modelos de transformadores, que incluyen modelos Hugging Face públicos y privados. Si bien Elasticsearch funciona como una base de datos versátil de vectores para todo el ecosistema, los desarrolladores que prefieren herramientas como LangChain y LlamaIndex pueden usar nuestras integraciones para activar con rapidez apps de AI generativa listas para producción usando LangChain Templates. La plataforma abierta de Elastic te prepara para adaptar, experimentar y acelerar rápidamente proyectos de AI generativa. Elastic también se agregó recientemente como base de datos de vectores externa para On Your Data, un nuevo servicio para crear copilotos conversacionales. Otro buen ejemplo es la colaboración de Elastic con el equipo de Cohere detrás de escena para convertir a Elastic en una excelente base de datos de vectores para incrustaciones de Cohere.
La AI generativa está transformando a todas las organizaciones, y Elastic está aquí para brindar soporte en la transformación. Para los desarrolladores, las claves para las implementaciones exitosas de AI generativa son el aprendizaje continuo (¿ya viste Elastic Search Labs?) y adaptarse con rapidez al panorama cambiante de la AI.
¡Pruébalo!
- Lee sobre estas capacidades y más en las notas de lanzamiento de Elastic Search.
- Los clientes existentes de Elastic Cloud pueden acceder a muchas de estas características directamente desde la consola de Elastic Cloud. ¿No usas Elastic Cloud? Comienza una prueba gratuita.
- Prueba Elasticsearch Relevance Engine, nuestro conjunto de herramientas para desarrolladores para crear aplicaciones de búsqueda de AI.
El lanzamiento y el plazo de cualquier característica o funcionalidad descrita en este blog quedan a la entera discreción de Elastic. Cualquier característica o funcionalidad que no esté disponible actualmente puede no entregarse a tiempo o no entregarse en absoluto.
En este blog, es posible que hayamos usado o mencionado herramientas de AI generativa de terceros, que son propiedad de sus respectivos propietarios y operadas por estos. Elastic no tiene ningún control sobre las herramientas de terceros, y no somos responsables de su contenido, funcionamiento o uso, ni de ninguna pérdida o daño que pueda resultar del uso de dichas herramientas. Ten cautela al usar herramientas de AI con información personal o confidencial. Cualquier dato que envíes puede ser utilizado para el entrenamiento de AI u otros fines. No hay garantías de que la información que proporciones se mantenga segura o confidencial. Deberías familiarizarte con las prácticas de privacidad y los términos de uso de cualquier herramienta de AI generativa previo a su uso.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine y las marcas asociadas son marcas comerciales, logotipos o marcas comerciales registradas de Elasticsearch N.V. en los Estados Unidos y otros países. Todos los demás nombres de empresas y productos son marcas comerciales, logotipos o marcas comerciales registradas de sus respectivos propietarios.
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime